 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTinySpeech: Attention Condensers for Deep Speech Recognition Neural Networks on Edge Devices
Paper and Code
Aug 23, 2020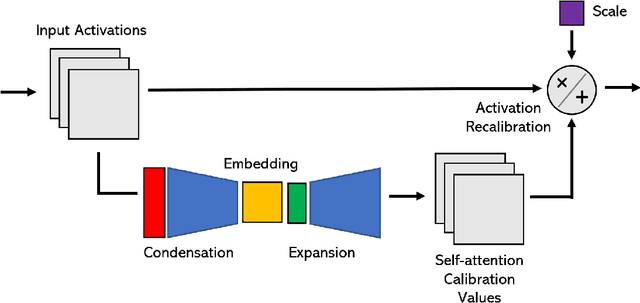

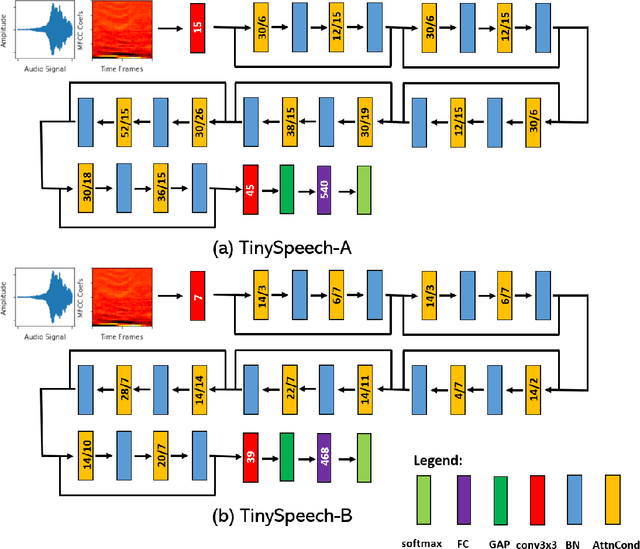
Advances in deep learning have led to state-of-the-art performance across a multitude of speech recognition tasks. Nevertheless, the widespread deployment of deep neural networks for on-device speech recognition remains a challenge, particularly in edge scenarios where the memory and computing resources are highly constrained (e.g., low-power embedded devices) or where the memory and computing budget dedicated to speech recognition is low (e.g., mobile devices performing numerous tasks besides speech recognition). In this study, we introduce the concept of attention condensers for building low-footprint, highly-efficient deep neural networks for on-device speech recognition on the edge. More specifically, an attention condenser is a self-attention mechanism that learns and produces a condensed embedding characterizing joint local and cross-channel activation relationships, and performs selective attention accordingly. To illustrate its efficacy, we introduce TinySpeech, low-precision deep neural networks comprising largely of attention condensers tailored for on-device speech recognition using a machine-driven design exploration strategy. Experimental results on the Google Speech Commands benchmark dataset for limited-vocabulary speech recognition showed that TinySpeech networks achieved significantly lower architectural complexity (as much as $207\times$ fewer parameters) and lower computational complexity (as much as $21\times$ fewer multiply-add operations) when compared to previous deep neural networks in research literature. These results not only demonstrate the efficacy of attention condensers for building highly efficient deep neural networks for on-device speech recognition, but also illuminate its potential for accelerating deep learning on the edge and empowering a wide range of TinyML applications.