 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeGaussianHeads: End-to-End Learning of Drivable Gaussian Head Avatars from Coarse-to-fine Representations
Sep 18, 2024Real-time rendering of human head avatars is a cornerstone of many computer graphics applications, such as augmented reality, video games, and films, to name a few. Recent approaches address this challenge with computationally efficient geometry primitives in a carefully calibrated multi-view setup. Albeit producing photorealistic head renderings, it often fails to represent complex motion changes such as the mouth interior and strongly varying head poses. We propose a new method to generate highly dynamic and deformable human head avatars from multi-view imagery in real-time. At the core of our method is a hierarchical representation of head models that allows to capture the complex dynamics of facial expressions and head movements. First, with rich facial features extracted from raw input frames, we learn to deform the coarse facial geometry of the template mesh. We then initialize 3D Gaussians on the deformed surface and refine their positions in a fine step. We train this coarse-to-fine facial avatar model along with the head pose as a learnable parameter in an end-to-end framework. This enables not only controllable facial animation via video inputs, but also high-fidelity novel view synthesis of challenging facial expressions, such as tongue deformations and fine-grained teeth structure under large motion changes. Moreover, it encourages the learned head avatar to generalize towards new facial expressions and head poses at inference time. We demonstrate the performance of our method with comparisons against the related methods on different datasets, spanning challenging facial expression sequences across multiple identities. We also show the potential application of our approach by demonstrating a cross-identity facial performance transfer application.
AvatarStudio: Text-driven Editing of 3D Dynamic Human Head Avatars
Jun 02, 2023

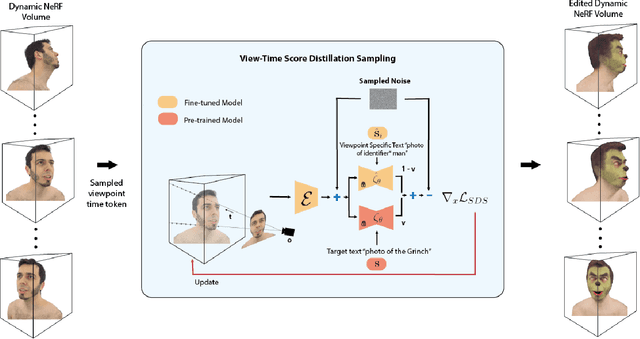
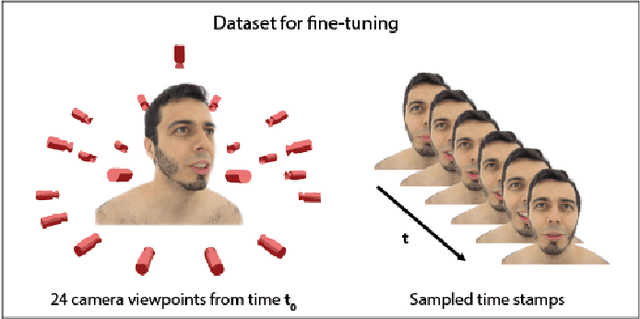
Capturing and editing full head performances enables the creation of virtual characters with various applications such as extended reality and media production. The past few years witnessed a steep rise in the photorealism of human head avatars. Such avatars can be controlled through different input data modalities, including RGB, audio, depth, IMUs and others. While these data modalities provide effective means of control, they mostly focus on editing the head movements such as the facial expressions, head pose and/or camera viewpoint. In this paper, we propose AvatarStudio, a text-based method for editing the appearance of a dynamic full head avatar. Our approach builds on existing work to capture dynamic performances of human heads using neural radiance field (NeRF) and edits this representation with a text-to-image diffusion model. Specifically, we introduce an optimization strategy for incorporating multiple keyframes representing different camera viewpoints and time stamps of a video performance into a single diffusion model. Using this personalized diffusion model, we edit the dynamic NeRF by introducing view-and-time-aware Score Distillation Sampling (VT-SDS) following a model-based guidance approach. Our method edits the full head in a canonical space, and then propagates these edits to remaining time steps via a pretrained deformation network. We evaluate our method visually and numerically via a user study, and results show that our method outperforms existing approaches. Our experiments validate the design choices of our method and highlight that our edits are genuine, personalized, as well as 3D- and time-consistent.
HQ3DAvatar: High Quality Controllable 3D Head Avatar
Mar 25, 2023Multi-view volumetric rendering techniques have recently shown great potential in modeling and synthesizing high-quality head avatars. A common approach to capture full head dynamic performances is to track the underlying geometry using a mesh-based template or 3D cube-based graphics primitives. While these model-based approaches achieve promising results, they often fail to learn complex geometric details such as the mouth interior, hair, and topological changes over time. This paper presents a novel approach to building highly photorealistic digital head avatars. Our method learns a canonical space via an implicit function parameterized by a neural network. It leverages multiresolution hash encoding in the learned feature space, allowing for high-quality, faster training and high-resolution rendering. At test time, our method is driven by a monocular RGB video. Here, an image encoder extracts face-specific features that also condition the learnable canonical space. This encourages deformation-dependent texture variations during training. We also propose a novel optical flow based loss that ensures correspondences in the learned canonical space, thus encouraging artifact-free and temporally consistent renderings. We show results on challenging facial expressions and show free-viewpoint renderings at interactive real-time rates for medium image resolutions. Our method outperforms all existing approaches, both visually and numerically. We will release our multiple-identity dataset to encourage further research. Our Project page is available at: https://vcai.mpi-inf.mpg.de/projects/HQ3DAvatar/