 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSemantically-Guided Representation Learning for Self-Supervised Monocular Depth
Feb 27, 2020
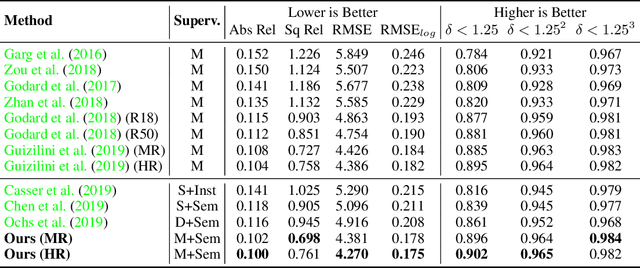
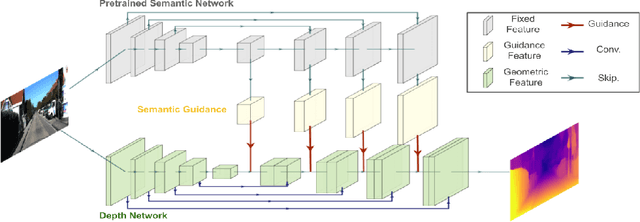
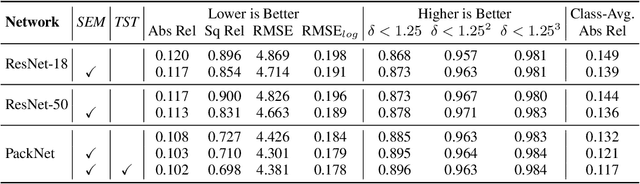
Self-supervised learning is showing great promise for monocular depth estimation, using geometry as the only source of supervision. Depth networks are indeed capable of learning representations that relate visual appearance to 3D properties by implicitly leveraging category-level patterns. In this work we investigate how to leverage more directly this semantic structure to guide geometric representation learning, while remaining in the self-supervised regime. Instead of using semantic labels and proxy losses in a multi-task approach, we propose a new architecture leveraging fixed pretrained semantic segmentation networks to guide self-supervised representation learning via pixel-adaptive convolutions. Furthermore, we propose a two-stage training process to overcome a common semantic bias on dynamic objects via resampling. Our method improves upon the state of the art for self-supervised monocular depth prediction over all pixels, fine-grained details, and per semantic categories.
Spatiotemporal Relationship Reasoning for Pedestrian Intent Prediction
Feb 20, 2020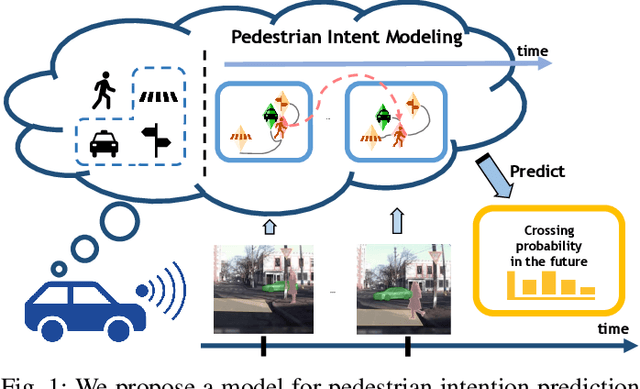
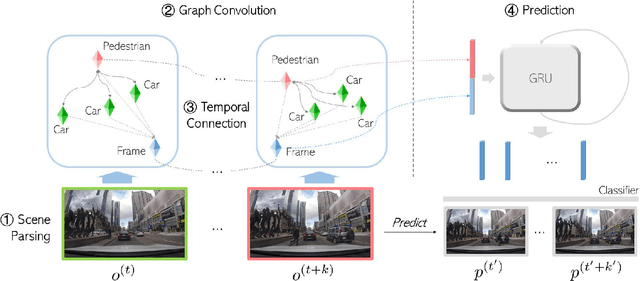


Reasoning over visual data is a desirable capability for robotics and vision-based applications. Such reasoning enables forecasting of the next events or actions in videos. In recent years, various models have been developed based on convolution operations for prediction or forecasting, but they lack the ability to reason over spatiotemporal data and infer the relationships of different objects in the scene. In this paper, we present a framework based on graph convolution to uncover the spatiotemporal relationships in the scene for reasoning about pedestrian intent. A scene graph is built on top of segmented object instances within and across video frames. Pedestrian intent, defined as the future action of crossing or not-crossing the street, is a very crucial piece of information for autonomous vehicles to navigate safely and more smoothly. We approach the problem of intent prediction from two different perspectives and anticipate the intention-to-cross within both pedestrian-centric and location-centric scenarios. In addition, we introduce a new dataset designed specifically for autonomous-driving scenarios in areas with dense pedestrian populations: the Stanford-TRI Intent Prediction (STIP) dataset. Our experiments on STIP and another benchmark dataset show that our graph modeling framework is able to predict the intention-to-cross of the pedestrians with an accuracy of 79.10% on STIP and 79.28% on \rev{Joint Attention for Autonomous Driving (JAAD) dataset up to one second earlier than when the actual crossing happens. These results outperform the baseline and previous work. Please refer to http://stip.stanford.edu/ for the dataset and code.
Self-Supervised 3D Keypoint Learning for Ego-motion Estimation
Dec 07, 2019
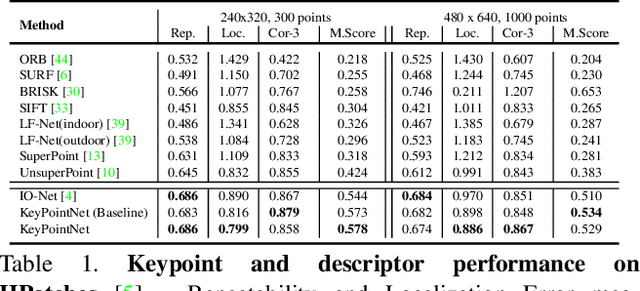
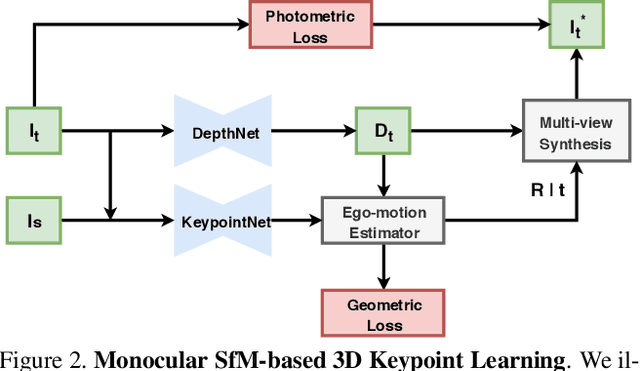

Generating reliable illumination and viewpoint invariant keypoints is critical for feature-based SLAM and SfM. State-of-the-art learning-based methods often rely on generating training samples by employing homography adaptation to create 2D synthetic views. While such approaches trivially solve data association between views, they cannot effectively learn from real illumination and non-planar 3D scenes. In this work, we propose a fully self-supervised approach towards learning depth-aware keypoints \textit{purely} from unlabeled videos by incorporating a differentiable pose estimation module that jointly optimizes the keypoints and their depths in a Structure-from-Motion setting. We introduce 3D Multi-View Adaptation, a technique that exploits the temporal context in videos to self-supervise keypoint detection and matching in an end-to-end differentiable manner. Finally, we show how a fully self-supervised keypoint detection and description network can be trivially incorporated as a front-end into a state-of-the-art visual odometry framework that is robust and accurate.
Real-Time Panoptic Segmentation from Dense Detections
Dec 04, 2019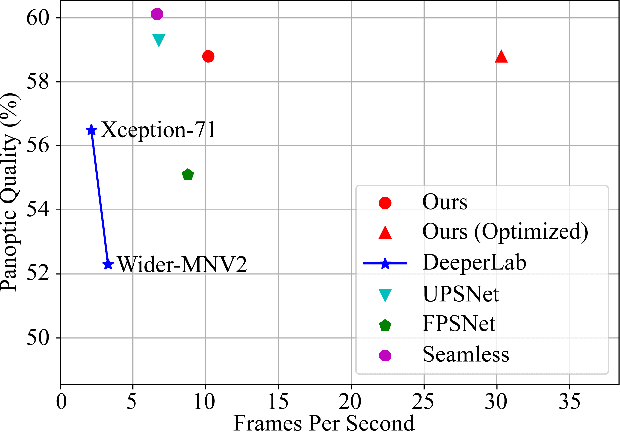
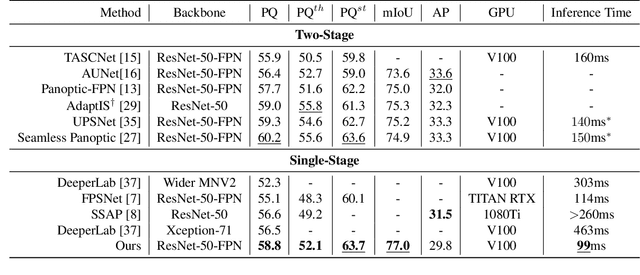
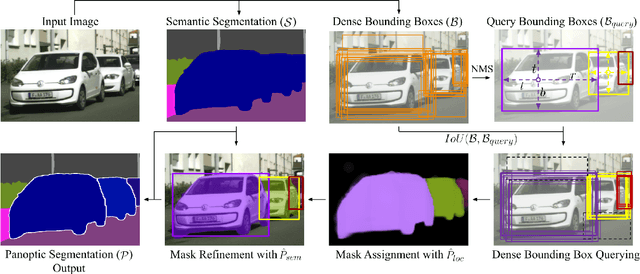
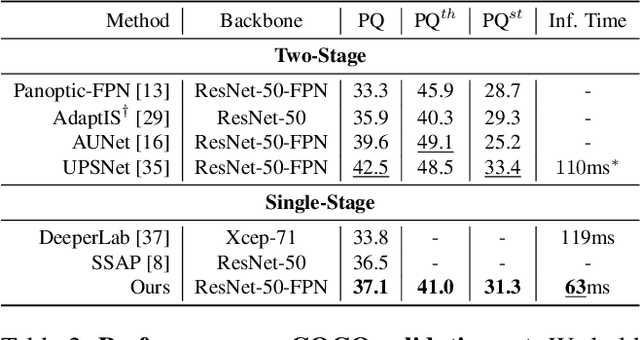
Panoptic segmentation is a complex full scene parsing task requiring simultaneous instance and semantic segmentation at high resolution. Current state-of-the-art approaches cannot run in real-time, and simplifying these architectures to improve efficiency severely degrades their accuracy. In this paper, we propose a new single-shot panoptic segmentation network that leverages dense detections and a global self-attention mechanism to operate in real-time with performance approaching the state of the art. We introduce a novel parameter-free mask construction method that substantially reduces computational complexity by efficiently reusing information from the object detection and semantic segmentation sub-tasks. The resulting network has a simple data flow that does not require feature map re-sampling or clustering post-processing, enabling significant hardware acceleration. Our experiments on the Cityscapes and COCO benchmarks show that our network works at 30 FPS on 1024x2048 resolution, trading a 3% relative performance degradation from the current state of the art for up to 440% faster inference.
Autolabeling 3D Objects with Differentiable Rendering of SDF Shape Priors
Nov 26, 2019



We present an automatic annotation pipeline to recover 9D cuboids and 3D shape from pre-trained off-the-shelf 2D detectors and sparse LIDAR data. Our autolabeling method solves this challenging ill-posed inverse problem by relying on learned shape priors and optimization of geometric and physical parameters. To that end, we propose a novel differentiable shape renderer over signed distance fields (SDF), which we leverage in combination with normalized object coordinate spaces (NOCS). Initially trained on synthetic data to predict shape and coordinates, our method uses these predictions for projective and geometrical alignment over real samples. We also propose a curriculum learning strategy, iteratively retraining on samples of increasing difficulty for subsequent self-improving annotation rounds. Our experiments on the KITTI3D dataset show that we can recover a substantial amount of accurate cuboids, and that these autolabels can be used to train 3D vehicle detectors with state-of-the-art results. We will make the code publicly available soon.
Disentangling Human Dynamics for Pedestrian Locomotion Forecasting with Noisy Supervision
Nov 04, 2019

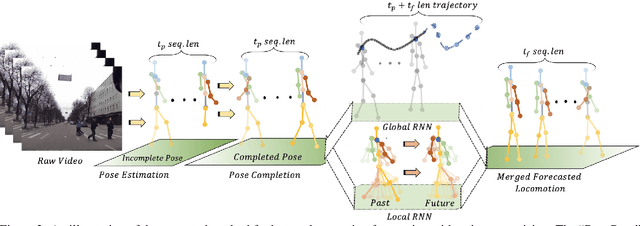

We tackle the problem of Human Locomotion Forecasting, a task for jointly predicting the spatial positions of several keypoints on the human body in the near future under an egocentric setting. In contrast to the previous work that aims to solve either the task of pose prediction or trajectory forecasting in isolation, we propose a framework to unify the two problems and address the practically useful task of pedestrian locomotion prediction in the wild. Among the major challenges in solving this task is the scarcity of annotated egocentric video datasets with dense annotations for pose, depth, or egomotion. To surmount this difficulty, we use state-of-the-art models to generate (noisy) annotations and propose robust forecasting models that can learn from this noisy supervision. We present a method to disentangle the overall pedestrian motion into easier to learn subparts by utilizing a pose completion and a decomposition module. The completion module fills in the missing key-point annotations and the decomposition module breaks the cleaned locomotion down to global (trajectory) and local (pose keypoint movements). Further, with Quasi RNN as our backbone, we propose a novel hierarchical trajectory forecasting network that utilizes low-level vision domain specific signals like egomotion and depth to predict the global trajectory. Our method leads to state-of-the-art results for the prediction of human locomotion in the egocentric view.
Robust Semi-Supervised Monocular Depth Estimation with Reprojected Distances
Oct 23, 2019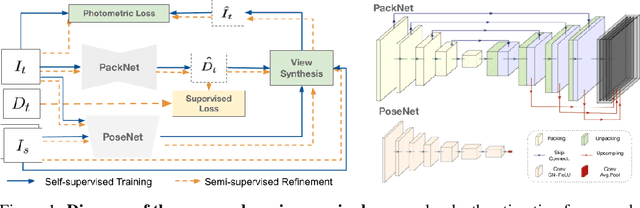
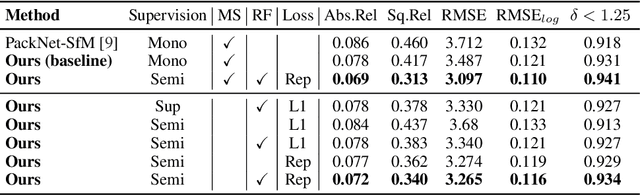
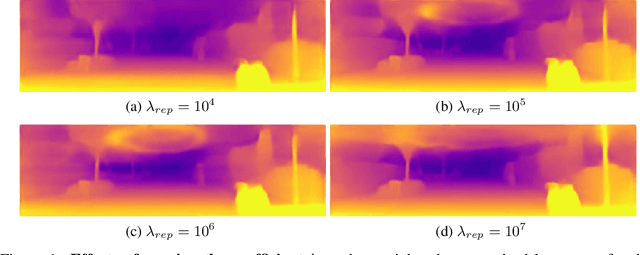
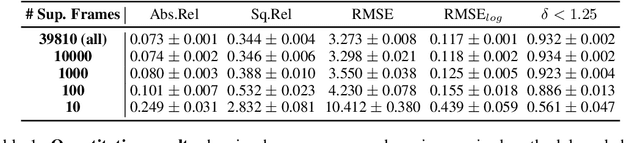
Dense depth estimation from a single image is a key problem in computer vision, with exciting applications in a multitude of robotic tasks. Initially viewed as a direct regression problem, requiring annotated labels as supervision at training time, in the past few years a substantial amount of work has been done in self-supervised depth training based on strong geometric cues, both from stereo cameras and more recently from monocular video sequences. In this paper we investigate how these two approaches (supervised & self-supervised) can be effectively combined, so that a depth model can learn to encode true scale from sparse supervision while achieving high fidelity local accuracy by leveraging geometric cues. To this end, we propose a novel supervised loss term that complements the widely used photometric loss, and show how it can be used to train robust semi-supervised monocular depth estimation models. Furthermore, we evaluate how much supervision is actually necessary to train accurate scale-aware monocular depth models, showing that with our proposed framework, very sparse LiDAR information, with as few as 4 beams (less than 100 valid depth values per image), is enough to achieve results competitive with the current state-of-the-art.
Two Stream Networks for Self-Supervised Ego-Motion Estimation
Oct 23, 2019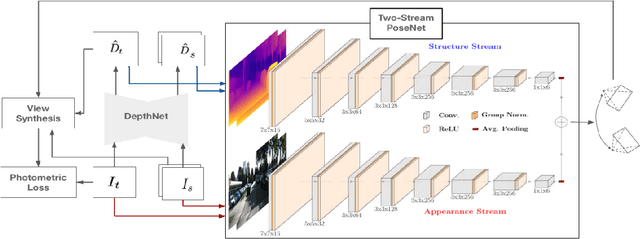
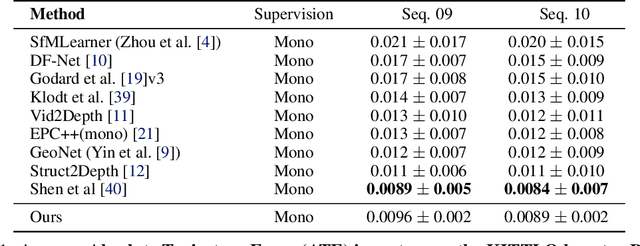
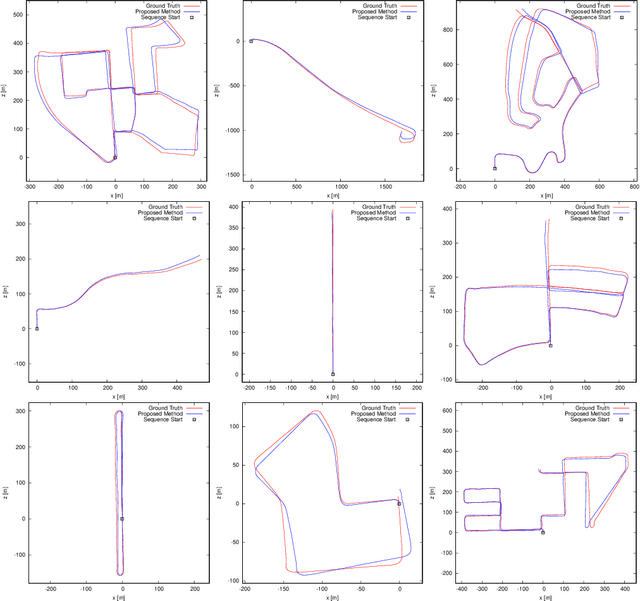

Learning depth and camera ego-motion from raw unlabeled RGB video streams is seeing exciting progress through self-supervision from strong geometric cues. To leverage not only appearance but also scene geometry, we propose a novel self-supervised two-stream network using RGB and inferred depth information for accurate visual odometry. In addition, we introduce a sparsity-inducing data augmentation policy for ego-motion learning that effectively regularizes the pose network to enable stronger generalization performance. As a result, we show that our proposed two-stream pose network achieves state-of-the-art results among learning-based methods on the KITTI odometry benchmark, and is especially suited for self-supervision at scale. Our experiments on a large-scale urban driving dataset of 1 million frames indicate that the performance of our proposed architecture does indeed scale progressively with more data.
Generating Human Action Videos by Coupling 3D Game Engines and Probabilistic Graphical Models
Oct 12, 2019
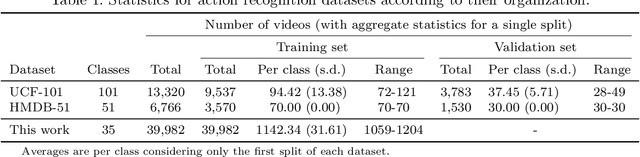


Deep video action recognition models have been highly successful in recent years but require large quantities of manually annotated data, which are expensive and laborious to obtain. In this work, we investigate the generation of synthetic training data for video action recognition, as synthetic data have been successfully used to supervise models for a variety of other computer vision tasks. We propose an interpretable parametric generative model of human action videos that relies on procedural generation, physics models and other components of modern game engines. With this model we generate a diverse, realistic, and physically plausible dataset of human action videos, called PHAV for "Procedural Human Action Videos". PHAV contains a total of 39,982 videos, with more than 1,000 examples for each of 35 action categories. Our video generation approach is not limited to existing motion capture sequences: 14 of these 35 categories are procedurally defined synthetic actions. In addition, each video is represented with 6 different data modalities, including RGB, optical flow and pixel-level semantic labels. These modalities are generated almost simultaneously using the Multiple Render Targets feature of modern GPUs. In order to leverage PHAV, we introduce a deep multi-task (i.e. that considers action classes from multiple datasets) representation learning architecture that is able to simultaneously learn from synthetic and real video datasets, even when their action categories differ. Our experiments on the UCF-101 and HMDB-51 benchmarks suggest that combining our large set of synthetic videos with small real-world datasets can boost recognition performance. Our approach also significantly outperforms video representations produced by fine-tuning state-of-the-art unsupervised generative models of videos.
Learning Imbalanced Datasets with Label-Distribution-Aware Margin Loss
Jun 18, 2019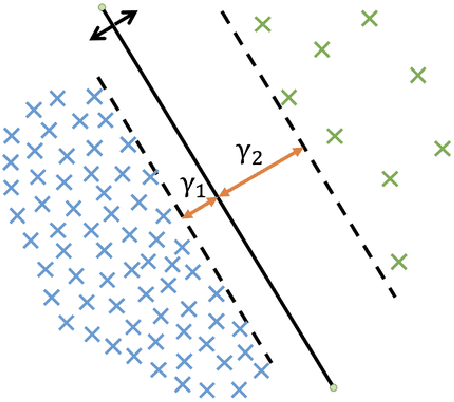
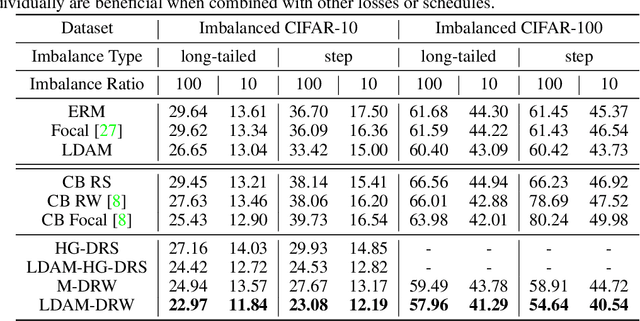
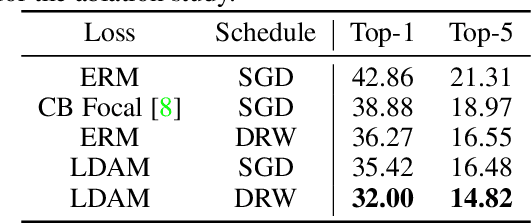
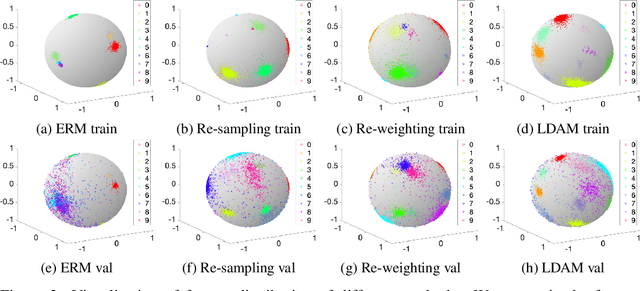
Deep learning algorithms can fare poorly when the training dataset suffers from heavy class-imbalance but the testing criterion requires good generalization on less frequent classes. We design two novel methods to improve performance in such scenarios. First, we propose a theoretically-principled label-distribution-aware margin (LDAM) loss motivated by minimizing a margin-based generalization bound. This loss replaces the standard cross-entropy objective during training and can be applied with prior strategies for training with class-imbalance such as re-weighting or re-sampling. Second, we propose a simple, yet effective, training schedule that defers re-weighting until after the initial stage, allowing the model to learn an initial representation while avoiding some of the complications associated with re-weighting or re-sampling. We test our methods on several benchmark vision tasks including the real-world imbalanced dataset iNaturalist 2018. Our experiments show that either of these methods alone can already improve over existing techniques and their combination achieves even better performance gains.