 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"speech": models, code, and papers
Tree-constrained Pointer Generator for End-to-end Contextual Speech Recognition
Sep 17, 2021
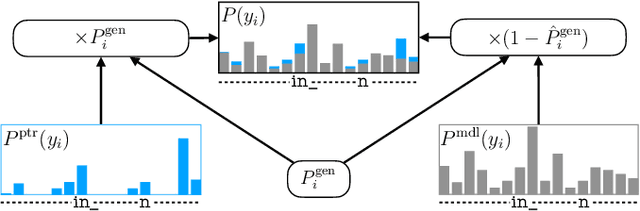

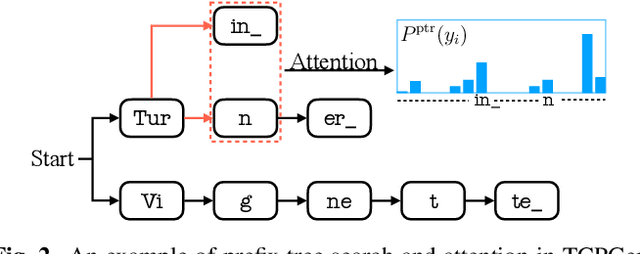
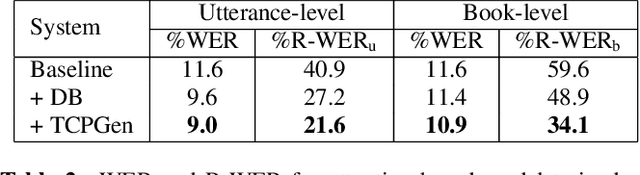
Contextual knowledge is important for real-world automatic speech recognition (ASR) applications. In this paper, a novel tree-constrained pointer generator (TCPGen) component is proposed that incorporates such knowledge as a list of biasing words into both attention-based encoder-decoder and transducer end-to-end ASR models in a neural-symbolic way. TCPGen structures the biasing words into an efficient prefix tree to serve as its symbolic input and creates a neural shortcut between the tree and the final ASR output distribution to facilitate recognising biasing words during decoding. Systems were trained and evaluated on the Librispeech corpus where biasing words were extracted at the scales of an utterance, a chapter, or a book to simulate different application scenarios. Experimental results showed that TCPGen consistently improved word error rates (WERs) compared to the baselines, and in particular, achieved significant WER reductions on the biasing words. TCPGen is highly efficient: it can handle 5,000 biasing words and distractors and only add a small overhead to memory use and computation cost.
Multimodal Crop Type Classification Fusing Multi-Spectral Satellite Time Series with Farmers Crop Rotations and Local Crop Distribution
Aug 23, 2022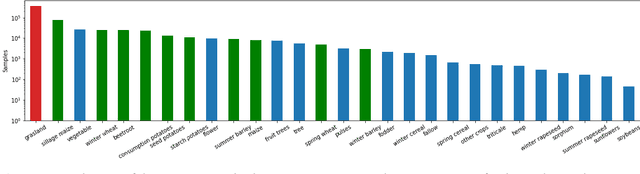
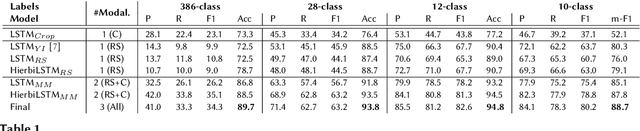
Accurate, detailed, and timely crop type mapping is a very valuable information for the institutions in order to create more accurate policies according to the needs of the citizens. In the last decade, the amount of available data dramatically increased, whether it can come from Remote Sensing (using Copernicus Sentinel-2 data) or directly from the farmers (providing in-situ crop information throughout the years and information on crop rotation). Nevertheless, the majority of the studies are restricted to the use of one modality (Remote Sensing data or crop rotation) and never fuse the Earth Observation data with domain knowledge like crop rotations. Moreover, when they use Earth Observation data they are mainly restrained to one year of data, not taking into account the past years. In this context, we propose to tackle a land use and crop type classification task using three data types, by using a Hierarchical Deep Learning algorithm modeling the crop rotations like a language model, the satellite signals like a speech signal and using the crop distribution as additional context vector. We obtained very promising results compared to classical approaches with significant performances, increasing the Accuracy by 5.1 points in a 28-class setting (.948), and the micro-F1 by 9.6 points in a 10-class setting (.887) using only a set of crop of interests selected by an expert. We finally proposed a data-augmentation technique to allow the model to classify the crop before the end of the season, which works surprisingly well in a multimodal setting.
The VoicePrivacy 2022 Challenge Evaluation Plan
Mar 27, 2022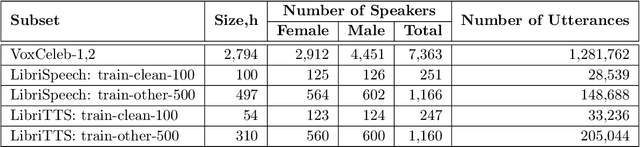
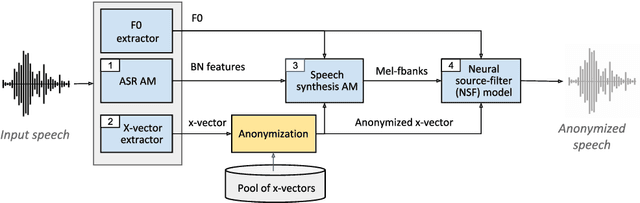
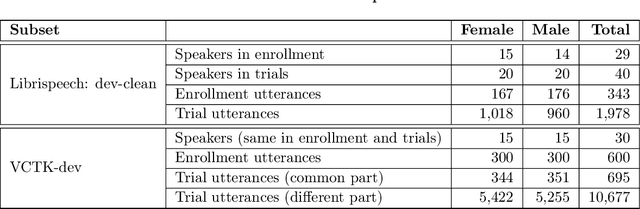
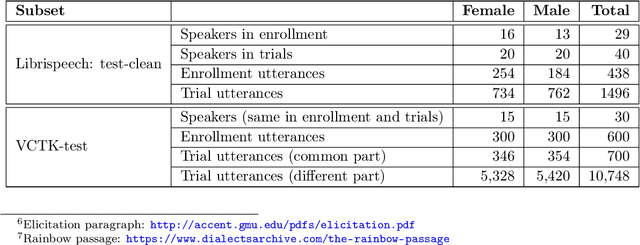
For new participants - Executive summary: (1) The task is to develop a voice anonymization system for speech data which conceals the speaker's voice identity while protecting linguistic content, paralinguistic attributes, intelligibility and naturalness. (2) Training, development and evaluation datasets are provided in addition to 3 different baseline anonymization systems, evaluation scripts, and metrics. Participants apply their developed anonymization systems, run evaluation scripts and submit objective evaluation results and anonymized speech data to the organizers. (3) Results will be presented at a workshop held in conjunction with INTERSPEECH 2022 to which all participants are invited to present their challenge systems and to submit additional workshop papers. For readers familiar with the VoicePrivacy Challenge - Changes w.r.t. 2020: (1) A stronger, semi-informed attack model in the form of an automatic speaker verification (ASV) system trained on anonymized (per-utterance) speech data. (2) Complementary metrics comprising the equal error rate (EER) as a privacy metric, the word error rate (WER) as a primary utility metric, and the pitch correlation and gain of voice distinctiveness as secondary utility metrics. (3) A new ranking policy based upon a set of minimum target privacy requirements.
Residual Excitation Skewness for Automatic Speech Polarity Detection
May 31, 2020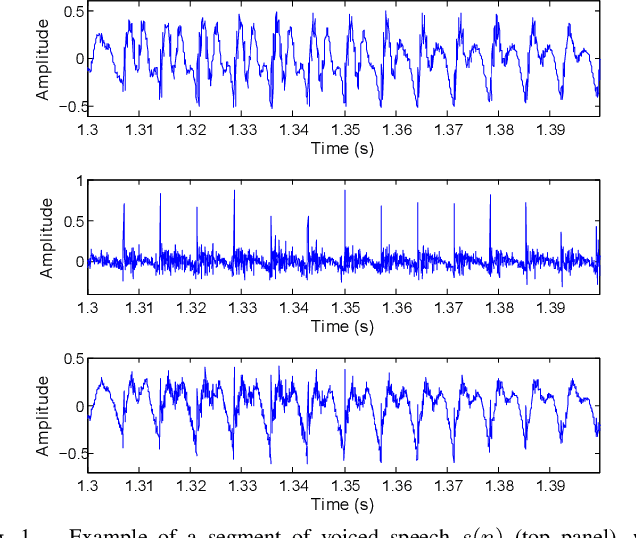
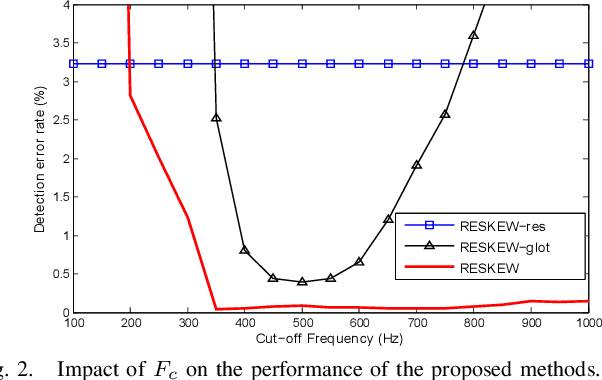

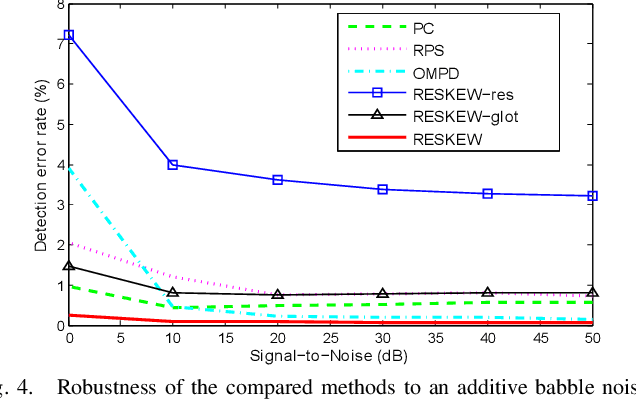
Detecting the correct speech polarity is a necessary step prior to several speech processing techniques. An error on its determination could have a dramatic detrimental impact on their performance. As current systems have to deal with increasing amounts of data stemming from multiple devices, the automatic detection of speech polarity has become a crucial problem. For this purpose, we here propose a very simple algorithm based on the skewness of two excitation signals. The method is shown on 10 speech corpora (8545 files) to lead to an error rate of only 0.06% in clean conditions and to clearly outperform four state-of-the-art methods. Besides it significantly reduces the computational load through its simplicity and is observed to exhibit the strongest robustness in both noisy and reverberant environments.
TinySpeech: Attention Condensers for Deep Speech Recognition Neural Networks on Edge Devices
Aug 11, 2020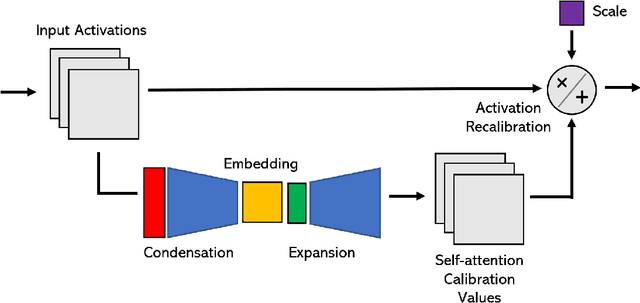

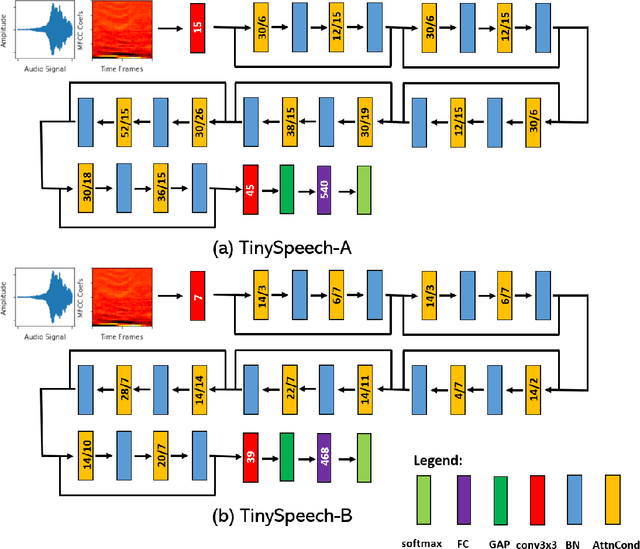
Advances in deep learning have led to state-of-the-art performance across a multitude of speech recognition tasks. Nevertheless, the widespread deployment of deep neural networks for on-device speech recognition remains a challenge, particularly in edge scenarios where the memory and computing resources are highly constrained (e.g., low-power embedded devices) or where the memory and computing budget dedicated to speech recognition is low (e.g., mobile devices performing numerous tasks besides speech recognition). In this study, we introduce the concept of attention condensers for building low-footprint, highly-efficient deep neural networks for on-device speech recognition on the edge. More specifically, an attention condenser is a self-attention mechanism that learns and produces a condensed embedding characterizing joint local and cross-channel activation relationships, and performs adaptive activation recalibration accordingly for selective concentration. To illustrate its efficacy, we introduce TinySpeech, low-precision deep neural networks comprising largely of attention condensers tailored for on-device speech recognition using a machine-driven design exploration strategy. Experimental results on the Google Speech Commands benchmark dataset for limited-vocabulary speech recognition showed that TinySpeech networks achieved significantly lower architectural complexity (as much as $207\times$ fewer parameters) and lower computational complexity (as much as $21\times$ fewer multiply-add operations) when compared to previous deep neural networks in research literature. These results not only demonstrate the efficacy of attention condensers for building highly efficient deep neural networks for on-device speech recognition, but also illuminate its potential for accelerating deep learning on the edge and empowering a wide range of TinyML applications.
Deep Multi-Task Models for Misogyny Identification and Categorization on Arabic Social Media
Jun 16, 2022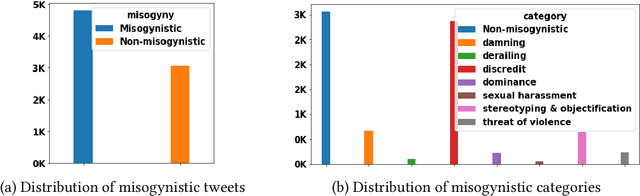
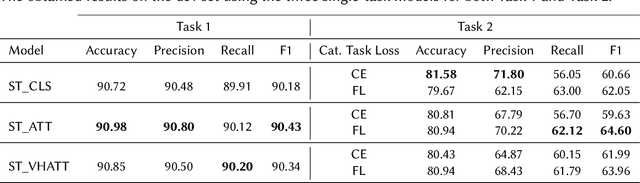
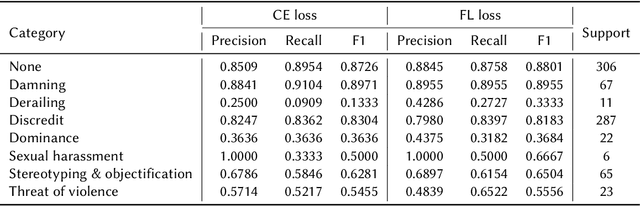
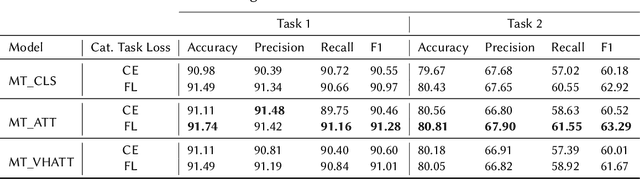
The prevalence of toxic content on social media platforms, such as hate speech, offensive language, and misogyny, presents serious challenges to our interconnected society. These challenging issues have attracted widespread attention in Natural Language Processing (NLP) community. In this paper, we present the submitted systems to the first Arabic Misogyny Identification shared task. We investigate three multi-task learning models as well as their single-task counterparts. In order to encode the input text, our models rely on the pre-trained MARBERT language model. The overall obtained results show that all our submitted models have achieved the best performances (top three ranked submissions) in both misogyny identification and categorization tasks.
textless-lib: a Library for Textless Spoken Language Processing
Feb 15, 2022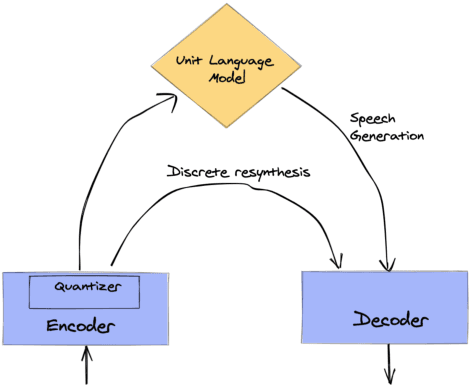
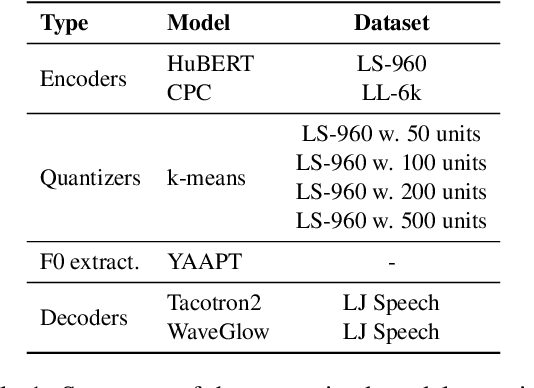
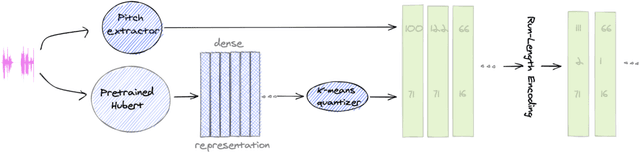
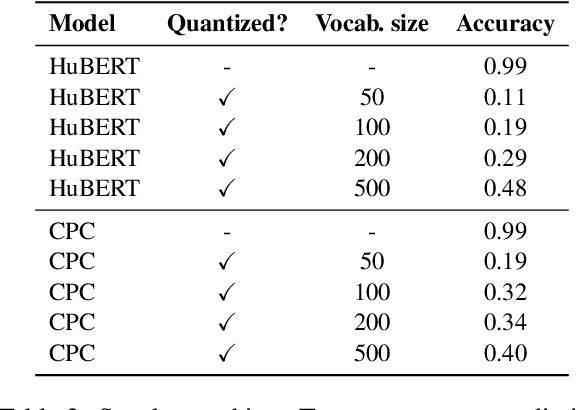
Textless spoken language processing research aims to extend the applicability of standard NLP toolset onto spoken language and languages with few or no textual resources. In this paper, we introduce textless-lib, a PyTorch-based library aimed to facilitate research in this research area. We describe the building blocks that the library provides and demonstrate its usability by discuss three different use-case examples: (i) speaker probing, (ii) speech resynthesis and compression, and (iii) speech continuation. We believe that textless-lib substantially simplifies research the textless setting and will be handful not only for speech researchers but also for the NLP community at large. The code, documentation, and pre-trained models are available at https://github.com/facebookresearch/textlesslib/ .
ASR in German: A Detailed Error Analysis
Apr 12, 2022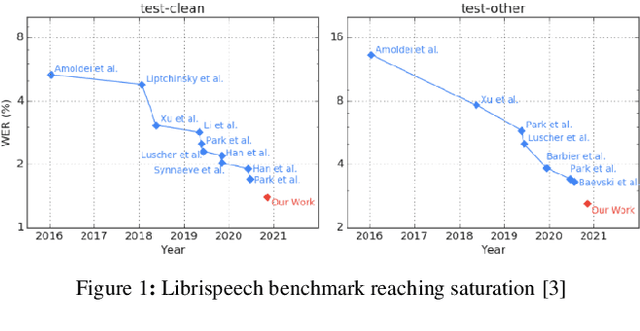
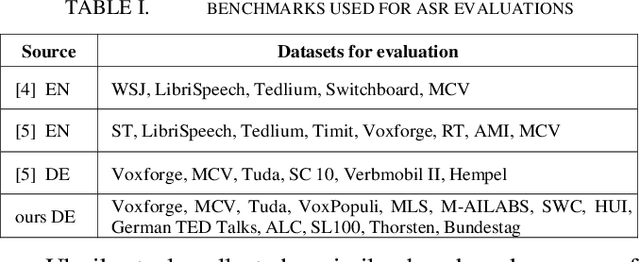
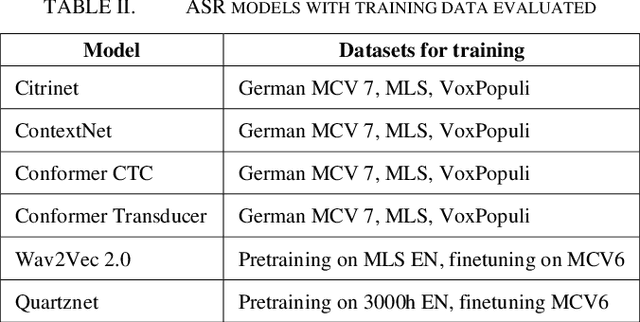
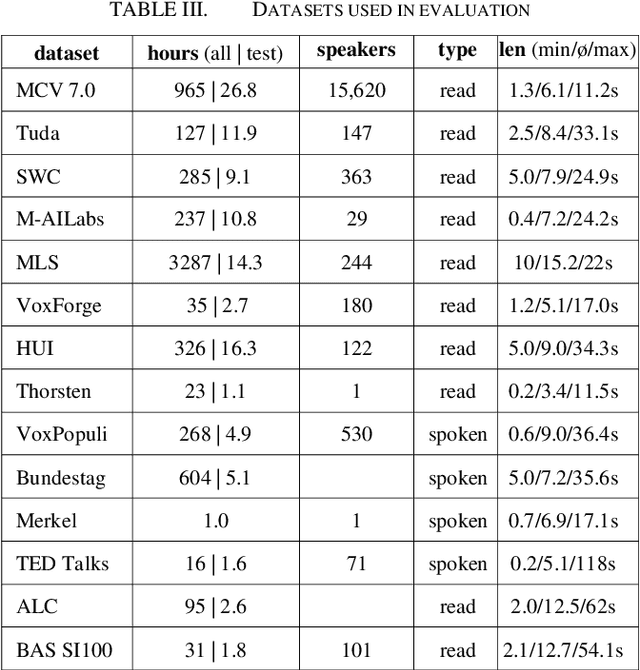
The amount of freely available systems for automatic speech recognition (ASR) based on neural networks is growing steadily, with equally increasingly reliable predictions. However, the evaluation of trained models is typically exclusively based on statistical metrics such as WER or CER, which do not provide any insight into the nature or impact of the errors produced when predicting transcripts from speech input. This work presents a selection of ASR model architectures that are pretrained on the German language and evaluates them on a benchmark of diverse test datasets. It identifies cross-architectural prediction errors, classifies those into categories and traces the sources of errors per category back into training data as well as other sources. Finally, it discusses solutions in order to create qualitatively better training datasets and more robust ASR systems.
Are Chess Discussions Racist? An Adversarial Hate Speech Data Set
Nov 20, 2020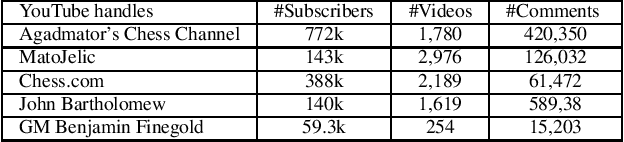


On June 28, 2020, while presenting a chess podcast on Grandmaster Hikaru Nakamura, Antonio Radi\'c's YouTube handle got blocked because it contained "harmful and dangerous" content. YouTube did not give further specific reason, and the channel got reinstated within 24 hours. However, Radi\'c speculated that given the current political situation, a referral to "black against white", albeit in the context of chess, earned him this temporary ban. In this paper, via a substantial corpus of 681,995 comments, on 8,818 YouTube videos hosted by five highly popular chess-focused YouTube channels, we ask the following research question: \emph{how robust are off-the-shelf hate-speech classifiers to out-of-domain adversarial examples?} We release a data set of 1,000 annotated comments where existing hate speech classifiers misclassified benign chess discussions as hate speech. We conclude with an intriguing analogy result on racial bias with our findings pointing out to the broader challenge of color polysemy.
Looking into Your Speech: Learning Cross-modal Affinity for Audio-visual Speech Separation
Mar 25, 2021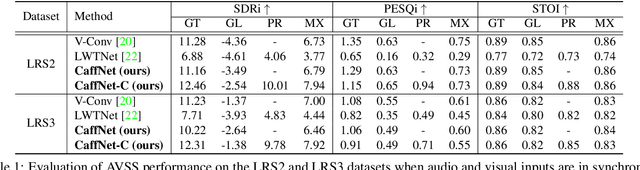
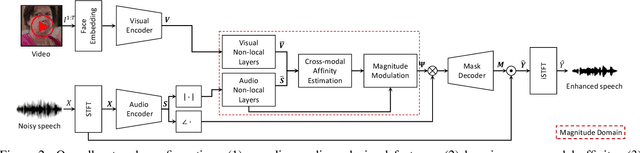
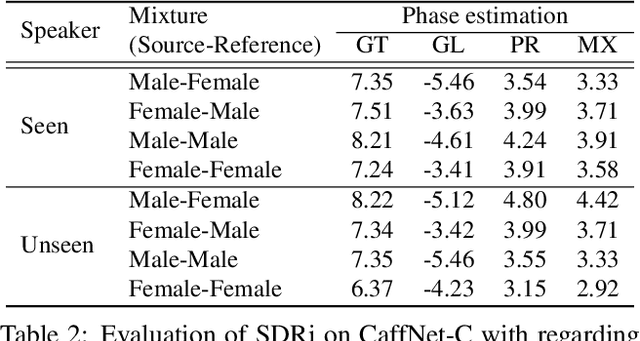
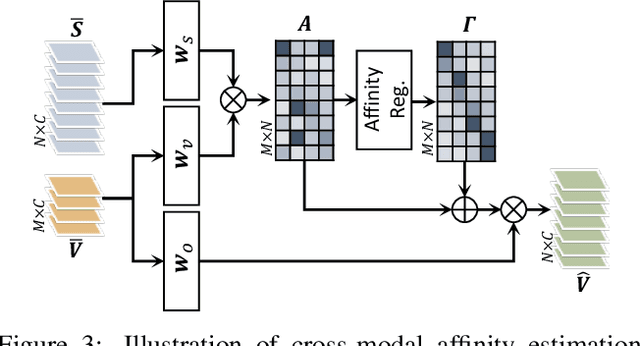
In this paper, we address the problem of separating individual speech signals from videos using audio-visual neural processing. Most conventional approaches utilize frame-wise matching criteria to extract shared information between co-occurring audio and video. Thus, their performance heavily depends on the accuracy of audio-visual synchronization and the effectiveness of their representations. To overcome the frame discontinuity problem between two modalities due to transmission delay mismatch or jitter, we propose a cross-modal affinity network (CaffNet) that learns global correspondence as well as locally-varying affinities between audio and visual streams. Given that the global term provides stability over a temporal sequence at the utterance-level, this resolves the label permutation problem characterized by inconsistent assignments. By extending the proposed cross-modal affinity on the complex network, we further improve the separation performance in the complex spectral domain. Experimental results verify that the proposed methods outperform conventional ones on various datasets, demonstrating their advantages in real-world scenarios.