 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMonocular Differentiable Rendering for Self-Supervised 3D Object Detection
Sep 30, 2020

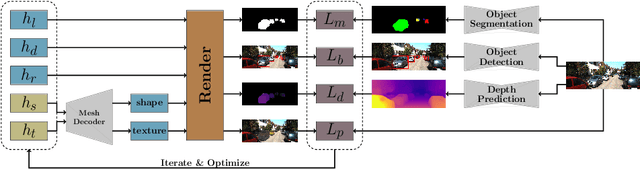
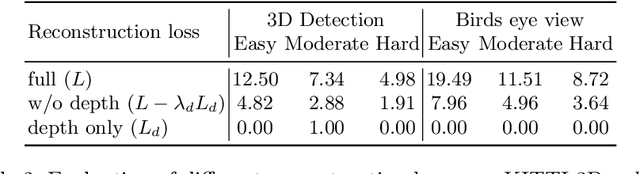
3D object detection from monocular images is an ill-posed problem due to the projective entanglement of depth and scale. To overcome this ambiguity, we present a novel self-supervised method for textured 3D shape reconstruction and pose estimation of rigid objects with the help of strong shape priors and 2D instance masks. Our method predicts the 3D location and meshes of each object in an image using differentiable rendering and a self-supervised objective derived from a pretrained monocular depth estimation network. We use the KITTI 3D object detection dataset to evaluate the accuracy of the method. Experiments demonstrate that we can effectively use noisy monocular depth and differentiable rendering as an alternative to expensive 3D ground-truth labels or LiDAR information.