 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"speech": models, code, and papers
Attention-based Neural Beamforming Layers for Multi-channel Speech Recognition
May 14, 2021


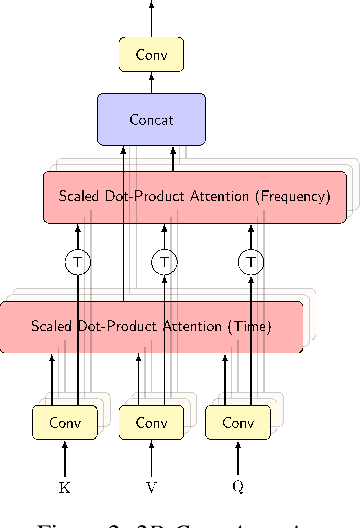

Attention-based beamformers have recently been shown to be effective for multi-channel speech recognition. However, they are less capable at capturing local information. In this work, we propose a 2D Conv-Attention module which combines convolution neural networks with attention for beamforming. We apply self- and cross-attention to explicitly model the correlations within and between the input channels. The end-to-end 2D Conv-Attention model is compared with a multi-head self-attention and superdirective-based neural beamformers. We train and evaluate on an in-house multi-channel dataset. The results show a relative improvement of 3.8% in WER by the proposed model over the baseline neural beamformer.
Non-autoregressive Transformer with Unified Bidirectional Decoder for Automatic Speech Recognition
Sep 14, 2021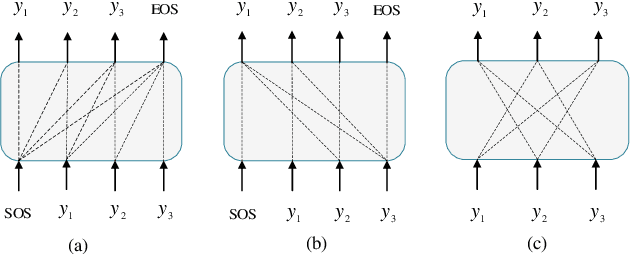
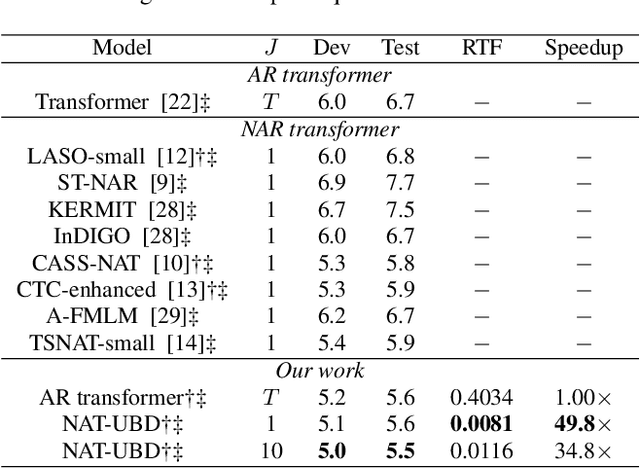
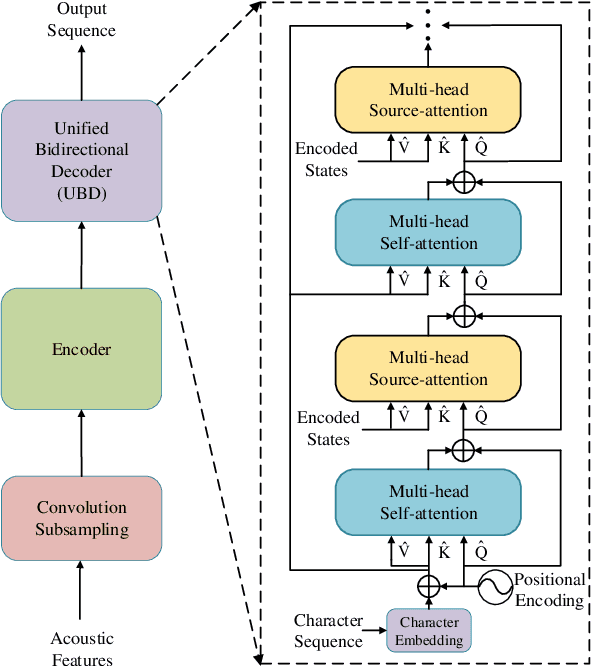

Non-autoregressive (NAR) transformer models have been studied intensively in automatic speech recognition (ASR), and a substantial part of NAR transformer models is to use the casual mask to limit token dependencies. However, the casual mask is designed for the left-to-right decoding process of the non-parallel autoregressive (AR) transformer, which is inappropriate for the parallel NAR transformer since it ignores the right-to-left contexts. Some models are proposed to utilize right-to-left contexts with an extra decoder, but these methods increase the model complexity. To tackle the above problems, we propose a new non-autoregressive transformer with a unified bidirectional decoder (NAT-UBD), which can simultaneously utilize left-to-right and right-to-left contexts. However, direct use of bidirectional contexts will cause information leakage, which means the decoder output can be affected by the character information from the input of the same position. To avoid information leakage, we propose a novel attention mask and modify vanilla queries, keys, and values matrices for NAT-UBD. Experimental results verify that NAT-UBD can achieve character error rates (CERs) of 5.0%/5.5% on the Aishell1 dev/test sets, outperforming all previous NAR transformer models. Moreover, NAT-UBD can run 49.8x faster than the AR transformer baseline when decoding in a single step.
VAW-GAN for Disentanglement and Recomposition of Emotional Elements in Speech
Nov 03, 2020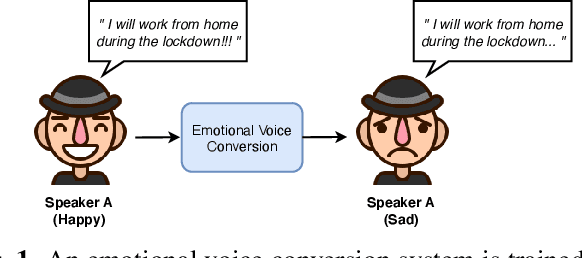
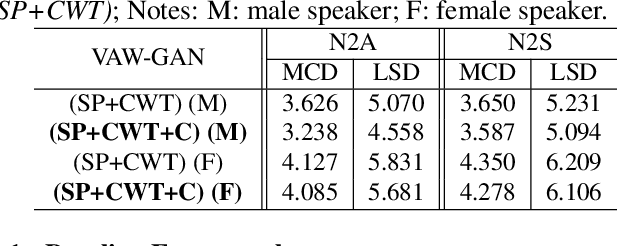
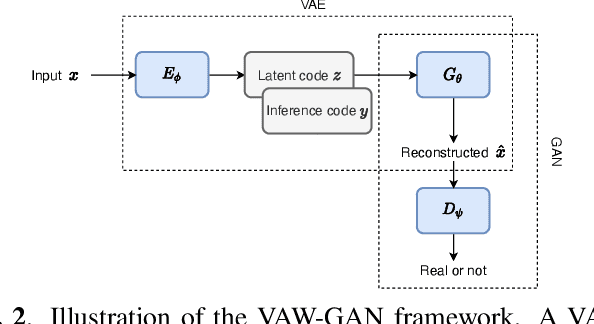
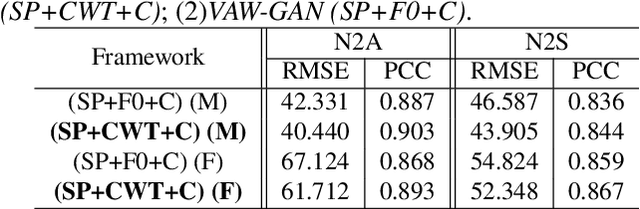
Emotional voice conversion (EVC) aims to convert the emotion of speech from one state to another while preserving the linguistic content and speaker identity. In this paper, we study the disentanglement and recomposition of emotional elements in speech through variational autoencoding Wasserstein generative adversarial network (VAW-GAN). We propose a speaker-dependent EVC framework based on VAW-GAN, that includes two VAW-GAN pipelines, one for spectrum conversion, and another for prosody conversion. We train a spectral encoder that disentangles emotion and prosody (F0) information from spectral features; we also train a prosodic encoder that disentangles emotion modulation of prosody (affective prosody) from linguistic prosody. At run-time, the decoder of spectral VAW-GAN is conditioned on the output of prosodic VAW-GAN. The vocoder takes the converted spectral and prosodic features to generate the target emotional speech. Experiments validate the effectiveness of our proposed method in both objective and subjective evaluations.
Integrating Text Inputs For Training and Adapting RNN Transducer ASR Models
Feb 26, 2022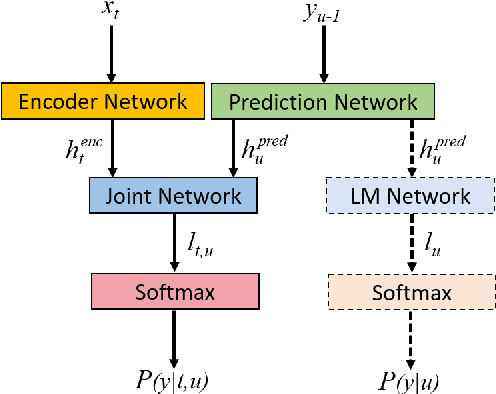
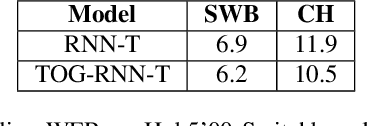
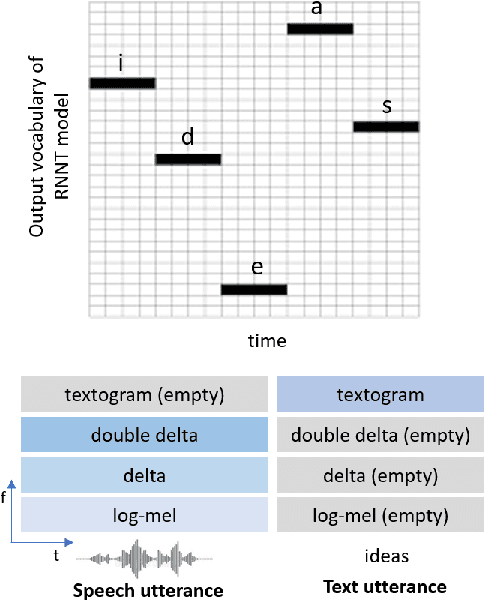
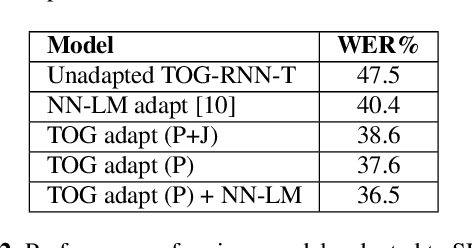
Compared to hybrid automatic speech recognition (ASR) systems that use a modular architecture in which each component can be independently adapted to a new domain, recent end-to-end (E2E) ASR system are harder to customize due to their all-neural monolithic construction. In this paper, we propose a novel text representation and training framework for E2E ASR models. With this approach, we show that a trained RNN Transducer (RNN-T) model's internal LM component can be effectively adapted with text-only data. An RNN-T model trained using both speech and text inputs improves over a baseline model trained on just speech with close to 13% word error rate (WER) reduction on the Switchboard and CallHome test sets of the NIST Hub5 2000 evaluation. The usefulness of the proposed approach is further demonstrated by customizing this general purpose RNN-T model to three separate datasets. We observe 20-45% relative word error rate (WER) reduction in these settings with this novel LM style customization technique using only unpaired text data from the new domains.
Self-Attention Channel Combinator Frontend for End-to-End Multichannel Far-field Speech Recognition
Sep 10, 2021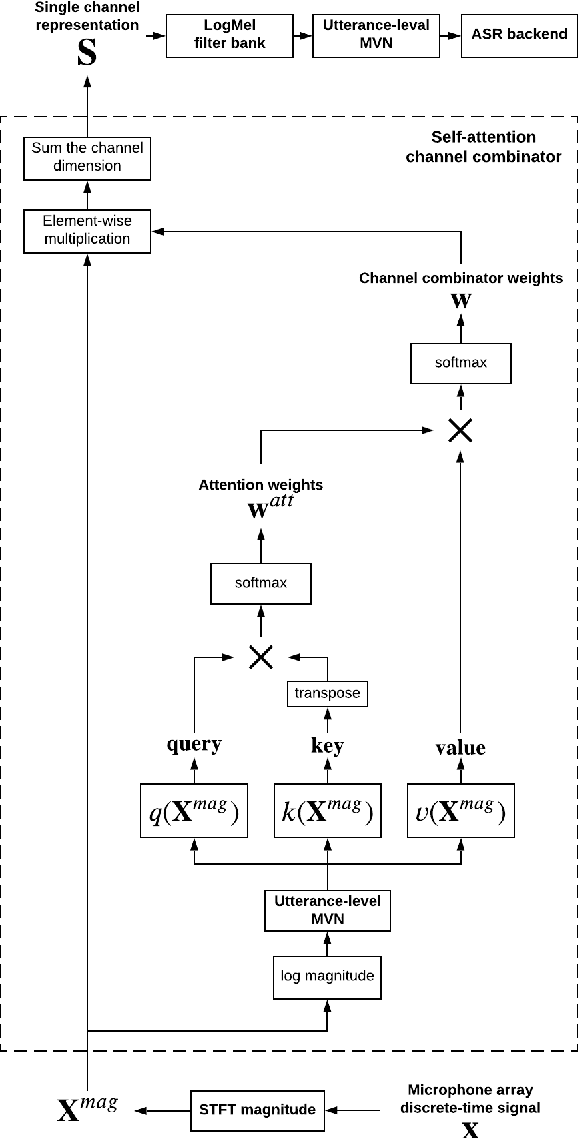
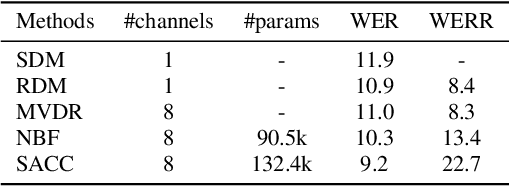
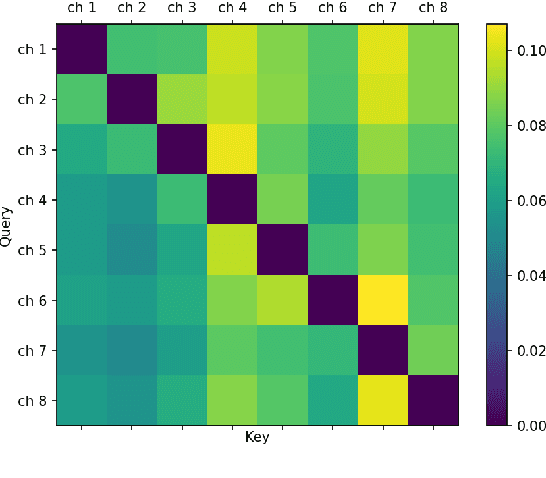
When a sufficiently large far-field training data is presented, jointly optimizing a multichannel frontend and an end-to-end (E2E) Automatic Speech Recognition (ASR) backend shows promising results. Recent literature has shown traditional beamformer designs, such as MVDR (Minimum Variance Distortionless Response) or fixed beamformers can be successfully integrated as the frontend into an E2E ASR system with learnable parameters. In this work, we propose the self-attention channel combinator (SACC) ASR frontend, which leverages the self-attention mechanism to combine multichannel audio signals in the magnitude spectral domain. Experiments conducted on a multichannel playback test data shows that the SACC achieved a 9.3% WERR compared to a state-of-the-art fixed beamformer-based frontend, both jointly optimized with a ContextNet-based ASR backend. We also demonstrate the connection between the SACC and the traditional beamformers, and analyze the intermediate outputs of the SACC.
Finnish Parliament ASR corpus - Analysis, benchmarks and statistics
Mar 28, 2022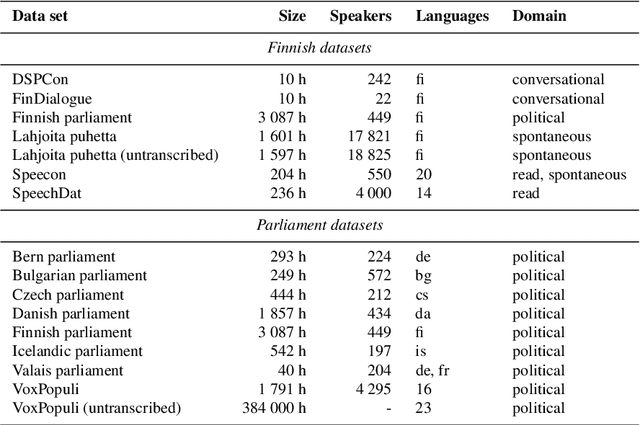
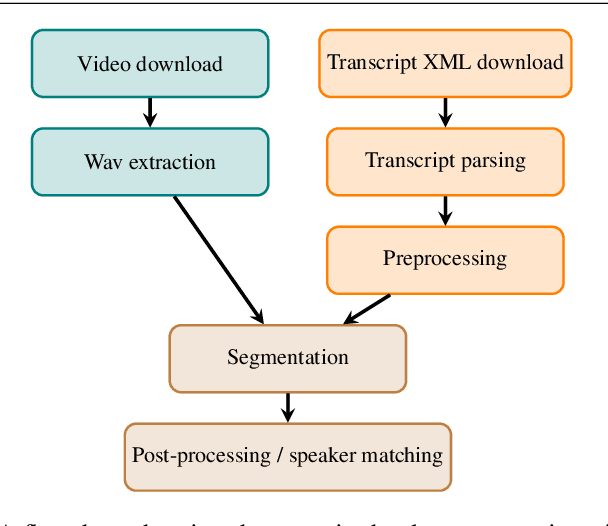

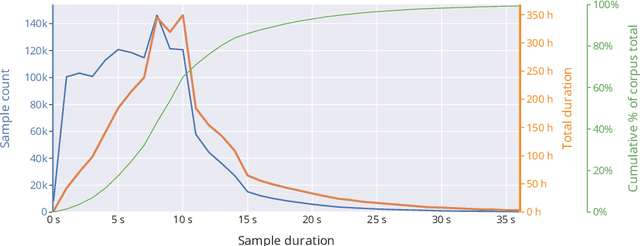
Public sources like parliament meeting recordings and transcripts provide ever-growing material for the training and evaluation of automatic speech recognition (ASR) systems. In this paper, we publish and analyse the Finnish parliament ASR corpus, the largest publicly available collection of manually transcribed speech data for Finnish with over 3000 hours of speech and 449 speakers for which it provides rich demographic metadata. This corpus builds on earlier initial work, and as a result the corpus has a natural split into two training subsets from two periods of time. Similarly, there are two official, corrected test sets covering different times, setting an ASR task with longitudinal distribution-shift characteristics. An official development set is also provided. We develop a complete Kaldi-based data preparation pipeline, and hidden Markov model (HMM), hybrid deep neural network (HMM-DNN) and attention-based encoder-decoder (AED) ASR recipes. We set benchmarks on the official test sets, as well as multiple other recently used test sets. Both temporal corpus subsets are already large, and we observe that beyond their scale, ASR performance on the official test sets plateaus, whereas other domains benefit from added data. The HMM-DNN and AED approaches are compared in a carefully matched equal data setting, with the HMM-DNN system consistently performing better. Finally, the variation of the ASR accuracy is compared between the speaker categories available in the parliament metadata to detect potential biases based on factors such as gender, age, and education.
Mondegreen: A Post-Processing Solution to Speech Recognition Error Correction for Voice Search Queries
May 20, 2021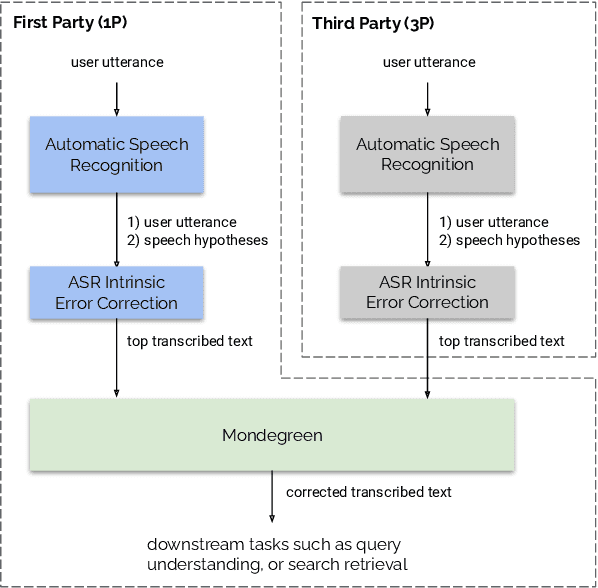
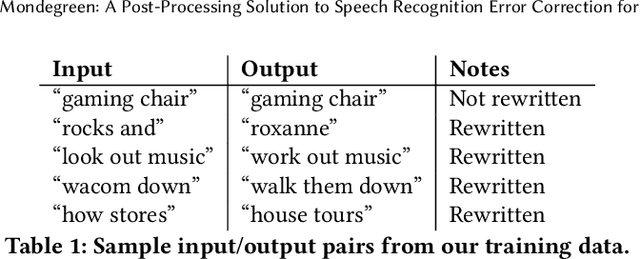
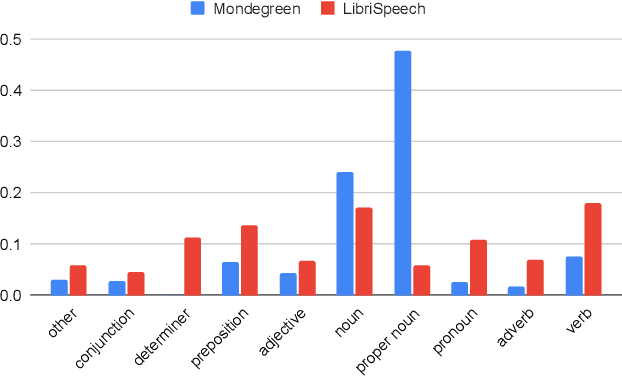
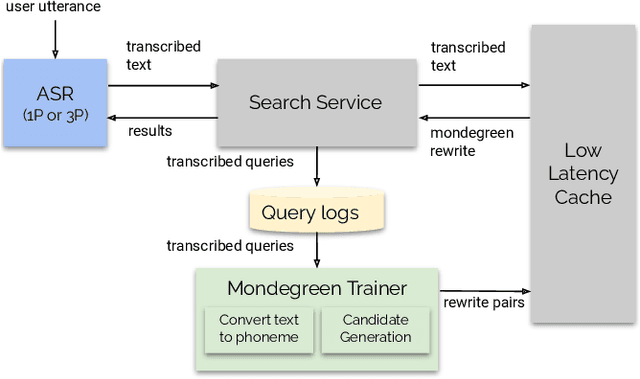
As more and more online search queries come from voice, automatic speech recognition becomes a key component to deliver relevant search results. Errors introduced by automatic speech recognition (ASR) lead to irrelevant search results returned to the user, thus causing user dissatisfaction. In this paper, we introduce an approach, Mondegreen, to correct voice queries in text space without depending on audio signals, which may not always be available due to system constraints or privacy or bandwidth (for example, some ASR systems run on-device) considerations. We focus on voice queries transcribed via several proprietary commercial ASR systems. These queries come from users making internet, or online service search queries. We first present an analysis showing how different the language distribution coming from user voice queries is from that in traditional text corpora used to train off-the-shelf ASR systems. We then demonstrate that Mondegreen can achieve significant improvements in increased user interaction by correcting user voice queries in one of the largest search systems in Google. Finally, we see Mondegreen as complementing existing highly-optimized production ASR systems, which may not be frequently retrained and thus lag behind due to vocabulary drifts.
You Do Not Need More Data: Improving End-To-End Speech Recognition by Text-To-Speech Data Augmentation
May 14, 2020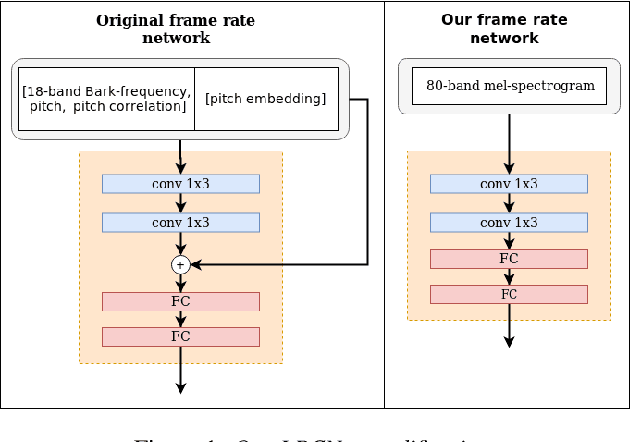
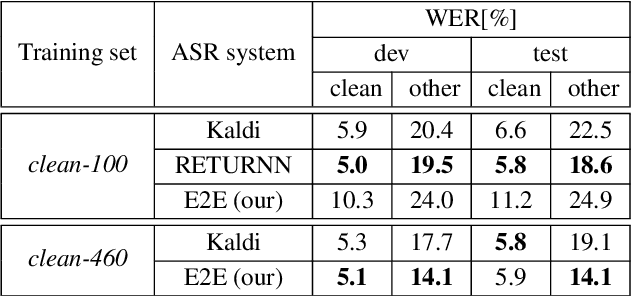
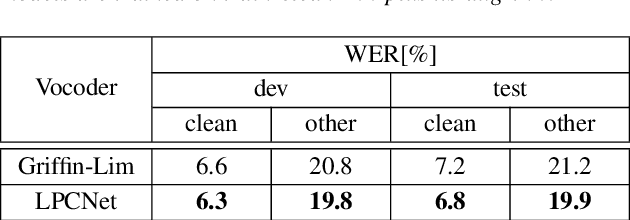
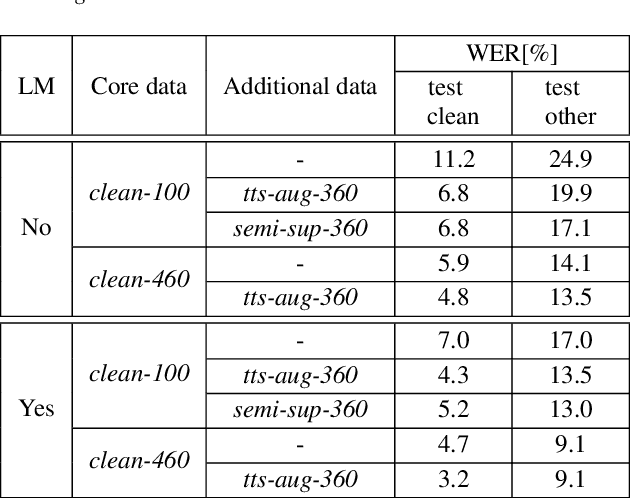
Data augmentation is one of the most effective ways to make end-to-end automatic speech recognition (ASR) perform close to the conventional hybrid approach, especially when dealing with low-resource tasks. Using recent advances in speech synthesis (text-to-speech, or TTS), we build our TTS system on an ASR training database and then extend the data with synthesized speech to train a recognition model. We argue that, when the training data amount is low, this approach can allow an end-to-end model to reach hybrid systems' quality. For an artificial low-resource setup, we compare the proposed augmentation with the semi-supervised learning technique. We also investigate the influence of vocoder usage on final ASR performance by comparing Griffin-Lim algorithm with our modified LPCNet. An external language model allows our approach to reach the quality of a comparable supervised setup and outperform a semi-supervised setup (both on test-clean). We establish a state-of-the-art result for end-to-end ASR trained on LibriSpeech train-clean-100 set with WER 4.3% on test-clean and 13.5% on test-other.
Confidence Estimation for Attention-based Sequence-to-sequence Models for Speech Recognition
Oct 23, 2020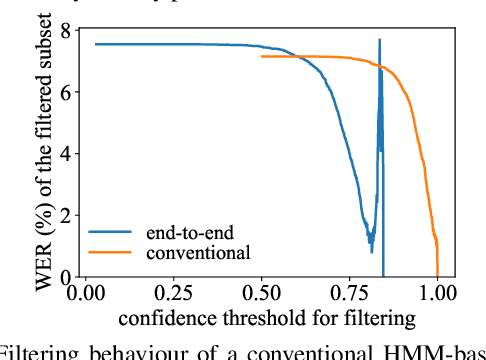
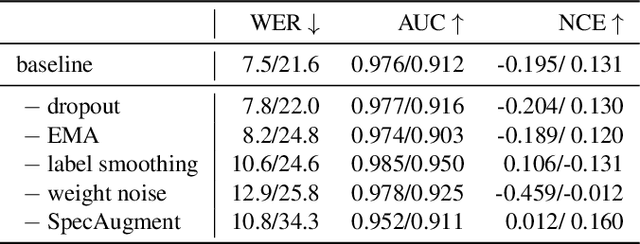
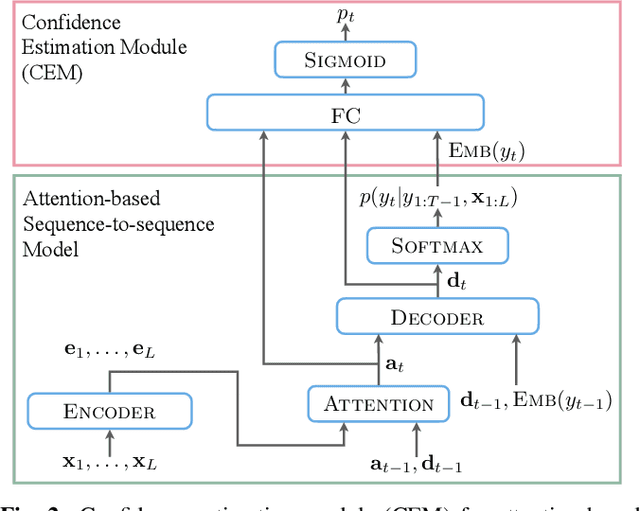
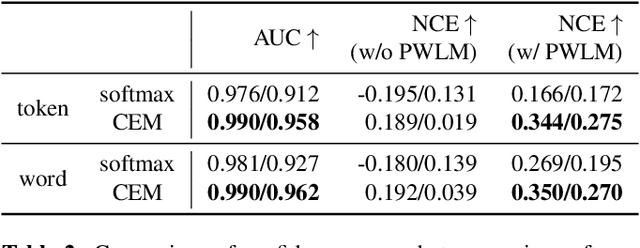
For various speech-related tasks, confidence scores from a speech recogniser are a useful measure to assess the quality of transcriptions. In traditional hidden Markov model-based automatic speech recognition (ASR) systems, confidence scores can be reliably obtained from word posteriors in decoding lattices. However, for an ASR system with an auto-regressive decoder, such as an attention-based sequence-to-sequence model, computing word posteriors is difficult. An obvious alternative is to use the decoder softmax probability as the model confidence. In this paper, we first examine how some commonly used regularisation methods influence the softmax-based confidence scores and study the overconfident behaviour of end-to-end models. Then we propose a lightweight and effective approach named confidence estimation module (CEM) on top of an existing end-to-end ASR model. Experiments on LibriSpeech show that CEM can mitigate the overconfidence problem and can produce more reliable confidence scores with and without shallow fusion of a language model. Further analysis shows that CEM generalises well to speech from a moderately mismatched domain and can potentially improve downstream tasks such as semi-supervised learning.
Dialogue Enhancement and Listening Effort in Broadcast Audio: A Multimodal Evaluation
Aug 03, 2022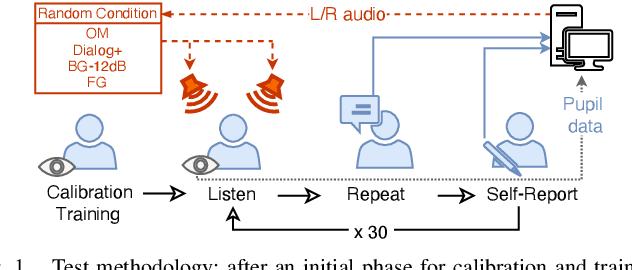
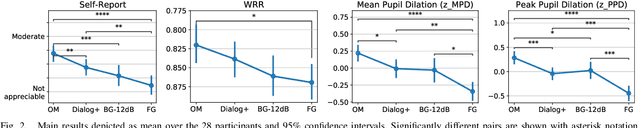
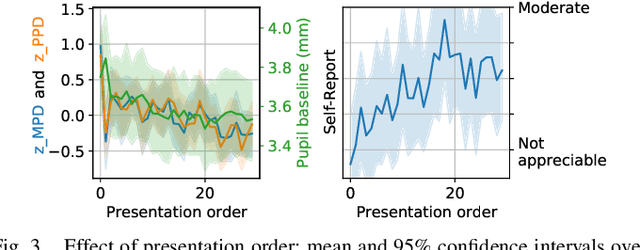
Dialogue enhancement (DE) plays a vital role in broadcasting, enabling the personalization of the relative level between foreground speech and background music and effects. DE has been shown to improve the quality of experience, intelligibility, and self-reported listening effort (LE). A physiological indicator of LE known from audiology studies is pupil size. The relation between pupil size and LE is typically studied using artificial sentences and background noises not encountered in broadcast content. This work evaluates the effect of DE on LE in a multimodal manner that includes pupil size (tracked by a VR headset) and real-world audio excerpts from TV. Under ideal listening conditions, 28 normal-hearing participants listened to 30 audio excerpts presented in random order and processed by conditions varying the relative level between foreground and background audio. One of these conditions employed a recently proposed source separation system to attenuate the background given the original mixture as the sole input. After listening to each excerpt, subjects were asked to repeat the heard sentence and self-report the LE. Mean pupil dilation and peak pupil dilation were analyzed and compared with the self-report and the word recall rate. The multimodal evaluation shows a consistent trend of decreasing LE along with decreasing background level. DE, also when enabled by source separation, significantly reduces the pupil size as well as the self-reported LE. This highlights the benefit of personalization functionalities at the user's end.