 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeRobust Neural Machine Translation for Clean and Noisy Speech Transcripts
Paper and Code
Oct 22, 2019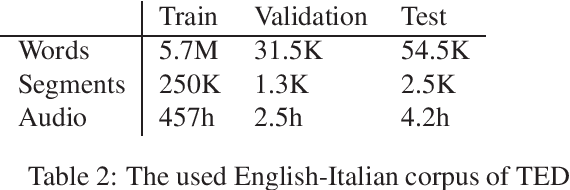
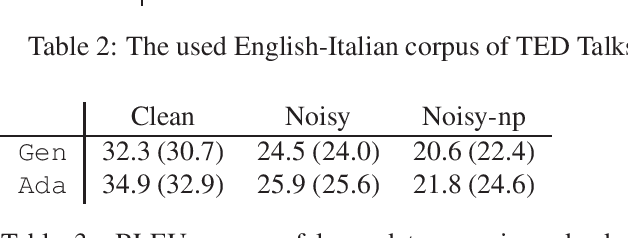
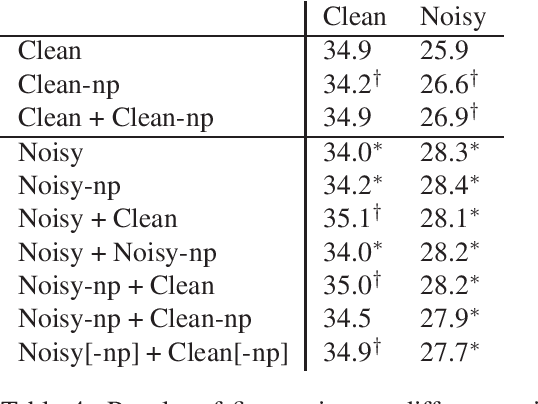
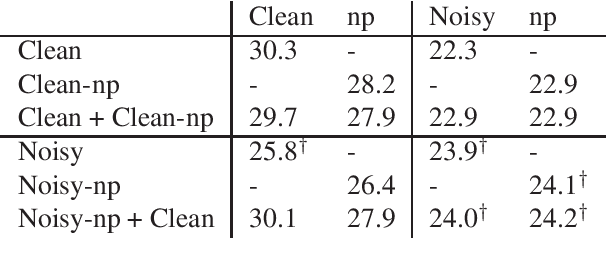
Neural machine translation models have shown to achieve high quality when trained and fed with well structured and punctuated input texts. Unfortunately, the latter condition is not met in spoken language translation, where the input is generated by an automatic speech recognition (ASR) system. In this paper, we study how to adapt a strong NMT system to make it robust to typical ASR errors. As in our application scenarios transcripts might be post-edited by human experts, we propose adaptation strategies to train a single system that can translate either clean or noisy input with no supervision on the input type. Our experimental results on a public speech translation data set show that adapting a model on a significant amount of parallel data including ASR transcripts is beneficial with test data of the same type, but produces a small degradation when translating clean text. Adapting on both clean and noisy variants of the same data leads to the best results on both input types.