 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeImproving Unsupervised Subword Modeling via Disentangled Speech Representation Learning and Transformation
Paper and Code
Jul 03, 2019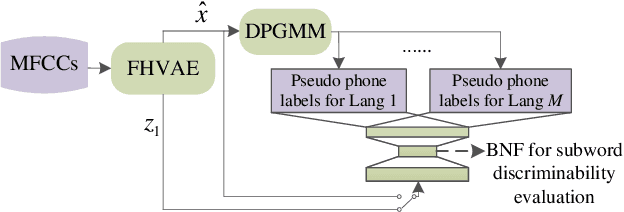
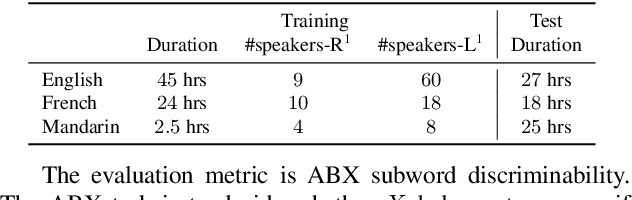
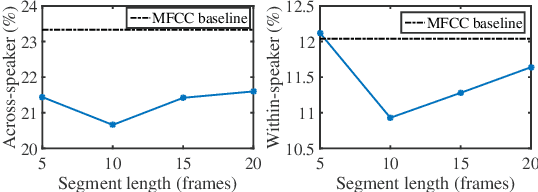
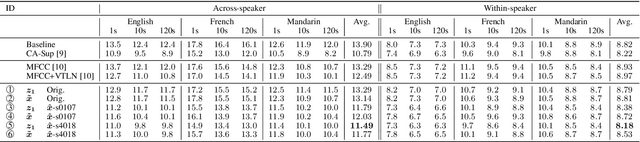
This study tackles unsupervised subword modeling in the zero-resource scenario, learning frame-level speech representation that is phonetically discriminative and speaker-invariant, using only untranscribed speech for target languages. Frame label acquisition is an essential step in solving this problem. High quality frame labels should be in good consistency with golden transcriptions and robust to speaker variation. We propose to improve frame label acquisition in our previously adopted deep neural network-bottleneck feature (DNN-BNF) architecture by applying the factorized hierarchical variational autoencoder (FHVAE). FHVAEs learn to disentangle linguistic content and speaker identity information encoded in speech. By discarding or unifying speaker information, speaker-invariant features are learned and fed as inputs to DPGMM frame clustering and DNN-BNF training. Experiments conducted on ZeroSpeech 2017 show that our proposed approaches achieve $2.4\%$ and $0.6\%$ absolute ABX error rate reductions in across- and within-speaker conditions, comparing to the baseline DNN-BNF system without applying FHVAEs. Our proposed approaches significantly outperform vocal tract length normalization in improving frame labeling and subword modeling.