 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFull Surround Monodepth from Multiple Cameras
Mar 31, 2021
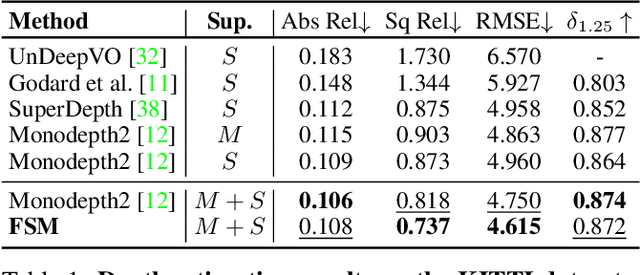
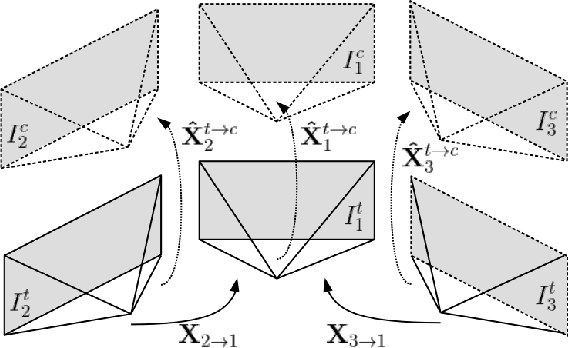
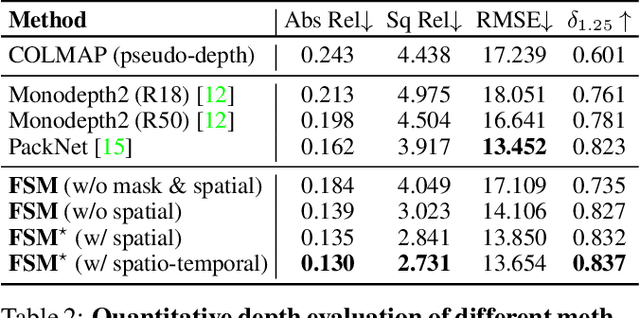
Self-supervised monocular depth and ego-motion estimation is a promising approach to replace or supplement expensive depth sensors such as LiDAR for robotics applications like autonomous driving. However, most research in this area focuses on a single monocular camera or stereo pairs that cover only a fraction of the scene around the vehicle. In this work, we extend monocular self-supervised depth and ego-motion estimation to large-baseline multi-camera rigs. Using generalized spatio-temporal contexts, pose consistency constraints, and carefully designed photometric loss masking, we learn a single network generating dense, consistent, and scale-aware point clouds that cover the same full surround 360 degree field of view as a typical LiDAR scanner. We also propose a new scale-consistent evaluation metric more suitable to multi-camera settings. Experiments on two challenging benchmarks illustrate the benefits of our approach over strong baselines.
Geometric Unsupervised Domain Adaptation for Semantic Segmentation
Mar 30, 2021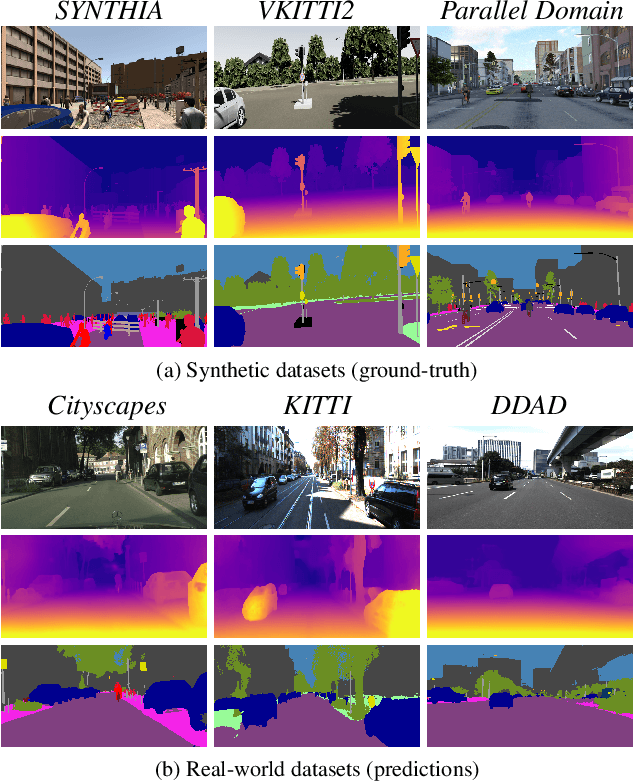
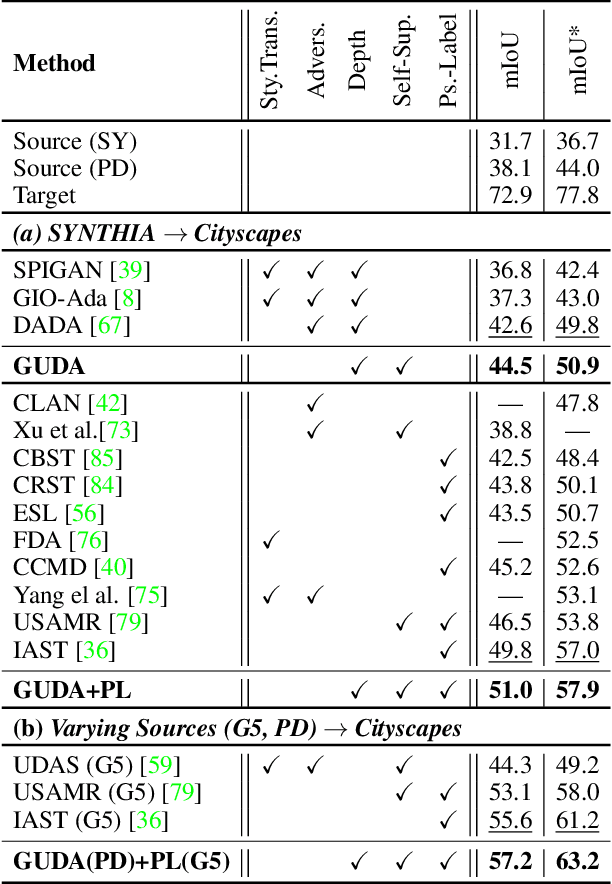
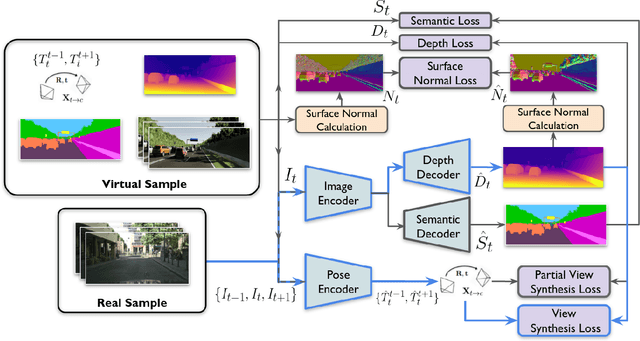
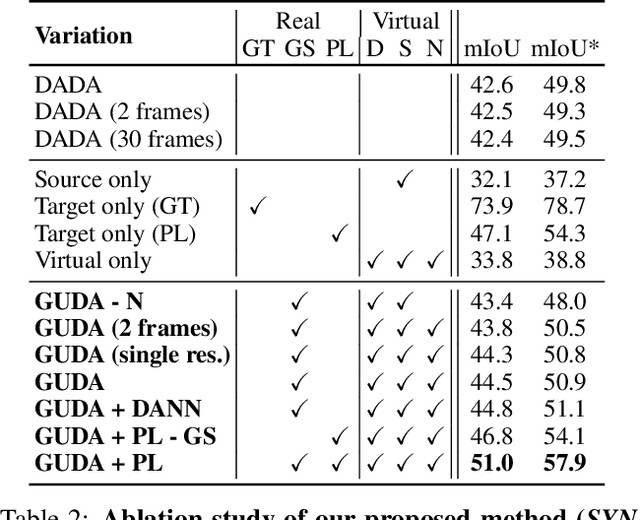
Simulators can efficiently generate large amounts of labeled synthetic data with perfect supervision for hard-to-label tasks like semantic segmentation. However, they introduce a domain gap that severely hurts real-world performance. We propose to use self-supervised monocular depth estimation as a proxy task to bridge this gap and improve sim-to-real unsupervised domain adaptation (UDA). Our Geometric Unsupervised Domain Adaptation method (GUDA) learns a domain-invariant representation via a multi-task objective combining synthetic semantic supervision with real-world geometric constraints on videos. GUDA establishes a new state of the art in UDA for semantic segmentation on three benchmarks, outperforming methods that use domain adversarial learning, self-training, or other self-supervised proxy tasks. Furthermore, we show that our method scales well with the quality and quantity of synthetic data while also improving depth prediction.
Sparse Auxiliary Networks for Unified Monocular Depth Prediction and Completion
Mar 30, 2021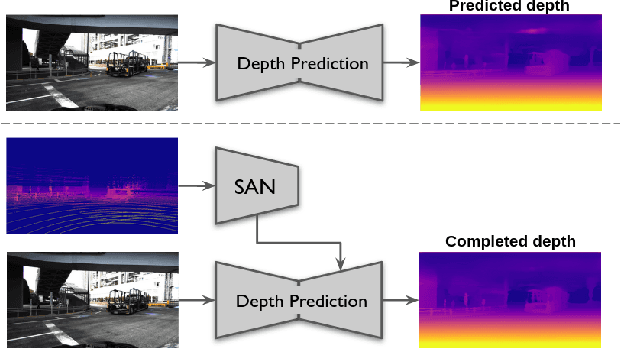
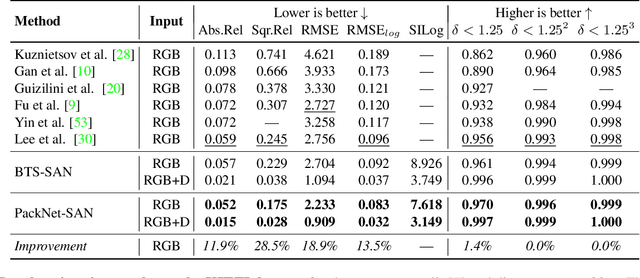
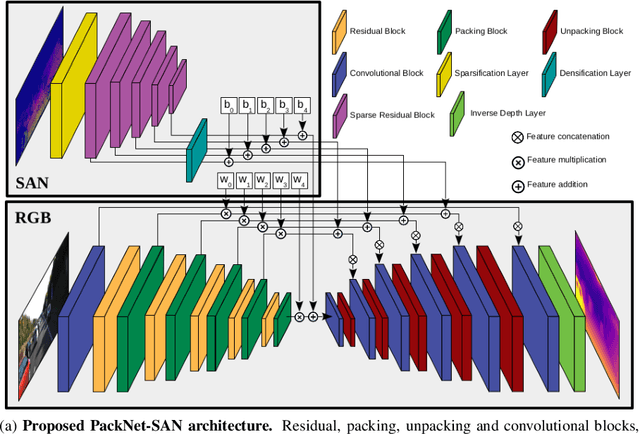
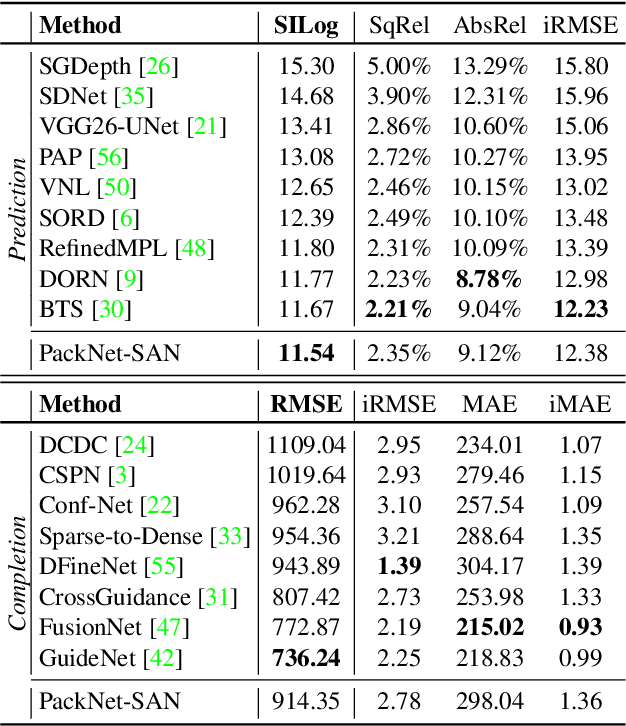
Estimating scene geometry from data obtained with cost-effective sensors is key for robots and self-driving cars. In this paper, we study the problem of predicting dense depth from a single RGB image (monodepth) with optional sparse measurements from low-cost active depth sensors. We introduce Sparse Auxiliary Networks (SANs), a new module enabling monodepth networks to perform both the tasks of depth prediction and completion, depending on whether only RGB images or also sparse point clouds are available at inference time. First, we decouple the image and depth map encoding stages using sparse convolutions to process only the valid depth map pixels. Second, we inject this information, when available, into the skip connections of the depth prediction network, augmenting its features. Through extensive experimental analysis on one indoor (NYUv2) and two outdoor (KITTI and DDAD) benchmarks, we demonstrate that our proposed SAN architecture is able to simultaneously learn both tasks, while achieving a new state of the art in depth prediction by a significant margin.
Measuring Sample Efficiency and Generalization in Reinforcement Learning Benchmarks: NeurIPS 2020 Procgen Benchmark
Mar 29, 2021
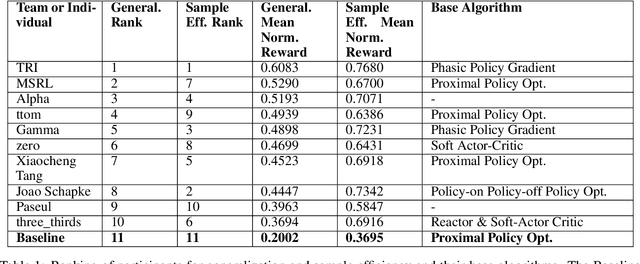
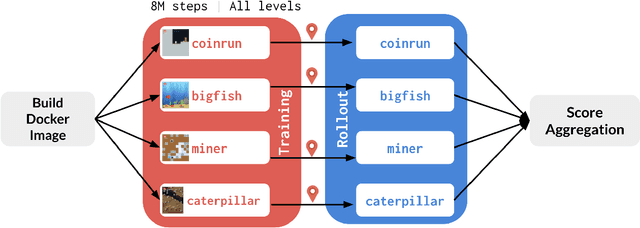
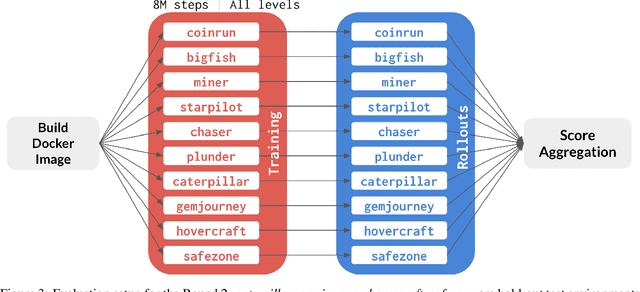
The NeurIPS 2020 Procgen Competition was designed as a centralized benchmark with clearly defined tasks for measuring Sample Efficiency and Generalization in Reinforcement Learning. Generalization remains one of the most fundamental challenges in deep reinforcement learning, and yet we do not have enough benchmarks to measure the progress of the community on Generalization in Reinforcement Learning. We present the design of a centralized benchmark for Reinforcement Learning which can help measure Sample Efficiency and Generalization in Reinforcement Learning by doing end to end evaluation of the training and rollout phases of thousands of user submitted code bases in a scalable way. We designed the benchmark on top of the already existing Procgen Benchmark by defining clear tasks and standardizing the end to end evaluation setups. The design aims to maximize the flexibility available for researchers who wish to design future iterations of such benchmarks, and yet imposes necessary practical constraints to allow for a system like this to scale. This paper presents the competition setup and the details and analysis of the top solutions identified through this setup in context of 2020 iteration of the competition at NeurIPS.
Learning to Track with Object Permanence
Mar 26, 2021

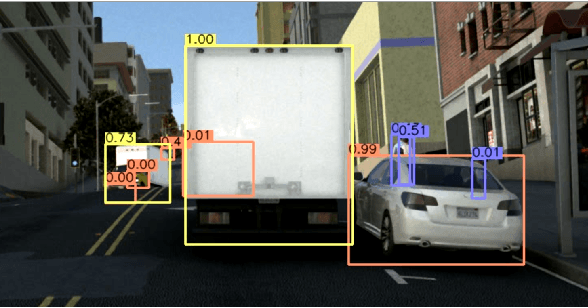
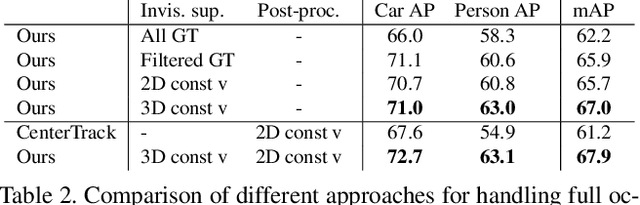
Tracking by detection, the dominant approach for online multi-object tracking, alternates between localization and re-identification steps. As a result, it strongly depends on the quality of instantaneous observations, often failing when objects are not fully visible. In contrast, tracking in humans is underlined by the notion of object permanence: once an object is recognized, we are aware of its physical existence and can approximately localize it even under full occlusions. In this work, we introduce an end-to-end trainable approach for joint object detection and tracking that is capable of such reasoning. We build on top of the recent CenterTrack architecture, which takes pairs of frames as input, and extend it to videos of arbitrary length. To this end, we augment the model with a spatio-temporal, recurrent memory module, allowing it to reason about object locations and identities in the current frame using all the previous history. It is, however, not obvious how to train such an approach. We study this question on a new, large-scale, synthetic dataset for multi-object tracking, which provides ground truth annotations for invisible objects, and propose several approaches for supervising tracking behind occlusions. Our model, trained jointly on synthetic and real data, outperforms the state of the art on KITTI, and MOT17 datasets thanks to its robustness to occlusions.
Monocular Depth Estimation for Soft Visuotactile Sensors
Jan 05, 2021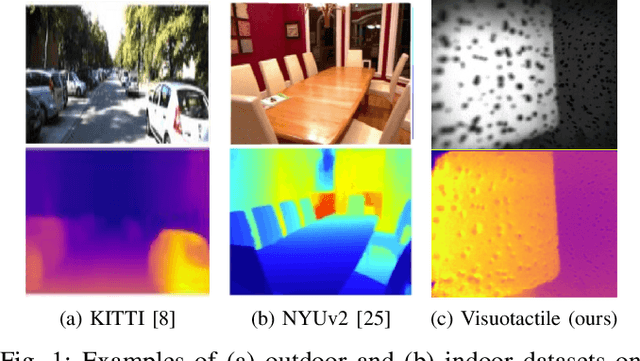
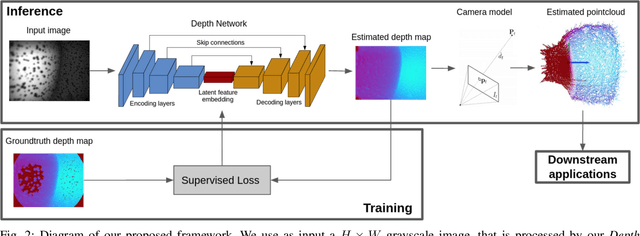


Fluid-filled soft visuotactile sensors such as the Soft-bubbles alleviate key challenges for robust manipulation, as they enable reliable grasps along with the ability to obtain high-resolution sensory feedback on contact geometry and forces. Although they are simple in construction, their utility has been limited due to size constraints introduced by enclosed custom IR/depth imaging sensors to directly measure surface deformations. Towards mitigating this limitation, we investigate the application of state-of-the-art monocular depth estimation to infer dense internal (tactile) depth maps directly from the internal single small IR imaging sensor. Through real-world experiments, we show that deep networks typically used for long-range depth estimation (1-100m) can be effectively trained for precise predictions at a much shorter range (1-100mm) inside a mostly textureless deformable fluid-filled sensor. We propose a simple supervised learning process to train an object-agnostic network requiring less than 10 random poses in contact for less than 10 seconds for a small set of diverse objects (mug, wine glass, box, and fingers in our experiments). We show that our approach is sample-efficient, accurate, and generalizes across different objects and sensor configurations unseen at training time. Finally, we discuss the implications of our approach for the design of soft visuotactile sensors and grippers.
Discovering Avoidable Planner Failures of Autonomous Vehicles using Counterfactual Analysis in Behaviorally Diverse Simulation
Nov 24, 2020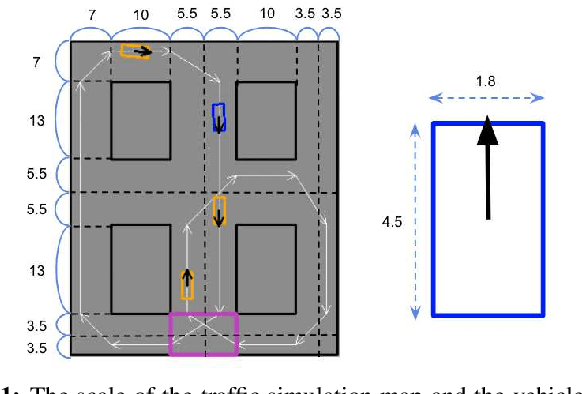
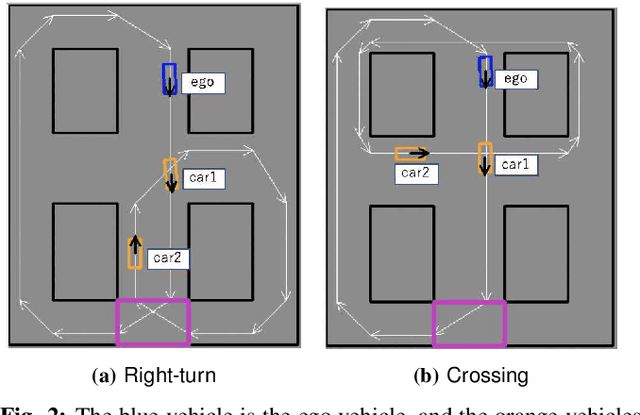
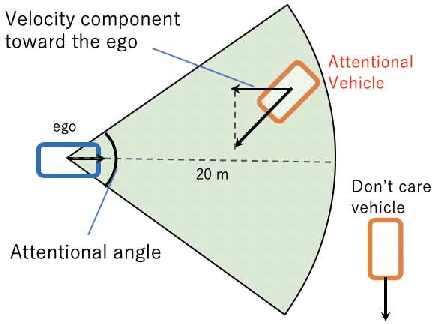
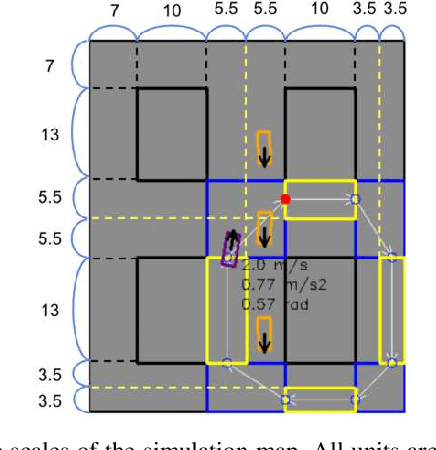
Automated Vehicles require exhaustive testing in simulation to detect as many safety-critical failures as possible before deployment on public roads. In this work, we focus on the core decision-making component of autonomous robots: their planning algorithm. We introduce a planner testing framework that leverages recent progress in simulating behaviorally diverse traffic participants. Using large scale search, we generate, detect, and characterize dynamic scenarios leading to collisions. In particular, we propose methods to distinguish between unavoidable and avoidable accidents, focusing especially on automatically finding planner-specific defects that must be corrected before deployment. Through experiments in complex multi-agent intersection scenarios, we show that our method can indeed find a wide range of critical planner failures.
* 8 pages, 8 figures
Behaviorally Diverse Traffic Simulation via Reinforcement Learning
Nov 11, 2020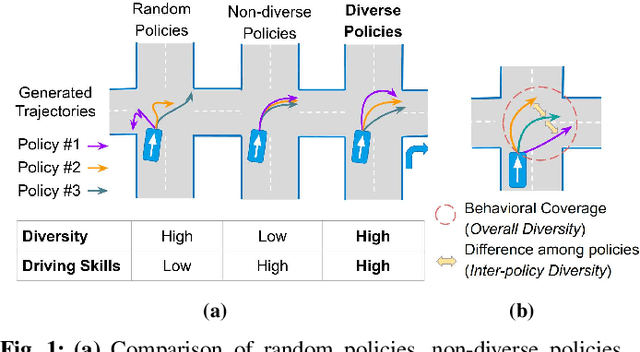
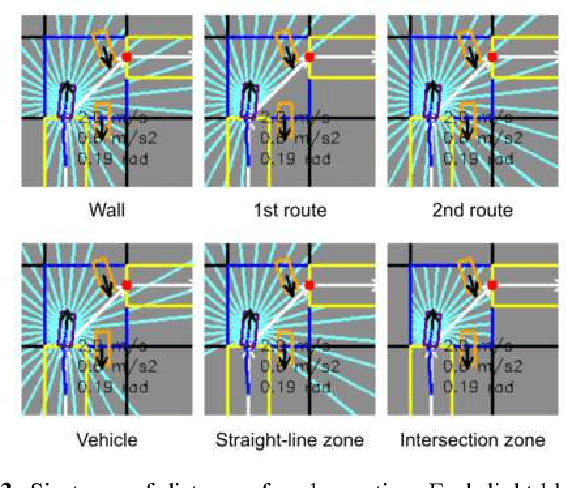
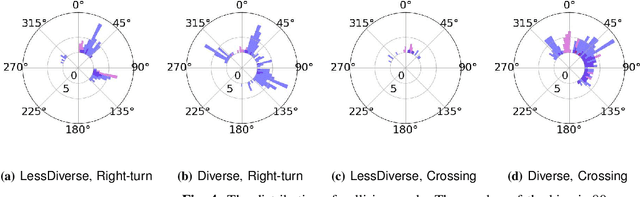
Traffic simulators are important tools in autonomous driving development. While continuous progress has been made to provide developers more options for modeling various traffic participants, tuning these models to increase their behavioral diversity while maintaining quality is often very challenging. This paper introduces an easily-tunable policy generation algorithm for autonomous driving agents. The proposed algorithm balances diversity and driving skills by leveraging the representation and exploration abilities of deep reinforcement learning via a distinct policy set selector. Moreover, we present an algorithm utilizing intrinsic rewards to widen behavioral differences in the training. To provide quantitative assessments, we develop two trajectory-based evaluation metrics which measure the differences among policies and behavioral coverage. We experimentally show the effectiveness of our methods on several challenging intersection scenes.
* 8 pages, 16 figures
RAT iLQR: A Risk Auto-Tuning Controller to Optimally Account for Stochastic Model Mismatch
Oct 16, 2020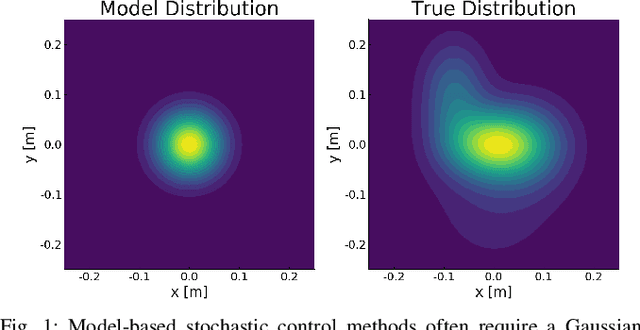
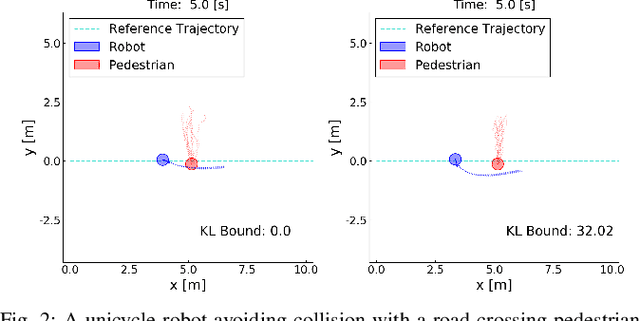
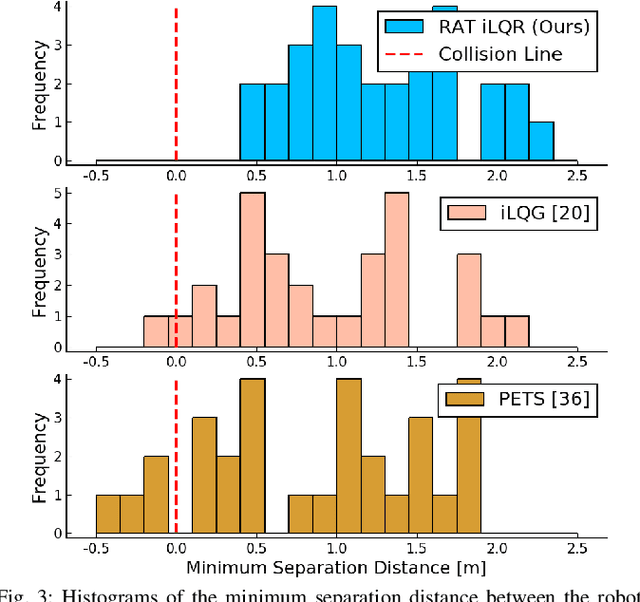
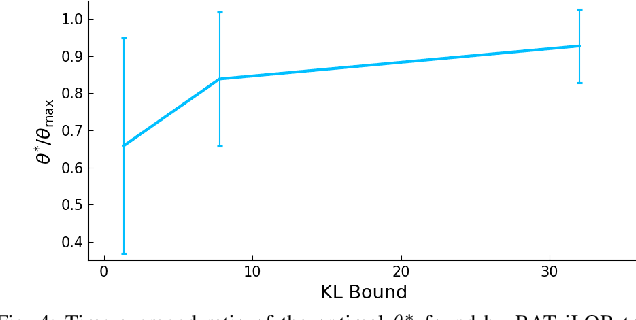
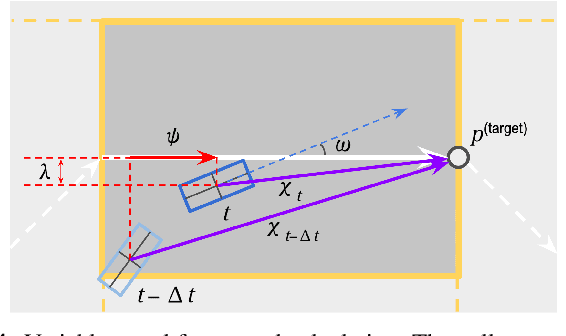
Successful robotic operation in stochastic environments relies on accurate characterization of the underlying probability distributions, yet this is often imperfect due to limited knowledge. This work presents a control algorithm that is capable of handling such distributional mismatches. Specifically, we propose a novel nonlinear MPC for distributionally robust control, which plans locally optimal feedback policies against a worst-case distribution within a given KL divergence bound from a Gaussian distribution. Leveraging mathematical equivalence between distributionally robust control and risk-sensitive optimal control, our framework also provides an algorithm to dynamically adjust the risk-sensitivity level online for risk-sensitive control. The benefits of the distributional robustness as well as the automatic risk-sensitivity adjustment are demonstrated in a dynamic collision avoidance scenario where the predictive distribution of human motion is erroneous.
Monocular Differentiable Rendering for Self-Supervised 3D Object Detection
Sep 30, 2020

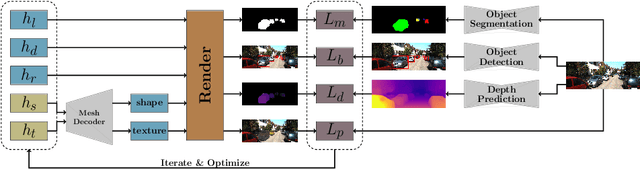
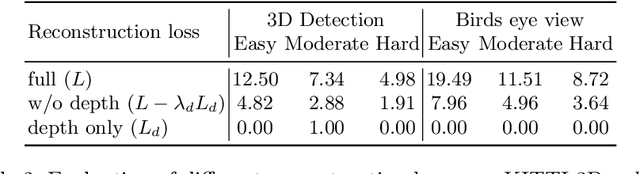
3D object detection from monocular images is an ill-posed problem due to the projective entanglement of depth and scale. To overcome this ambiguity, we present a novel self-supervised method for textured 3D shape reconstruction and pose estimation of rigid objects with the help of strong shape priors and 2D instance masks. Our method predicts the 3D location and meshes of each object in an image using differentiable rendering and a self-supervised objective derived from a pretrained monocular depth estimation network. We use the KITTI 3D object detection dataset to evaluate the accuracy of the method. Experiments demonstrate that we can effectively use noisy monocular depth and differentiable rendering as an alternative to expensive 3D ground-truth labels or LiDAR information.