 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEigenresiduals for improved Parametric Speech Synthesis
Jan 02, 2020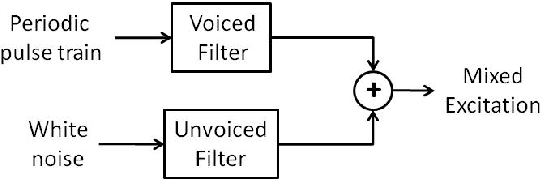
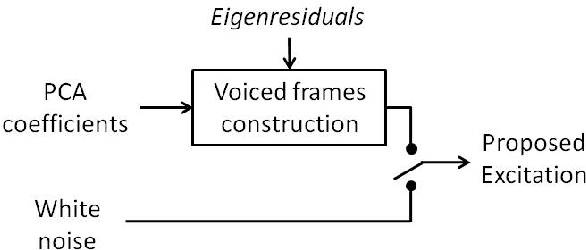
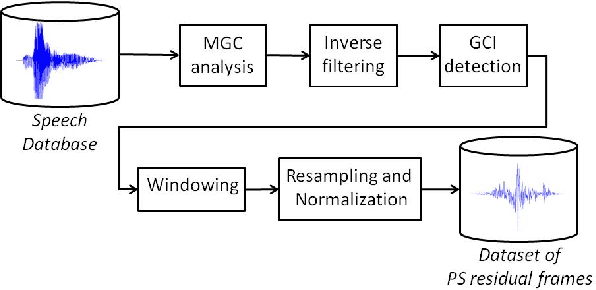
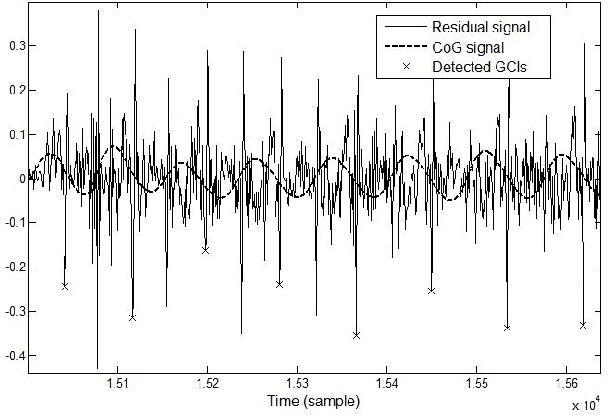
Statistical parametric speech synthesizers have recently shown their ability to produce natural-sounding and flexible voices. Unfortunately the delivered quality suffers from a typical buzziness due to the fact that speech is vocoded. This paper proposes a new excitation model in order to reduce this undesirable effect. This model is based on the decomposition of pitch-synchronous residual frames on an orthonormal basis obtained by Principal Component Analysis. This basis contains a limited number of eigenresiduals and is computed on a relatively small speech database. A stream of PCA-based coefficients is added to our HMM-based synthesizer and allows to generate the voiced excitation during the synthesis. An improvement compared to the traditional excitation is reported while the synthesis engine footprint remains under about 1Mb.
Using a Pitch-Synchronous Residual Codebook for Hybrid HMM/Frame Selection Speech Synthesis
Dec 30, 2019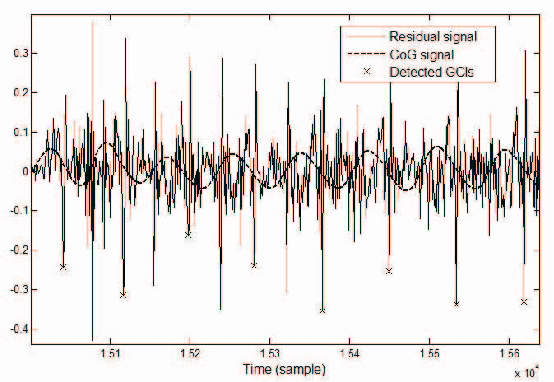
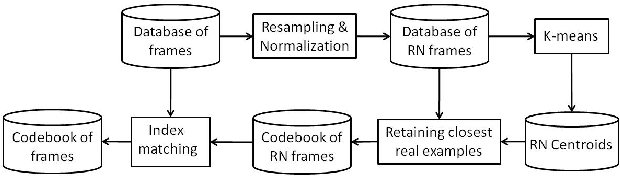
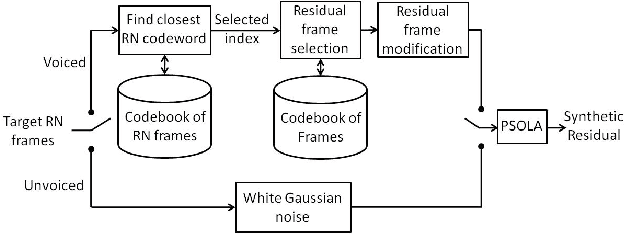
This paper proposes a method to improve the quality delivered by statistical parametric speech synthesizers. For this, we use a codebook of pitch-synchronous residual frames, so as to construct a more realistic source signal. First a limited codebook of typical excitations is built from some training database. During the synthesis part, HMMs are used to generate filter and source coefficients. The latter coefficients contain both the pitch and a compact representation of target residual frames. The source signal is obtained by concatenating excitation frames picked up from the codebook, based on a selection criterion and taking target residual coefficients as input. Subjective results show a relevant improvement compared to the basic technique.
A Deterministic plus Stochastic Model of the Residual Signal for Improved Parametric Speech Synthesis
Dec 29, 2019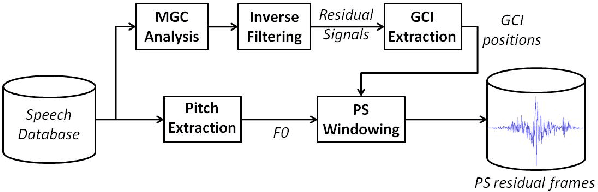
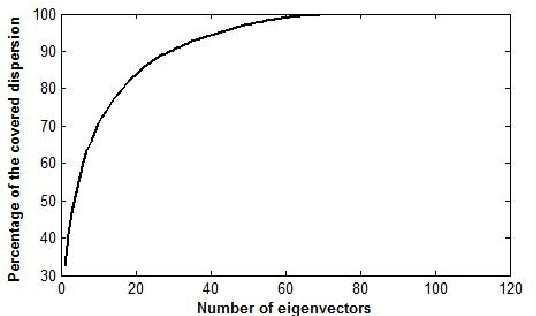
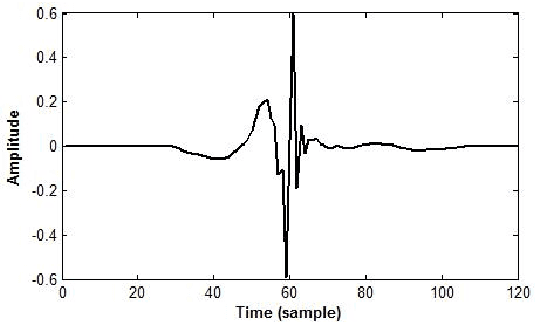
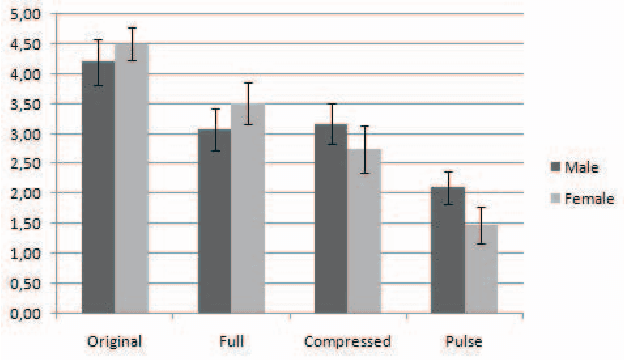
Speech generated by parametric synthesizers generally suffers from a typical buzziness, similar to what was encountered in old LPC-like vocoders. In order to alleviate this problem, a more suited modeling of the excitation should be adopted. For this, we hereby propose an adaptation of the Deterministic plus Stochastic Model (DSM) for the residual. In this model, the excitation is divided into two distinct spectral bands delimited by the maximum voiced frequency. The deterministic part concerns the low-frequency contents and consists of a decomposition of pitch-synchronous residual frames on an orthonormal basis obtained by Principal Component Analysis. The stochastic component is a high-pass filtered noise whose time structure is modulated by an energy-envelope, similarly to what is done in the Harmonic plus Noise Model (HNM). The proposed residual model is integrated within a HMM-based speech synthesizer and is compared to the traditional excitation through a subjective test. Results show a significative improvement for both male and female voices. In addition the proposed model requires few computational load and memory, which is essential for its integration in commercial applications.