 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeUse the Force, Luke! Learning to Predict Physical Forces by Simulating Effects
Mar 26, 2020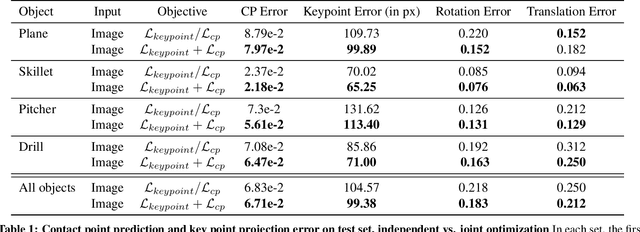
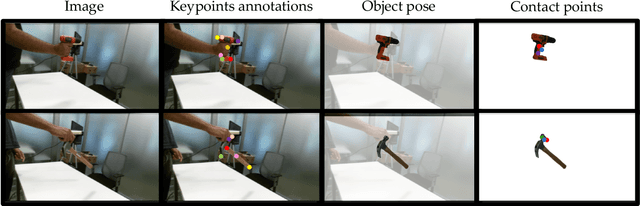

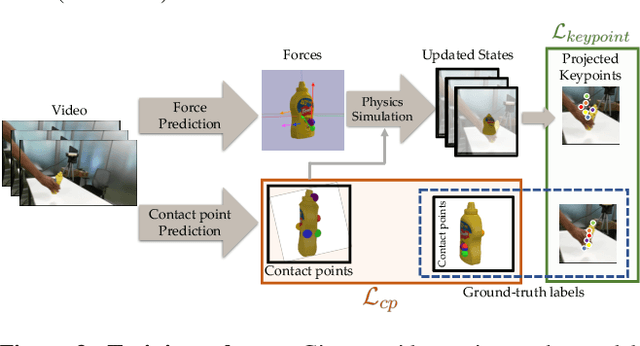
When we humans look at a video of human-object interaction, we can not only infer what is happening but we can even extract actionable information and imitate those interactions. On the other hand, current recognition or geometric approaches lack the physicality of action representation. In this paper, we take a step towards a more physical understanding of actions. We address the problem of inferring contact points and the physical forces from videos of humans interacting with objects. One of the main challenges in tackling this problem is obtaining ground-truth labels for forces. We sidestep this problem by instead using a physics simulator for supervision. Specifically, we use a simulator to predict effects and enforce that estimated forces must lead to the same effect as depicted in the video. Our quantitative and qualitative results show that (a) we can predict meaningful forces from videos whose effects lead to accurate imitation of the motions observed, (b) by jointly optimizing for contact point and force prediction, we can improve the performance on both tasks in comparison to independent training, and (c) we can learn a representation from this model that generalizes to novel objects using few shot examples.
Beyond the Camera: Neural Networks in World Coordinates
Mar 12, 2020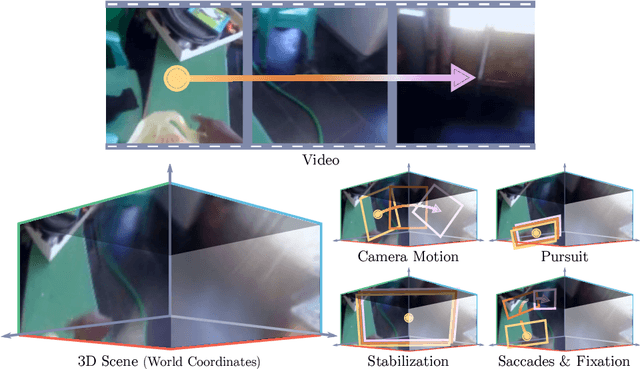
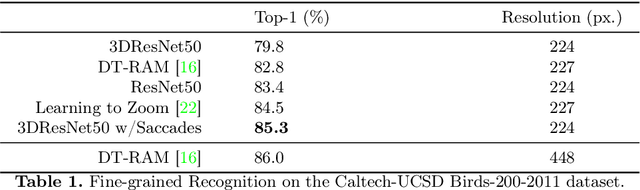
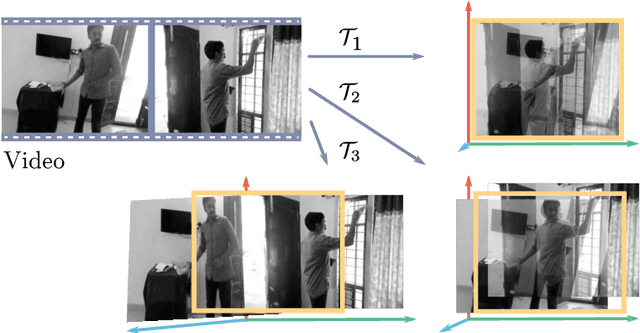

Eye movement and strategic placement of the visual field onto the retina, gives animals increased resolution of the scene and suppresses distracting information. This fundamental system has been missing from video understanding with deep networks, typically limited to 224 by 224 pixel content locked to the camera frame. We propose a simple idea, WorldFeatures, where each feature at every layer has a spatial transformation, and the feature map is only transformed as needed. We show that a network built with these WorldFeatures, can be used to model eye movements, such as saccades, fixation, and smooth pursuit, even in a batch setting on pre-recorded video. That is, the network can for example use all 224 by 224 pixels to look at a small detail one moment, and the whole scene the next. We show that typical building blocks, such as convolutions and pooling, can be adapted to support WorldFeatures using available tools. Experiments are presented on the Charades, Olympic Sports, and Caltech-UCSD Birds-200-2011 datasets, exploring action recognition, fine-grained recognition, and video stabilization.
Intrinsic Motivation for Encouraging Synergistic Behavior
Feb 12, 2020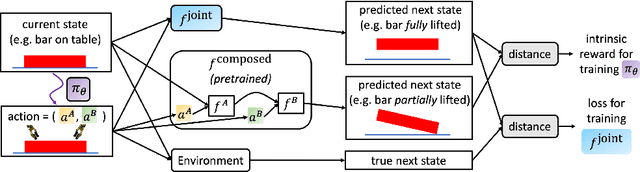

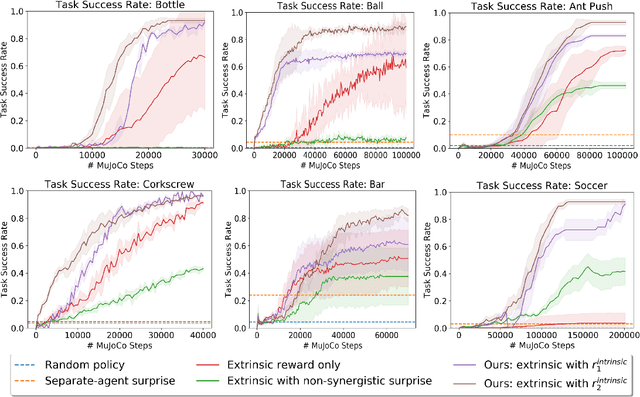
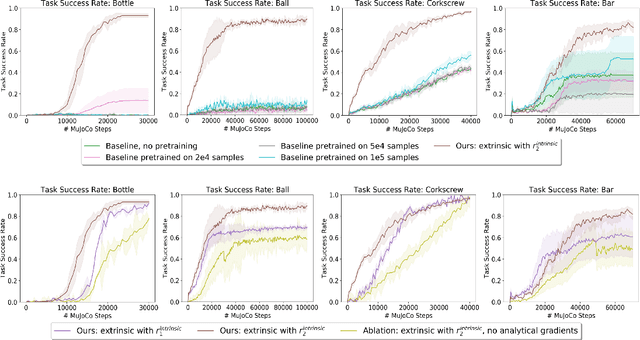
We study the role of intrinsic motivation as an exploration bias for reinforcement learning in sparse-reward synergistic tasks, which are tasks where multiple agents must work together to achieve a goal they could not individually. Our key idea is that a good guiding principle for intrinsic motivation in synergistic tasks is to take actions which affect the world in ways that would not be achieved if the agents were acting on their own. Thus, we propose to incentivize agents to take (joint) actions whose effects cannot be predicted via a composition of the predicted effect for each individual agent. We study two instantiations of this idea, one based on the true states encountered, and another based on a dynamics model trained concurrently with the policy. While the former is simpler, the latter has the benefit of being analytically differentiable with respect to the action taken. We validate our approach in robotic bimanual manipulation and multi-agent locomotion tasks with sparse rewards; we find that our approach yields more efficient learning than both 1) training with only the sparse reward and 2) using the typical surprise-based formulation of intrinsic motivation, which does not bias toward synergistic behavior. Videos are available on the project webpage: https://sites.google.com/view/iclr2020-synergistic.
Exploring Structural Inductive Biases in Emergent Communication
Feb 04, 2020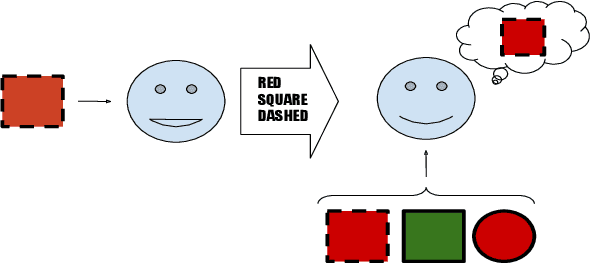
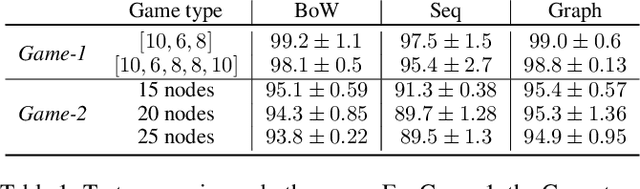
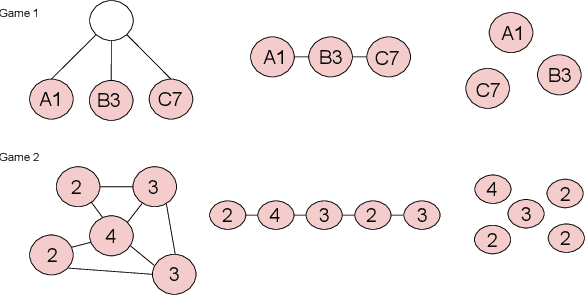
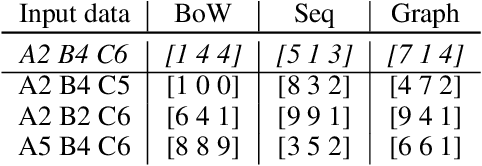
Human language and thought are characterized by the ability to systematically generate a potentially infinite number of complex structures (e.g., sentences) from a finite set of familiar components (e.g., words). Recent works in emergent communication have discussed the propensity of artificial agents to develop a systematically compositional language through playing co-operative referential games. The degree of structure in the input data was found to affect the compositionality of the emerged communication protocols. Thus, we explore various structural priors in multi-agent communication and propose a novel graph referential game. We compare the effect of structural inductive bias (bag-of-words, sequences and graphs) on the emergence of compositional understanding of the input concepts measured by topographic similarity and generalization to unseen combinations of familiar properties. We empirically show that graph neural networks induce a better compositional language prior and a stronger generalization to out-of-domain data. We further perform ablation studies that show the robustness of the emerged protocol in graph referential games.
Towards Graph Representation Learning in Emergent Communication
Feb 04, 2020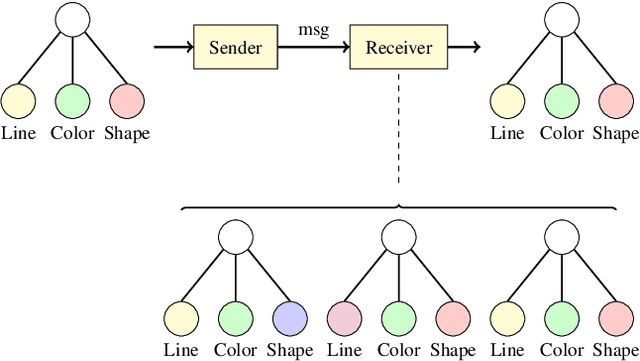

Recent findings in neuroscience suggest that the human brain represents information in a geometric structure (for instance, through conceptual spaces). In order to communicate, we flatten the complex representation of entities and their attributes into a single word or a sentence. In this paper we use graph convolutional networks to support the evolution of language and cooperation in multi-agent systems. Motivated by an image-based referential game, we propose a graph referential game with varying degrees of complexity, and we provide strong baseline models that exhibit desirable properties in terms of language emergence and cooperation. We show that the emerged communication protocol is robust, that the agents uncover the true factors of variation in the game, and that they learn to generalize beyond the samples encountered during training.
On the interaction between supervision and self-play in emergent communication
Feb 04, 2020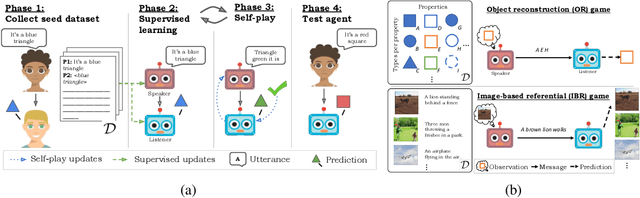
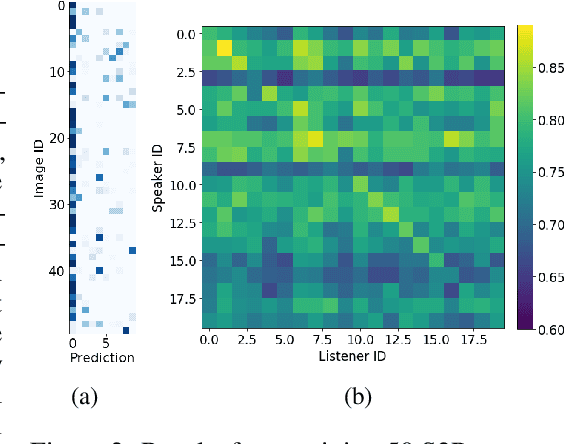
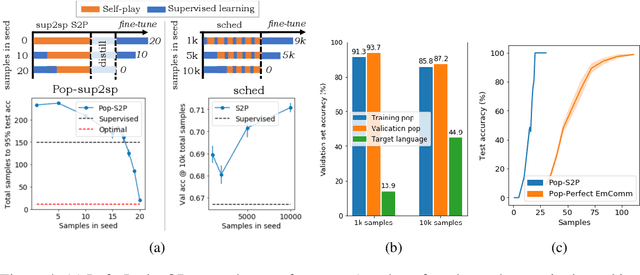
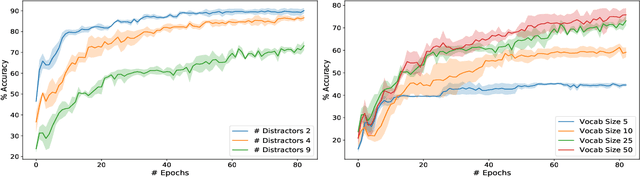
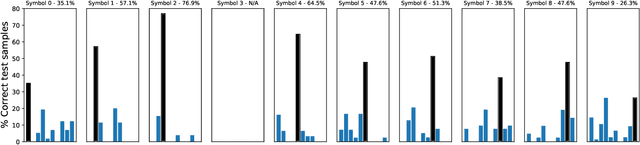
A promising approach for teaching artificial agents to use natural language involves using human-in-the-loop training. However, recent work suggests that current machine learning methods are too data inefficient to be trained in this way from scratch. In this paper, we investigate the relationship between two categories of learning signals with the ultimate goal of improving sample efficiency: imitating human language data via supervised learning, and maximizing reward in a simulated multi-agent environment via self-play (as done in emergent communication), and introduce the term supervised self-play (S2P) for algorithms using both of these signals. We find that first training agents via supervised learning on human data followed by self-play outperforms the converse, suggesting that it is not beneficial to emerge languages from scratch. We then empirically investigate various S2P schedules that begin with supervised learning in two environments: a Lewis signaling game with symbolic inputs, and an image-based referential game with natural language descriptions. Lastly, we introduce population based approaches to S2P, which further improves the performance over single-agent methods.
ClusterFit: Improving Generalization of Visual Representations
Dec 06, 2019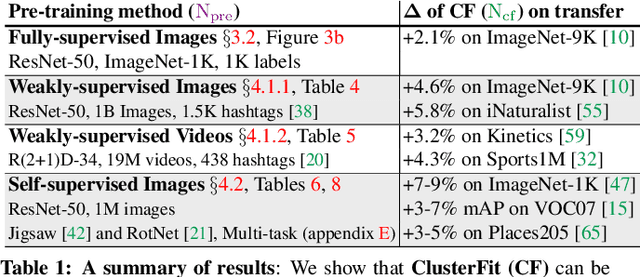
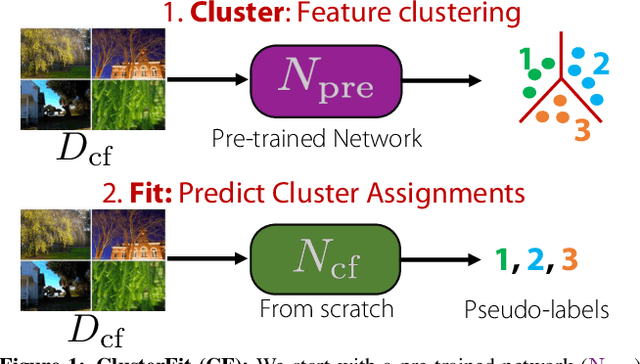
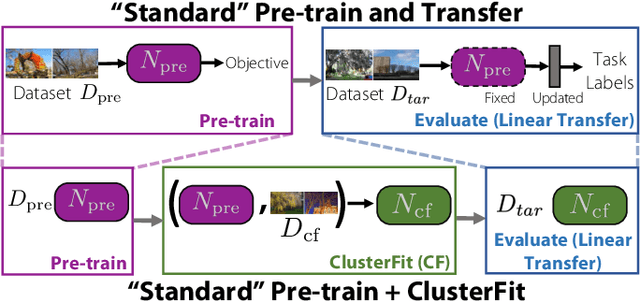
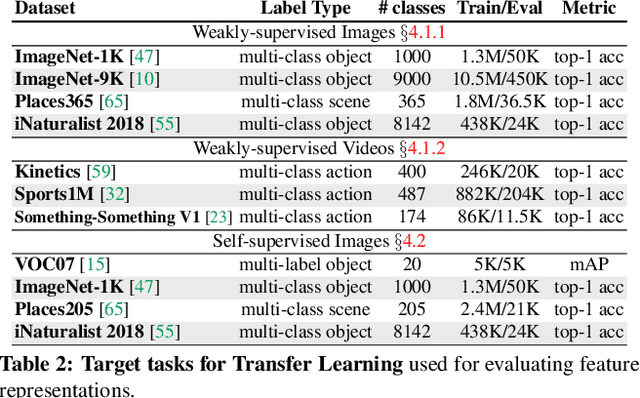
Pre-training convolutional neural networks with weakly-supervised and self-supervised strategies is becoming increasingly popular for several computer vision tasks. However, due to the lack of strong discriminative signals, these learned representations may overfit to the pre-training objective (e.g., hashtag prediction) and not generalize well to downstream tasks. In this work, we present a simple strategy - ClusterFit (CF) to improve the robustness of the visual representations learned during pre-training. Given a dataset, we (a) cluster its features extracted from a pre-trained network using k-means and (b) re-train a new network from scratch on this dataset using cluster assignments as pseudo-labels. We empirically show that clustering helps reduce the pre-training task-specific information from the extracted features thereby minimizing overfitting to the same. Our approach is extensible to different pre-training frameworks -- weak- and self-supervised, modalities -- images and videos, and pre-training tasks -- object and action classification. Through extensive transfer learning experiments on 11 different target datasets of varied vocabularies and granularities, we show that ClusterFit significantly improves the representation quality compared to the state-of-the-art large-scale (millions / billions) weakly-supervised image and video models and self-supervised image models.
Third-Person Visual Imitation Learning via Decoupled Hierarchical Controller
Nov 21, 2019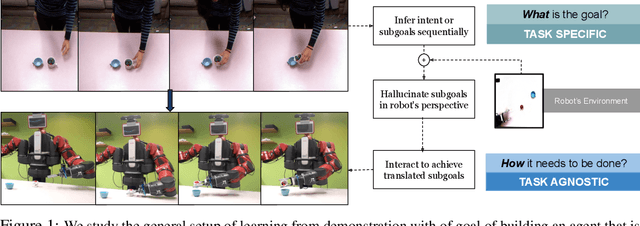

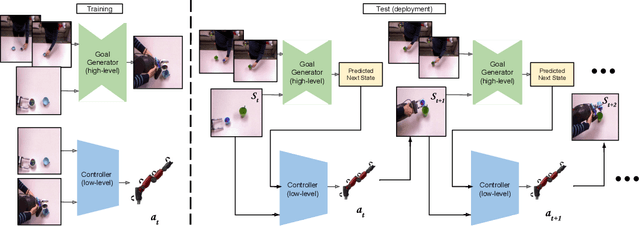
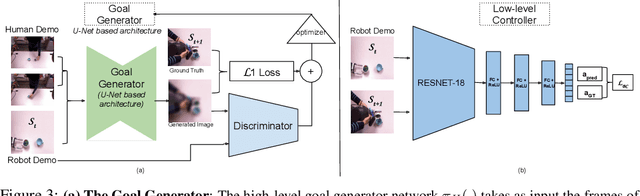
We study a generalized setup for learning from demonstration to build an agent that can manipulate novel objects in unseen scenarios by looking at only a single video of human demonstration from a third-person perspective. To accomplish this goal, our agent should not only learn to understand the intent of the demonstrated third-person video in its context but also perform the intended task in its environment configuration. Our central insight is to enforce this structure explicitly during learning by decoupling what to achieve (intended task) from how to perform it (controller). We propose a hierarchical setup where a high-level module learns to generate a series of first-person sub-goals conditioned on the third-person video demonstration, and a low-level controller predicts the actions to achieve those sub-goals. Our agent acts from raw image observations without any access to the full state information. We show results on a real robotic platform using Baxter for the manipulation tasks of pouring and placing objects in a box. Project video and code are at https://pathak22.github.io/hierarchical-imitation/
Capacity, Bandwidth, and Compositionality in Emergent Language Learning
Oct 24, 2019
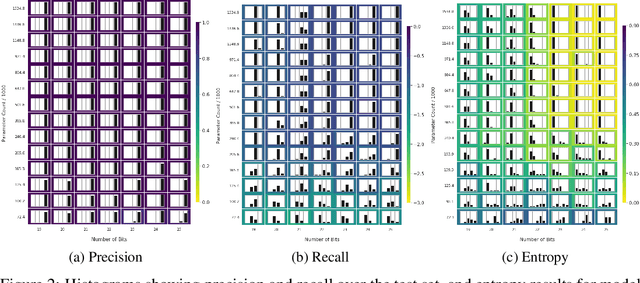
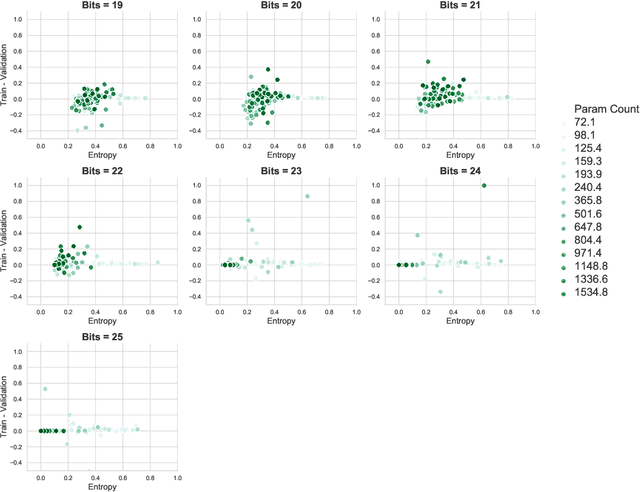
Many recent works have discussed the propensity, or lack thereof, for emergent languages to exhibit properties of natural languages. A favorite in the literature is learning compositionality. We note that most of those works have focused on communicative bandwidth as being of primary importance. While important, it is not the only contributing factor. In this paper, we investigate the learning biases that affect the efficacy and compositionality of emergent languages. Our foremost contribution is to explore how capacity of a neural network impacts its ability to learn a compositional language. We additionally introduce a set of evaluation metrics with which we analyze the learned languages. Our hypothesis is that there should be a specific range of model capacity and channel bandwidth that induces compositional structure in the resulting language and consequently encourages systematic generalization. While we empirically see evidence for the bottom of this range, we curiously do not find evidence for the top part of the range and believe that this is an open question for the community.
Object-centric Forward Modeling for Model Predictive Control
Oct 08, 2019
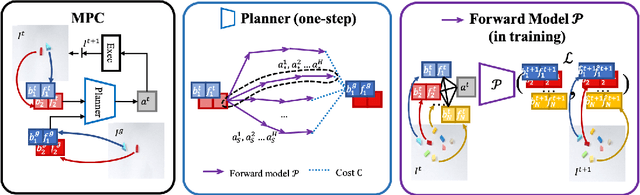

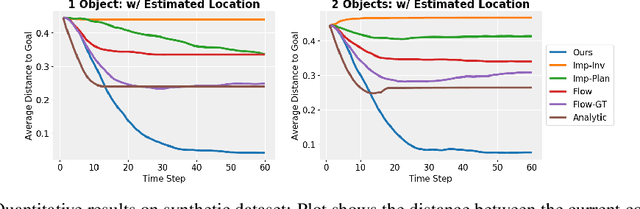
We present an approach to learn an object-centric forward model, and show that this allows us to plan for sequences of actions to achieve distant desired goals. We propose to model a scene as a collection of objects, each with an explicit spatial location and implicit visual feature, and learn to model the effects of actions using random interaction data. Our model allows capturing the robot-object and object-object interactions, and leads to more sample-efficient and accurate predictions. We show that this learned model can be leveraged to search for action sequences that lead to desired goal configurations, and that in conjunction with a learned correction module, this allows for robust closed loop execution. We present experiments both in simulation and the real world, and show that our approach improves over alternate implicit or pixel-space forward models. Please see our project page (https://judyye.github.io/ocmpc/) for result videos.