 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEvaluation of medium-large Language Models at zero-shot closed book generative question answering
May 19, 2023Large language models (LLMs) have garnered significant attention, but the definition of "large" lacks clarity. This paper focuses on medium-sized lan-guage models (MLMs), defined as having at least six billion parameters but less than 100 billion. The study evaluates MLMs regarding zero-shot genera-tive question answering, which requires models to provide elaborate answers without external document retrieval. The paper introduces an own test da-taset and presents results from human evaluation. Results show that combin-ing the best answers from different MLMs yielded an overall correct answer rate of 82.7% which is better than the 60.9% of ChatGPT. The best MLM achieved 46.4% and has 7B parameters, which highlights the importance of using appropriate training data for fine-tuning rather than solely relying on the number of parameters. More fine-grained feedback should be used to further improve the quality of answers.
ASR Bundestag: A Large-Scale political debate dataset in German
Feb 12, 2023We present ASR Bundestag, a dataset for automatic speech recognition in German, consisting of 610 hours of aligned audio-transcript pairs for supervised training as well as 1,038 hours of unlabeled audio snippets for self-supervised learning, based on raw audio data and transcriptions from plenary sessions and committee meetings of the German parliament. In addition, we discuss utilized approaches for the automated creation of speech datasets and assess the quality of the resulting dataset based on evaluations and finetuning of a pre-trained state of the art model. We make the dataset publicly available, including all subsets.
ASR in German: A Detailed Error Analysis
Apr 12, 2022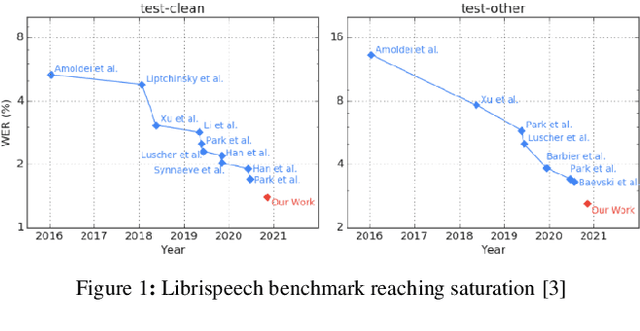
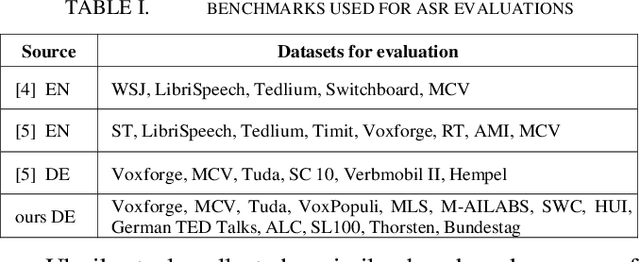
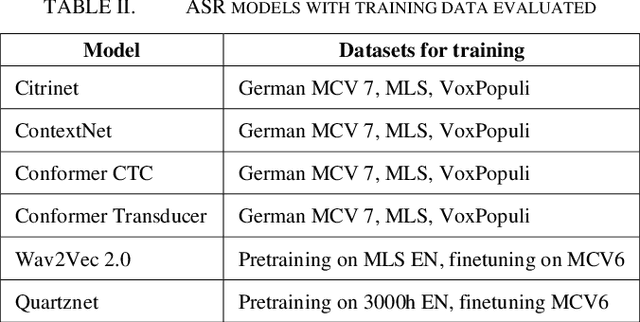
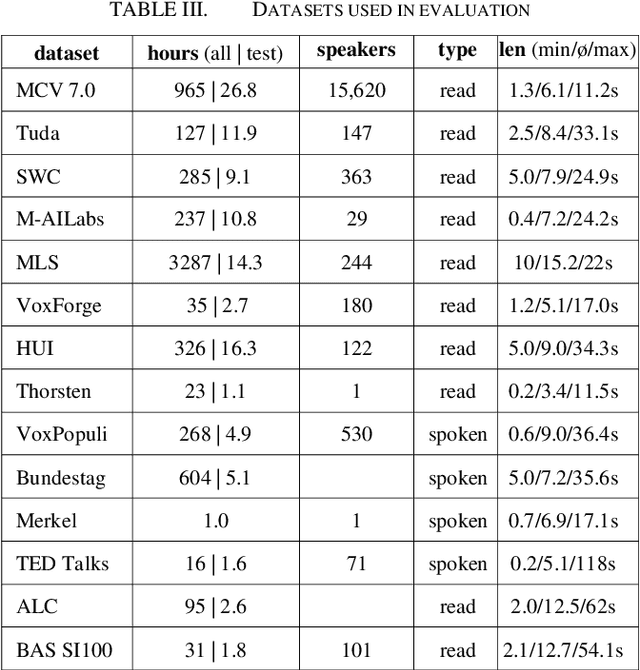
The amount of freely available systems for automatic speech recognition (ASR) based on neural networks is growing steadily, with equally increasingly reliable predictions. However, the evaluation of trained models is typically exclusively based on statistical metrics such as WER or CER, which do not provide any insight into the nature or impact of the errors produced when predicting transcripts from speech input. This work presents a selection of ASR model architectures that are pretrained on the German language and evaluates them on a benchmark of diverse test datasets. It identifies cross-architectural prediction errors, classifies those into categories and traces the sources of errors per category back into training data as well as other sources. Finally, it discusses solutions in order to create qualitatively better training datasets and more robust ASR systems.
HUI-Audio-Corpus-German: A high quality TTS dataset
Jun 11, 2021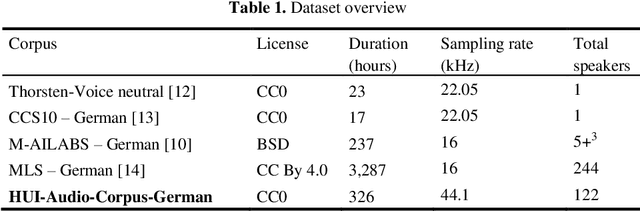
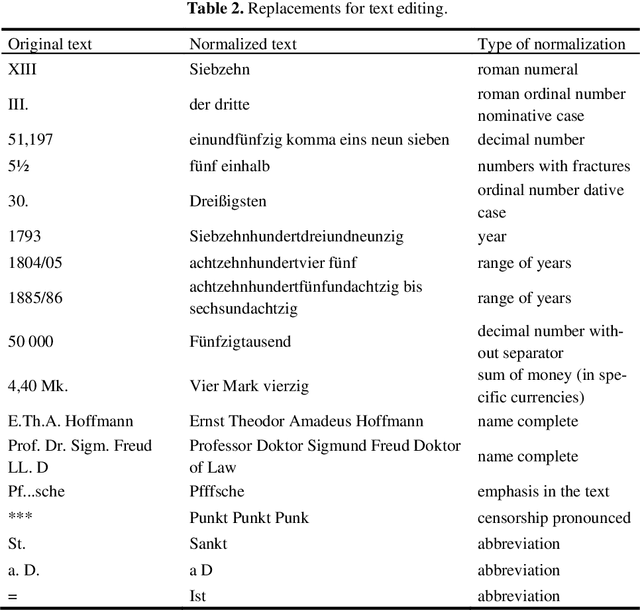
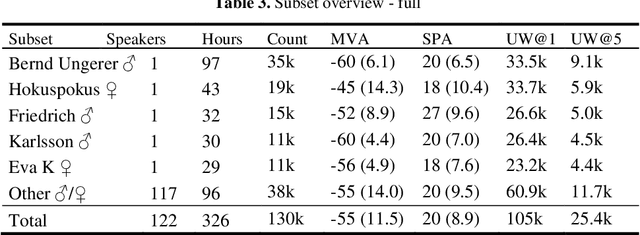
The increasing availability of audio data on the internet lead to a multitude of datasets for development and training of text to speech applications, based on neural networks. Highly differing quality of voice, low sampling rates, lack of text normalization and disadvantageous alignment of audio samples to corresponding transcript sentences still limit the performance of deep neural networks trained on this task. Additionally, data resources in languages like German are still very limited. We introduce the "HUI-Audio-Corpus-German", a large, open-source dataset for TTS engines, created with a processing pipeline, which produces high quality audio to transcription alignments and decreases manual effort needed for creation.