 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeXANE Background Acoustic Embeddings: Ablation and Clustering Analysis
Jul 08, 2024We explore the recently proposed explainable acoustic neural embedding~(XANE) system that models the background acoustics of a speech signal in a non-intrusive manner. The XANE embeddings are used to estimate specific parameters related to the background acoustic properties of the signal which allows the embeddings to be explainable in terms of those parameters. We perform ablation studies on the XANE system and show that estimating all acoustic parameters jointly has an overall positive effect. Furthermore, we illustrate the value of XANE embeddings by performing clustering experiments on unseen test data and show that the proposed embeddings achieve a mean F1 score of 92\% for three different tasks, outperforming significantly the WavLM based signal embeddings and are complimentary to speaker embeddings.
XANE: eXplainable Acoustic Neural Embeddings
Jun 07, 2024We present a novel method for extracting neural embeddings that model the background acoustics of a speech signal. The extracted embeddings are used to estimate specific parameters related to the background acoustic properties of the signal in a non-intrusive manner, which allows the embeddings to be explainable in terms of those parameters. We illustrate the value of these embeddings by performing clustering experiments on unseen test data and show that the proposed embeddings achieve a mean F1 score of 95.2\% for three different tasks, outperforming significantly the WavLM based signal embeddings. We also show that the proposed method can explain the embeddings by estimating 14 acoustic parameters characterizing the background acoustics, including reverberation and noise levels, overlapped speech detection, CODEC type detection and noise type detection with high accuracy and a real-time factor 17 times lower than an external baseline method.
Spatial Processing Front-End For Distant ASR Exploiting Self-Attention Channel Combinator
Mar 25, 2022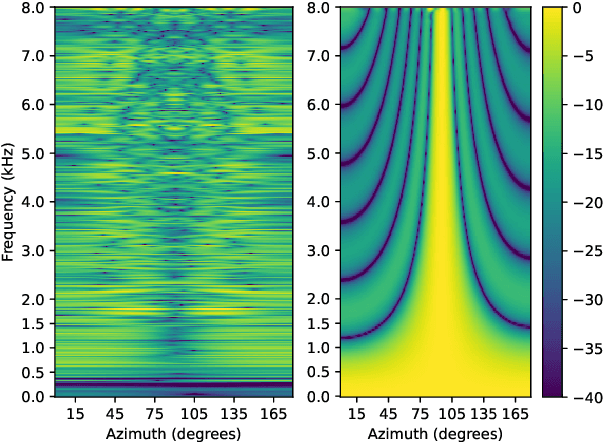
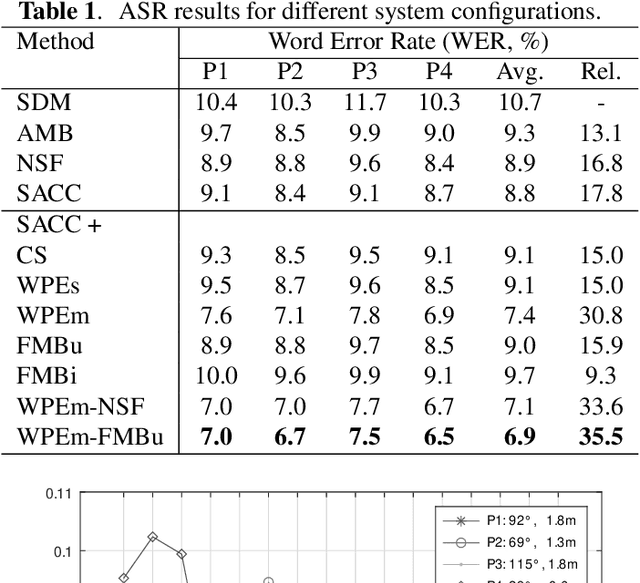
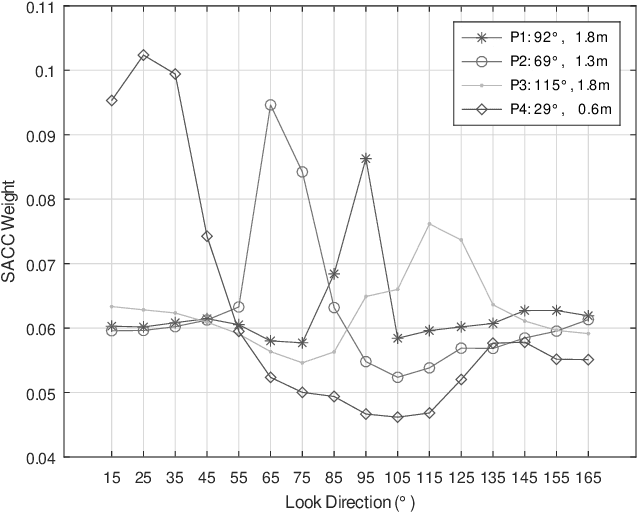
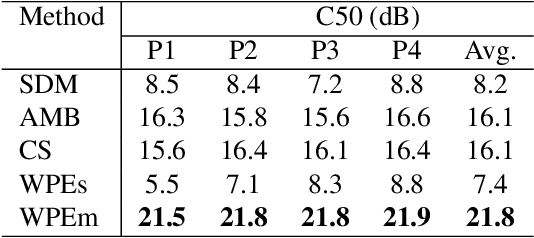
We present a novel multi-channel front-end based on channel shortening with theWeighted Prediction Error (WPE) method followed by a fixed MVDR beamformer used in combination with a recently proposed self-attention-based channel combination (SACC) scheme, for tackling the distant ASR problem. We show that the proposed system used as part of a ContextNet based end-to-end (E2E) ASR system outperforms leading ASR systems as demonstrated by a 21.6% reduction in relative WER on a multi-channel LibriSpeech playback dataset. We also show how dereverberation prior to beamforming is beneficial and compare the WPE method with a modified neural channel shortening approach. An analysis of the non-intrusive estimate of the signal C50 confirms that the 8 channel WPE method provides significant dereverberation of the signals (13.6 dB improvement). We also show how the weights of the SACC system allow the extraction of accurate spatial information which can be beneficial for other speech processing applications like diarization.
ChannelAugment: Improving generalization of multi-channel ASR by training with input channel randomization
Sep 23, 2021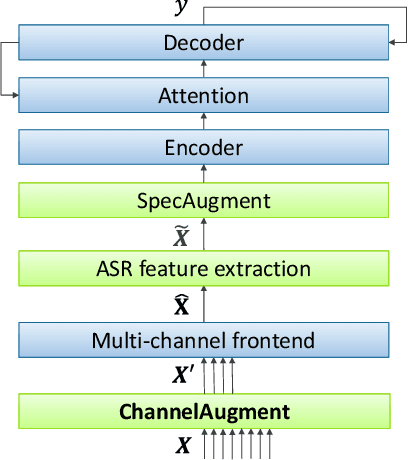
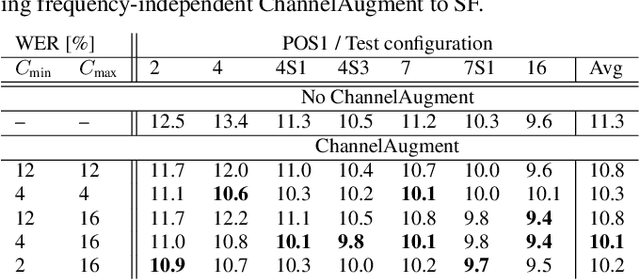
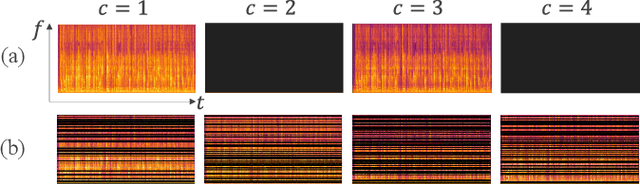
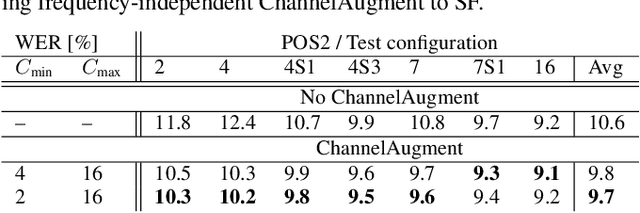
End-to-end (E2E) multi-channel ASR systems show state-of-the-art performance in far-field ASR tasks by joint training of a multi-channel front-end along with the ASR model. The main limitation of such systems is that they are usually trained with data from a fixed array geometry, which can lead to degradation in accuracy when a different array is used in testing. This makes it challenging to deploy these systems in practice, as it is costly to retrain and deploy different models for various array configurations. To address this, we present a simple and effective data augmentation technique, which is based on randomly dropping channels in the multi-channel audio input during training, in order to improve the robustness to various array configurations at test time. We call this technique ChannelAugment, in contrast to SpecAugment (SA) which drops time and/or frequency components of a single channel input audio. We apply ChannelAugment to the Spatial Filtering (SF) and Minimum Variance Distortionless Response (MVDR) neural beamforming approaches. For SF, we observe 10.6% WER improvement across various array configurations employing different numbers of microphones. For MVDR, we achieve a 74% reduction in training time without causing degradation of recognition accuracy.
Self-Attention Channel Combinator Frontend for End-to-End Multichannel Far-field Speech Recognition
Sep 10, 2021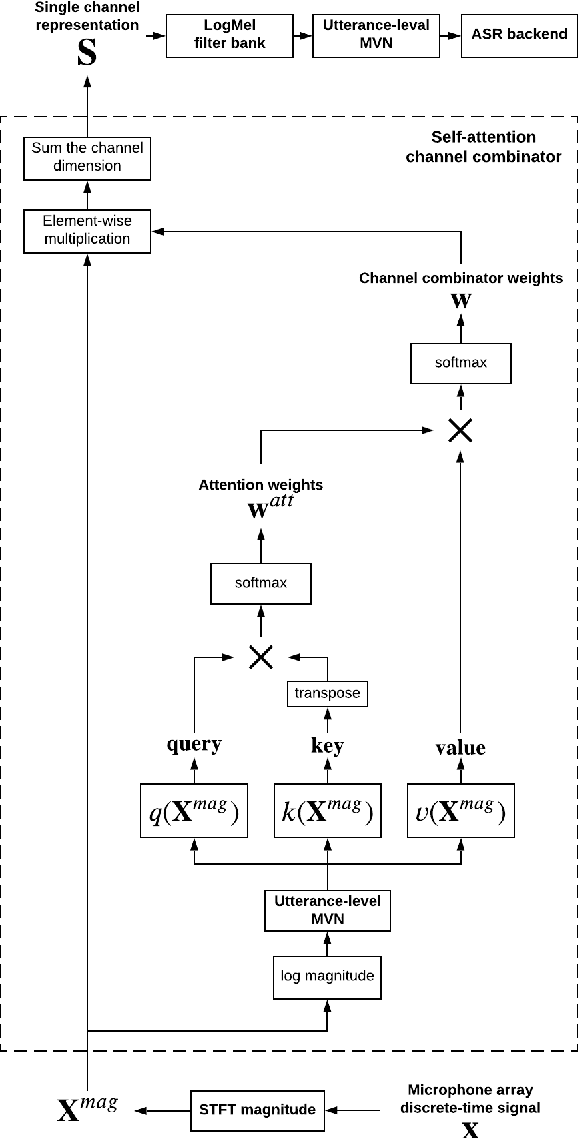
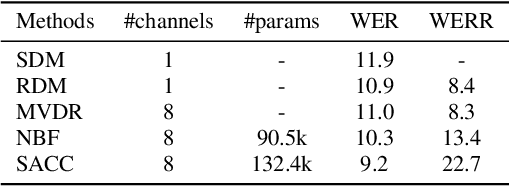
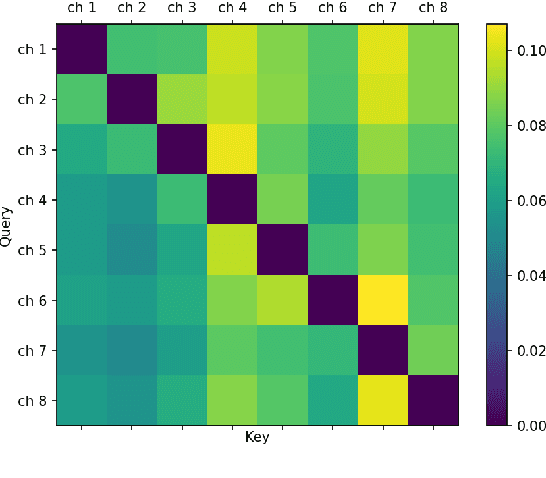
When a sufficiently large far-field training data is presented, jointly optimizing a multichannel frontend and an end-to-end (E2E) Automatic Speech Recognition (ASR) backend shows promising results. Recent literature has shown traditional beamformer designs, such as MVDR (Minimum Variance Distortionless Response) or fixed beamformers can be successfully integrated as the frontend into an E2E ASR system with learnable parameters. In this work, we propose the self-attention channel combinator (SACC) ASR frontend, which leverages the self-attention mechanism to combine multichannel audio signals in the magnitude spectral domain. Experiments conducted on a multichannel playback test data shows that the SACC achieved a 9.3% WERR compared to a state-of-the-art fixed beamformer-based frontend, both jointly optimized with a ContextNet-based ASR backend. We also demonstrate the connection between the SACC and the traditional beamformers, and analyze the intermediate outputs of the SACC.