 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"speech": models, code, and papers
"How Robust r u?": Evaluating Task-Oriented Dialogue Systems on Spoken Conversations
Sep 28, 2021

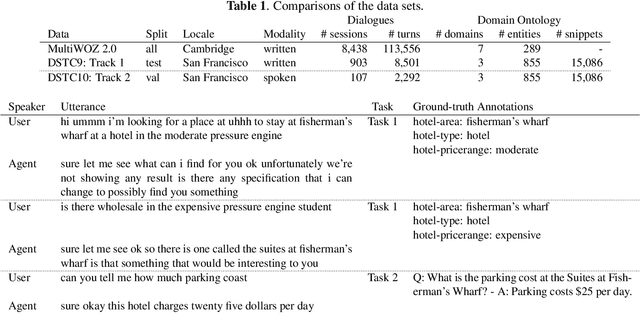
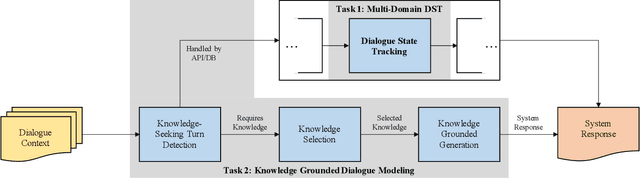

Most prior work in dialogue modeling has been on written conversations mostly because of existing data sets. However, written dialogues are not sufficient to fully capture the nature of spoken conversations as well as the potential speech recognition errors in practical spoken dialogue systems. This work presents a new benchmark on spoken task-oriented conversations, which is intended to study multi-domain dialogue state tracking and knowledge-grounded dialogue modeling. We report that the existing state-of-the-art models trained on written conversations are not performing well on our spoken data, as expected. Furthermore, we observe improvements in task performances when leveraging n-best speech recognition hypotheses such as by combining predictions based on individual hypotheses. Our data set enables speech-based benchmarking of task-oriented dialogue systems.
AB/BA analysis: A framework for estimating keyword spotting recall improvement while maintaining audio privacy
Apr 18, 2022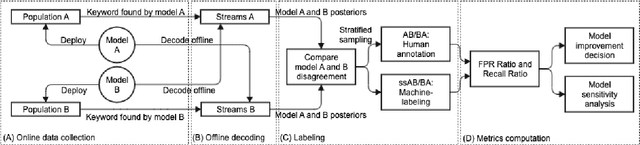

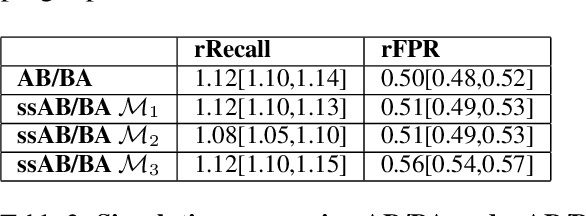
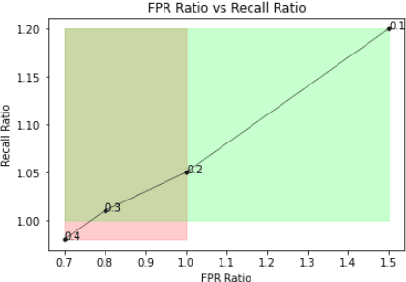
Evaluation of keyword spotting (KWS) systems that detect keywords in speech is a challenging task under realistic privacy constraints. The KWS is designed to only collect data when the keyword is present, limiting the availability of hard samples that may contain false negatives, and preventing direct estimation of model recall from production data. Alternatively, complementary data collected from other sources may not be fully representative of the real application. In this work, we propose an evaluation technique which we call AB/BA analysis. Our framework evaluates a candidate KWS model B against a baseline model A, using cross-dataset offline decoding for relative recall estimation, without requiring negative examples. Moreover, we propose a formulation with assumptions that allow estimation of relative false positive rate between models with low variance even when the number of false positives is small. Finally, we propose to leverage machine-generated soft labels, in a technique we call Semi-Supervised AB/BA analysis, that improves the analysis time, privacy, and cost. Experiments with both simulation and real data show that AB/BA analysis is successful at measuring recall improvement in conjunction with the trade-off in relative false positive rate.
Unified Autoregressive Modeling for Joint End-to-End Multi-Talker Overlapped Speech Recognition and Speaker Attribute Estimation
Jul 04, 2021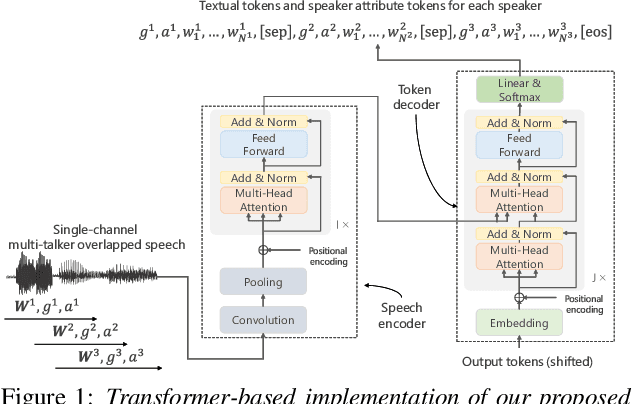
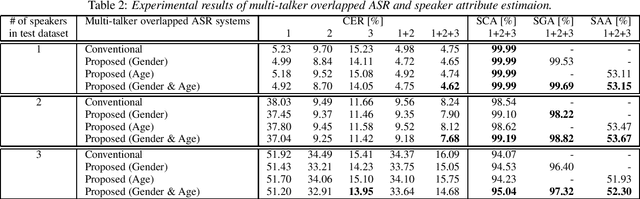
In this paper, we present a novel modeling method for single-channel multi-talker overlapped automatic speech recognition (ASR) systems. Fully neural network based end-to-end models have dramatically improved the performance of multi-taker overlapped ASR tasks. One promising approach for end-to-end modeling is autoregressive modeling with serialized output training in which transcriptions of multiple speakers are recursively generated one after another. This enables us to naturally capture relationships between speakers. However, the conventional modeling method cannot explicitly take into account the speaker attributes of individual utterances such as gender and age information. In fact, the performance deteriorates when each speaker is the same gender or is close in age. To address this problem, we propose unified autoregressive modeling for joint end-to-end multi-talker overlapped ASR and speaker attribute estimation. Our key idea is to handle gender and age estimation tasks within the unified autoregressive modeling. In the proposed method, transformer-based autoregressive model recursively generates not only textual tokens but also attribute tokens of each speaker. This enables us to effectively utilize speaker attributes for improving multi-talker overlapped ASR. Experiments on Japanese multi-talker overlapped ASR tasks demonstrate the effectiveness of the proposed method.
Gated Multimodal Fusion with Contrastive Learning for Turn-taking Prediction in Human-robot Dialogue
Apr 18, 2022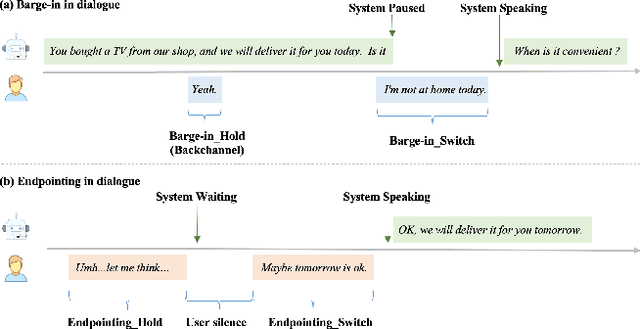
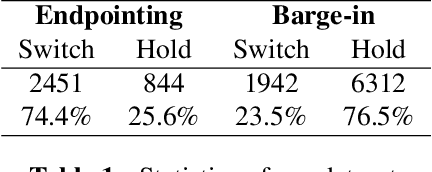
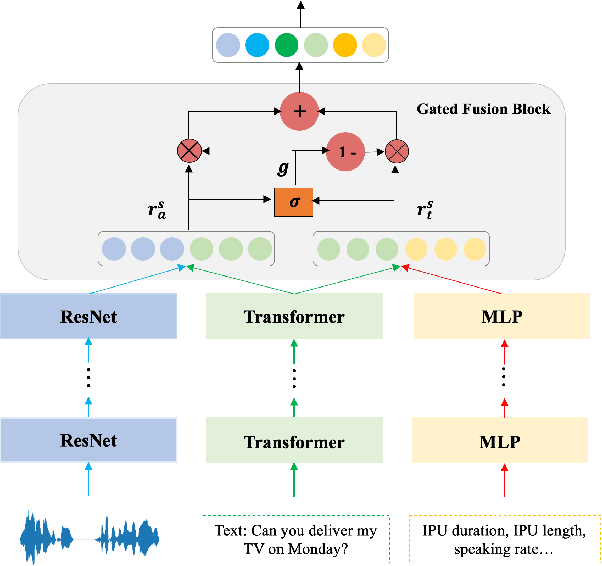
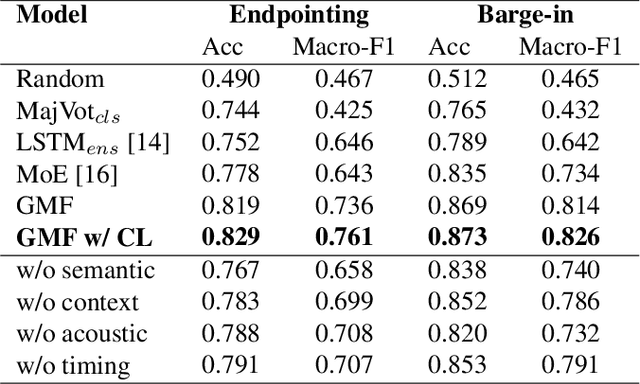
Turn-taking, aiming to decide when the next speaker can start talking, is an essential component in building human-robot spoken dialogue systems. Previous studies indicate that multimodal cues can facilitate this challenging task. However, due to the paucity of public multimodal datasets, current methods are mostly limited to either utilizing unimodal features or simplistic multimodal ensemble models. Besides, the inherent class imbalance in real scenario, e.g. sentence ending with short pause will be mostly regarded as the end of turn, also poses great challenge to the turn-taking decision. In this paper, we first collect a large-scale annotated corpus for turn-taking with over 5,000 real human-robot dialogues in speech and text modalities. Then, a novel gated multimodal fusion mechanism is devised to utilize various information seamlessly for turn-taking prediction. More importantly, to tackle the data imbalance issue, we design a simple yet effective data augmentation method to construct negative instances without supervision and apply contrastive learning to obtain better feature representations. Extensive experiments are conducted and the results demonstrate the superiority and competitiveness of our model over several state-of-the-art baselines.
Robust End-to-end Speaker Diarization with Generic Neural Clustering
Apr 18, 2022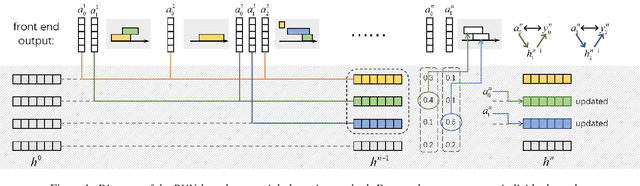
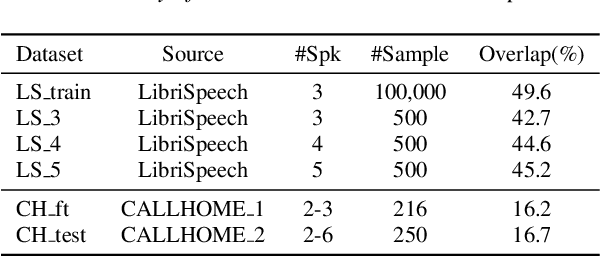
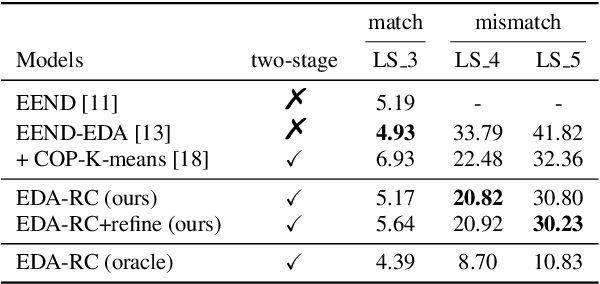
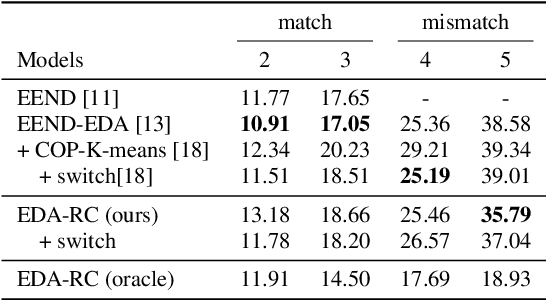
End-to-end speaker diarization approaches have shown exceptional performance over the traditional modular approaches. To further improve the performance of the end-to-end speaker diarization for real speech recordings, recently works have been proposed which integrate unsupervised clustering algorithms with the end-to-end neural diarization models. However, these methods have a number of drawbacks: 1) The unsupervised clustering algorithms cannot leverage the supervision from the available datasets; 2) The K-means-based unsupervised algorithms that are explored often suffer from the constraint violation problem; 3) There is unavoidable mismatch between the supervised training and the unsupervised inference. In this paper, a robust generic neural clustering approach is proposed that can be integrated with any chunk-level predictor to accomplish a fully supervised end-to-end speaker diarization model. Also, by leveraging the sequence modelling ability of a recurrent neural network, the proposed neural clustering approach can dynamically estimate the number of speakers during inference. Experimental show that when integrating an attractor-based chunk-level predictor, the proposed neural clustering approach can yield better Diarization Error Rate (DER) than the constrained K-means-based clustering approaches under the mismatched conditions.
ESNI: Domestic Robots Design for Elderly and Disabled People
Mar 30, 2022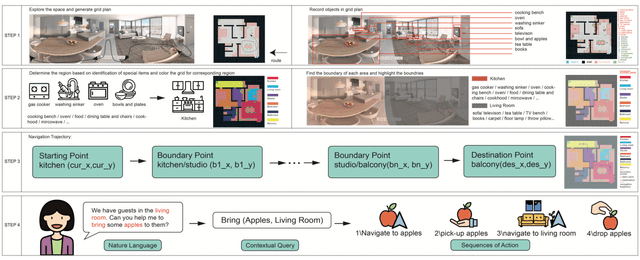
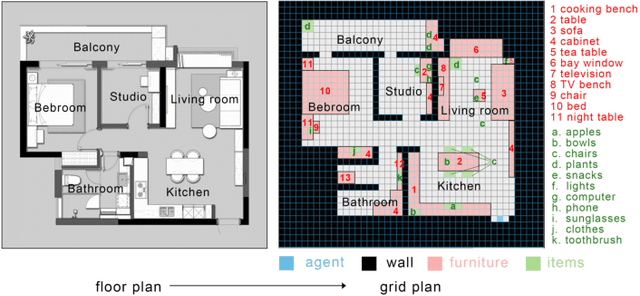
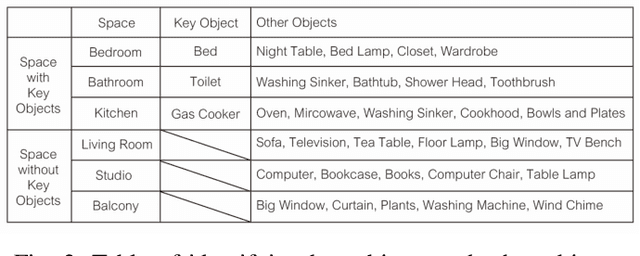
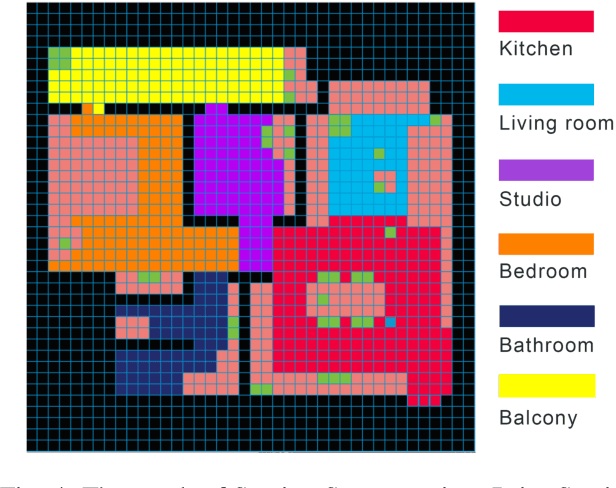
Our paper focuses on the research of the possibility for speech recognition intelligent agents to assist the elderly and disabled people's lives, to improve their life quality by utilizing cutting-edge technologies. After researching the attitude of elderly and disabled people toward the household agent, we propose a design framework: ESNI(Exploration, Segmentation, Navigation, Instruction) that apply to mobile agent, achieve some functionalities such as processing human commands, picking up a specified object, and moving an object to another location. The agent starts the exploration in an unseen environment, stores each item's information in the grid cells to his memory and analyzes the corresponding features for each section. We divided our indoor environment into 6 sections: Kitchen, Living room, Bedroom, Studio, Bathroom, Balcony. The agent uses algorithms to assign sections for each grid cell then generates a navigation trajectory base on the section segmentation. When the user gives a command to the agent, feature words will be extracted and processed into a sequence of sub-tasks.
Learning to detect dysarthria from raw speech
Nov 27, 2018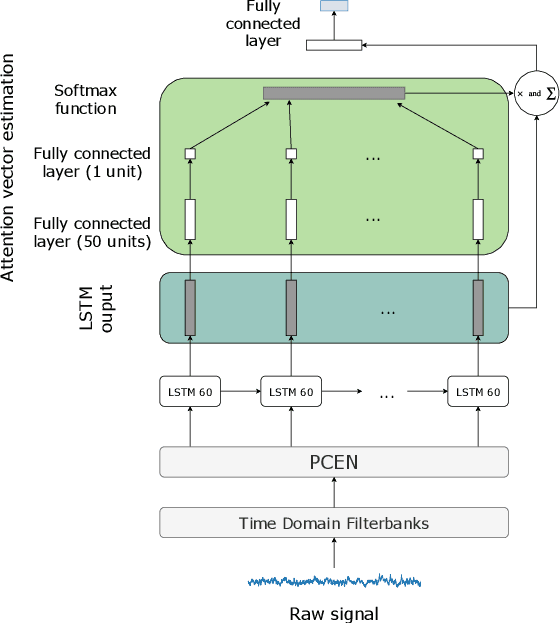
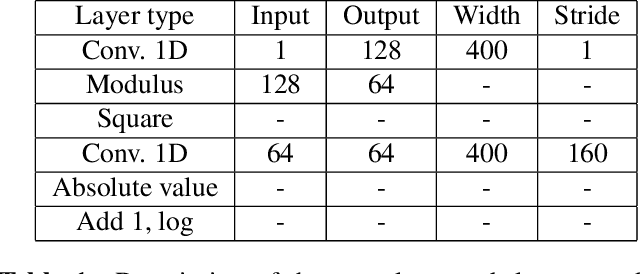

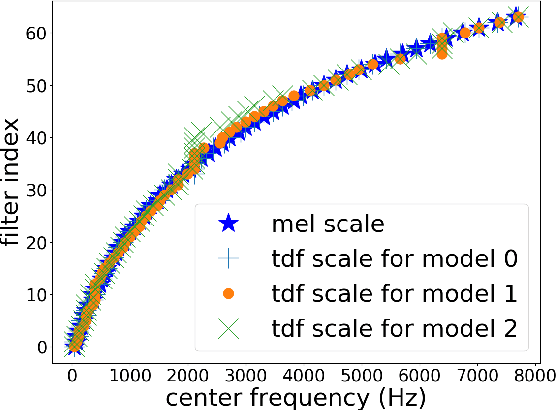
Speech classifiers of paralinguistic traits traditionally learn from diverse hand-crafted low-level features, by selecting the relevant information for the task at hand. We explore an alternative to this selection, by learning jointly the classifier, and the feature extraction. Recent work on speech recognition has shown improved performance over speech features by learning from the waveform. We extend this approach to paralinguistic classification and propose a neural network that can learn a filterbank, a normalization factor and a compression power from the raw speech, jointly with the rest of the architecture. We apply this model to dysarthria detection from sentence-level audio recordings. Starting from a strong attention-based baseline on which mel-filterbanks outperform standard low-level descriptors, we show that learning the filters or the normalization and compression improves over fixed features by 10% absolute accuracy. We also observe a gain over OpenSmile features by learning jointly the feature extraction, the normalization, and the compression factor with the architecture. This constitutes a first attempt at learning jointly all these operations from raw audio for a speech classification task.
AISPEECH-SJTU accent identification system for the Accented English Speech Recognition Challenge
Feb 19, 2021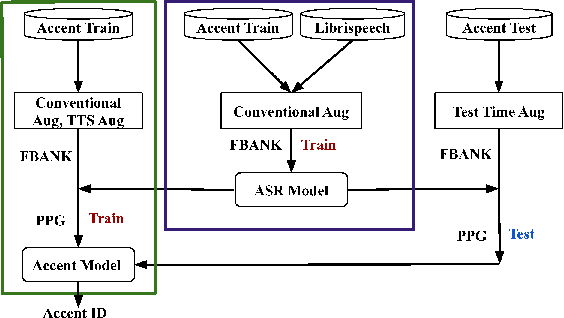
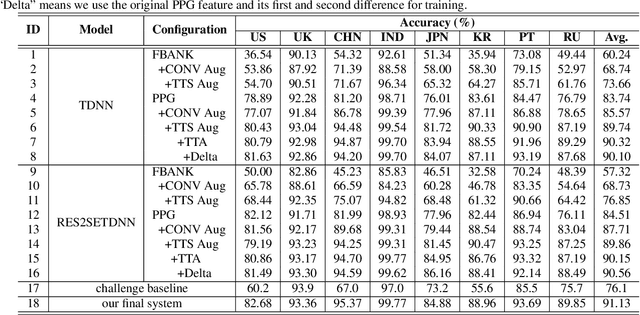
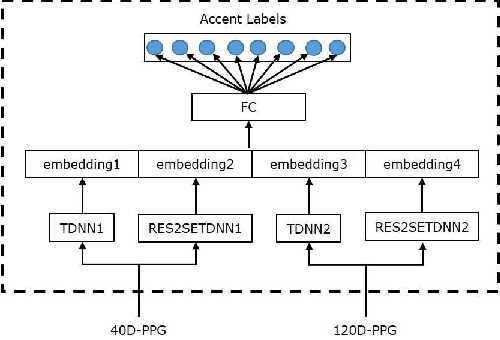
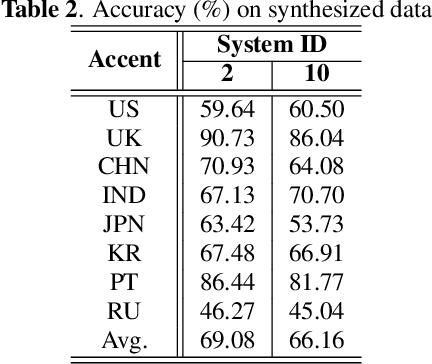
This paper describes the AISpeech-SJTU system for the accent identification track of the Interspeech-2020 Accented English Speech Recognition Challenge. In this challenge track, only 160-hour accented English data collected from 8 countries and the auxiliary Librispeech dataset are provided for training. To build an accurate and robust accent identification system, we explore the whole system pipeline in detail. First, we introduce the ASR based phone posteriorgram (PPG) feature to accent identification and verify its efficacy. Then, a novel TTS based approach is carefully designed to augment the very limited accent training data for the first time. Finally, we propose the test time augmentation and embedding fusion schemes to further improve the system performance. Our final system is ranked first in the challenge and outperforms all the other participants by a large margin. The submitted system achieves 83.63\% average accuracy on the challenge evaluation data, ahead of the others by more than 10\% in absolute terms.
Robust Unsupervised Audio-visual Speech Enhancement Using a Mixture of Variational Autoencoders
Nov 10, 2019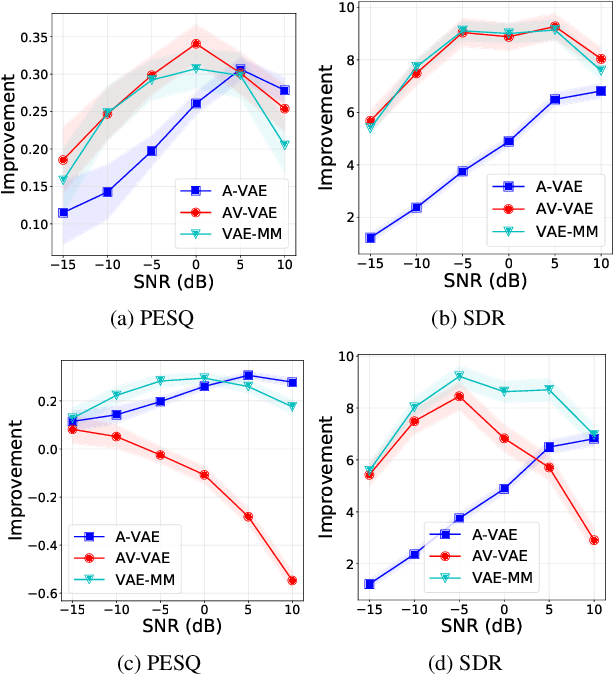
Recently, an audio-visual speech generative model based on variational autoencoder (VAE) has been proposed, which is combined with a nonnegative matrix factorization (NMF) model for noise variance to perform unsupervised speech enhancement. When visual data is clean, speech enhancement with audio-visual VAE shows a better performance than with audio-only VAE, which is trained on audio-only data. However, audio-visual VAE is not robust against noisy visual data, e.g., when for some video frames, speaker face is not frontal or lips region is occluded. In this paper, we propose a robust unsupervised audio-visual speech enhancement method based on a per-frame VAE mixture model. This mixture model consists of a trained audio-only VAE and a trained audio-visual VAE. The motivation is to skip noisy visual frames by switching to the audio-only VAE model. We present a variational expectation-maximization method to estimate the parameters of the model. Experiments show the promising performance of the proposed method.
Short-Term Word-Learning in a Dynamically Changing Environment
Mar 29, 2022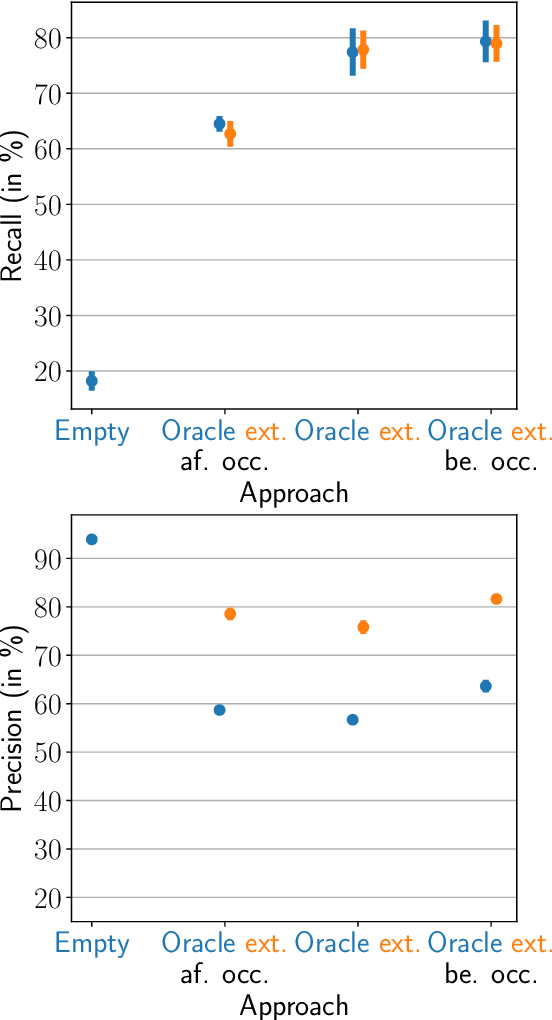
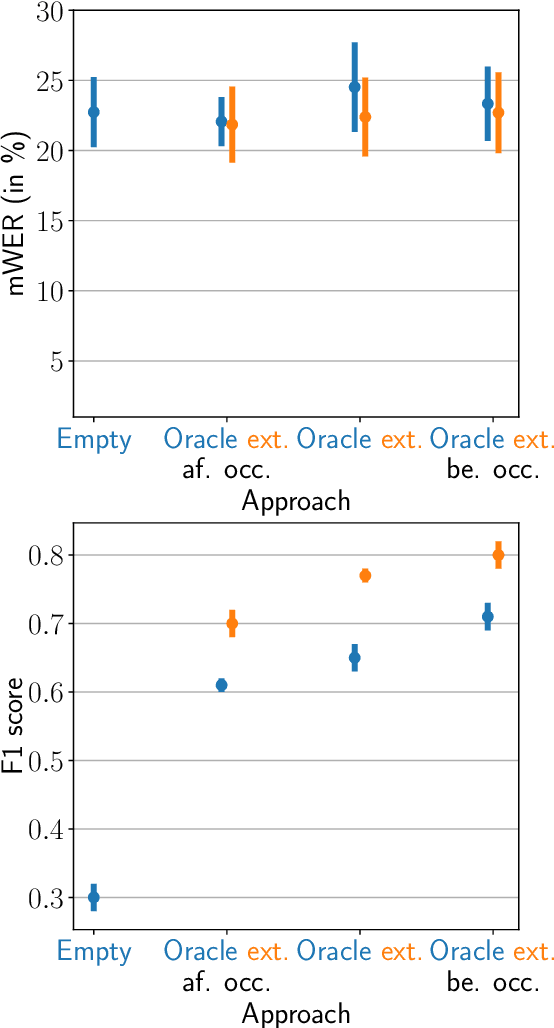
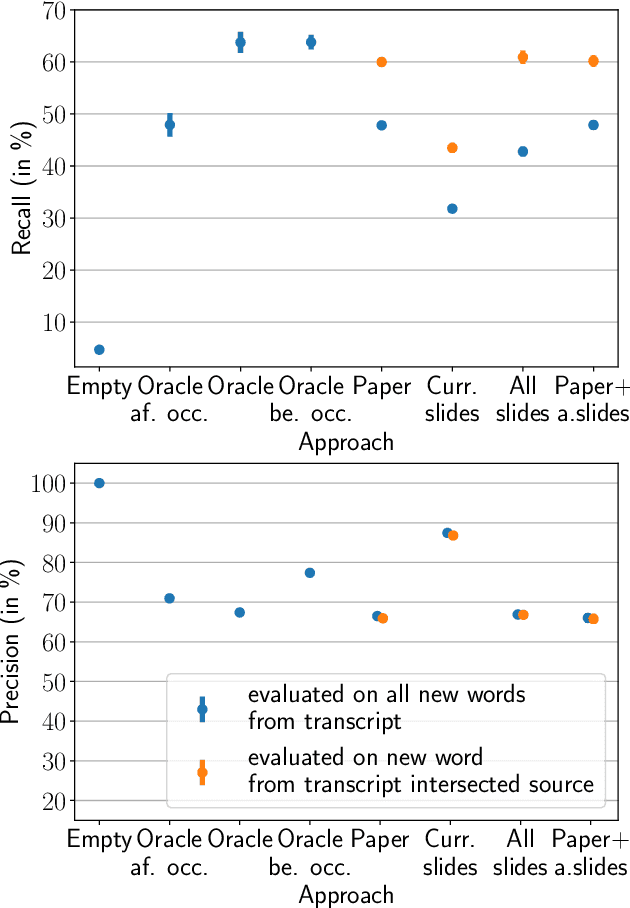
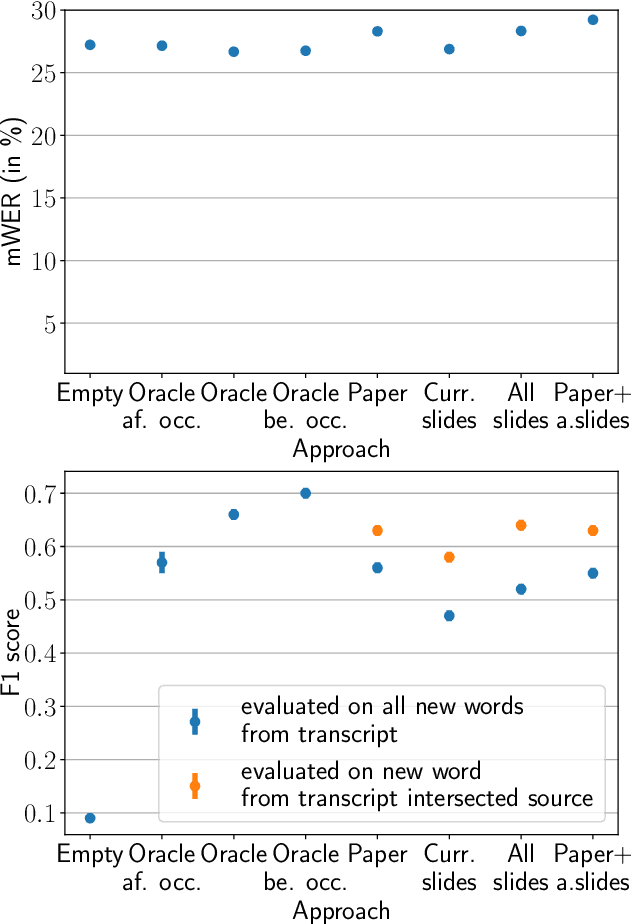
Neural sequence-to-sequence automatic speech recognition (ASR) systems are in principle open vocabulary systems, when using appropriate modeling units. In practice, however, they often fail to recognize words not seen during training, e.g., named entities, numbers or technical terms. To alleviate this problem, Huber et al. proposed to supplement an end-to-end ASR system with a word/phrase memory and a mechanism to access this memory to recognize the words and phrases correctly. In this paper we study, a) methods to acquire important words for this memory dynamically and, b) the trade-off between improvement in recognition accuracy of new words and the potential danger of false alarms for those added words. We demonstrate significant improvements in the detection rate of new words with only a minor increase in false alarms (F1 score 0.30 $\rightarrow$ 0.80), when using an appropriate number of new words. In addition, we show that important keywords can be extracted from supporting documents and used effectively.