 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"speech": models, code, and papers
Recognizing long-form speech using streaming end-to-end models
Oct 24, 2019
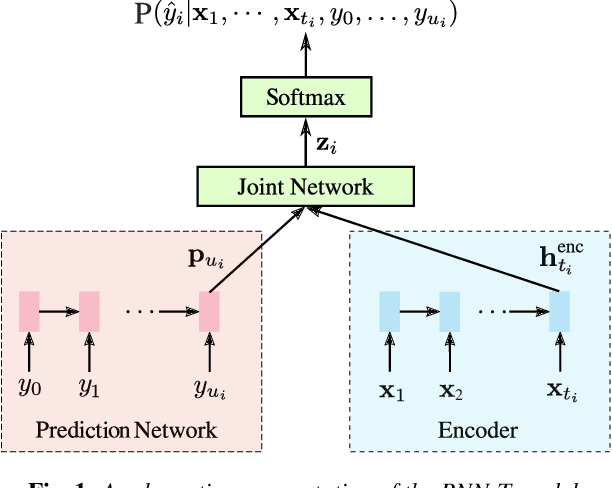
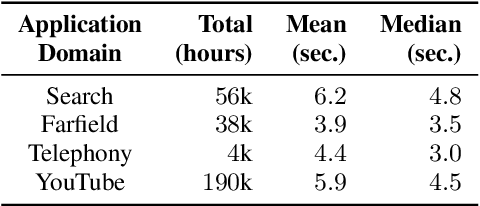
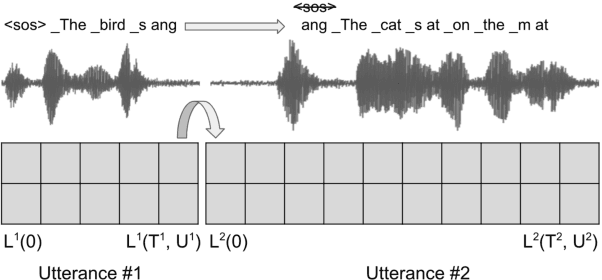
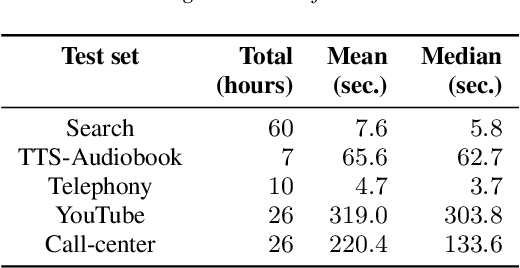
All-neural end-to-end (E2E) automatic speech recognition (ASR) systems that use a single neural network to transduce audio to word sequences have been shown to achieve state-of-the-art results on several tasks. In this work, we examine the ability of E2E models to generalize to unseen domains, where we find that models trained on short utterances fail to generalize to long-form speech. We propose two complementary solutions to address this: training on diverse acoustic data, and LSTM state manipulation to simulate long-form audio when training using short utterances. On a synthesized long-form test set, adding data diversity improves word error rate (WER) by 90% relative, while simulating long-form training improves it by 67% relative, though the combination doesn't improve over data diversity alone. On a real long-form call-center test set, adding data diversity improves WER by 40% relative. Simulating long-form training on top of data diversity improves performance by an additional 27% relative.
Speech Sentiment Analysis via Pre-trained Features from End-to-end ASR Models
Nov 21, 2019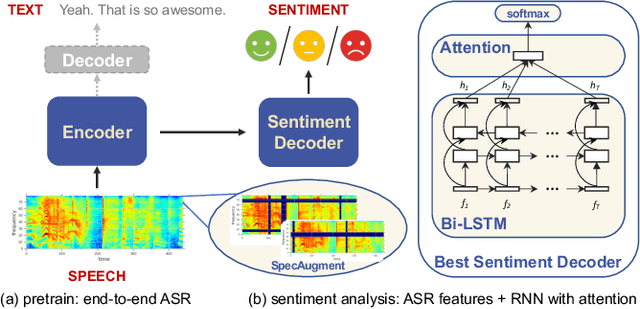

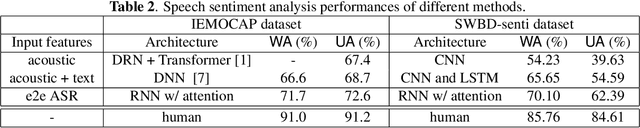

In this paper, we propose to use pre-trained features from end-to-end ASR models to solve the speech sentiment analysis problem as a down-stream task. We show that end-to-end ASR features, which integrate both acoustic and text information from speech, achieve promising results. We use RNN with self-attention as the sentiment classifier, which also provides an easy visualization through attention weights to help interpret model predictions. We use well benchmarked IEMOCAP dataset and a new large-scale sentiment analysis dataset SWBD-senti for evaluation. Our approach improves the-state-of-the-art accuracy on IEMOCAP from 66.6% to 71.7%, and achieves an accuracy of 70.10% on SWBD-senti with more than 49,500 utterances.
Forecast Evaluation for Data Scientists: Common Pitfalls and Best Practices
Apr 04, 2022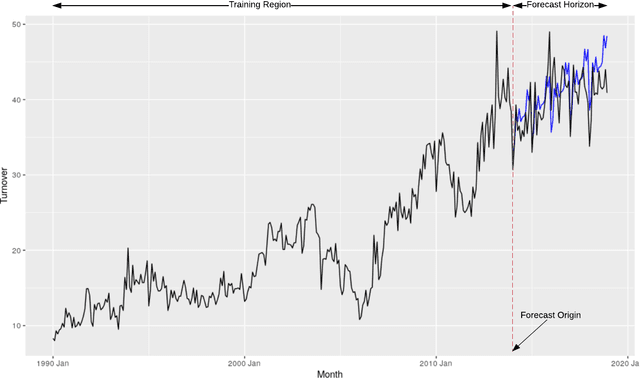
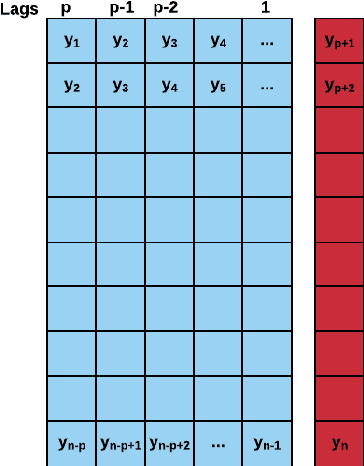

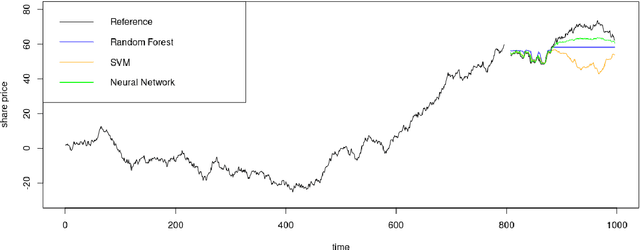
Machine Learning (ML) and Deep Learning (DL) methods are increasingly replacing traditional methods in many domains involved with important decision making activities. DL techniques tailor-made for specific tasks such as image recognition, signal processing, or speech analysis are being introduced at a fast pace with many improvements. However, for the domain of forecasting, the current state in the ML community is perhaps where other domains such as Natural Language Processing and Computer Vision were at several years ago. The field of forecasting has mainly been fostered by statisticians/econometricians; consequently the related concepts are not the mainstream knowledge among general ML practitioners. The different non-stationarities associated with time series challenge the data-driven ML models. Nevertheless, recent trends in the domain have shown that with the availability of massive amounts of time series, ML techniques are quite competent in forecasting, when related pitfalls are properly handled. Therefore, in this work we provide a tutorial-like compilation of the details of one of the most important steps in the overall forecasting process, namely the evaluation. This way, we intend to impart the information of forecast evaluation to fit the context of ML, as means of bridging the knowledge gap between traditional methods of forecasting and state-of-the-art ML techniques. We elaborate on the different problematic characteristics of time series such as non-normalities and non-stationarities and how they are associated with common pitfalls in forecast evaluation. Best practices in forecast evaluation are outlined with respect to the different steps such as data partitioning, error calculation, statistical testing, and others. Further guidelines are also provided along selecting valid and suitable error measures depending on the specific characteristics of the dataset at hand.
Constructing interval variables via faceted Rasch measurement and multitask deep learning: a hate speech application
Sep 22, 2020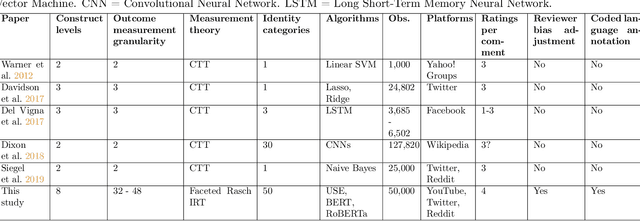



We propose a general method for measuring complex variables on a continuous, interval spectrum by combining supervised deep learning with the Constructing Measures approach to faceted Rasch item response theory (IRT). We decompose the target construct, hate speech in our case, into multiple constituent components that are labeled as ordinal survey items. Those survey responses are transformed via IRT into a debiased, continuous outcome measure. Our method estimates the survey interpretation bias of the human labelers and eliminates that influence on the generated continuous measure. We further estimate the response quality of each labeler using faceted IRT, allowing responses from low-quality labelers to be removed. Our faceted Rasch scaling procedure integrates naturally with a multitask deep learning architecture for automated prediction on new data. The ratings on the theorized components of the target outcome are used as supervised, ordinal variables for the neural networks' internal concept learning. We test the use of an activation function (ordinal softmax) and loss function (ordinal cross-entropy) designed to exploit the structure of ordinal outcome variables. Our multitask architecture leads to a new form of model interpretation because each continuous prediction can be directly explained by the constituent components in the penultimate layer. We demonstrate this new method on a dataset of 50,000 social media comments sourced from YouTube, Twitter, and Reddit and labeled by 11,000 U.S.-based Amazon Mechanical Turk workers to measure a continuous spectrum from hate speech to counterspeech. We evaluate Universal Sentence Encoders, BERT, and RoBERTa as language representation models for the comment text, and compare our predictive accuracy to Google Jigsaw's Perspective API models, showing significant improvement over this standard benchmark.
Learning Problem-agnostic Speech Representations from Multiple Self-supervised Tasks
Apr 06, 2019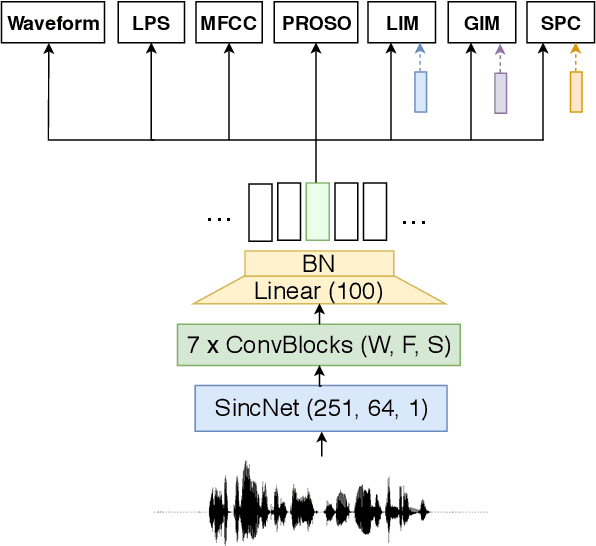
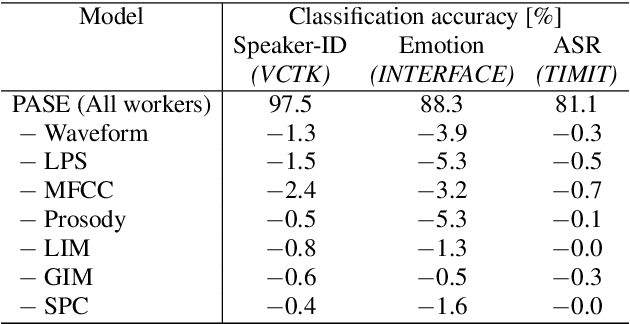
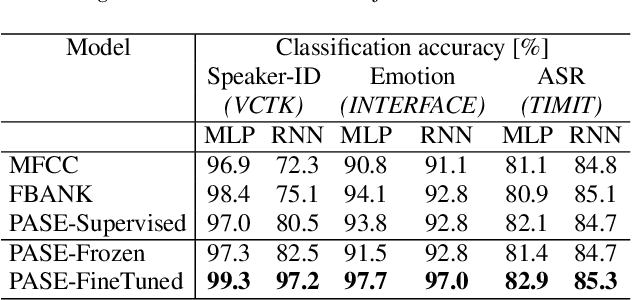
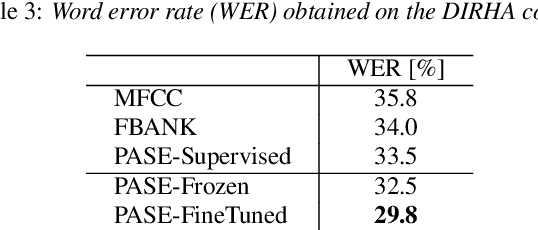
Learning good representations without supervision is still an open issue in machine learning, and is particularly challenging for speech signals, which are often characterized by long sequences with a complex hierarchical structure. Some recent works, however, have shown that it is possible to derive useful speech representations by employing a self-supervised encoder-discriminator approach. This paper proposes an improved self-supervised method, where a single neural encoder is followed by multiple workers that jointly solve different self-supervised tasks. The needed consensus across different tasks naturally imposes meaningful constraints to the encoder, contributing to discover general representations and to minimize the risk of learning superficial ones. Experiments show that the proposed approach can learn transferable, robust, and problem-agnostic features that carry on relevant information from the speech signal, such as speaker identity, phonemes, and even higher-level features such as emotional cues. In addition, a number of design choices make the encoder easily exportable, facilitating its direct usage or adaptation to different problems.
Location-Relative Attention Mechanisms For Robust Long-Form Speech Synthesis
Oct 23, 2019
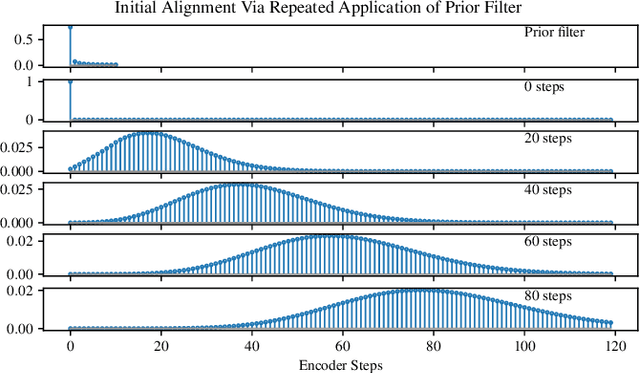

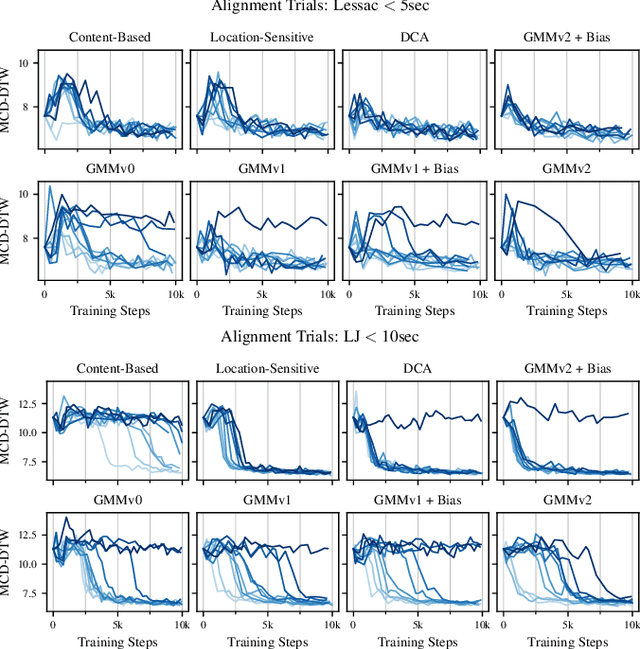
Despite the ability to produce human-level speech for in-domain text, attention-based end-to-end text-to-speech (TTS) systems suffer from text alignment failures that increase in frequency for out-of-domain text. We show that these failures can be addressed using simple location-relative attention mechanisms that do away with content-based query/key comparisons. We compare two families of attention mechanisms: location-relative GMM-based mechanisms and additive energy-based mechanisms. We suggest simple modifications to GMM-based attention that allow it to align quickly and consistently during training, and introduce a new location-relative attention mechanism to the additive energy-based family, called Dynamic Convolution Attention (DCA). We compare the various mechanisms in terms of alignment speed and consistency during training, naturalness, and ability to generalize to long utterances, and conclude that GMM attention and DCA can generalize to very long utterances, while preserving naturalness for shorter, in-domain utterances.
Robust Neural Machine Translation for Clean and Noisy Speech Transcripts
Oct 22, 2019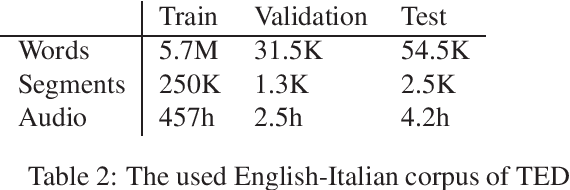
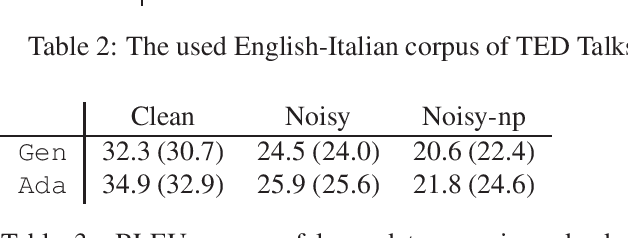
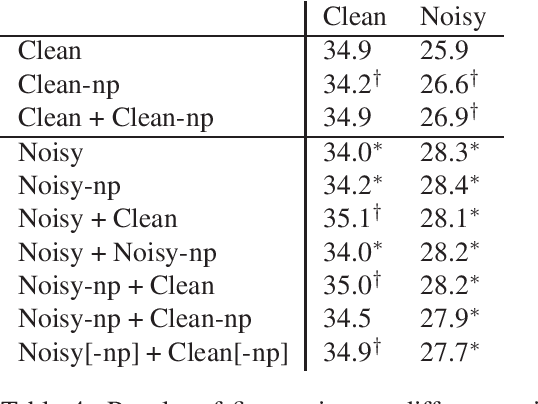
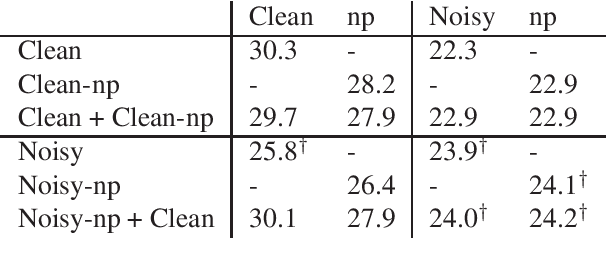
Neural machine translation models have shown to achieve high quality when trained and fed with well structured and punctuated input texts. Unfortunately, the latter condition is not met in spoken language translation, where the input is generated by an automatic speech recognition (ASR) system. In this paper, we study how to adapt a strong NMT system to make it robust to typical ASR errors. As in our application scenarios transcripts might be post-edited by human experts, we propose adaptation strategies to train a single system that can translate either clean or noisy input with no supervision on the input type. Our experimental results on a public speech translation data set show that adapting a model on a significant amount of parallel data including ASR transcripts is beneficial with test data of the same type, but produces a small degradation when translating clean text. Adapting on both clean and noisy variants of the same data leads to the best results on both input types.
End-to-End Automatic Speech Translation of Audiobooks
Feb 12, 2018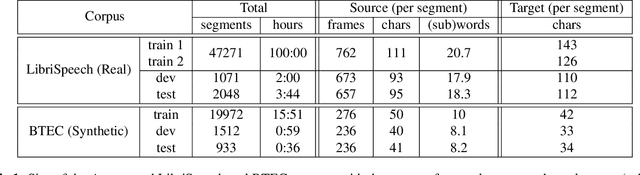
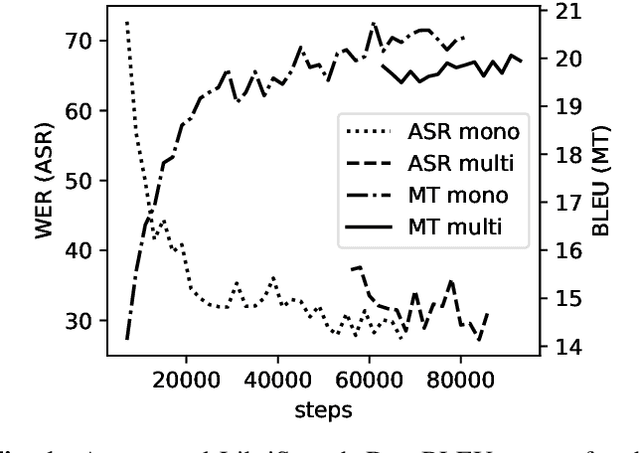
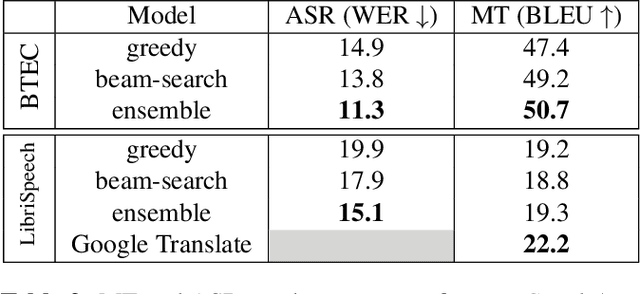
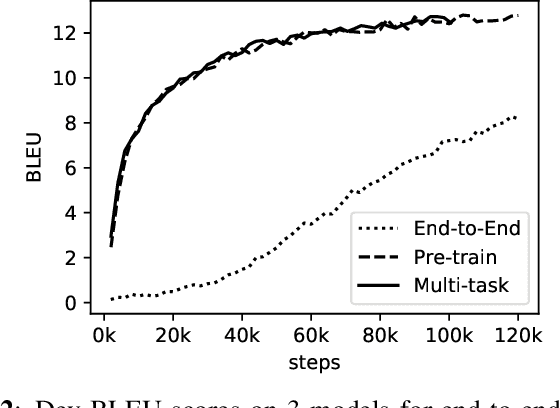
We investigate end-to-end speech-to-text translation on a corpus of audiobooks specifically augmented for this task. Previous works investigated the extreme case where source language transcription is not available during learning nor decoding, but we also study a midway case where source language transcription is available at training time only. In this case, a single model is trained to decode source speech into target text in a single pass. Experimental results show that it is possible to train compact and efficient end-to-end speech translation models in this setup. We also distribute the corpus and hope that our speech translation baseline on this corpus will be challenged in the future.
Improving Unsupervised Subword Modeling via Disentangled Speech Representation Learning and Transformation
Jul 03, 2019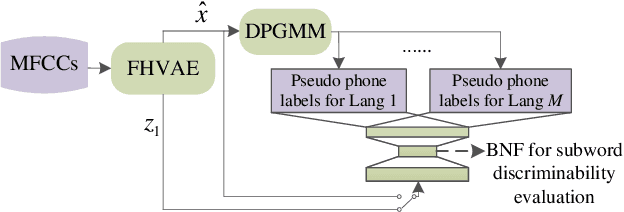
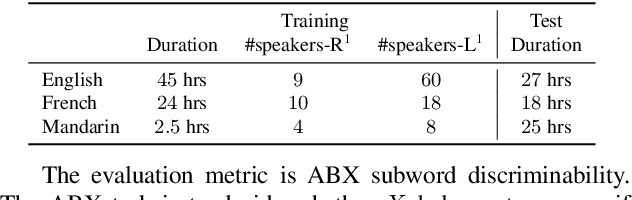
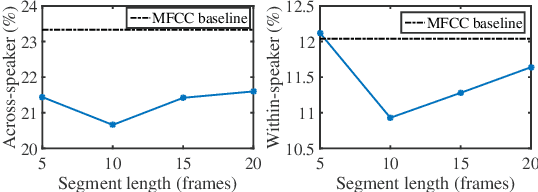
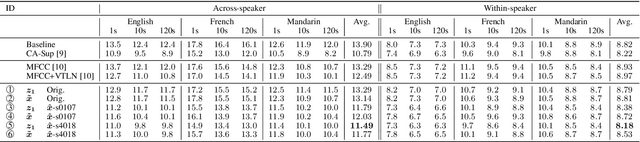
This study tackles unsupervised subword modeling in the zero-resource scenario, learning frame-level speech representation that is phonetically discriminative and speaker-invariant, using only untranscribed speech for target languages. Frame label acquisition is an essential step in solving this problem. High quality frame labels should be in good consistency with golden transcriptions and robust to speaker variation. We propose to improve frame label acquisition in our previously adopted deep neural network-bottleneck feature (DNN-BNF) architecture by applying the factorized hierarchical variational autoencoder (FHVAE). FHVAEs learn to disentangle linguistic content and speaker identity information encoded in speech. By discarding or unifying speaker information, speaker-invariant features are learned and fed as inputs to DPGMM frame clustering and DNN-BNF training. Experiments conducted on ZeroSpeech 2017 show that our proposed approaches achieve $2.4\%$ and $0.6\%$ absolute ABX error rate reductions in across- and within-speaker conditions, comparing to the baseline DNN-BNF system without applying FHVAEs. Our proposed approaches significantly outperform vocal tract length normalization in improving frame labeling and subword modeling.
Online Automatic Speech Recognition with Listen, Attend and Spell Model
Aug 12, 2020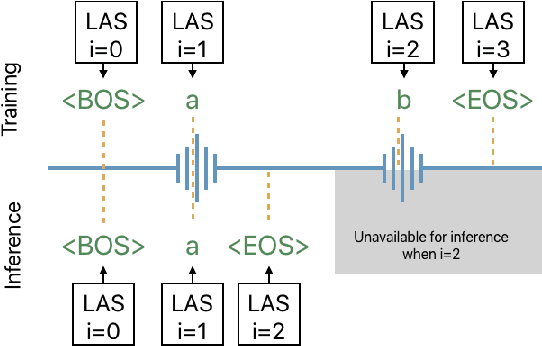
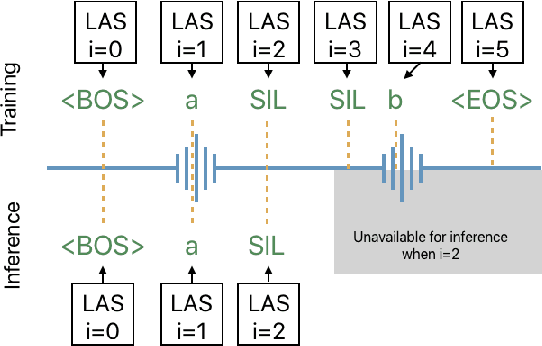
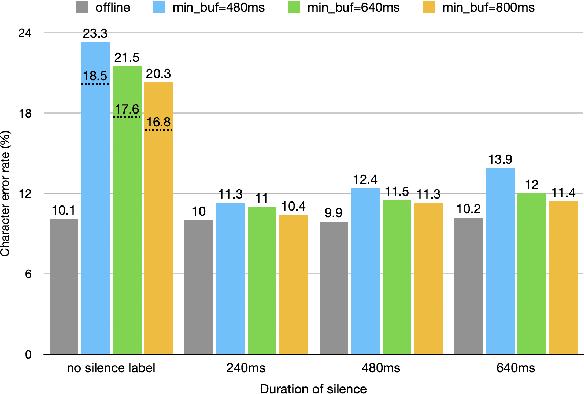
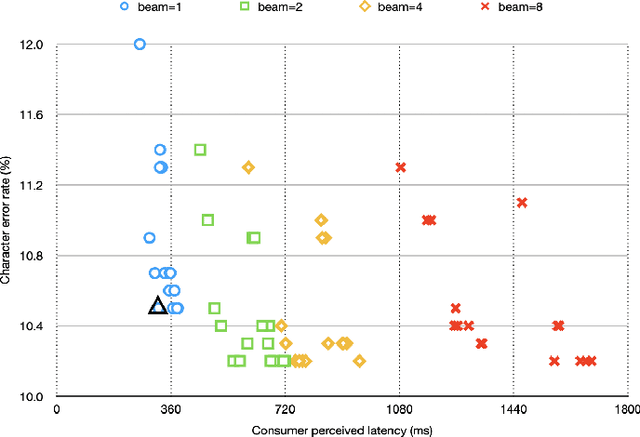
The Listen, Attend and Spell (LAS) model and other attention-based automatic speech recognition (ASR) models have known limitations when operated in a fully online mode. In this paper, we analyze the online operation of LAS models to demonstrate that these limitations stem from the handling of silence regions and the reliability of online attention mechanism at the edge of input buffers. We propose a novel and simple technique that can achieve fully online recognition while meeting accuracy and latency targets. For the Mandarin dictation task, our proposed approach can achieve a character error rate in online operation that is within 4% relative to an offline LAS model. The proposed online LAS model operates at 12% lower latency relative to a conventional neural network hidden Markov model hybrid of comparable accuracy. We have validated the proposed method through a production scale deployment, which, to the best of our knowledge, is the first such deployment of a fully online LAS model.