 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDatasetNeRF: Efficient 3D-aware Data Factory with Generative Radiance Fields
Nov 18, 2023



Progress in 3D computer vision tasks demands a huge amount of data, yet annotating multi-view images with 3D-consistent annotations, or point clouds with part segmentation is both time-consuming and challenging. This paper introduces DatasetNeRF, a novel approach capable of generating infinite, high-quality 3D-consistent 2D annotations alongside 3D point cloud segmentations, while utilizing minimal 2D human-labeled annotations. Specifically, we leverage the strong semantic prior within a 3D generative model to train a semantic decoder, requiring only a handful of fine-grained labeled samples. Once trained, the decoder efficiently generalizes across the latent space, enabling the generation of infinite data. The generated data is applicable across various computer vision tasks, including video segmentation and 3D point cloud segmentation. Our approach not only surpasses baseline models in segmentation quality, achieving superior 3D consistency and segmentation precision on individual images, but also demonstrates versatility by being applicable to both articulated and non-articulated generative models. Furthermore, we explore applications stemming from our approach, such as 3D-aware semantic editing and 3D inversion.
3D-Aware Visual Question Answering about Parts, Poses and Occlusions
Oct 27, 2023



Despite rapid progress in Visual question answering (VQA), existing datasets and models mainly focus on testing reasoning in 2D. However, it is important that VQA models also understand the 3D structure of visual scenes, for example to support tasks like navigation or manipulation. This includes an understanding of the 3D object pose, their parts and occlusions. In this work, we introduce the task of 3D-aware VQA, which focuses on challenging questions that require a compositional reasoning over the 3D structure of visual scenes. We address 3D-aware VQA from both the dataset and the model perspective. First, we introduce Super-CLEVR-3D, a compositional reasoning dataset that contains questions about object parts, their 3D poses, and occlusions. Second, we propose PO3D-VQA, a 3D-aware VQA model that marries two powerful ideas: probabilistic neural symbolic program execution for reasoning and deep neural networks with 3D generative representations of objects for robust visual recognition. Our experimental results show our model PO3D-VQA outperforms existing methods significantly, but we still observe a significant performance gap compared to 2D VQA benchmarks, indicating that 3D-aware VQA remains an important open research area.
Animal3D: A Comprehensive Dataset of 3D Animal Pose and Shape
Aug 22, 2023



Accurately estimating the 3D pose and shape is an essential step towards understanding animal behavior, and can potentially benefit many downstream applications, such as wildlife conservation. However, research in this area is held back by the lack of a comprehensive and diverse dataset with high-quality 3D pose and shape annotations. In this paper, we propose Animal3D, the first comprehensive dataset for mammal animal 3D pose and shape estimation. Animal3D consists of 3379 images collected from 40 mammal species, high-quality annotations of 26 keypoints, and importantly the pose and shape parameters of the SMAL model. All annotations were labeled and checked manually in a multi-stage process to ensure highest quality results. Based on the Animal3D dataset, we benchmark representative shape and pose estimation models at: (1) supervised learning from only the Animal3D data, (2) synthetic to real transfer from synthetically generated images, and (3) fine-tuning human pose and shape estimation models. Our experimental results demonstrate that predicting the 3D shape and pose of animals across species remains a very challenging task, despite significant advances in human pose estimation. Our results further demonstrate that synthetic pre-training is a viable strategy to boost the model performance. Overall, Animal3D opens new directions for facilitating future research in animal 3D pose and shape estimation, and is publicly available.
3D-Aware Neural Body Fitting for Occlusion Robust 3D Human Pose Estimation
Aug 19, 2023Regression-based methods for 3D human pose estimation directly predict the 3D pose parameters from a 2D image using deep networks. While achieving state-of-the-art performance on standard benchmarks, their performance degrades under occlusion. In contrast, optimization-based methods fit a parametric body model to 2D features in an iterative manner. The localized reconstruction loss can potentially make them robust to occlusion, but they suffer from the 2D-3D ambiguity. Motivated by the recent success of generative models in rigid object pose estimation, we propose 3D-aware Neural Body Fitting (3DNBF) - an approximate analysis-by-synthesis approach to 3D human pose estimation with SOTA performance and occlusion robustness. In particular, we propose a generative model of deep features based on a volumetric human representation with Gaussian ellipsoidal kernels emitting 3D pose-dependent feature vectors. The neural features are trained with contrastive learning to become 3D-aware and hence to overcome the 2D-3D ambiguity. Experiments show that 3DNBF outperforms other approaches on both occluded and standard benchmarks. Code is available at https://github.com/edz-o/3DNBF
Intriguing Properties of Text-guided Diffusion Models
Jun 18, 2023



Text-guided diffusion models (TDMs) are widely applied but can fail unexpectedly. Common failures include: (i) natural-looking text prompts generating images with the wrong content, or (ii) different random samples of the latent variables that generate vastly different, and even unrelated, outputs despite being conditioned on the same text prompt. In this work, we aim to study and understand the failure modes of TDMs in more detail. To achieve this, we propose SAGE, an adversarial attack on TDMs that uses image classifiers as surrogate loss functions, to search over the discrete prompt space and the high-dimensional latent space of TDMs to automatically discover unexpected behaviors and failure cases in the image generation. We make several technical contributions to ensure that SAGE finds failure cases of the diffusion model, rather than the classifier, and verify this in a human study. Our study reveals four intriguing properties of TDMs that have not been systematically studied before: (1) We find a variety of natural text prompts producing images that fail to capture the semantics of input texts. We categorize these failures into ten distinct types based on the underlying causes. (2) We find samples in the latent space (which are not outliers) that lead to distorted images independent of the text prompt, suggesting that parts of the latent space are not well-structured. (3) We also find latent samples that lead to natural-looking images which are unrelated to the text prompt, implying a potential misalignment between the latent and prompt spaces. (4) By appending a single adversarial token embedding to an input prompt we can generate a variety of specified target objects, while only minimally affecting the CLIP score. This demonstrates the fragility of language representations and raises potential safety concerns.
Adding 3D Geometry Control to Diffusion Models
Jun 13, 2023



Diffusion models have emerged as a powerful method of generative modeling across a range of fields, capable of producing stunning photo-realistic images from natural language descriptions. However, these models lack explicit control over the 3D structure of the objects in the generated images. In this paper, we propose a novel method that incorporates 3D geometry control into diffusion models, making them generate even more realistic and diverse images. To achieve this, our method exploits ControlNet, which extends diffusion models by using visual prompts in addition to text prompts. We generate images of 3D objects taken from a 3D shape repository (e.g., ShapeNet and Objaverse), render them from a variety of poses and viewing directions, compute the edge maps of the rendered images, and use these edge maps as visual prompts to generate realistic images. With explicit 3D geometry control, we can easily change the 3D structures of the objects in the generated images and obtain ground-truth 3D annotations automatically. This allows us to use the generated images to improve a lot of vision tasks, e.g., classification and 3D pose estimation, in both in-distribution (ID) and out-of-distribution (OOD) settings. We demonstrate the effectiveness of our method through extensive experiments on ImageNet-50, ImageNet-R, PASCAL3D+, ObjectNet3D, and OOD-CV datasets. The results show that our method significantly outperforms existing methods across multiple benchmarks (e.g., 4.6 percentage points on ImageNet-50 using ViT and 3.5 percentage points on PASCAL3D+ and ObjectNet3D using NeMo).
AvatarStudio: Text-driven Editing of 3D Dynamic Human Head Avatars
Jun 02, 2023

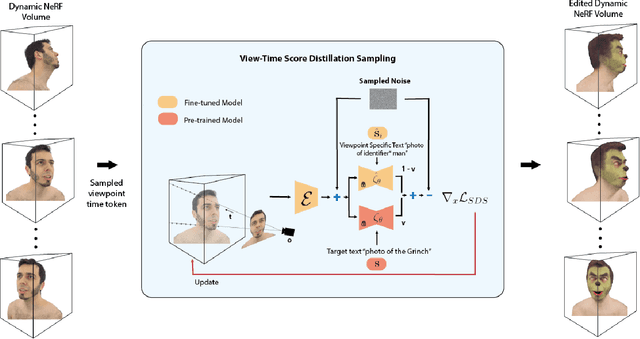
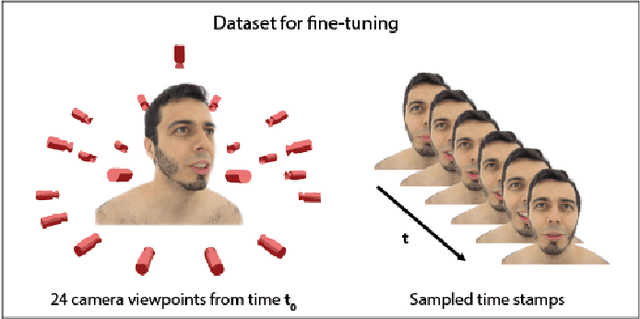
Capturing and editing full head performances enables the creation of virtual characters with various applications such as extended reality and media production. The past few years witnessed a steep rise in the photorealism of human head avatars. Such avatars can be controlled through different input data modalities, including RGB, audio, depth, IMUs and others. While these data modalities provide effective means of control, they mostly focus on editing the head movements such as the facial expressions, head pose and/or camera viewpoint. In this paper, we propose AvatarStudio, a text-based method for editing the appearance of a dynamic full head avatar. Our approach builds on existing work to capture dynamic performances of human heads using neural radiance field (NeRF) and edits this representation with a text-to-image diffusion model. Specifically, we introduce an optimization strategy for incorporating multiple keyframes representing different camera viewpoints and time stamps of a video performance into a single diffusion model. Using this personalized diffusion model, we edit the dynamic NeRF by introducing view-and-time-aware Score Distillation Sampling (VT-SDS) following a model-based guidance approach. Our method edits the full head in a canonical space, and then propagates these edits to remaining time steps via a pretrained deformation network. We evaluate our method visually and numerically via a user study, and results show that our method outperforms existing approaches. Our experiments validate the design choices of our method and highlight that our edits are genuine, personalized, as well as 3D- and time-consistent.
Neural Textured Deformable Meshes for Robust Analysis-by-Synthesis
May 31, 2023Human vision demonstrates higher robustness than current AI algorithms under out-of-distribution scenarios. It has been conjectured such robustness benefits from performing analysis-by-synthesis. Our paper formulates triple vision tasks in a consistent manner using approximate analysis-by-synthesis by render-and-compare algorithms on neural features. In this work, we introduce Neural Textured Deformable Meshes, which involve the object model with deformable geometry that allows optimization on both camera parameters and object geometries. The deformable mesh is parameterized as a neural field, and covered by whole-surface neural texture maps, which are trained to have spatial discriminability. During inference, we extract the feature map of the test image and subsequently optimize the 3D pose and shape parameters of our model using differentiable rendering to best reconstruct the target feature map. We show that our analysis-by-synthesis is much more robust than conventional neural networks when evaluated on real-world images and even in challenging out-of-distribution scenarios, such as occlusion and domain shift. Our algorithms are competitive with standard algorithms when tested on conventional performance measures.
Robust Category-Level 3D Pose Estimation from Synthetic Data
May 25, 2023Obtaining accurate 3D object poses is vital for numerous computer vision applications, such as 3D reconstruction and scene understanding. However, annotating real-world objects is time-consuming and challenging. While synthetically generated training data is a viable alternative, the domain shift between real and synthetic data is a significant challenge. In this work, we aim to narrow the performance gap between models trained on synthetic data and few real images and fully supervised models trained on large-scale data. We achieve this by approaching the problem from two perspectives: 1) We introduce SyntheticP3D, a new synthetic dataset for object pose estimation generated from CAD models and enhanced with a novel algorithm. 2) We propose a novel approach (CC3D) for training neural mesh models that perform pose estimation via inverse rendering. In particular, we exploit the spatial relationships between features on the mesh surface and a contrastive learning scheme to guide the domain adaptation process. Combined, these two approaches enable our models to perform competitively with state-of-the-art models using only 10% of the respective real training images, while outperforming the SOTA model by 10.4% with a threshold of pi/18 using only 50% of the real training data. Our trained model further demonstrates robust generalization to out-of-distribution scenarios despite being trained with minimal real data.
Robust 3D-aware Object Classification via Discriminative Render-and-Compare
May 24, 2023



In real-world applications, it is essential to jointly estimate the 3D object pose and class label of objects, i.e., to perform 3D-aware classification.While current approaches for either image classification or pose estimation can be extended to 3D-aware classification, we observe that they are inherently limited: 1) Their performance is much lower compared to the respective single-task models, and 2) they are not robust in out-of-distribution (OOD) scenarios. Our main contribution is a novel architecture for 3D-aware classification, which builds upon a recent work and performs comparably to single-task models while being highly robust. In our method, an object category is represented as a 3D cuboid mesh composed of feature vectors at each mesh vertex. Using differentiable rendering, we estimate the 3D object pose by minimizing the reconstruction error between the mesh and the feature representation of the target image. Object classification is then performed by comparing the reconstruction losses across object categories. Notably, the neural texture of the mesh is trained in a discriminative manner to enhance the classification performance while also avoiding local optima in the reconstruction loss. Furthermore, we show how our method and feed-forward neural networks can be combined to scale the render-and-compare approach to larger numbers of categories. Our experiments on PASCAL3D+, occluded-PASCAL3D+, and OOD-CV show that our method outperforms all baselines at 3D-aware classification by a wide margin in terms of performance and robustness.