 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeA real-time spatiotemporal AI model analyzes skill in open surgical videos
Dec 14, 2021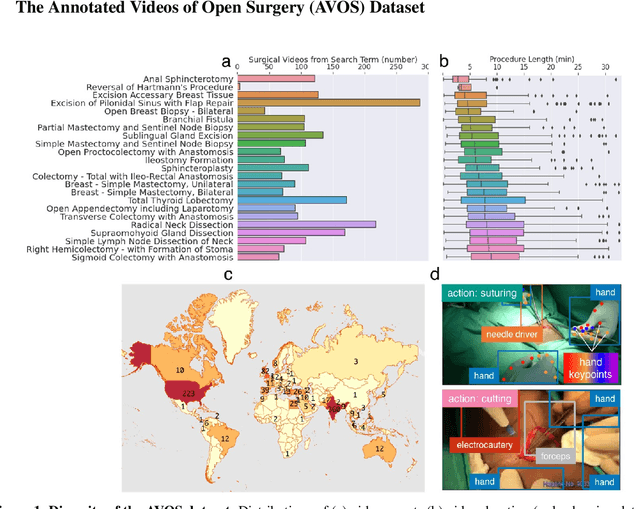
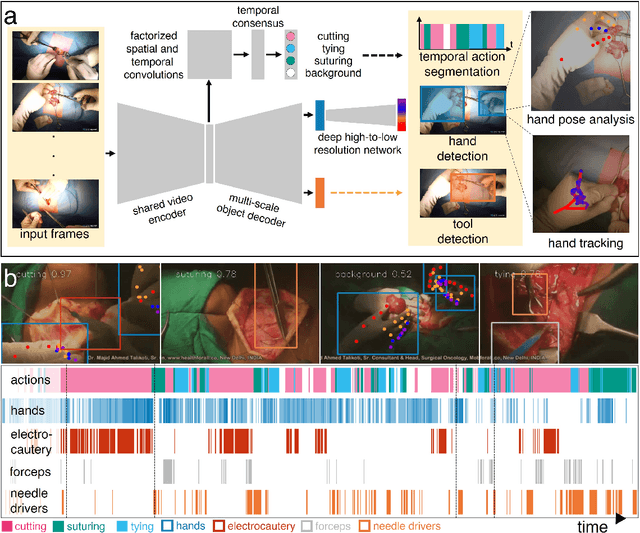
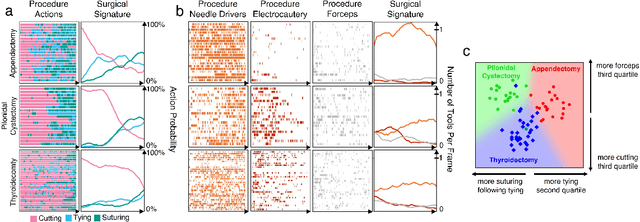
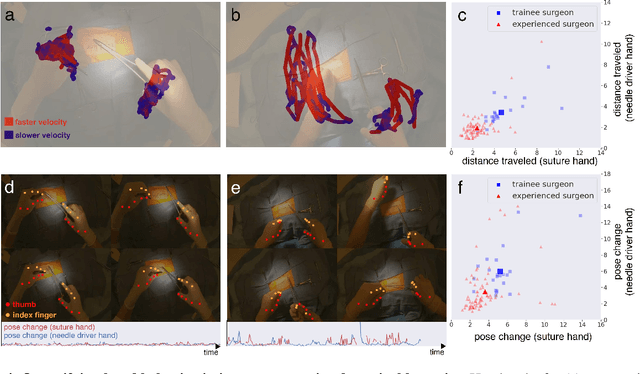
Open procedures represent the dominant form of surgery worldwide. Artificial intelligence (AI) has the potential to optimize surgical practice and improve patient outcomes, but efforts have focused primarily on minimally invasive techniques. Our work overcomes existing data limitations for training AI models by curating, from YouTube, the largest dataset of open surgical videos to date: 1997 videos from 23 surgical procedures uploaded from 50 countries. Using this dataset, we developed a multi-task AI model capable of real-time understanding of surgical behaviors, hands, and tools - the building blocks of procedural flow and surgeon skill. We show that our model generalizes across diverse surgery types and environments. Illustrating this generalizability, we directly applied our YouTube-trained model to analyze open surgeries prospectively collected at an academic medical center and identified kinematic descriptors of surgical skill related to efficiency of hand motion. Our Annotated Videos of Open Surgery (AVOS) dataset and trained model will be made available for further development of surgical AI.
Tracking e-cigarette warning label compliance on Instagram with deep learning
Feb 08, 2021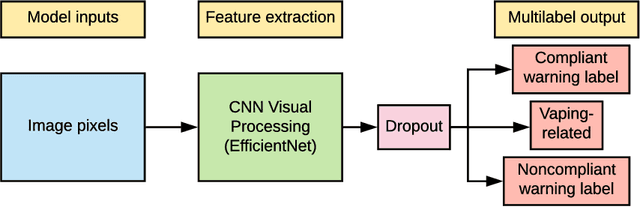

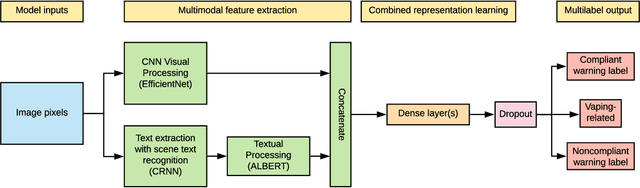
The U.S. Food & Drug Administration (FDA) requires that e-cigarette advertisements include a prominent warning label that reminds consumers that nicotine is addictive. However, the high volume of vaping-related posts on social media makes compliance auditing expensive and time-consuming, suggesting that an automated, scalable method is needed. We sought to develop and evaluate a deep learning system designed to automatically determine if an Instagram post promotes vaping, and if so, if an FDA-compliant warning label was included or if a non-compliant warning label was visible in the image. We compiled and labeled a dataset of 4,363 Instagram images, of which 44% were vaping-related, 3% contained FDA-compliant warning labels, and 4% contained non-compliant labels. Using a 20% test set for evaluation, we tested multiple neural network variations: image processing backbone model (Inceptionv3, ResNet50, EfficientNet), data augmentation, progressive layer unfreezing, output bias initialization designed for class imbalance, and multitask learning. Our final model achieved an area under the curve (AUC) and [accuracy] of 0.97 [92%] on vaping classification, 0.99 [99%] on FDA-compliant warning labels, and 0.94 [97%] on non-compliant warning labels. We conclude that deep learning models can effectively identify vaping posts on Instagram and track compliance with FDA warning label requirements.
Constructing interval variables via faceted Rasch measurement and multitask deep learning: a hate speech application
Sep 22, 2020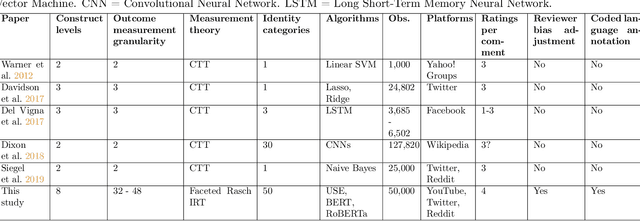



We propose a general method for measuring complex variables on a continuous, interval spectrum by combining supervised deep learning with the Constructing Measures approach to faceted Rasch item response theory (IRT). We decompose the target construct, hate speech in our case, into multiple constituent components that are labeled as ordinal survey items. Those survey responses are transformed via IRT into a debiased, continuous outcome measure. Our method estimates the survey interpretation bias of the human labelers and eliminates that influence on the generated continuous measure. We further estimate the response quality of each labeler using faceted IRT, allowing responses from low-quality labelers to be removed. Our faceted Rasch scaling procedure integrates naturally with a multitask deep learning architecture for automated prediction on new data. The ratings on the theorized components of the target outcome are used as supervised, ordinal variables for the neural networks' internal concept learning. We test the use of an activation function (ordinal softmax) and loss function (ordinal cross-entropy) designed to exploit the structure of ordinal outcome variables. Our multitask architecture leads to a new form of model interpretation because each continuous prediction can be directly explained by the constituent components in the penultimate layer. We demonstrate this new method on a dataset of 50,000 social media comments sourced from YouTube, Twitter, and Reddit and labeled by 11,000 U.S.-based Amazon Mechanical Turk workers to measure a continuous spectrum from hate speech to counterspeech. We evaluate Universal Sentence Encoders, BERT, and RoBERTa as language representation models for the comment text, and compare our predictive accuracy to Google Jigsaw's Perspective API models, showing significant improvement over this standard benchmark.