 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAnyTOD: A Programmable Task-Oriented Dialog System
Dec 20, 2022



We propose AnyTOD, an end-to-end task-oriented dialog (TOD) system with zero-shot capability for unseen tasks. We view TOD as a program executed by a language model (LM), where program logic and ontology is provided by a designer in the form of a schema. To enable generalization onto unseen schemas and programs without prior training, AnyTOD adopts a neuro-symbolic approach. A neural LM keeps track of events that occur during a conversation, and a symbolic program implementing the dialog policy is executed to recommend next actions AnyTOD should take. This approach drastically reduces data annotation and model training requirements, addressing a long-standing challenge in TOD research: rapidly adapting a TOD system to unseen tasks and domains. We demonstrate state-of-the-art results on the STAR and ABCD benchmarks, as well as AnyTOD's strong zero-shot transfer capability in low-resource settings. In addition, we release STARv2, an updated version of the STAR dataset with richer data annotations, for benchmarking zero-shot end-to-end TOD models.
Speech Aware Dialog System Technology Challenge (DSTC11)
Dec 16, 2022



Most research on task oriented dialog modeling is based on written text input. However, users interact with practical dialog systems often using speech as input. Typically, systems convert speech into text using an Automatic Speech Recognition (ASR) system, introducing errors. Furthermore, these systems do not address the differences in written and spoken language. The research on this topic is stymied by the lack of a public corpus. Motivated by these considerations, our goal in hosting the speech-aware dialog state tracking challenge was to create a public corpus or task which can be used to investigate the performance gap between the written and spoken forms of input, develop models that could alleviate this gap, and establish whether Text-to-Speech-based (TTS) systems is a reasonable surrogate to the more-labor intensive human data collection. We created three spoken versions of the popular written-domain MultiWoz task -- (a) TTS-Verbatim: written user inputs were converted into speech waveforms using a TTS system, (b) Human-Verbatim: humans spoke the user inputs verbatim, and (c) Human-paraphrased: humans paraphrased the user inputs. Additionally, we provided different forms of ASR output to encourage wider participation from teams that may not have access to state-of-the-art ASR systems. These included ASR transcripts, word time stamps, and latent representations of the audio (audio encoder outputs). In this paper, we describe the corpus, report results from participating teams, provide preliminary analyses of their results, and summarize the current state-of-the-art in this domain.
Beyond the Imitation Game: Quantifying and extrapolating the capabilities of language models
Jun 10, 2022Language models demonstrate both quantitative improvement and new qualitative capabilities with increasing scale. Despite their potentially transformative impact, these new capabilities are as yet poorly characterized. In order to inform future research, prepare for disruptive new model capabilities, and ameliorate socially harmful effects, it is vital that we understand the present and near-future capabilities and limitations of language models. To address this challenge, we introduce the Beyond the Imitation Game benchmark (BIG-bench). BIG-bench currently consists of 204 tasks, contributed by 442 authors across 132 institutions. Task topics are diverse, drawing problems from linguistics, childhood development, math, common-sense reasoning, biology, physics, social bias, software development, and beyond. BIG-bench focuses on tasks that are believed to be beyond the capabilities of current language models. We evaluate the behavior of OpenAI's GPT models, Google-internal dense transformer architectures, and Switch-style sparse transformers on BIG-bench, across model sizes spanning millions to hundreds of billions of parameters. In addition, a team of human expert raters performed all tasks in order to provide a strong baseline. Findings include: model performance and calibration both improve with scale, but are poor in absolute terms (and when compared with rater performance); performance is remarkably similar across model classes, though with benefits from sparsity; tasks that improve gradually and predictably commonly involve a large knowledge or memorization component, whereas tasks that exhibit "breakthrough" behavior at a critical scale often involve multiple steps or components, or brittle metrics; social bias typically increases with scale in settings with ambiguous context, but this can be improved with prompting.
Show, Don't Tell: Demonstrations Outperform Descriptions for Schema-Guided Task-Oriented Dialogue
Apr 08, 2022
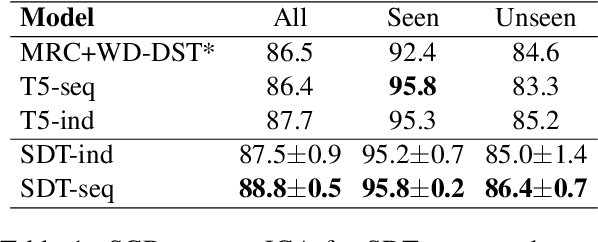
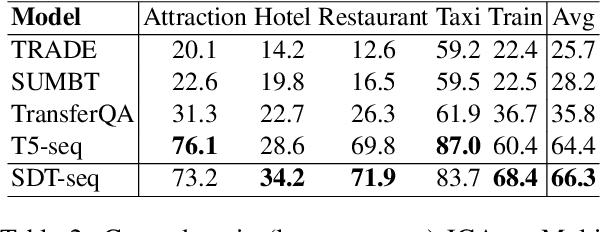

Building universal dialogue systems that can seamlessly operate across multiple domains/APIs and generalize to new ones with minimal supervision and maintenance is a critical challenge. Recent works have leveraged natural language descriptions for schema elements to enable such systems; however, descriptions can only indirectly convey schema semantics. In this work, we propose Show, Don't Tell, a prompt format for seq2seq modeling which uses a short labeled example dialogue to show the semantics of schema elements rather than tell the model via descriptions. While requiring similar effort from service developers, we show that using short examples as schema representations with large language models results in stronger performance and better generalization on two popular dialogue state tracking benchmarks: the Schema-Guided Dialogue dataset and the MultiWoZ leave-one-out benchmark.
A Unified Approach to Entity-Centric Context Tracking in Social Conversations
Jan 28, 2022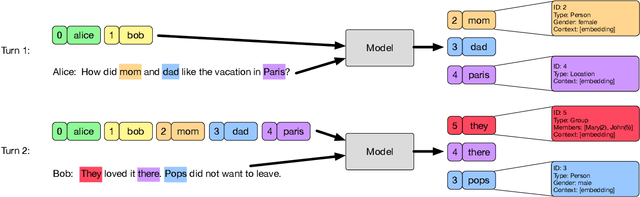
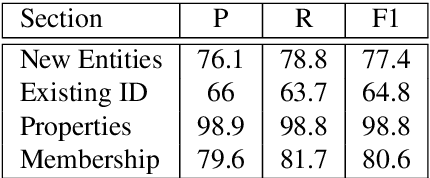
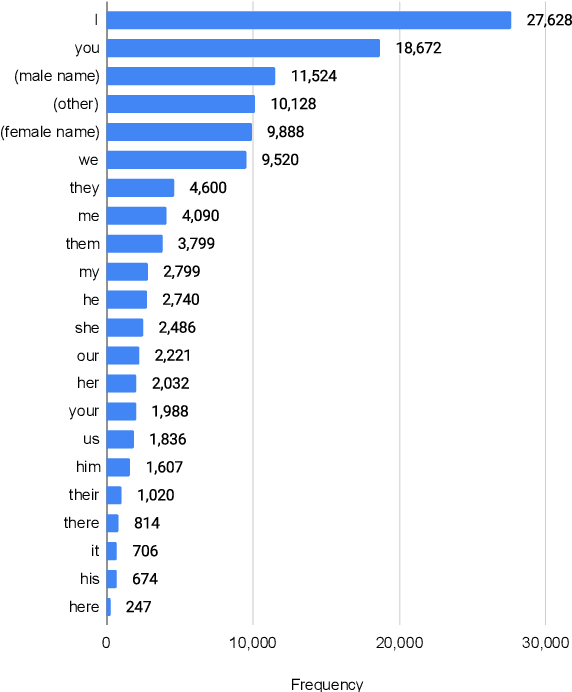
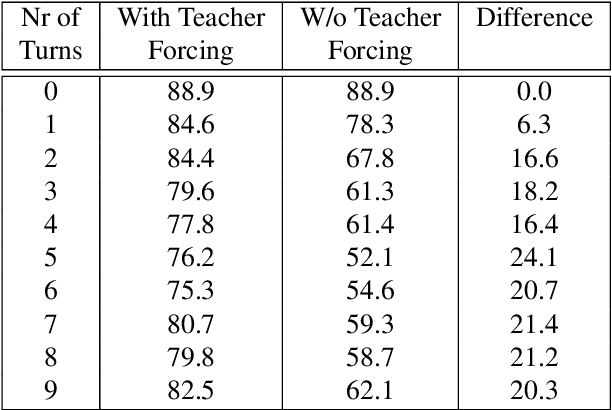
In human-human conversations, Context Tracking deals with identifying important entities and keeping track of their properties and relationships. This is a challenging problem that encompasses several subtasks such as slot tagging, coreference resolution, resolving plural mentions and entity linking. We approach this problem as an end-to-end modeling task where the conversational context is represented by an entity repository containing the entity references mentioned so far, their properties and the relationships between them. The repository is updated turn-by-turn, thus making training and inference computationally efficient even for long conversations. This paper lays the groundwork for an investigation of this framework in two ways. First, we release Contrack, a large scale human-human conversation corpus for context tracking with people and location annotations. It contains over 7000 conversations with an average of 11.8 turns, 5.8 entities and 15.2 references per conversation. Second, we open-source a neural network architecture for context tracking. Finally we compare this network to state-of-the-art approaches for the subtasks it subsumes and report results on the involved tradeoffs.
Description-Driven Task-Oriented Dialog Modeling
Jan 21, 2022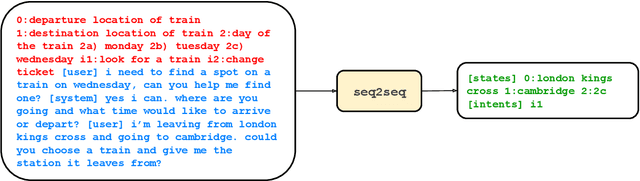

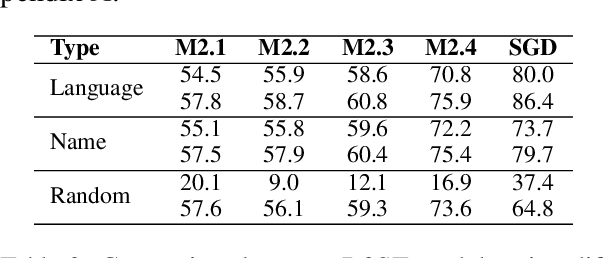

Task-oriented dialogue (TOD) systems are required to identify key information from conversations for the completion of given tasks. Such information is conventionally specified in terms of intents and slots contained in task-specific ontology or schemata. Since these schemata are designed by system developers, the naming convention for slots and intents is not uniform across tasks, and may not convey their semantics effectively. This can lead to models memorizing arbitrary patterns in data, resulting in suboptimal performance and generalization. In this paper, we propose that schemata should be modified by replacing names or notations entirely with natural language descriptions. We show that a language description-driven system exhibits better understanding of task specifications, higher performance on state tracking, improved data efficiency, and effective zero-shot transfer to unseen tasks. Following this paradigm, we present a simple yet effective Description-Driven Dialog State Tracking (D3ST) model, which relies purely on schema descriptions and an "index-picking" mechanism. We demonstrate the superiority in quality, data efficiency and robustness of our approach as measured on the MultiWOZ (Budzianowski et al.,2018), SGD (Rastogi et al., 2020), and the recent SGD-X (Lee et al., 2021) benchmarks.
SGD-X: A Benchmark for Robust Generalization in Schema-Guided Dialogue Systems
Oct 13, 2021
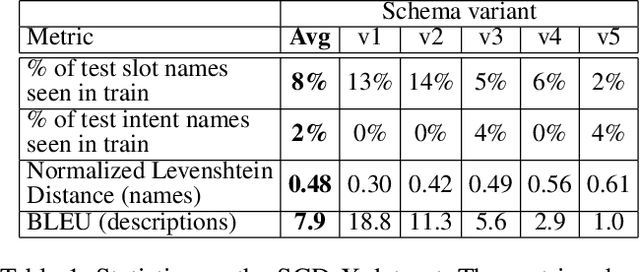
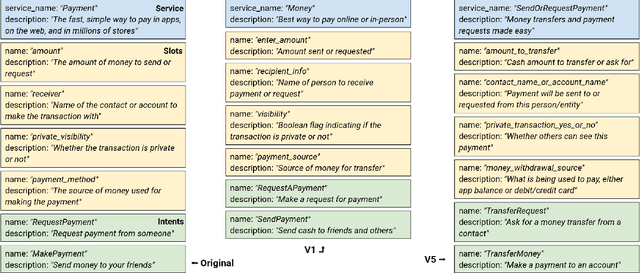
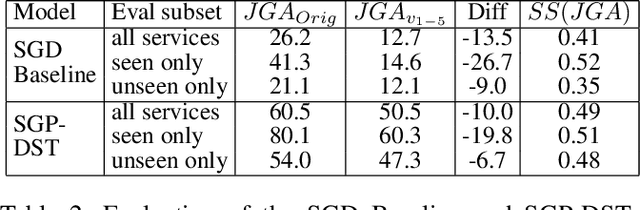
Zero/few-shot transfer to unseen services is a critical challenge in task-oriented dialogue research. The Schema-Guided Dialogue (SGD) dataset introduced a paradigm for enabling models to support an unlimited number of services without additional data collection or re-training through the use of schemas. Schemas describe service APIs in natural language, which models consume to understand the services they need to support. However, the impact of the choice of language in these schemas on model performance remains unexplored. We address this by releasing SGD-X, a benchmark for measuring the robustness of dialogue systems to linguistic variations in schemas. SGD-X extends the SGD dataset with crowdsourced variants for every schema, where variants are semantically similar yet stylistically diverse. We evaluate two dialogue state tracking models on SGD-X and observe that neither generalizes well across schema variations, measured by joint goal accuracy and a novel metric for measuring schema sensitivity. Furthermore, we present a simple model-agnostic data augmentation method to improve schema robustness and zero-shot generalization to unseen services.
UIBert: Learning Generic Multimodal Representations for UI Understanding
Aug 10, 2021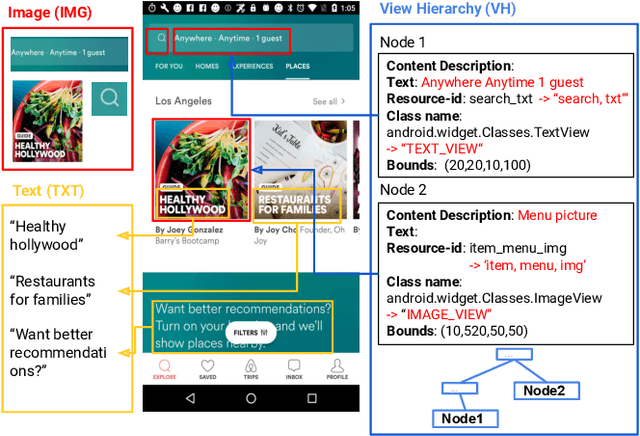
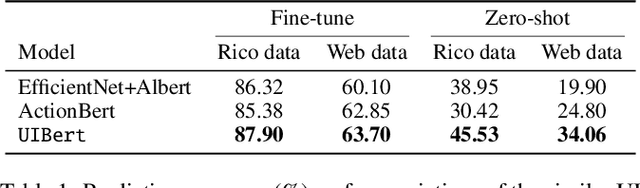
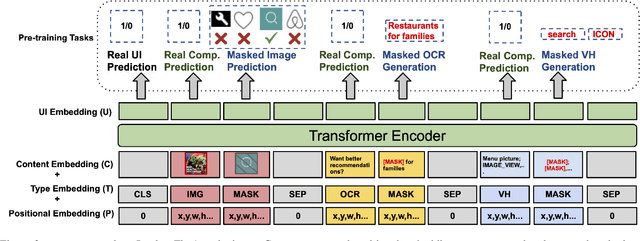
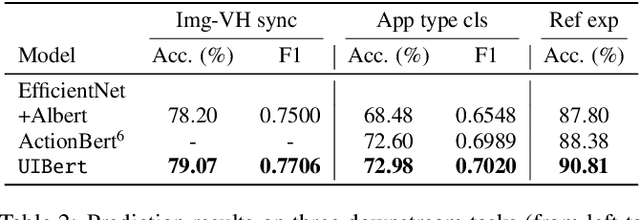
To improve the accessibility of smart devices and to simplify their usage, building models which understand user interfaces (UIs) and assist users to complete their tasks is critical. However, unique challenges are proposed by UI-specific characteristics, such as how to effectively leverage multimodal UI features that involve image, text, and structural metadata and how to achieve good performance when high-quality labeled data is unavailable. To address such challenges we introduce UIBert, a transformer-based joint image-text model trained through novel pre-training tasks on large-scale unlabeled UI data to learn generic feature representations for a UI and its components. Our key intuition is that the heterogeneous features in a UI are self-aligned, i.e., the image and text features of UI components, are predictive of each other. We propose five pretraining tasks utilizing this self-alignment among different features of a UI component and across various components in the same UI. We evaluate our method on nine real-world downstream UI tasks where UIBert outperforms strong multimodal baselines by up to 9.26% accuracy.
Overview of the Ninth Dialog System Technology Challenge: DSTC9
Nov 12, 2020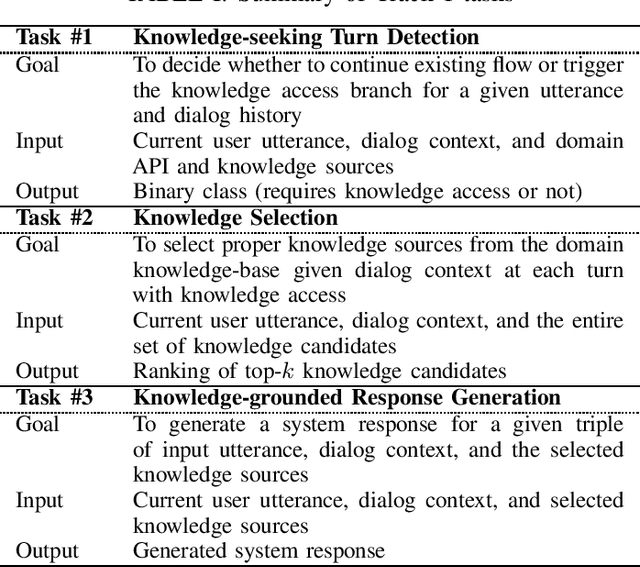
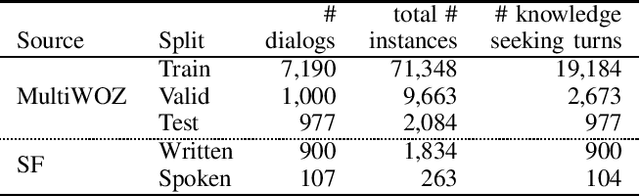

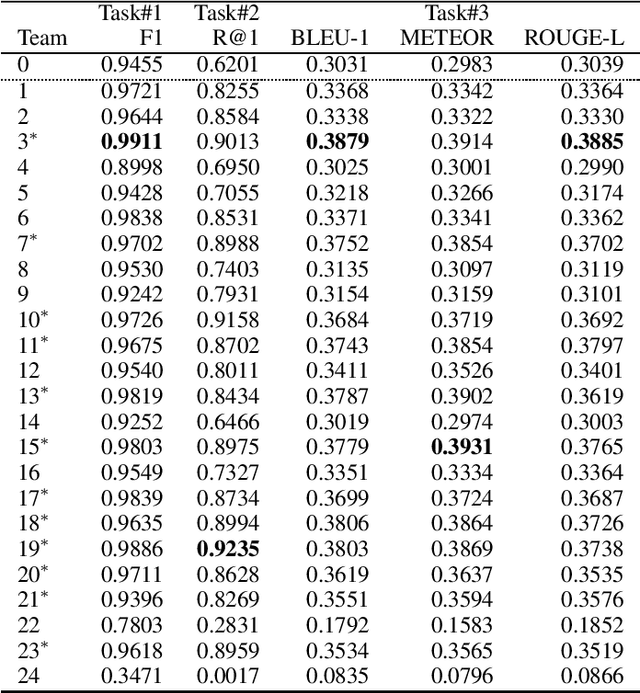
This paper introduces the Ninth Dialog System Technology Challenge (DSTC-9). This edition of the DSTC focuses on applying end-to-end dialog technologies for four distinct tasks in dialog systems, namely, 1. Task-oriented dialog Modeling with unstructured knowledge access, 2. Multi-domain task-oriented dialog, 3. Interactive evaluation of dialog, and 4. Situated interactive multi-modal dialog. This paper describes the task definition, provided datasets, baselines and evaluation set-up for each track. We also summarize the results of the submitted systems to highlight the overall trends of the state-of-the-art technologies for the tasks.
Few-Shot Natural Language Generation by Rewriting Templates
Apr 30, 2020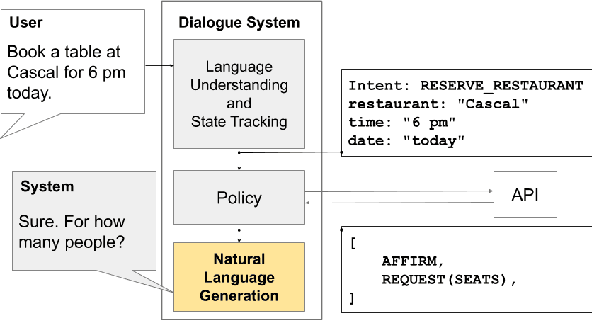
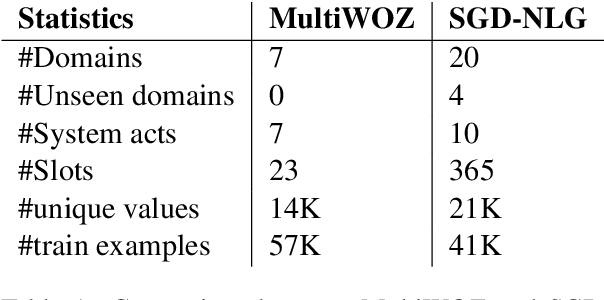
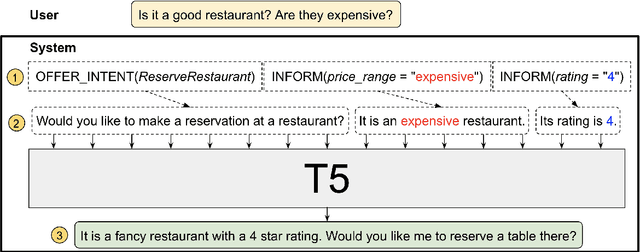
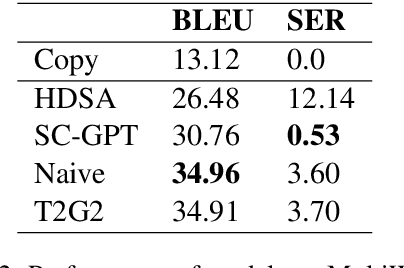
Virtual assistants such as Google Assistant, Alexa and Siri enable users to interact with a large number of services and APIs on the web using natural language. The response generation module converts the actions generated by a policy module into a natural language utterance. Traditionally, template based approaches have been used for response generation in virtual assistants. However, such approaches are not feasible for commercial assistants, which need to support a large number of services. Defining templates for a large number of slot combinations for each of the services supported by large scale assistants becomes tedious. In this work, we propose a template rewriting method for Natural Language Generation (NLG), where the number of templates scales only linearly with the number of slots. A set of simple templates is used to convert actions into utterances, which are concatenated to give a semantically correct, but possibly incoherent and ungrammatical utterance. A pre-trained language model is subsequently employed to rewrite it into coherent, natural sounding text. Through automatic metrics and human evaluation, we show that our method improves over strong baselines, while being much more sample efficient.