 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTask-Directed Exploration in Continuous POMDPs for Robotic Manipulation of Articulated Objects
Dec 08, 2022



Representing and reasoning about uncertainty is crucial for autonomous agents acting in partially observable environments with noisy sensors. Partially observable Markov decision processes (POMDPs) serve as a general framework for representing problems in which uncertainty is an important factor. Online sample-based POMDP methods have emerged as efficient approaches to solving large POMDPs and have been shown to extend to continuous domains. However, these solutions struggle to find long-horizon plans in problems with significant uncertainty. Exploration heuristics can help guide planning, but many real-world settings contain significant task-irrelevant uncertainty that might distract from the task objective. In this paper, we propose STRUG, an online POMDP solver capable of handling domains that require long-horizon planning with significant task-relevant and task-irrelevant uncertainty. We demonstrate our solution on several temporally extended versions of toy POMDP problems as well as robotic manipulation of articulated objects using a neural perception frontend to construct a distribution of possible models. Our results show that STRUG outperforms the current sample-based online POMDP solvers on several tasks.
Visibility-Aware Navigation Among Movable Obstacles
Dec 06, 2022In this paper, we examine the problem of visibility-aware robot navigation among movable obstacles (VANAMO). A variant of the well-known NAMO robotic planning problem, VANAMO puts additional visibility constraints on robot motion and object movability. This new problem formulation lifts the restrictive assumption that the map is fully visible and the object positions are fully known. We provide a formal definition of the VANAMO problem and propose the Look and Manipulate Backchaining (LaMB) algorithm for solving such problems. LaMB has a simple vision-based API that makes it more easily transferable to real-world robot applications and scales to the large 3D environments. To evaluate LaMB, we construct a set of tasks that illustrate the complex interplay between visibility and object movability that can arise in mobile base manipulation problems in unknown environments. We show that LaMB outperforms NAMO and visibility-aware motion planning approaches as well as simple combinations of them on complex manipulation problems with partial observability.
PG3: Policy-Guided Planning for Generalized Policy Generation
Apr 21, 2022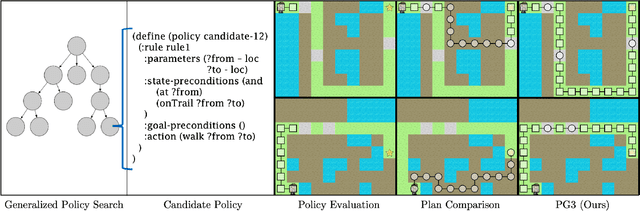



A longstanding objective in classical planning is to synthesize policies that generalize across multiple problems from the same domain. In this work, we study generalized policy search-based methods with a focus on the score function used to guide the search over policies. We demonstrate limitations of two score functions and propose a new approach that overcomes these limitations. The main idea behind our approach, Policy-Guided Planning for Generalized Policy Generation (PG3), is that a candidate policy should be used to guide planning on training problems as a mechanism for evaluating that candidate. Theoretical results in a simplified setting give conditions under which PG3 is optimal or admissible. We then study a specific instantiation of policy search where planning problems are PDDL-based and policies are lifted decision lists. Empirical results in six domains confirm that PG3 learns generalized policies more efficiently and effectively than several baselines. Code: https://github.com/ryangpeixu/pg3
Let's Handle It: Generalizable Manipulation of Articulated Objects
Feb 23, 2022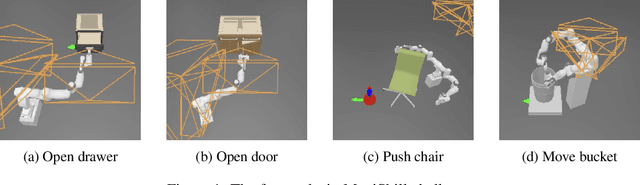
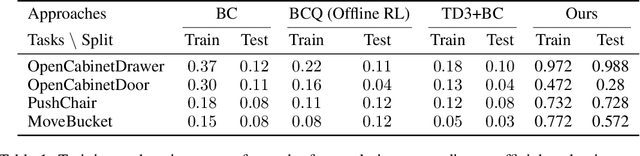

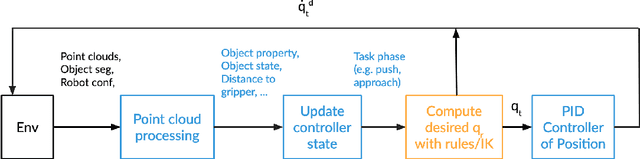
In this project we present a framework for building generalizable manipulation controller policies that map from raw input point clouds and segmentation masks to joint velocities. We took a traditional robotics approach, using point cloud processing, end-effector trajectory calculation, inverse kinematics, closed-loop position controllers, and behavior trees. We demonstrate our framework on four manipulation skills on common household objects that comprise the SAPIEN ManiSkill Manipulation challenge.
Map Induction: Compositional spatial submap learning for efficient exploration in novel environments
Oct 23, 2021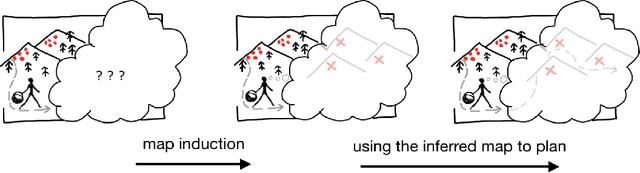
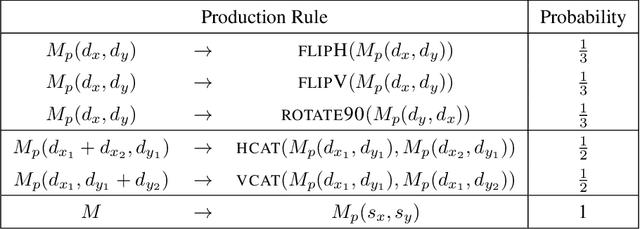
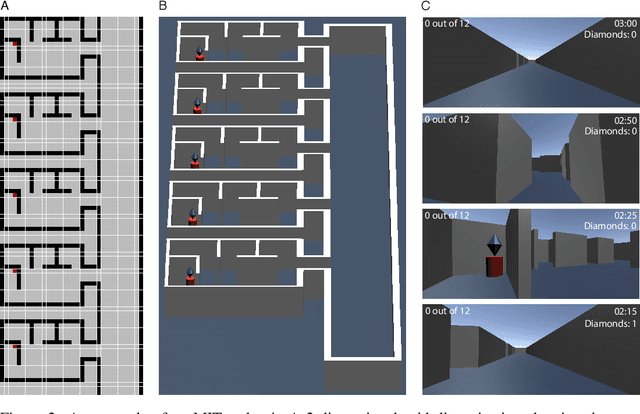
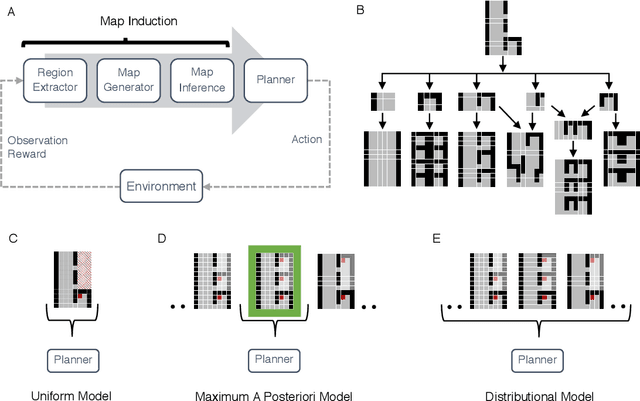
Humans are expert explorers. Understanding the computational cognitive mechanisms that support this efficiency can advance the study of the human mind and enable more efficient exploration algorithms. We hypothesize that humans explore new environments efficiently by inferring the structure of unobserved spaces using spatial information collected from previously explored spaces. This cognitive process can be modeled computationally using program induction in a Hierarchical Bayesian framework that explicitly reasons about uncertainty with strong spatial priors. Using a new behavioral Map Induction Task, we demonstrate that this computational framework explains human exploration behavior better than non-inductive models and outperforms state-of-the-art planning algorithms when applied to a realistic spatial navigation domain.
Discovering State and Action Abstractions for Generalized Task and Motion Planning
Sep 23, 2021
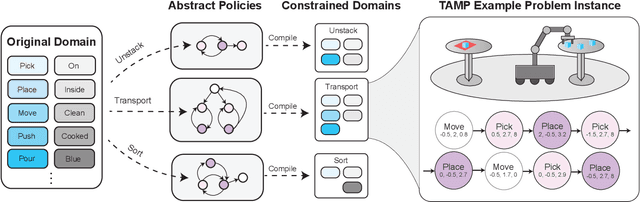
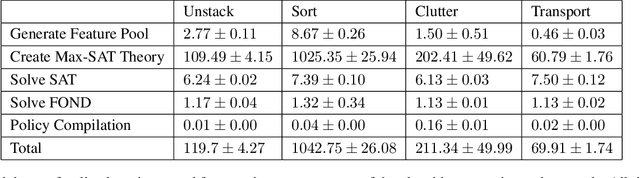
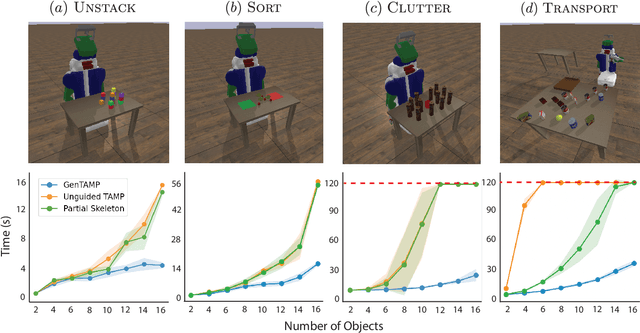
Generalized planning accelerates classical planning by finding an algorithm-like policy that solves multiple instances of a task. A generalized plan can be learned from a few training examples and applied to an entire domain of problems. Generalized planning approaches perform well in discrete AI planning problems that involve large numbers of objects and extended action sequences to achieve the goal. In this paper, we propose an algorithm for learning features, abstractions, and generalized plans for continuous robotic task and motion planning (TAMP) and examine the unique difficulties that arise when forced to consider geometric and physical constraints as a part of the generalized plan. Additionally, we show that these simple generalized plans learned from only a handful of examples can be used to improve the search efficiency of TAMP solvers.
Long-Horizon Manipulation of Unknown Objects via Task and Motion Planning with Estimated Affordances
Aug 10, 2021
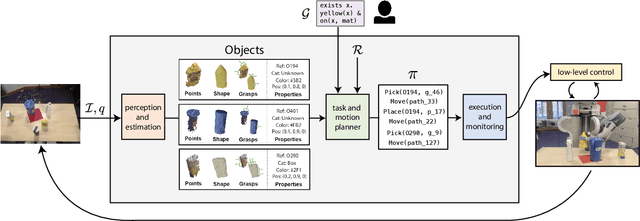


We present a strategy for designing and building very general robot manipulation systems involving the integration of a general-purpose task-and-motion planner with engineered and learned perception modules that estimate properties and affordances of unknown objects. Such systems are closed-loop policies that map from RGB images, depth images, and robot joint encoder measurements to robot joint position commands. We show that following this strategy a task-and-motion planner can be used to plan intelligent behaviors even in the absence of a priori knowledge regarding the set of manipulable objects, their geometries, and their affordances. We explore several different ways of implementing such perceptual modules for segmentation, property detection, shape estimation, and grasp generation. We show how these modules are integrated within the PDDLStream task and motion planning framework. Finally, we demonstrate that this strategy can enable a single system to perform a wide variety of real-world multi-step manipulation tasks, generalizing over a broad class of objects, object arrangements, and goals, without any prior knowledge of the environment and without re-training.
Planning with Learned Object Importance in Large Problem Instances using Graph Neural Networks
Sep 11, 2020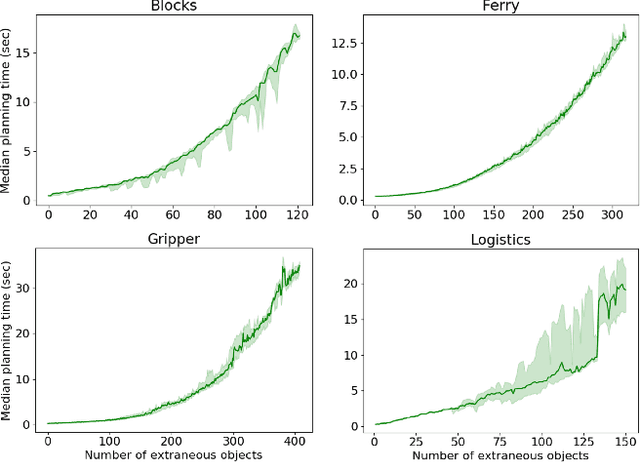
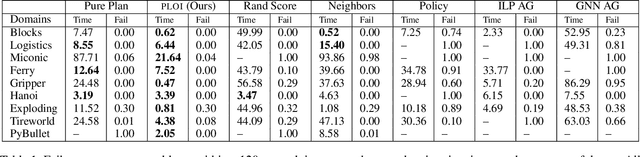
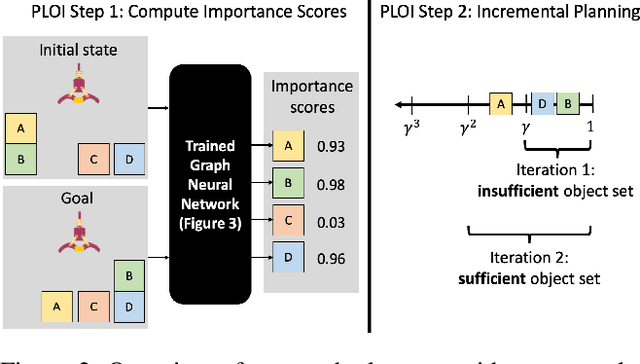

Real-world planning problems often involve hundreds or even thousands of objects, straining the limits of modern planners. In this work, we address this challenge by learning to predict a small set of objects that, taken together, would be sufficient for finding a plan. We propose a graph neural network architecture for predicting object importance in a single pass, thereby incurring little overhead while substantially reducing the number of objects that must be considered by the planner. Our approach treats the planner and transition model as black boxes, and can be used with any off-the-shelf planner. Empirically, across classical planning, probabilistic planning, and robotic task and motion planning, we find that our method results in planning that is significantly faster than several baselines, including other partial grounding strategies and lifted planners. We conclude that learning to predict a sufficient set of objects for a planning problem is a simple, powerful, and general mechanism for planning in large instances. Video: https://youtu.be/FWsVJc2fvCE
ThreeDWorld: A Platform for Interactive Multi-Modal Physical Simulation
Jul 09, 2020
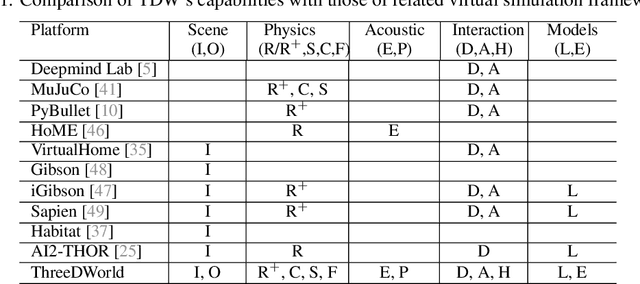

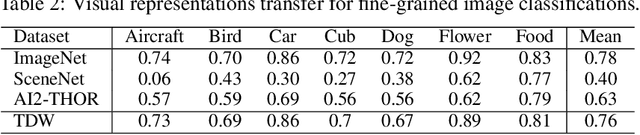
We introduce ThreeDWorld (TDW), a platform for interactive multi-modal physical simulation. With TDW, users can simulate high-fidelity sensory data and physical interactions between mobile agents and objects in a wide variety of rich 3D environments. TDW has several unique properties: 1) realtime near photo-realistic image rendering quality; 2) a library of objects and environments with materials for high-quality rendering, and routines enabling user customization of the asset library; 3) generative procedures for efficiently building classes of new environments 4) high-fidelity audio rendering; 5) believable and realistic physical interactions for a wide variety of material types, including cloths, liquid, and deformable objects; 6) a range of "avatar" types that serve as embodiments of AI agents, with the option for user avatar customization; and 7) support for human interactions with VR devices. TDW also provides a rich API enabling multiple agents to interact within a simulation and return a range of sensor and physics data representing the state of the world. We present initial experiments enabled by the platform around emerging research directions in computer vision, machine learning, and cognitive science, including multi-modal physical scene understanding, multi-agent interactions, models that "learn like a child", and attention studies in humans and neural networks. The simulation platform will be made publicly available.
Flexible and Efficient Long-Range Planning Through Curious Exploration
Apr 22, 2020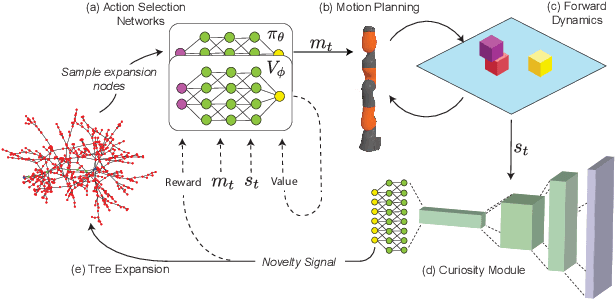
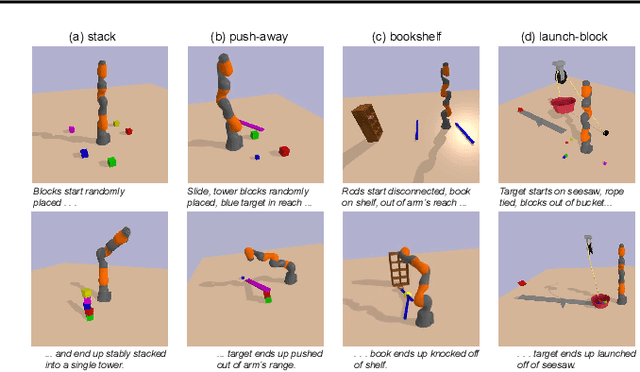
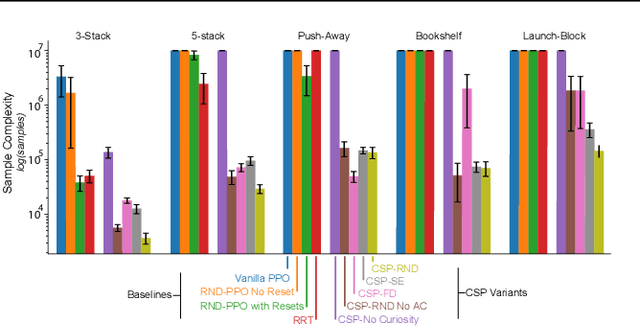
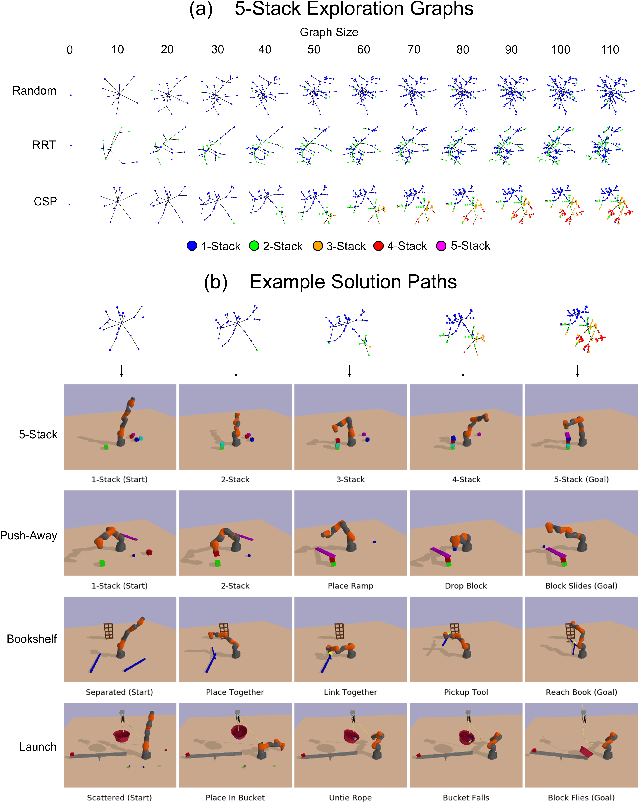
Identifying algorithms that flexibly and efficiently discover temporally-extended multi-phase plans is an essential step for the advancement of robotics and model-based reinforcement learning. The core problem of long-range planning is finding an efficient way to search through the tree of possible action sequences. Existing non-learned planning solutions from the Task and Motion Planning (TAMP) literature rely on the existence of logical descriptions for the effects and preconditions for actions. This constraint allows TAMP methods to efficiently reduce the tree search problem but limits their ability to generalize to unseen and complex physical environments. In contrast, deep reinforcement learning (DRL) methods use flexible neural-network-based function approximators to discover policies that generalize naturally to unseen circumstances. However, DRL methods struggle to handle the very sparse reward landscapes inherent to long-range multi-step planning situations. Here, we propose the Curious Sample Planner (CSP), which fuses elements of TAMP and DRL by combining a curiosity-guided sampling strategy with imitation learning to accelerate planning. We show that CSP can efficiently discover interesting and complex temporally-extended plans for solving a wide range of physically realistic 3D tasks. In contrast, standard planning and learning methods often fail to solve these tasks at all or do so only with a huge and highly variable number of training samples. We explore the use of a variety of curiosity metrics with CSP and analyze the types of solutions that CSP discovers. Finally, we show that CSP supports task transfer so that the exploration policies learned during experience with one task can help improve efficiency on related tasks.