 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLearning to Grasp Without Seeing
May 10, 2018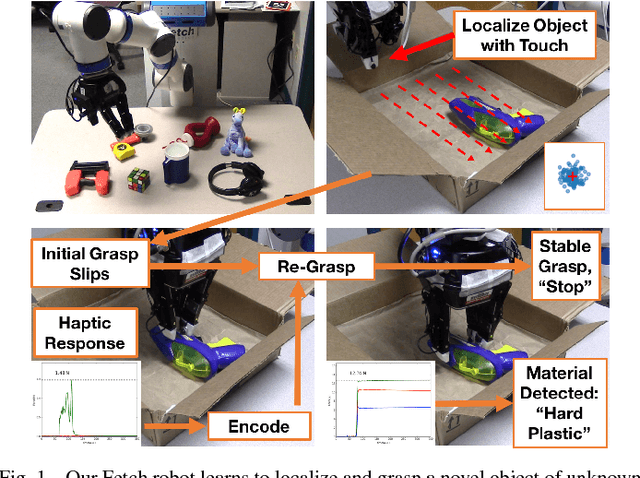
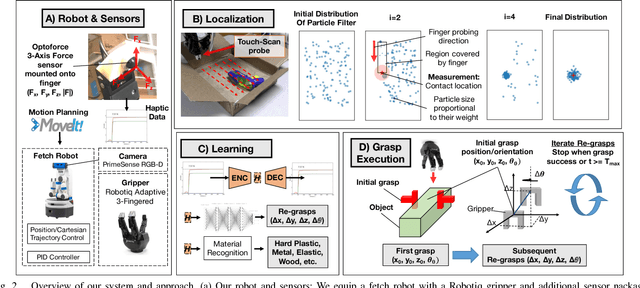
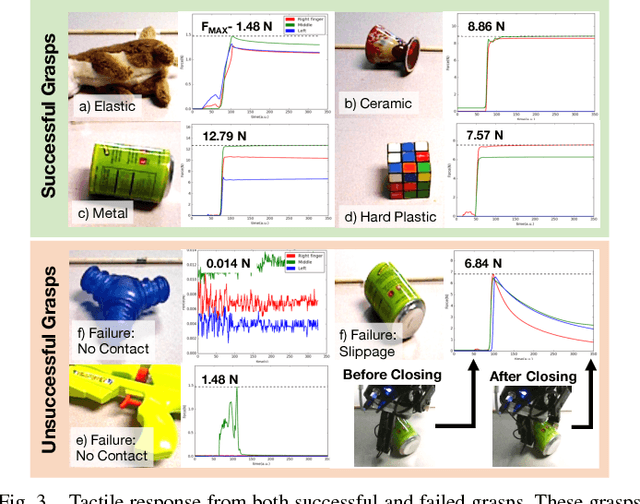
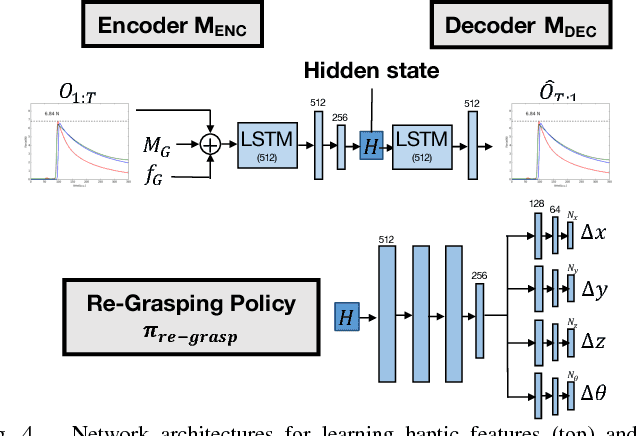
Can a robot grasp an unknown object without seeing it? In this paper, we present a tactile-sensing based approach to this challenging problem of grasping novel objects without prior knowledge of their location or physical properties. Our key idea is to combine touch based object localization with tactile based re-grasping. To train our learning models, we created a large-scale grasping dataset, including more than 30 RGB frames and over 2.8 million tactile samples from 7800 grasp interactions of 52 objects. To learn a representation of tactile signals, we propose an unsupervised auto-encoding scheme, which shows a significant improvement of 4-9% over prior methods on a variety of tactile perception tasks. Our system consists of two steps. First, our touch localization model sequentially 'touch-scans' the workspace and uses a particle filter to aggregate beliefs from multiple hits of the target. It outputs an estimate of the object's location, from which an initial grasp is established. Next, our re-grasping model learns to progressively improve grasps with tactile feedback based on the learned features. This network learns to estimate grasp stability and predict adjustment for the next grasp. Re-grasping thus is performed iteratively until our model identifies a stable grasp. Finally, we demonstrate extensive experimental results on grasping a large set of novel objects using tactile sensing alone. Furthermore, when applied on top of a vision-based policy, our re-grasping model significantly boosts the overall accuracy by 10.6%. We believe this is the first attempt at learning to grasp with only tactile sensing and without any prior object knowledge.
Charades-Ego: A Large-Scale Dataset of Paired Third and First Person Videos
Apr 30, 2018

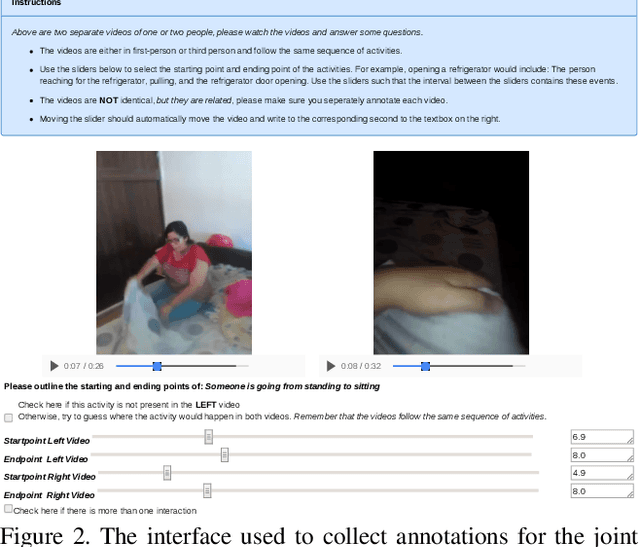

In Actor and Observer we introduced a dataset linking the first and third-person video understanding domains, the Charades-Ego Dataset. In this paper we describe the egocentric aspect of the dataset and present annotations for Charades-Ego with 68,536 activity instances in 68.8 hours of first and third-person video, making it one of the largest and most diverse egocentric datasets available. Charades-Ego furthermore shares activity classes, scripts, and methodology with the Charades dataset, that consist of additional 82.3 hours of third-person video with 66,500 activity instances. Charades-Ego has temporal annotations and textual descriptions, making it suitable for egocentric video classification, localization, captioning, and new tasks utilizing the cross-modal nature of the data.
Actor and Observer: Joint Modeling of First and Third-Person Videos
Apr 25, 2018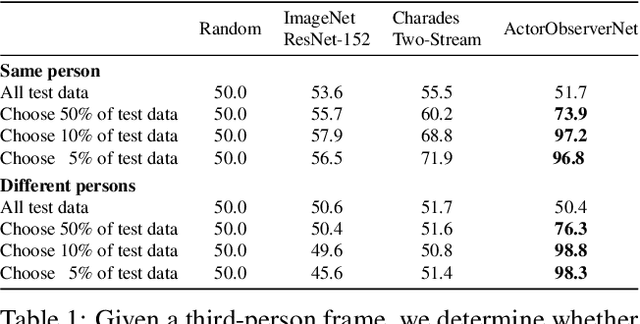


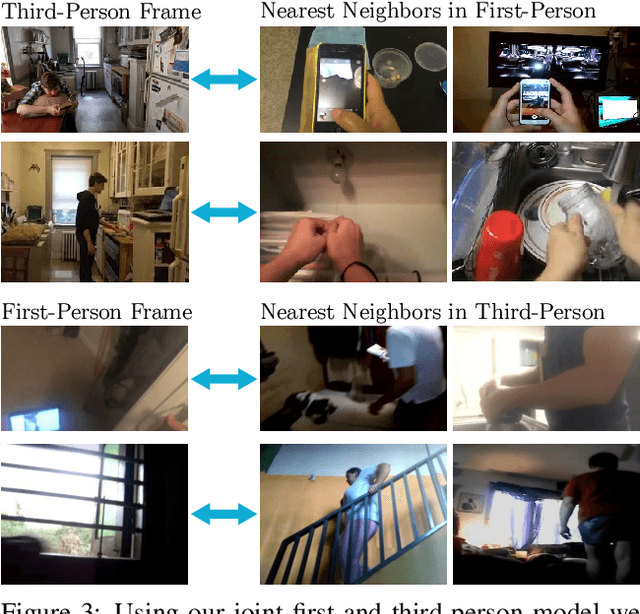
Several theories in cognitive neuroscience suggest that when people interact with the world, or simulate interactions, they do so from a first-person egocentric perspective, and seamlessly transfer knowledge between third-person (observer) and first-person (actor). Despite this, learning such models for human action recognition has not been achievable due to the lack of data. This paper takes a step in this direction, with the introduction of Charades-Ego, a large-scale dataset of paired first-person and third-person videos, involving 112 people, with 4000 paired videos. This enables learning the link between the two, actor and observer perspectives. Thereby, we address one of the biggest bottlenecks facing egocentric vision research, providing a link from first-person to the abundant third-person data on the web. We use this data to learn a joint representation of first and third-person videos, with only weak supervision, and show its effectiveness for transferring knowledge from the third-person to the first-person domain.
* CVPR 2018 spotlight presentation
Non-local Neural Networks
Apr 13, 2018
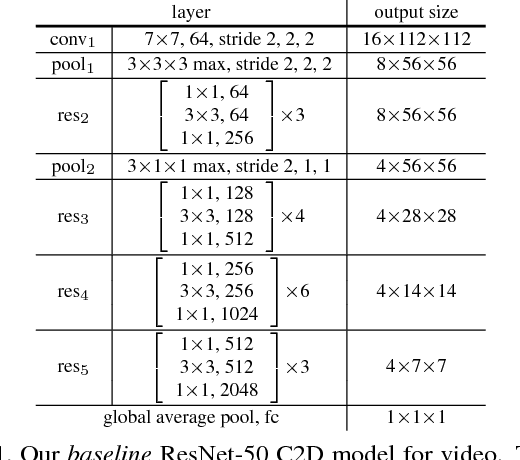
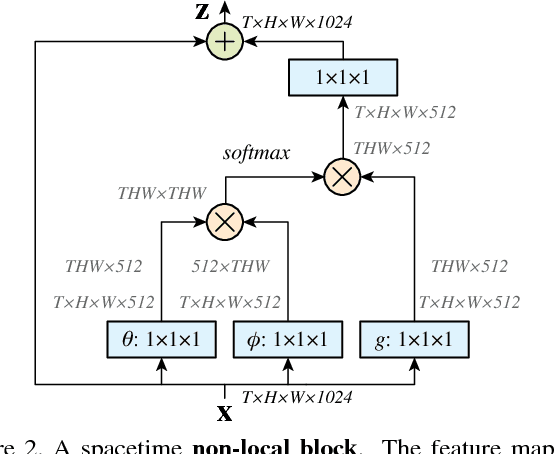
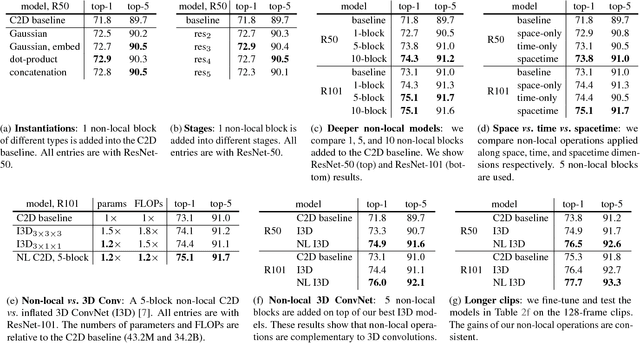
Both convolutional and recurrent operations are building blocks that process one local neighborhood at a time. In this paper, we present non-local operations as a generic family of building blocks for capturing long-range dependencies. Inspired by the classical non-local means method in computer vision, our non-local operation computes the response at a position as a weighted sum of the features at all positions. This building block can be plugged into many computer vision architectures. On the task of video classification, even without any bells and whistles, our non-local models can compete or outperform current competition winners on both Kinetics and Charades datasets. In static image recognition, our non-local models improve object detection/segmentation and pose estimation on the COCO suite of tasks. Code is available at https://github.com/facebookresearch/video-nonlocal-net .
Binge Watching: Scaling Affordance Learning from Sitcoms
Apr 09, 2018

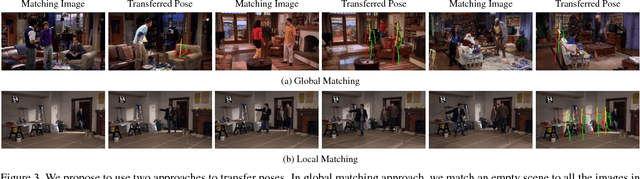
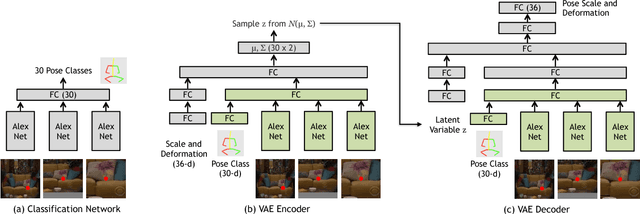
In recent years, there has been a renewed interest in jointly modeling perception and action. At the core of this investigation is the idea of modeling affordances(Affordances are opportunities of interaction in the scene. In other words, it represents what actions can the object be used for). However, when it comes to predicting affordances, even the state of the art approaches still do not use any ConvNets. Why is that? Unlike semantic or 3D tasks, there still does not exist any large-scale dataset for affordances. In this paper, we tackle the challenge of creating one of the biggest dataset for learning affordances. We use seven sitcoms to extract a diverse set of scenes and how actors interact with different objects in the scenes. Our dataset consists of more than 10K scenes and 28K ways humans can interact with these 10K images. We also propose a two-step approach to predict affordances in a new scene. In the first step, given a location in the scene we classify which of the 30 pose classes is the likely affordance pose. Given the pose class and the scene, we then use a Variational Autoencoder (VAE) to extract the scale and deformation of the pose. The VAE allows us to sample the distribution of possible poses at test time. Finally, we show the importance of large-scale data in learning a generalizable and robust model of affordances.
Zero-shot Recognition via Semantic Embeddings and Knowledge Graphs
Apr 08, 2018
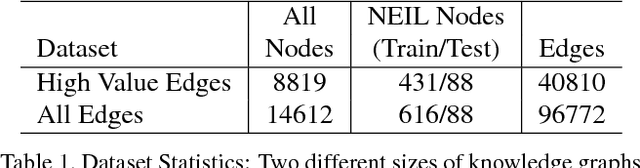
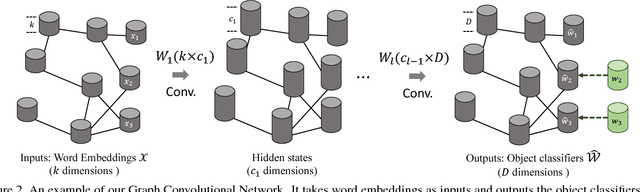
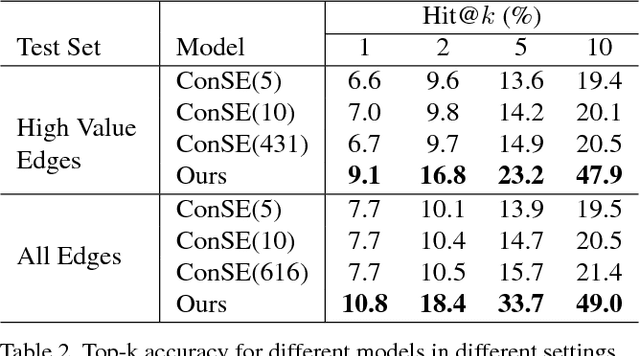
We consider the problem of zero-shot recognition: learning a visual classifier for a category with zero training examples, just using the word embedding of the category and its relationship to other categories, which visual data are provided. The key to dealing with the unfamiliar or novel category is to transfer knowledge obtained from familiar classes to describe the unfamiliar class. In this paper, we build upon the recently introduced Graph Convolutional Network (GCN) and propose an approach that uses both semantic embeddings and the categorical relationships to predict the classifiers. Given a learned knowledge graph (KG), our approach takes as input semantic embeddings for each node (representing visual category). After a series of graph convolutions, we predict the visual classifier for each category. During training, the visual classifiers for a few categories are given to learn the GCN parameters. At test time, these filters are used to predict the visual classifiers of unseen categories. We show that our approach is robust to noise in the KG. More importantly, our approach provides significant improvement in performance compared to the current state-of-the-art results (from 2 ~ 3% on some metrics to whopping 20% on a few).
Iterative Visual Reasoning Beyond Convolutions
Mar 29, 2018
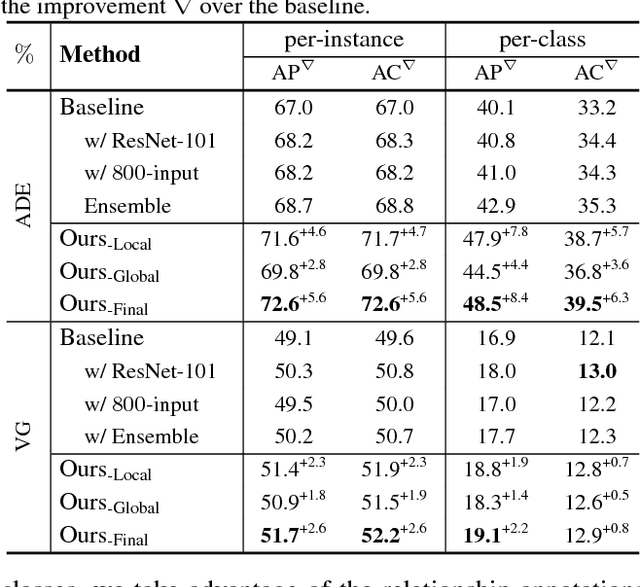
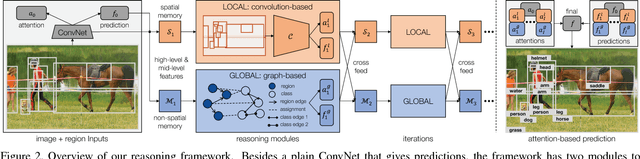
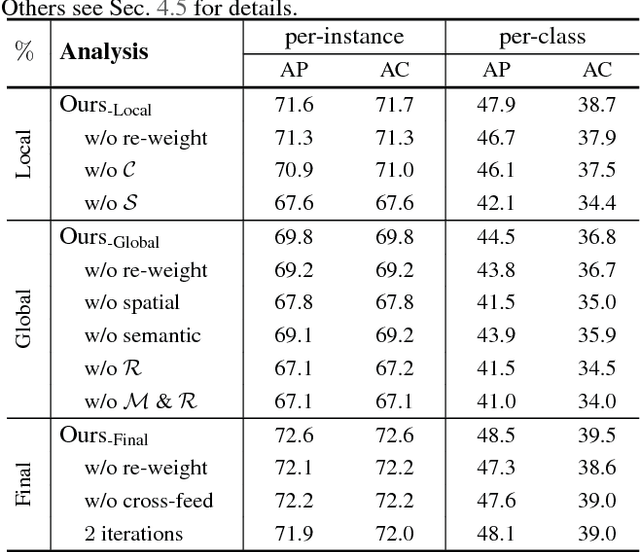
We present a novel framework for iterative visual reasoning. Our framework goes beyond current recognition systems that lack the capability to reason beyond stack of convolutions. The framework consists of two core modules: a local module that uses spatial memory to store previous beliefs with parallel updates; and a global graph-reasoning module. Our graph module has three components: a) a knowledge graph where we represent classes as nodes and build edges to encode different types of semantic relationships between them; b) a region graph of the current image where regions in the image are nodes and spatial relationships between these regions are edges; c) an assignment graph that assigns regions to classes. Both the local module and the global module roll-out iteratively and cross-feed predictions to each other to refine estimates. The final predictions are made by combining the best of both modules with an attention mechanism. We show strong performance over plain ConvNets, \eg achieving an $8.4\%$ absolute improvement on ADE measured by per-class average precision. Analysis also shows that the framework is resilient to missing regions for reasoning.
CASSL: Curriculum Accelerated Self-Supervised Learning
Feb 12, 2018

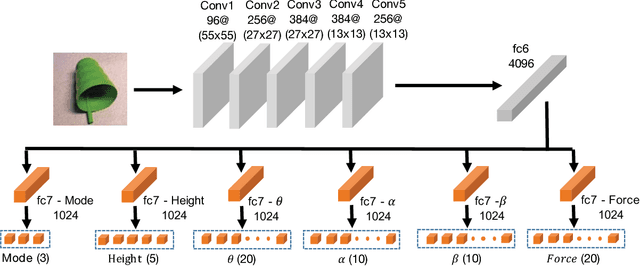

Recent self-supervised learning approaches focus on using a few thousand data points to learn policies for high-level, low-dimensional action spaces. However, scaling this framework for high-dimensional control require either scaling up the data collection efforts or using a clever sampling strategy for training. We present a novel approach - Curriculum Accelerated Self-Supervised Learning (CASSL) - to train policies that map visual information to high-level, higher- dimensional action spaces. CASSL orders the sampling of training data based on control dimensions: the learning and sampling are focused on few control parameters before other parameters. The right curriculum for learning is suggested by variance-based global sensitivity analysis of the control space. We apply our CASSL framework to learning how to grasp using an adaptive, underactuated multi-fingered gripper, a challenging system to control. Our experimental results indicate that CASSL provides significant improvement and generalization compared to baseline methods such as staged curriculum learning (8% increase) and complete end-to-end learning with random exploration (14% improvement) tested on a set of novel objects.
AI2-THOR: An Interactive 3D Environment for Visual AI
Dec 14, 2017
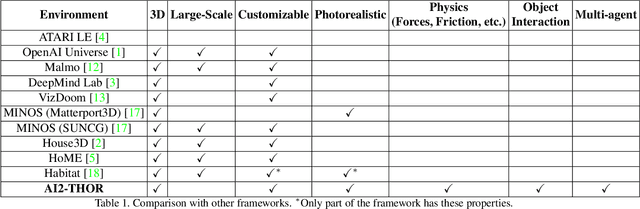
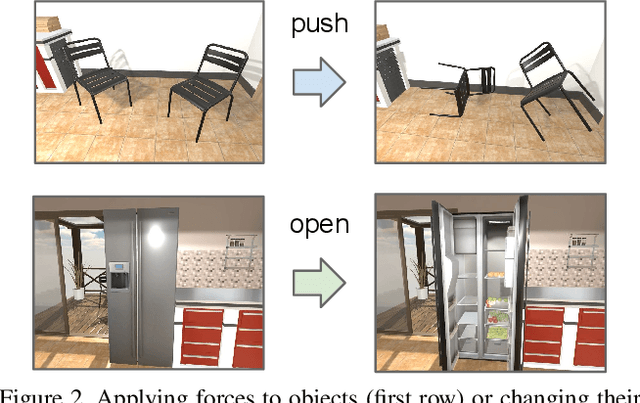
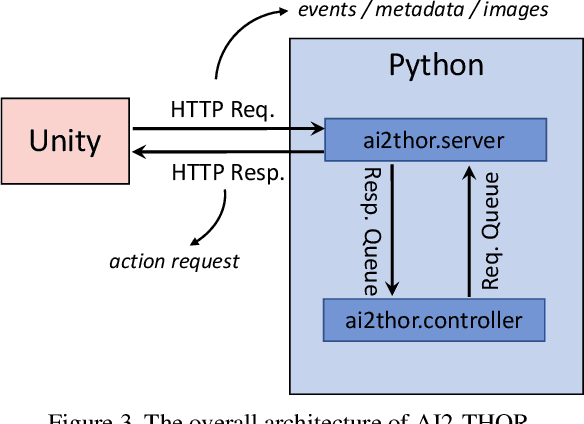
We introduce The House Of inteRactions (THOR), a framework for visual AI research, available at http://ai2thor.allenai.org. AI2-THOR consists of near photo-realistic 3D indoor scenes, where AI agents can navigate in the scenes and interact with objects to perform tasks. AI2-THOR enables research in many different domains including but not limited to deep reinforcement learning, imitation learning, learning by interaction, planning, visual question answering, unsupervised representation learning, object detection and segmentation, and learning models of cognition. The goal of AI2-THOR is to facilitate building visually intelligent models and push the research forward in this domain.
Learning by Asking Questions
Dec 04, 2017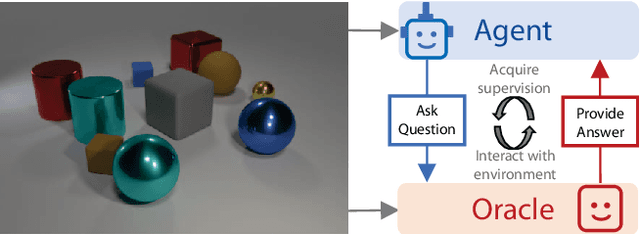
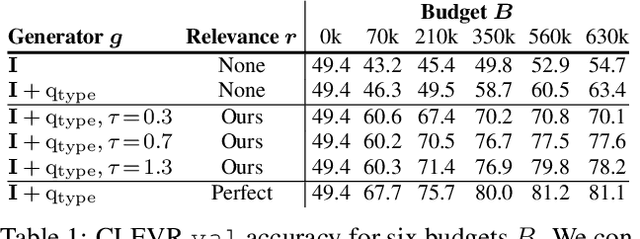

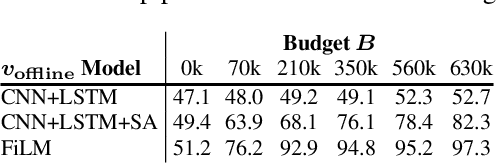
We introduce an interactive learning framework for the development and testing of intelligent visual systems, called learning-by-asking (LBA). We explore LBA in context of the Visual Question Answering (VQA) task. LBA differs from standard VQA training in that most questions are not observed during training time, and the learner must ask questions it wants answers to. Thus, LBA more closely mimics natural learning and has the potential to be more data-efficient than the traditional VQA setting. We present a model that performs LBA on the CLEVR dataset, and show that it automatically discovers an easy-to-hard curriculum when learning interactively from an oracle. Our LBA generated data consistently matches or outperforms the CLEVR train data and is more sample efficient. We also show that our model asks questions that generalize to state-of-the-art VQA models and to novel test time distributions.