 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEvaluating the Morphosyntactic Well-formedness of Generated Texts
Mar 30, 2021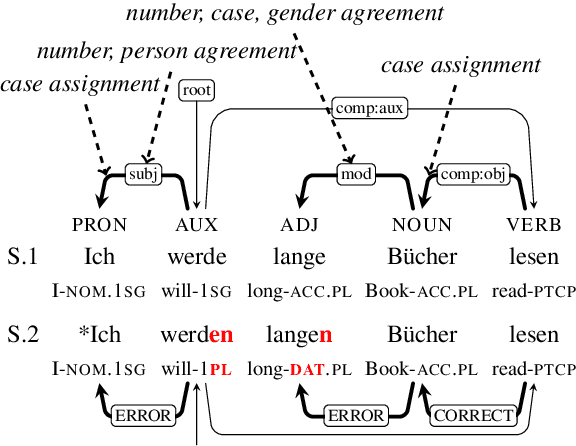

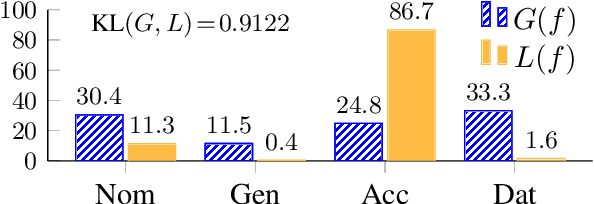

Text generation systems are ubiquitous in natural language processing applications. However, evaluation of these systems remains a challenge, especially in multilingual settings. In this paper, we propose L'AMBRE -- a metric to evaluate the morphosyntactic well-formedness of text using its dependency parse and morphosyntactic rules of the language. We present a way to automatically extract various rules governing morphosyntax directly from dependency treebanks. To tackle the noisy outputs from text generation systems, we propose a simple methodology to train robust parsers. We show the effectiveness of our metric on the task of machine translation through a diachronic study of systems translating into morphologically-rich languages.
Reducing Confusion in Active Learning for Part-Of-Speech Tagging
Nov 02, 2020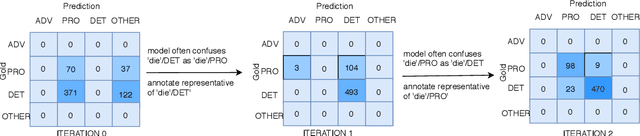

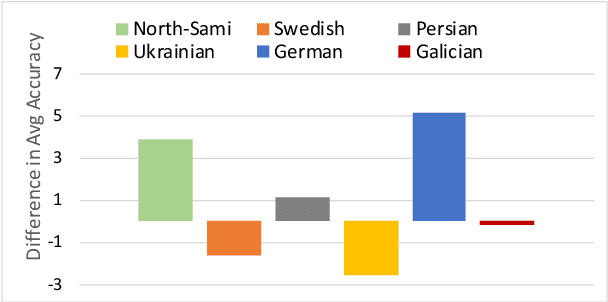

Active learning (AL) uses a data selection algorithm to select useful training samples to minimize annotation cost. This is now an essential tool for building low-resource syntactic analyzers such as part-of-speech (POS) taggers. Existing AL heuristics are generally designed on the principle of selecting uncertain yet representative training instances, where annotating these instances may reduce a large number of errors. However, in an empirical study across six typologically diverse languages (German, Swedish, Galician, North Sami, Persian, and Ukrainian), we found the surprising result that even in an oracle scenario where we know the true uncertainty of predictions, these current heuristics are far from optimal. Based on this analysis, we pose the problem of AL as selecting instances which maximally reduce the confusion between particular pairs of output tags. Extensive experimentation on the aforementioned languages shows that our proposed AL strategy outperforms other AL strategies by a significant margin. We also present auxiliary results demonstrating the importance of proper calibration of models, which we ensure through cross-view training, and analysis demonstrating how our proposed strategy selects examples that more closely follow the oracle data distribution.
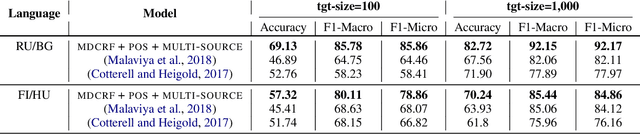
SIGTYP 2020 Shared Task: Prediction of Typological Features
Oct 26, 2020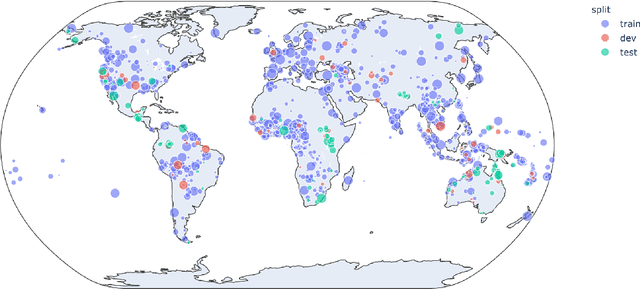

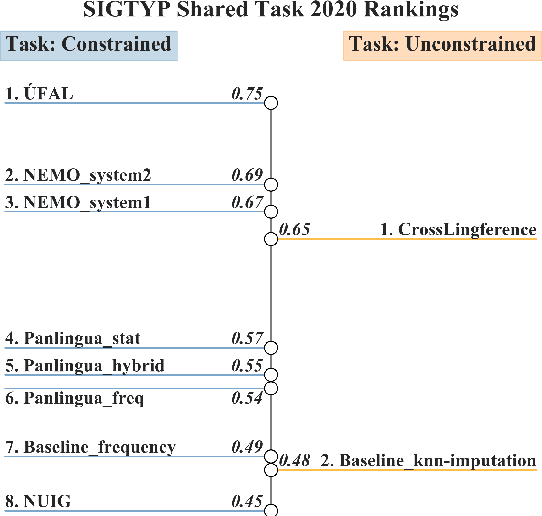
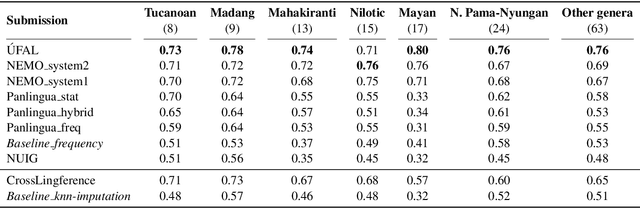
Typological knowledge bases (KBs) such as WALS (Dryer and Haspelmath, 2013) contain information about linguistic properties of the world's languages. They have been shown to be useful for downstream applications, including cross-lingual transfer learning and linguistic probing. A major drawback hampering broader adoption of typological KBs is that they are sparsely populated, in the sense that most languages only have annotations for some features, and skewed, in that few features have wide coverage. As typological features often correlate with one another, it is possible to predict them and thus automatically populate typological KBs, which is also the focus of this shared task. Overall, the task attracted 8 submissions from 5 teams, out of which the most successful methods make use of such feature correlations. However, our error analysis reveals that even the strongest submitted systems struggle with predicting feature values for languages where few features are known.
DICT-MLM: Improved Multilingual Pre-Training using Bilingual Dictionaries
Oct 23, 2020
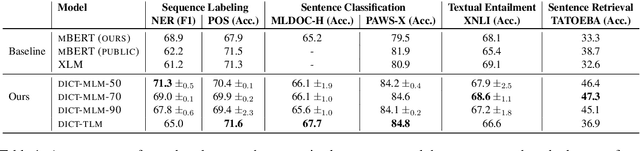
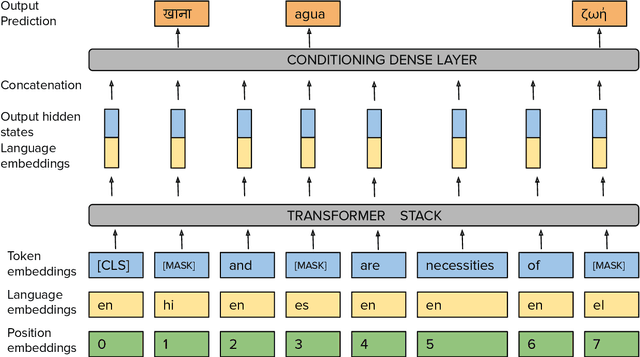
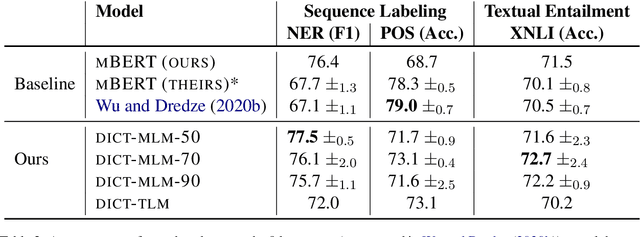
Pre-trained multilingual language models such as mBERT have shown immense gains for several natural language processing (NLP) tasks, especially in the zero-shot cross-lingual setting. Most, if not all, of these pre-trained models rely on the masked-language modeling (MLM) objective as the key language learning objective. The principle behind these approaches is that predicting the masked words with the help of the surrounding text helps learn potent contextualized representations. Despite the strong representation learning capability enabled by MLM, we demonstrate an inherent limitation of MLM for multilingual representation learning. In particular, by requiring the model to predict the language-specific token, the MLM objective disincentivizes learning a language-agnostic representation -- which is a key goal of multilingual pre-training. Therefore to encourage better cross-lingual representation learning we propose the DICT-MLM method. DICT-MLM works by incentivizing the model to be able to predict not just the original masked word, but potentially any of its cross-lingual synonyms as well. Our empirical analysis on multiple downstream tasks spanning 30+ languages, demonstrates the efficacy of the proposed approach and its ability to learn better multilingual representations.
Automatic Extraction of Rules Governing Morphological Agreement
Oct 06, 2020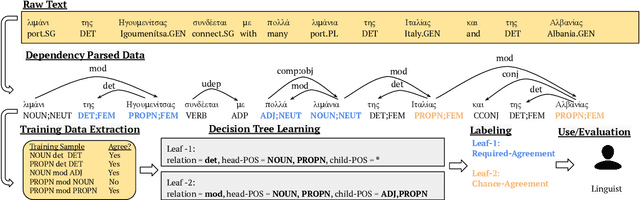
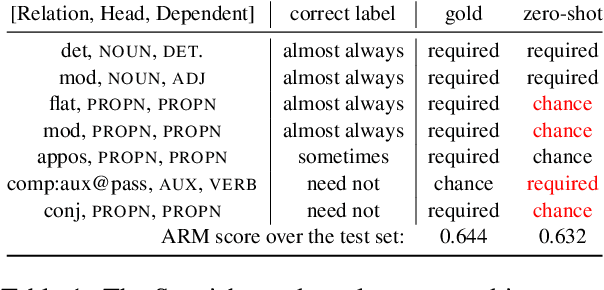
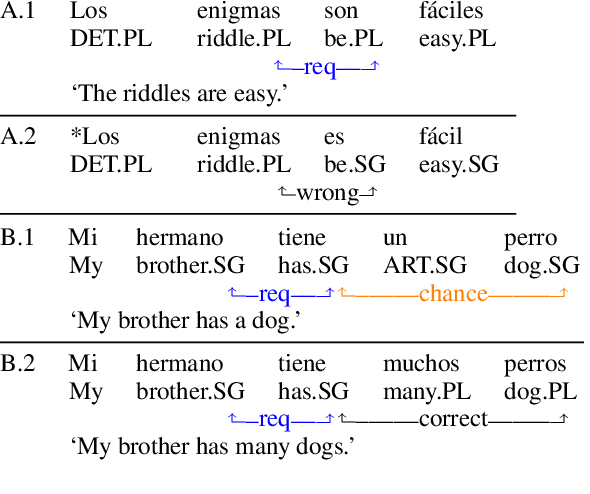
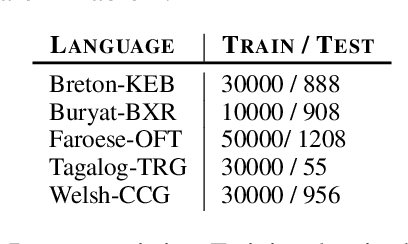
Creating a descriptive grammar of a language is an indispensable step for language documentation and preservation. However, at the same time it is a tedious, time-consuming task. In this paper, we take steps towards automating this process by devising an automated framework for extracting a first-pass grammatical specification from raw text in a concise, human- and machine-readable format. We focus on extracting rules describing agreement, a morphosyntactic phenomenon at the core of the grammars of many of the world's languages. We apply our framework to all languages included in the Universal Dependencies project, with promising results. Using cross-lingual transfer, even with no expert annotations in the language of interest, our framework extracts a grammatical specification which is nearly equivalent to those created with large amounts of gold-standard annotated data. We confirm this finding with human expert evaluations of the rules that our framework produces, which have an average accuracy of 78%. We release an interface demonstrating the extracted rules at https://neulab.github.io/lase/.
A Summary of the First Workshop on Language Technology for Language Documentation and Revitalization
Apr 27, 2020


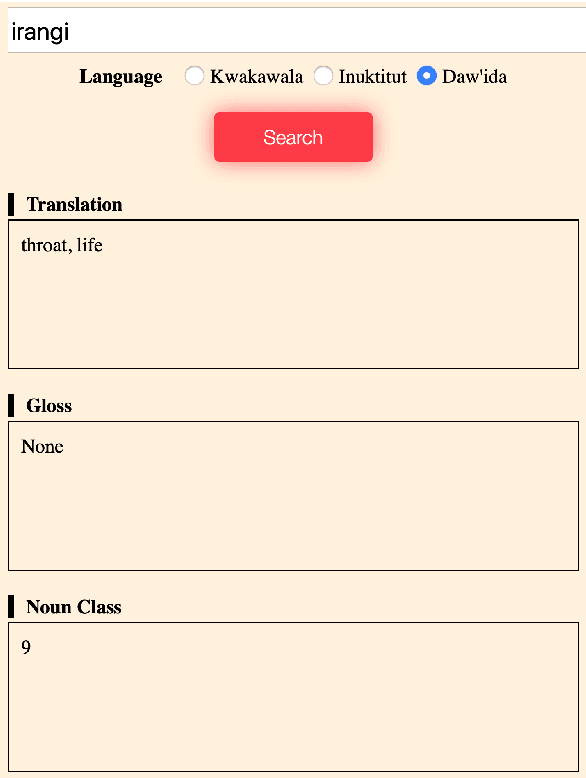
Despite recent advances in natural language processing and other language technology, the application of such technology to language documentation and conservation has been limited. In August 2019, a workshop was held at Carnegie Mellon University in Pittsburgh to attempt to bring together language community members, documentary linguists, and technologists to discuss how to bridge this gap and create prototypes of novel and practical language revitalization technologies. This paper reports the results of this workshop, including issues discussed, and various conceived and implemented technologies for nine languages: Arapaho, Cayuga, Inuktitut, Irish Gaelic, Kidaw'ida, Kwak'wala, Ojibwe, San Juan Quiahije Chatino, and Seneca.
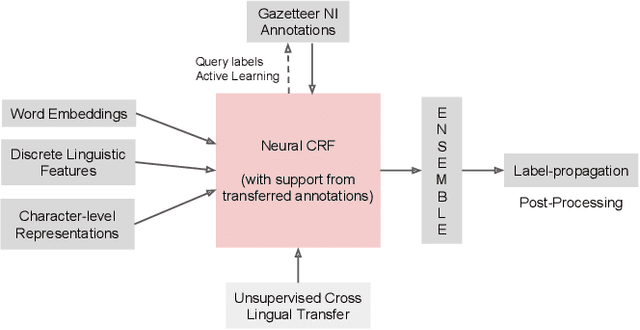
A Little Annotation does a Lot of Good: A Study in Bootstrapping Low-resource Named Entity Recognizers
Aug 23, 2019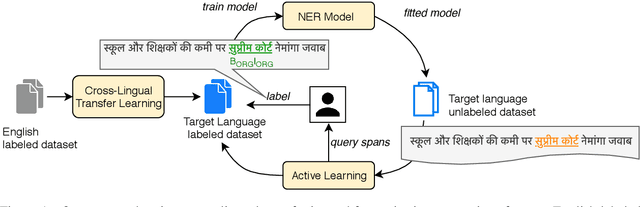
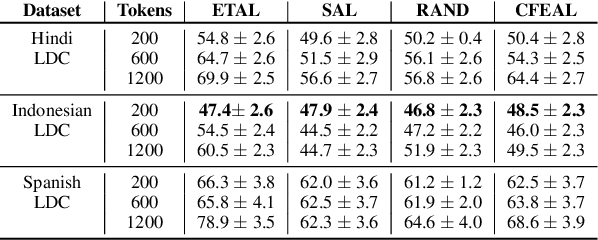
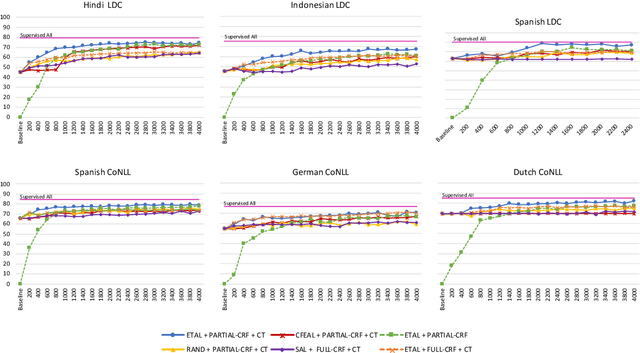
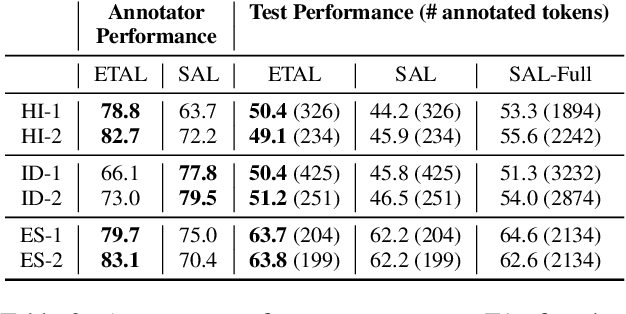
Most state-of-the-art models for named entity recognition (NER) rely on the availability of large amounts of labeled data, making them challenging to extend to new, lower-resourced languages. However, there are now several proposed approaches involving either cross-lingual transfer learning, which learns from other highly resourced languages, or active learning, which efficiently selects effective training data based on model predictions. This paper poses the question: given this recent progress, and limited human annotation, what is the most effective method for efficiently creating high-quality entity recognizers in under-resourced languages? Based on extensive experimentation using both simulated and real human annotation, we find a dual-strategy approach best, starting with a cross-lingual transferred model, then performing targeted annotation of only uncertain entity spans in the target language, minimizing annotator effort. Results demonstrate that cross-lingual transfer is a powerful tool when very little data can be annotated, but an entity-targeted annotation strategy can achieve competitive accuracy quickly, with just one-tenth of training data.
Dr.Quad at MEDIQA 2019: Towards Textual Inference and Question Entailment using contextualized representations
Jul 23, 2019
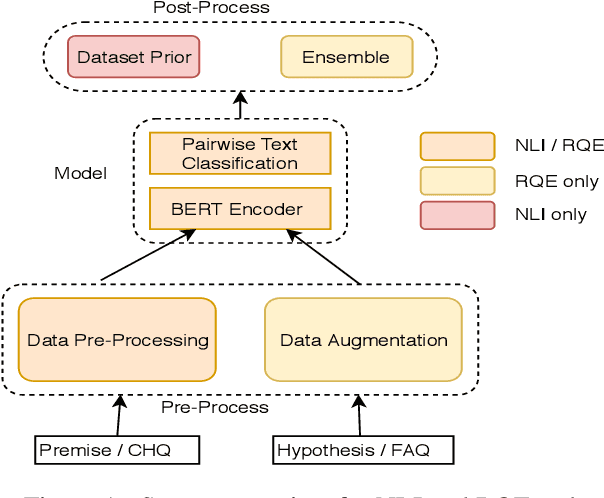

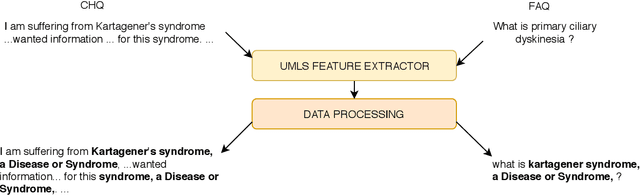
This paper presents the submissions by Team Dr.Quad to the ACL-BioNLP 2019 shared task on Textual Inference and Question Entailment in the Medical Domain. Our system is based on the prior work Liu et al. (2019) which uses a multi-task objective function for textual entailment. In this work, we explore different strategies for generalizing state-of-the-art language understanding models to the specialized medical domain. Our results on the shared task demonstrate that incorporating domain knowledge through data augmentation is a powerful strategy for addressing challenges posed by specialized domains such as medicine.
CMU-01 at the SIGMORPHON 2019 Shared Task on Crosslinguality and Context in Morphology
Jul 23, 2019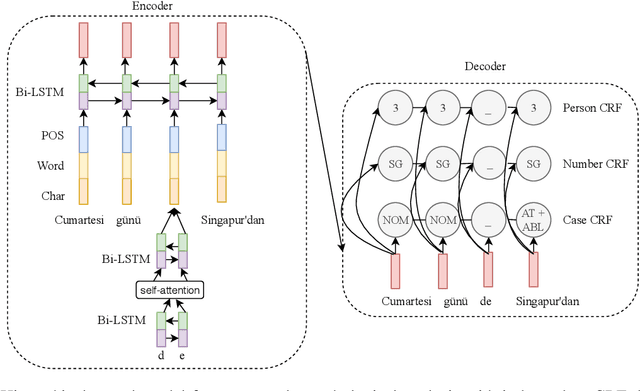
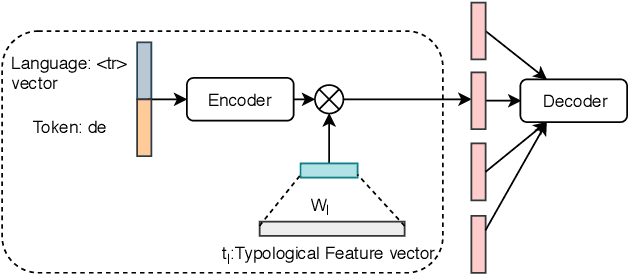
This paper presents the submission by the CMU-01 team to the SIGMORPHON 2019 task 2 of Morphological Analysis and Lemmatization in Context. This task requires us to produce the lemma and morpho-syntactic description of each token in a sequence, for 107 treebanks. We approach this task with a hierarchical neural conditional random field (CRF) model which predicts each coarse-grained feature (eg. POS, Case, etc.) independently. However, most treebanks are under-resourced, thus making it challenging to train deep neural models for them. Hence, we propose a multi-lingual transfer training regime where we transfer from multiple related languages that share similar typology.
The ARIEL-CMU Systems for LoReHLT18
Feb 24, 2019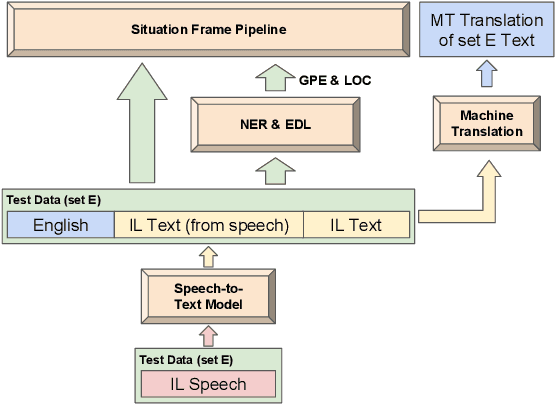
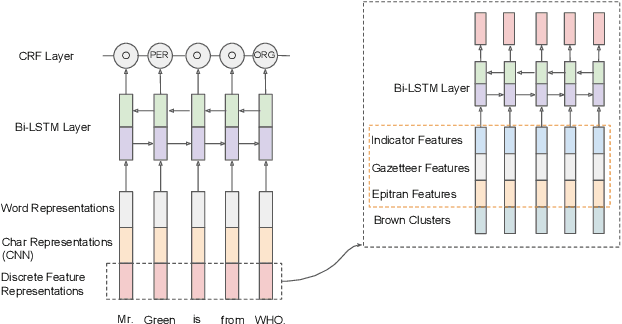
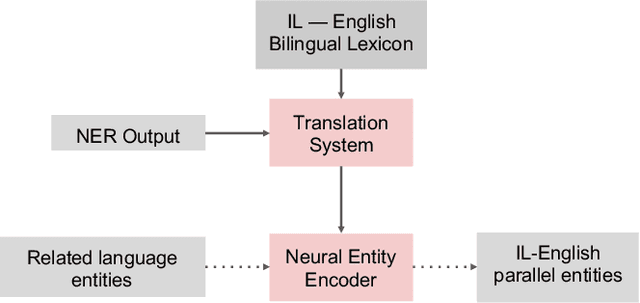
This paper describes the ARIEL-CMU submissions to the Low Resource Human Language Technologies (LoReHLT) 2018 evaluations for the tasks Machine Translation (MT), Entity Discovery and Linking (EDL), and detection of Situation Frames in Text and Speech (SF Text and Speech).