 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"speech": models, code, and papers
Spoken Speech Enhancement using EEG
Sep 13, 2019

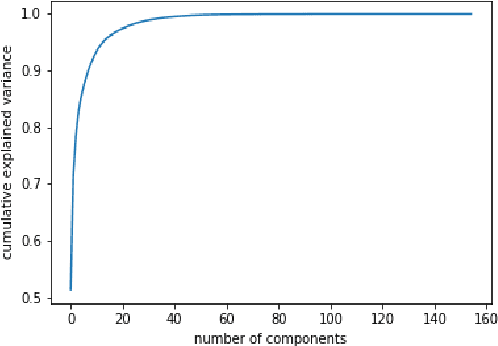
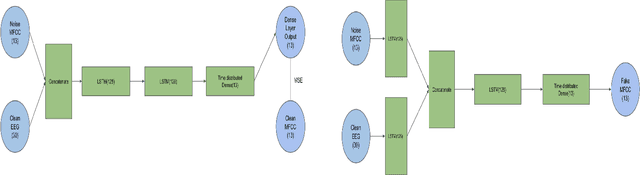
In this paper we demonstrate spoken speech enhancement using electroencephalography (EEG) signals using a generative adversarial network (GAN) based model and Long short-term Memory (LSTM) regression based model. Our results demonstrate that EEG features can be used to clean speech recorded in presence of background noise.
Emotional Speaker Identification using a Novel Capsule Nets Model
Jan 09, 2022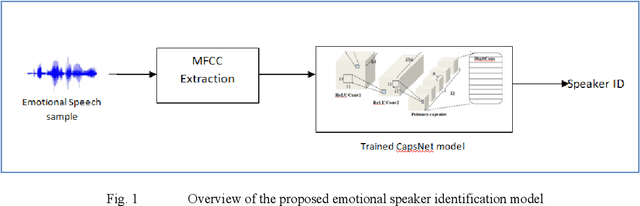

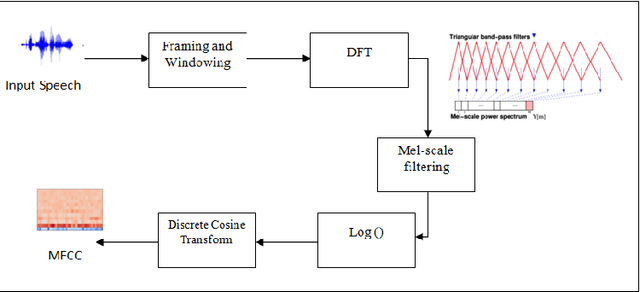
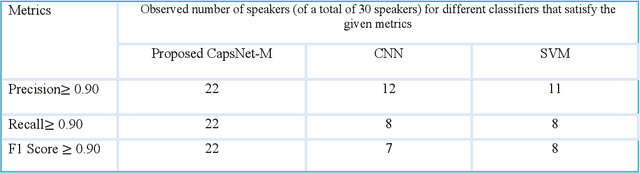
Speaker recognition systems are widely used in various applications to identify a person by their voice; however, the high degree of variability in speech signals makes this a challenging task. Dealing with emotional variations is very difficult because emotions alter the voice characteristics of a person; thus, the acoustic features differ from those used to train models in a neutral environment. Therefore, speaker recognition models trained on neutral speech fail to correctly identify speakers under emotional stress. Although considerable advancements in speaker identification have been made using convolutional neural networks (CNN), CNNs cannot exploit the spatial association between low-level features. Inspired by the recent introduction of capsule networks (CapsNets), which are based on deep learning to overcome the inadequacy of CNNs in preserving the pose relationship between low-level features with their pooling technique, this study investigates the performance of using CapsNets in identifying speakers from emotional speech recordings. A CapsNet-based speaker identification model is proposed and evaluated using three distinct speech databases, i.e., the Emirati Speech Database, SUSAS Dataset, and RAVDESS (open-access). The proposed model is also compared to baseline systems. Experimental results demonstrate that the novel proposed CapsNet model trains faster and provides better results over current state-of-the-art schemes. The effect of the routing algorithm on speaker identification performance was also studied by varying the number of iterations, both with and without a decoder network.
Quadrupedal Robotic Guide Dog with Vocal Human-Robot Interaction
Nov 25, 2021
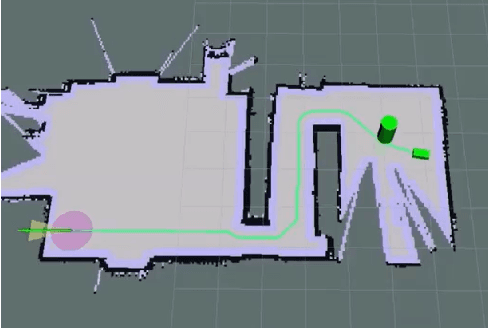
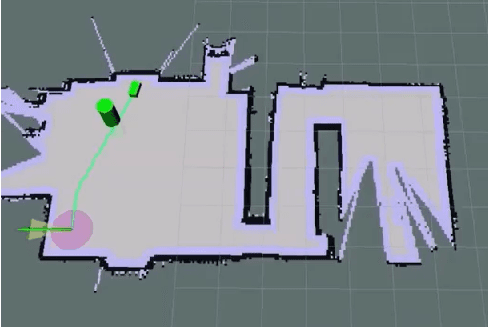
Guide dogs play a critical role in the lives of many, however training them is a time- and labor-intensive process. We are developing a method to allow an autonomous robot to physically guide humans using direct human-robot communication. The proposed algorithm will be deployed on a Unitree A1 quadrupedal robot and will autonomously navigate the person to their destination while communicating with the person using a speech interface compatible with the robot. This speech interface utilizes cloud based services such as Amazon Polly and Google Cloud to serve as the text-to-speech and speech-to-text engines.
EAT: Enhanced ASR-TTS for Self-supervised Speech Recognition
Apr 13, 2021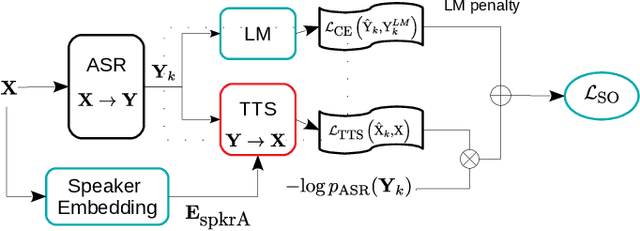
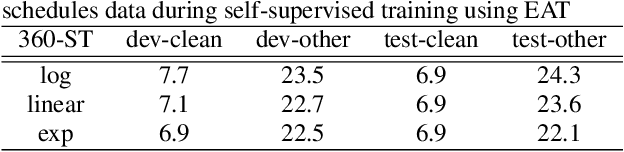
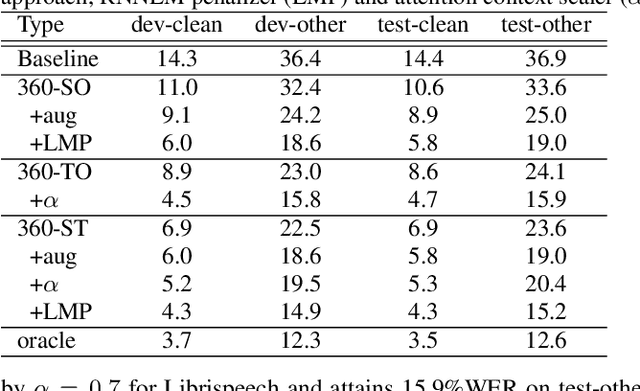
Self-supervised ASR-TTS models suffer in out-of-domain data conditions. Here we propose an enhanced ASR-TTS (EAT) model that incorporates two main features: 1) The ASR$\rightarrow$TTS direction is equipped with a language model reward to penalize the ASR hypotheses before forwarding it to TTS. 2) In the TTS$\rightarrow$ASR direction, a hyper-parameter is introduced to scale the attention context from synthesized speech before sending it to ASR to handle out-of-domain data. Training strategies and the effectiveness of the EAT model are explored under out-of-domain data conditions. The results show that EAT reduces the performance gap between supervised and self-supervised training significantly by absolute 2.6\% and 2.7\% on Librispeech and BABEL respectively.
The INTERSPEECH 2021 Computational Paralinguistics Challenge: COVID-19 Cough, COVID-19 Speech, Escalation & Primates
Feb 24, 2021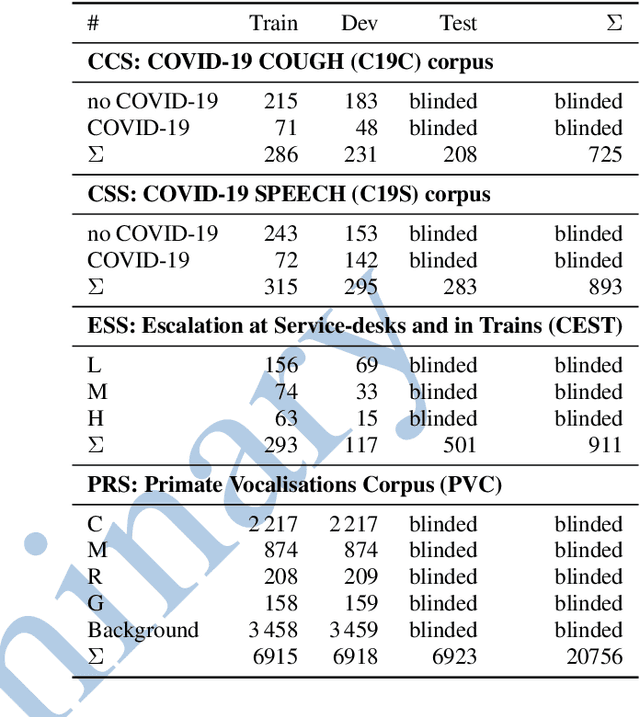
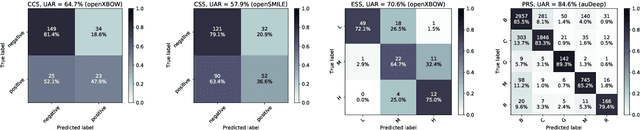
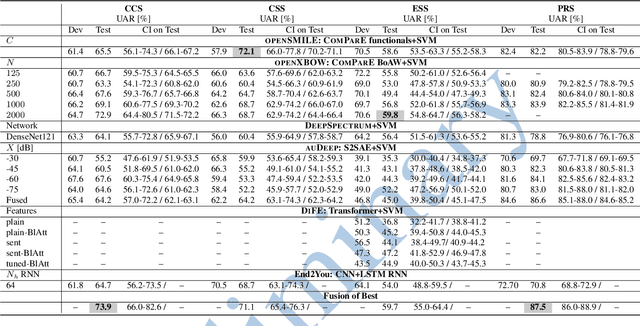
The INTERSPEECH 2021 Computational Paralinguistics Challenge addresses four different problems for the first time in a research competition under well-defined conditions: In the COVID-19 Cough and COVID-19 Speech Sub-Challenges, a binary classification on COVID-19 infection has to be made based on coughing sounds and speech; in the Escalation SubChallenge, a three-way assessment of the level of escalation in a dialogue is featured; and in the Primates Sub-Challenge, four species vs background need to be classified. We describe the Sub-Challenges, baseline feature extraction, and classifiers based on the 'usual' COMPARE and BoAW features as well as deep unsupervised representation learning using the AuDeep toolkit, and deep feature extraction from pre-trained CNNs using the Deep Spectrum toolkit; in addition, we add deep end-to-end sequential modelling, and partially linguistic analysis.
HaGRID - HAnd Gesture Recognition Image Dataset
Jun 16, 2022
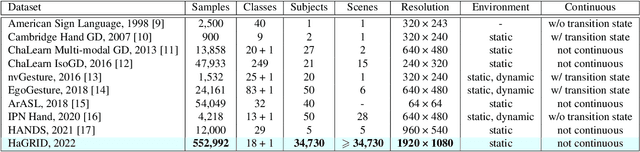
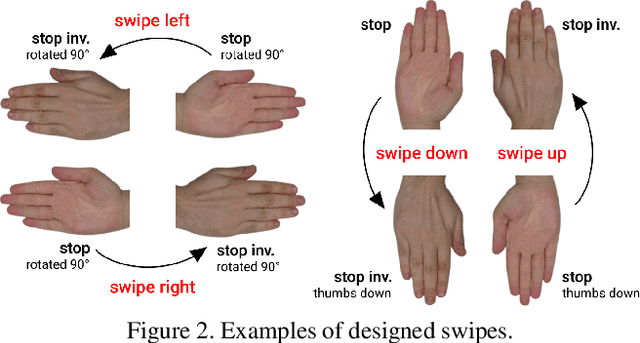
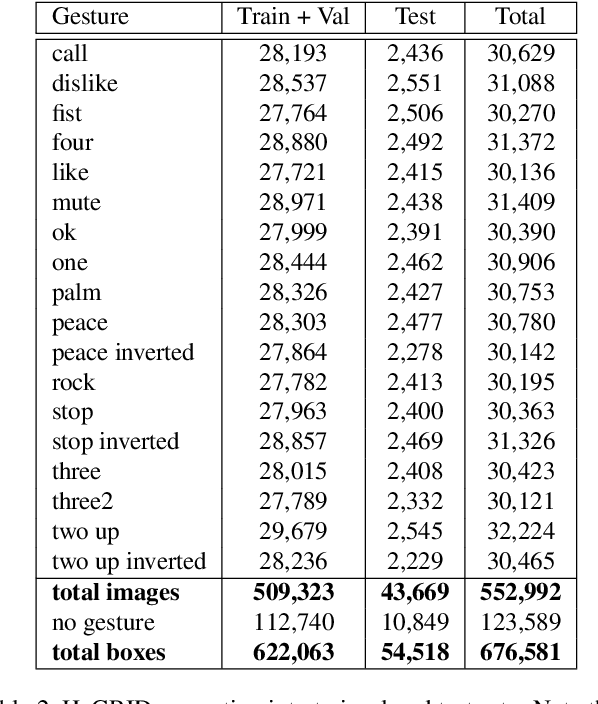
In this paper, we introduce an enormous dataset HaGRID (HAnd Gesture Recognition Image Dataset) for hand gesture recognition (HGR) systems. This dataset contains 552,992 samples divided into 18 classes of gestures. The annotations consist of bounding boxes of hands with gesture labels and markups of leading hands. The proposed dataset allows for building HGR systems, which can be used in video conferencing services, home automation systems, the automotive sector, services for people with speech and hearing impairments, etc. We are especially focused on interaction with devices to manage them. That is why all 18 chosen gestures are functional, familiar to the majority of people, and may be an incentive to take some action. In addition, we used crowdsourcing platforms to collect the dataset and took into account various parameters to ensure data diversity. We describe the challenges of using existing HGR datasets for our task and provide a detailed overview of them. Furthermore, the baselines for the hand detection and gesture classification tasks are proposed.
Visually Guided Self Supervised Learning of Speech Representations
Jan 13, 2020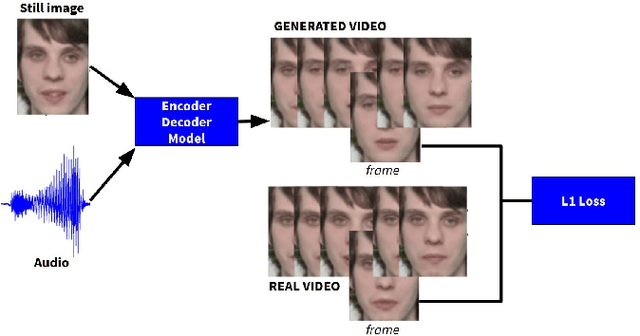
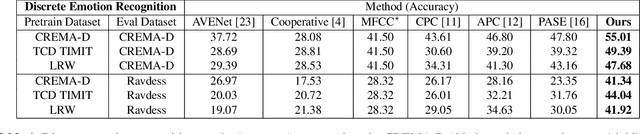
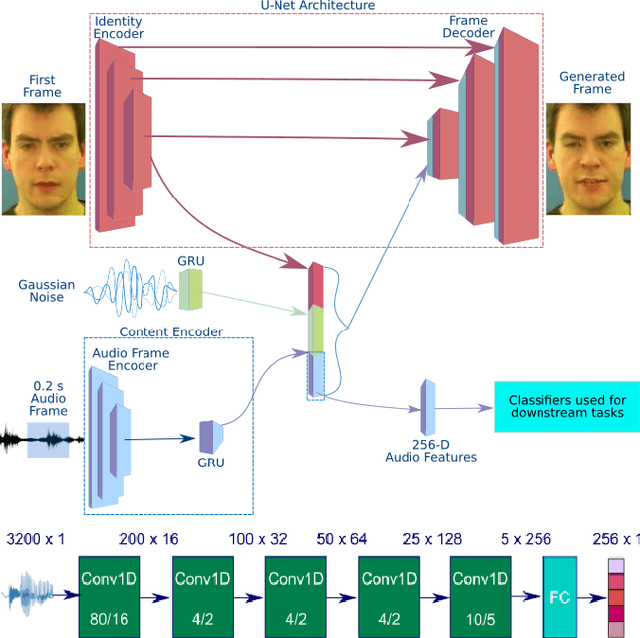
Self supervised representation learning has recently attracted a lot of research interest for both the audio and visual modalities. However, most works typically focus on a particular modality or feature alone and there has been very limited work that studies the interaction between the two modalities for learning self supervised representations. We propose a framework for learning audio representations guided by the visual modality in the context of audiovisual speech. We employ a generative audio-to-video training scheme in which we animate a still image corresponding to a given audio clip and optimize the generated video to be as close as possible to the real video of the speech segment. Through this process, the audio encoder network learns useful speech representations that we evaluate on emotion recognition and speech recognition. We achieve state of the art results for emotion recognition and competitive results for speech recognition. This demonstrates the potential of visual supervision for learning audio representations as a novel way for self-supervised learning which has not been explored in the past. The proposed unsupervised audio features can leverage a virtually unlimited amount of training data of unlabelled audiovisual speech and have a large number of potentially promising applications.
Closing the Gap between Single-User and Multi-User VoiceFilter-Lite
Feb 24, 2022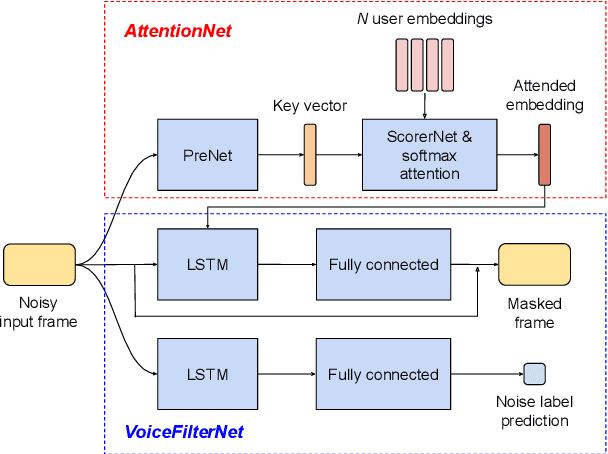
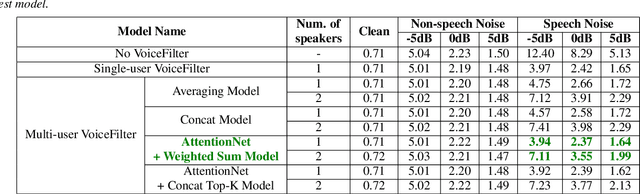
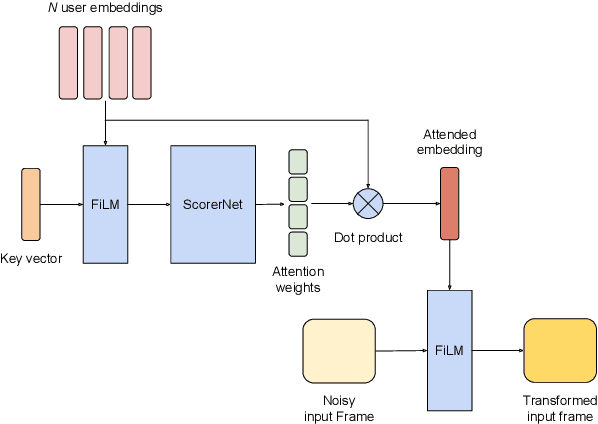
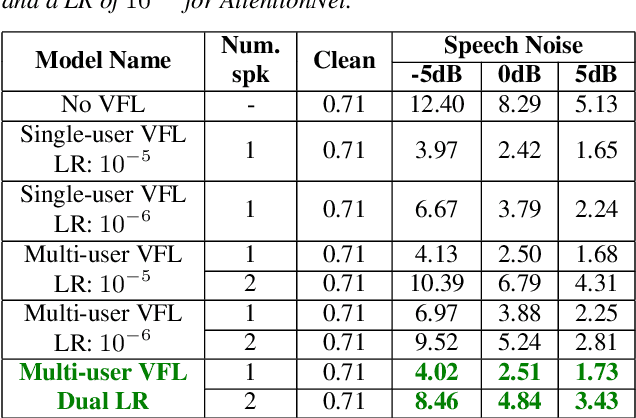
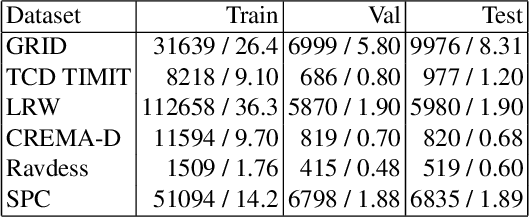
VoiceFilter-Lite is a speaker-conditioned voice separation model that plays a crucial role in improving speech recognition and speaker verification by suppressing overlapping speech from non-target speakers. However, one limitation of VoiceFilter-Lite, and other speaker-conditioned speech models in general, is that these models are usually limited to a single target speaker. This is undesirable as most smart home devices now support multiple enrolled users. In order to extend the benefits of personalization to multiple users, we previously developed an attention-based speaker selection mechanism and applied it to VoiceFilter-Lite. However, the original multi-user VoiceFilter-Lite model suffers from significant performance degradation compared with single-user models. In this paper, we devised a series of experiments to improve the multi-user VoiceFilter-Lite model. By incorporating a dual learning rate schedule and by using feature-wise linear modulation (FiLM) to condition the model with the attended speaker embedding, we successfully closed the performance gap between multi-user and single-user VoiceFilter-Lite models on single-speaker evaluations. At the same time, the new model can also be easily extended to support any number of users, and significantly outperforms our previously published model on multi-speaker evaluations.
Eigenresiduals for improved Parametric Speech Synthesis
Jan 02, 2020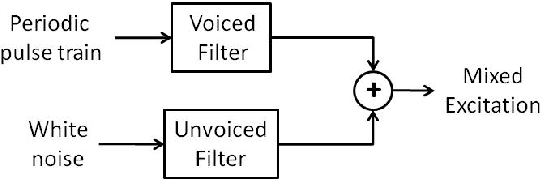
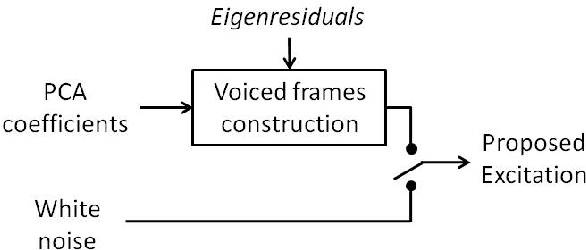
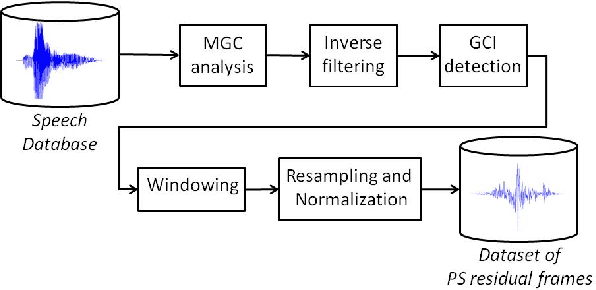
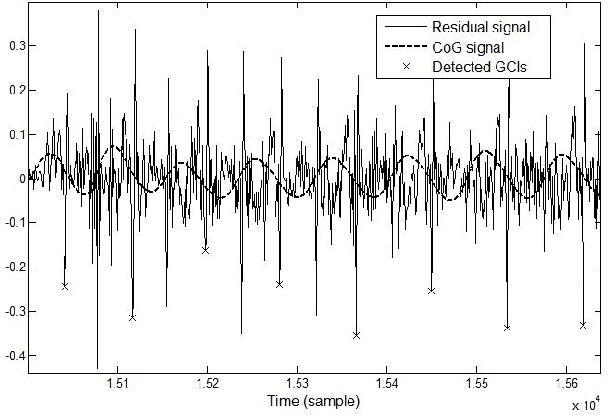
Statistical parametric speech synthesizers have recently shown their ability to produce natural-sounding and flexible voices. Unfortunately the delivered quality suffers from a typical buzziness due to the fact that speech is vocoded. This paper proposes a new excitation model in order to reduce this undesirable effect. This model is based on the decomposition of pitch-synchronous residual frames on an orthonormal basis obtained by Principal Component Analysis. This basis contains a limited number of eigenresiduals and is computed on a relatively small speech database. A stream of PCA-based coefficients is added to our HMM-based synthesizer and allows to generate the voiced excitation during the synthesis. An improvement compared to the traditional excitation is reported while the synthesis engine footprint remains under about 1Mb.
Hierarchical Attention Network for Evaluating Therapist Empathy in Counseling Session
Mar 31, 2022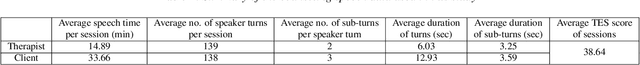
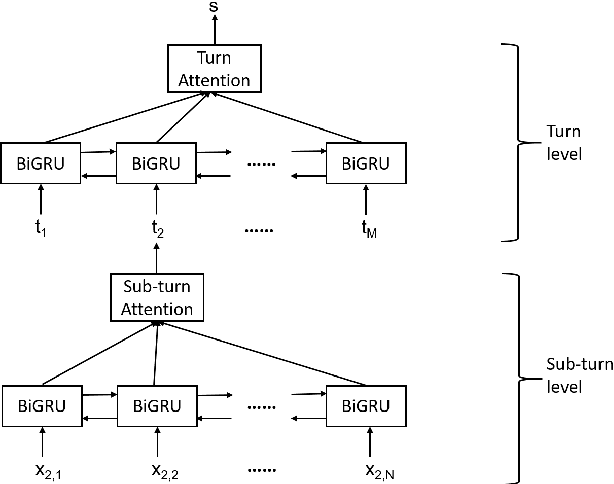
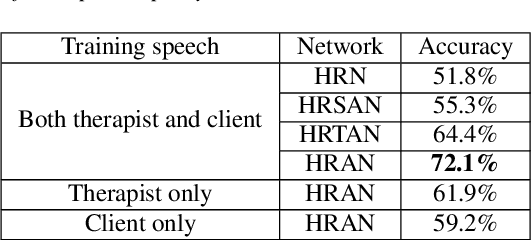
Counseling typically takes the form of spoken conversation between a therapist and a client. The empathy level expressed by the therapist is considered to be an essential quality factor of counseling outcome. This paper proposes a hierarchical recurrent network combined with two-level attention mechanisms to determine the therapist's empathy level solely from the acoustic features of conversational speech in a counseling session. The experimental results show that the proposed model can achieve an accuracy of 72.1% in classifying the therapist's empathy level as being "high" or "low". It is found that the speech from both the therapist and the client are contributing to predicting the empathy level that is subjectively rated by an expert observer. By analyzing speaker turns assigned with high attention weights, it is observed that 2 to 6 consecutive turns should be considered together to provide useful clues for detecting empathy, and the observer tends to take the whole session into consideration when rating the therapist empathy, instead of relying on a few specific speaker turns.