 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEAT: Enhanced ASR-TTS for Self-supervised Speech Recognition
Paper and Code
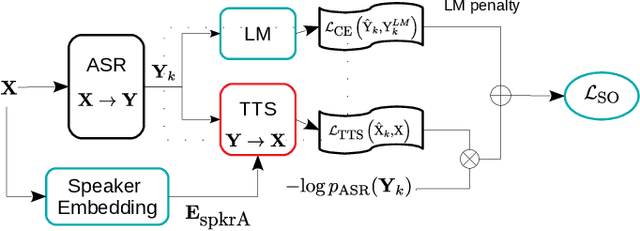
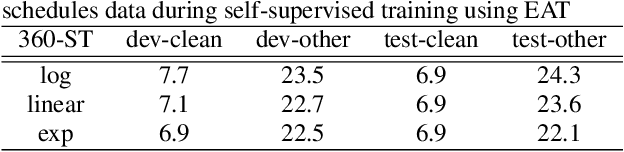
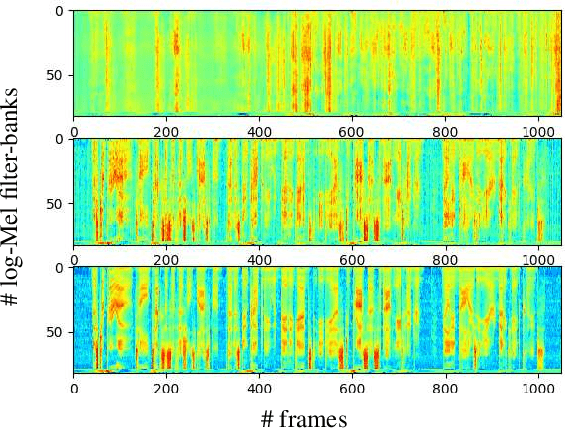
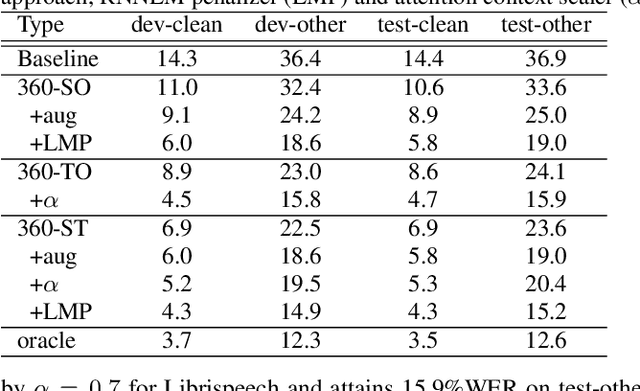
Self-supervised ASR-TTS models suffer in out-of-domain data conditions. Here we propose an enhanced ASR-TTS (EAT) model that incorporates two main features: 1) The ASR$\rightarrow$TTS direction is equipped with a language model reward to penalize the ASR hypotheses before forwarding it to TTS. 2) In the TTS$\rightarrow$ASR direction, a hyper-parameter is introduced to scale the attention context from synthesized speech before sending it to ASR to handle out-of-domain data. Training strategies and the effectiveness of the EAT model are explored under out-of-domain data conditions. The results show that EAT reduces the performance gap between supervised and self-supervised training significantly by absolute 2.6\% and 2.7\% on Librispeech and BABEL respectively.