 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"speech": models, code, and papers
Leveraging cross-platform data to improve automated hate speech detection
Feb 09, 2021
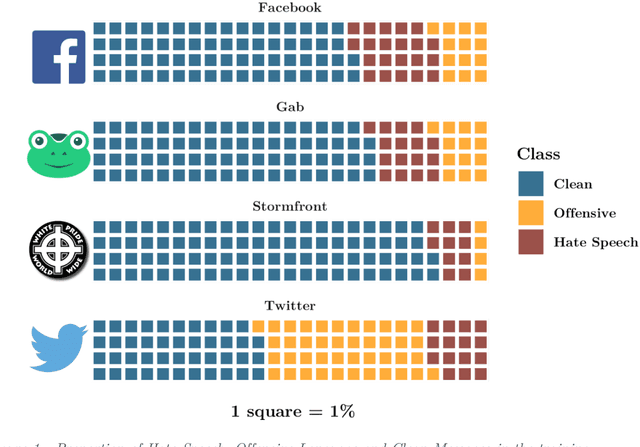

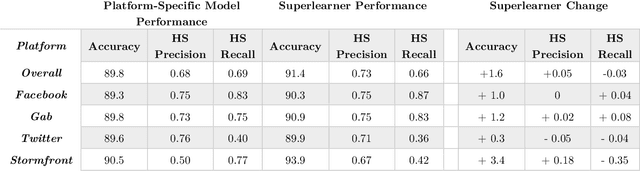
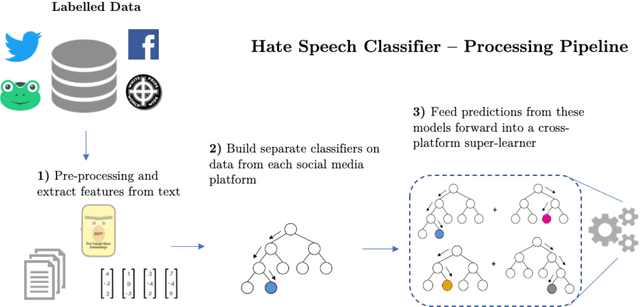
Hate speech is increasingly prevalent online, and its negative outcomes include increased prejudice, extremism, and even offline hate crime. Automatic detection of online hate speech can help us to better understand these impacts. However, while the field has recently progressed through advances in natural language processing, challenges still remain. In particular, most existing approaches for hate speech detection focus on a single social media platform in isolation. This limits both the use of these models and their validity, as the nature of language varies from platform to platform. Here we propose a new cross-platform approach to detect hate speech which leverages multiple datasets and classification models from different platforms and trains a superlearner that can combine existing and novel training data to improve detection and increase model applicability. We demonstrate how this approach outperforms existing models, and achieves good performance when tested on messages from novel social media platforms not included in the original training data.
A Syntax Aware BERT for Identifying Well-Formed Queries in a Curriculum Framework
Aug 21, 2022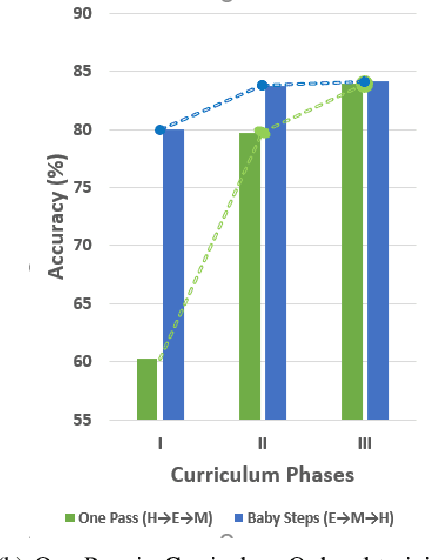
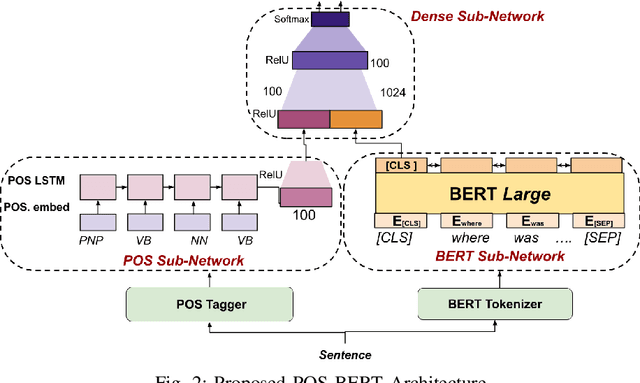
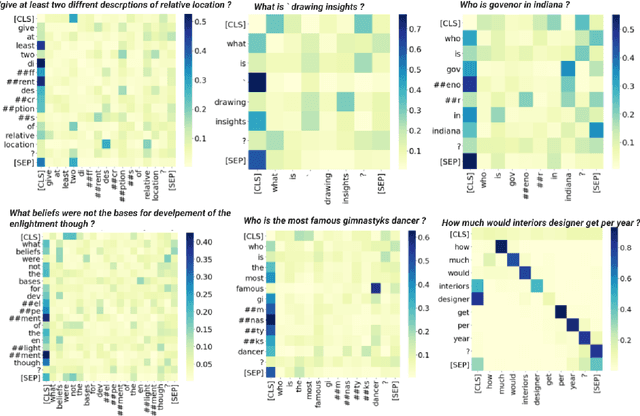

A well formed query is defined as a query which is formulated in the manner of an inquiry, and with correct interrogatives, spelling and grammar. While identifying well formed queries is an important task, few works have attempted to address it. In this paper we propose transformer based language model - Bidirectional Encoder Representations from Transformers (BERT) to this task. We further imbibe BERT with parts-of-speech information inspired from earlier works. Furthermore, we also train the model in multiple curriculum settings for improvement in performance. Curriculum Learning over the task is experimented with Baby Steps and One Pass techniques. Proposed architecture performs exceedingly well on the task. The best approach achieves accuracy of 83.93%, outperforming previous state-of-the-art at 75.0% and reaching close to the approximate human upper bound of 88.4%.
Scaling sparsemax based channel selection for speech recognition with ad-hoc microphone arrays
Apr 01, 2021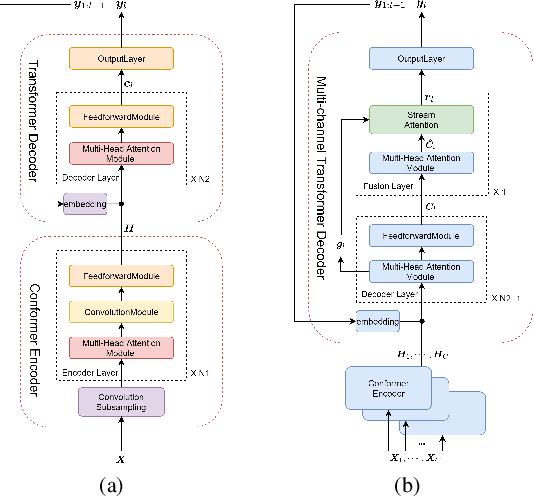
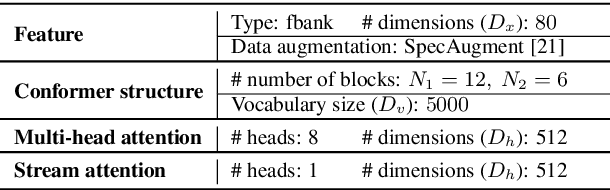
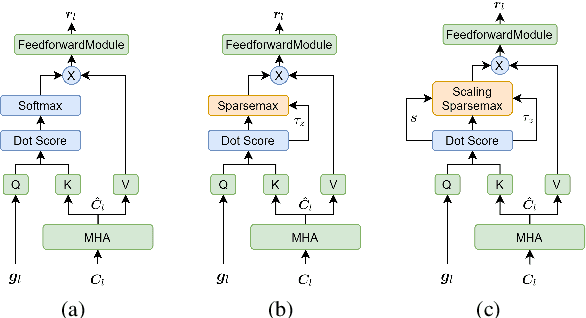
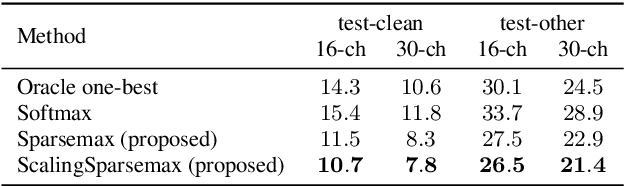
Recently, speech recognition with ad-hoc microphone arrays has received much attention. It is known that channel selection is an important problem of ad-hoc microphone arrays, however, this topic seems far from explored in speech recognition yet, particularly with a large-scale ad-hoc microphone array. To address this problem, we propose a Scaling Sparsemax algorithm for the channel selection problem of the speech recognition with large-scale ad-hoc microphone arrays. Specifically, we first replace the conventional Softmax operator in the stream attention mechanism of a multichannel end-to-end speech recognition system with Sparsemax, which conducts channel selection by forcing the channel weights of noisy channels to zero. Because Sparsemax punishes the weights of many channels to zero harshly, we propose Scaling Sparsemax which punishes the channels mildly by setting the weights of very noisy channels to zero only. Experimental results with ad-hoc microphone arrays of over 30 channels under the conformer speech recognition architecture show that the proposed Scaling Sparsemax yields a word error rate of over 30% lower than Softmax on simulation data sets, and over 20% lower on semi-real data sets, in test scenarios with both matched and mismatched channel numbers.
Cascaded Models With Cyclic Feedback For Direct Speech Translation
Oct 21, 2020
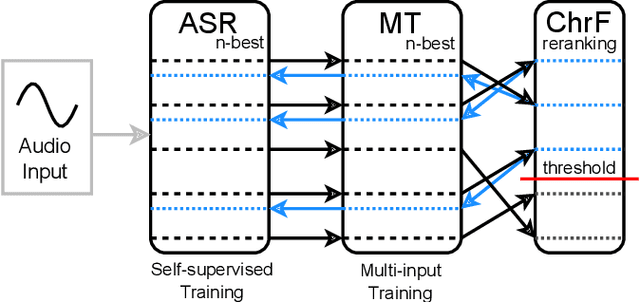

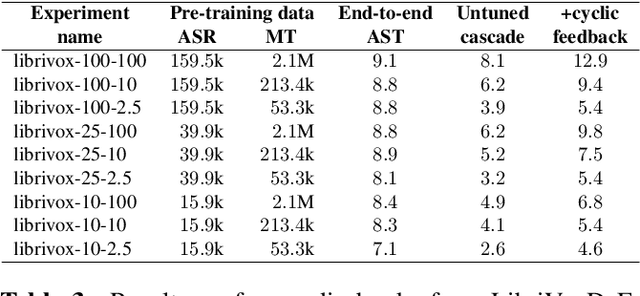
Direct speech translation describes a scenario where only speech inputs and corresponding translations are available. Such data are notoriously limited. We present a technique that allows cascades of automatic speech recognition (ASR) and machine translation (MT) to exploit in-domain direct speech translation data in addition to out-of-domain MT and ASR data. After pre-training MT and ASR, we use a feedback cycle where the downstream performance of the MT system is used as a signal to improve the ASR system by self-training, and the MT component is fine-tuned on multiple ASR outputs, making it more tolerant towards spelling variations. A comparison to end-to-end speech translation using components of identical architecture and the same data shows gains of up to 3.8 BLEU points on LibriVoxDeEn and up to 5.1 BLEU points on CoVoST for German-to-English speech translation.
Liquid Structural State-Space Models
Sep 26, 2022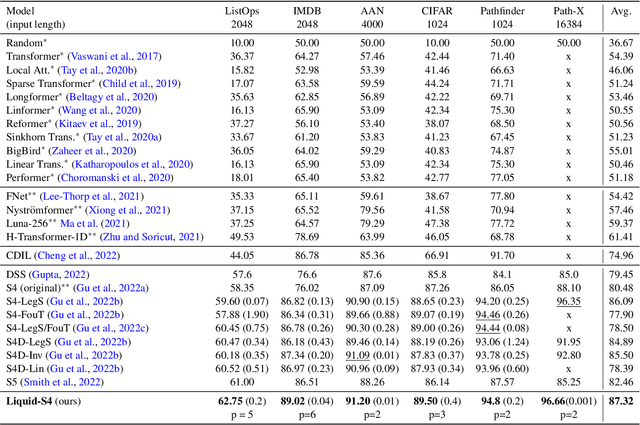
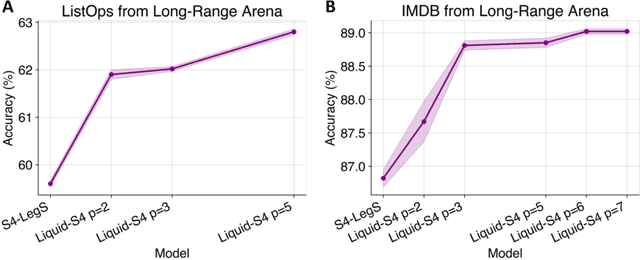
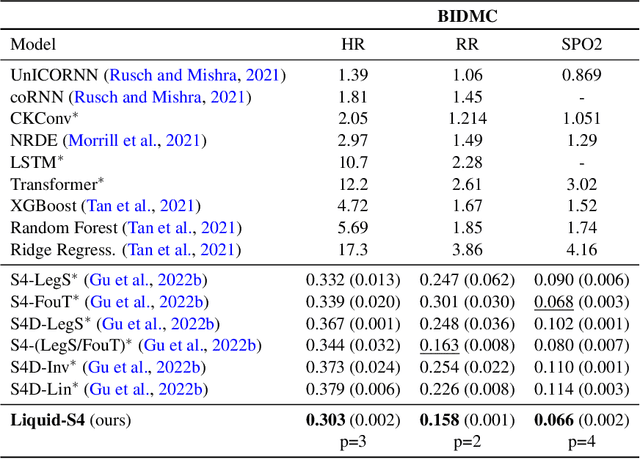
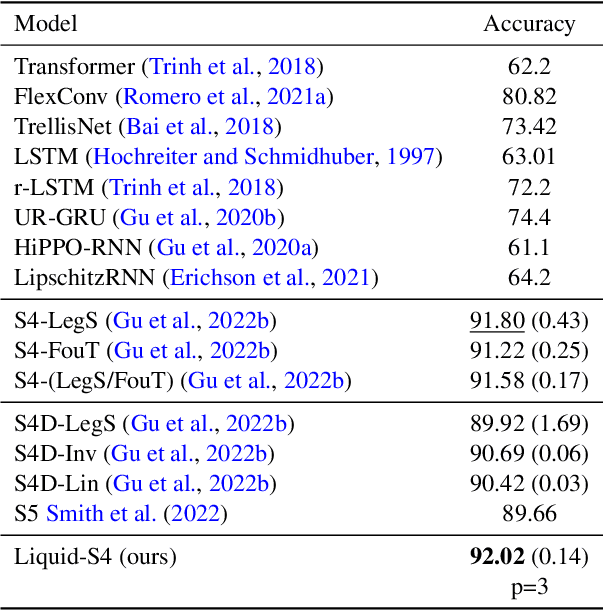
A proper parametrization of state transition matrices of linear state-space models (SSMs) followed by standard nonlinearities enables them to efficiently learn representations from sequential data, establishing the state-of-the-art on a large series of long-range sequence modeling benchmarks. In this paper, we show that we can improve further when the structural SSM such as S4 is given by a linear liquid time-constant (LTC) state-space model. LTC neural networks are causal continuous-time neural networks with an input-dependent state transition module, which makes them learn to adapt to incoming inputs at inference. We show that by using a diagonal plus low-rank decomposition of the state transition matrix introduced in S4, and a few simplifications, the LTC-based structural state-space model, dubbed Liquid-S4, achieves the new state-of-the-art generalization across sequence modeling tasks with long-term dependencies such as image, text, audio, and medical time-series, with an average performance of 87.32% on the Long-Range Arena benchmark. On the full raw Speech Command recognition, dataset Liquid-S4 achieves 96.78% accuracy with a 30% reduction in parameter counts compared to S4. The additional gain in performance is the direct result of the Liquid-S4's kernel structure that takes into account the similarities of the input sequence samples during training and inference.
Non-autoregressive Error Correction for CTC-based ASR with Phone-conditioned Masked LM
Sep 08, 2022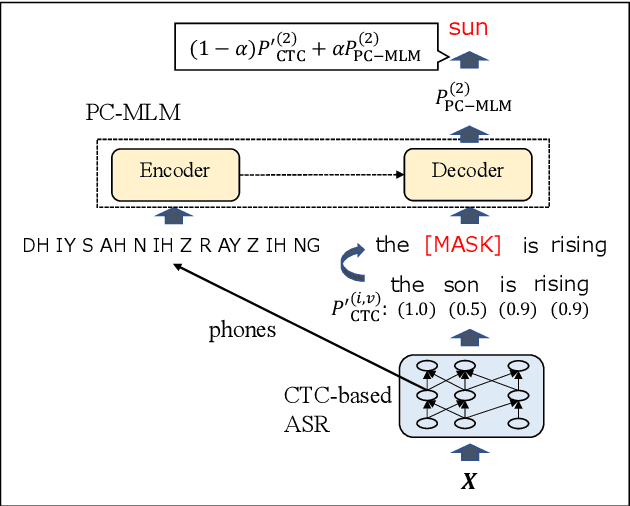
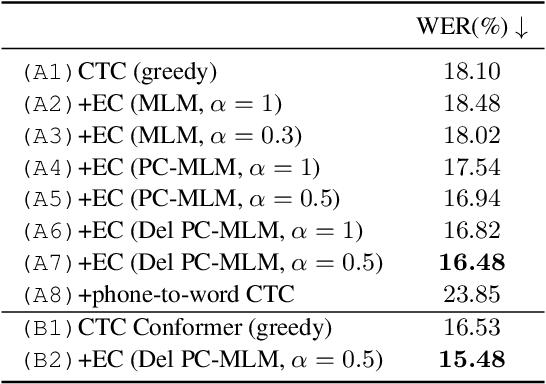
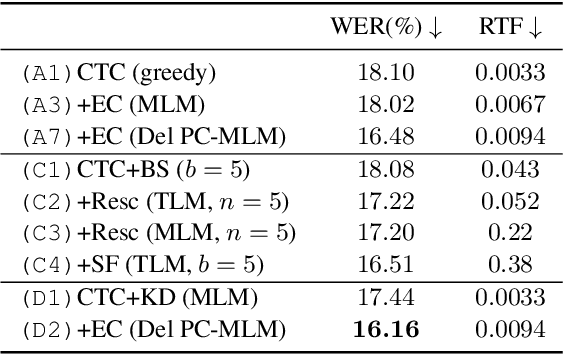
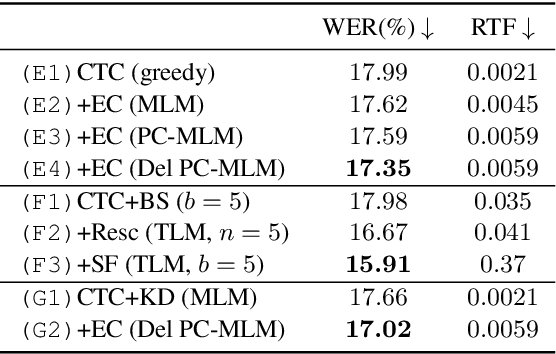
Connectionist temporal classification (CTC) -based models are attractive in automatic speech recognition (ASR) because of their non-autoregressive nature. To take advantage of text-only data, language model (LM) integration approaches such as rescoring and shallow fusion have been widely used for CTC. However, they lose CTC's non-autoregressive nature because of the need for beam search, which slows down the inference speed. In this study, we propose an error correction method with phone-conditioned masked LM (PC-MLM). In the proposed method, less confident word tokens in a greedy decoded output from CTC are masked. PC-MLM then predicts these masked word tokens given unmasked words and phones supplementally predicted from CTC. We further extend it to Deletable PC-MLM in order to address insertion errors. Since both CTC and PC-MLM are non-autoregressive models, the method enables fast LM integration. Experimental evaluations on the Corpus of Spontaneous Japanese (CSJ) and TED-LIUM2 in domain adaptation setting shows that our proposed method outperformed rescoring and shallow fusion in terms of inference speed, and also in terms of recognition accuracy on CSJ.
Universal Fourier Attack for Time Series
Sep 02, 2022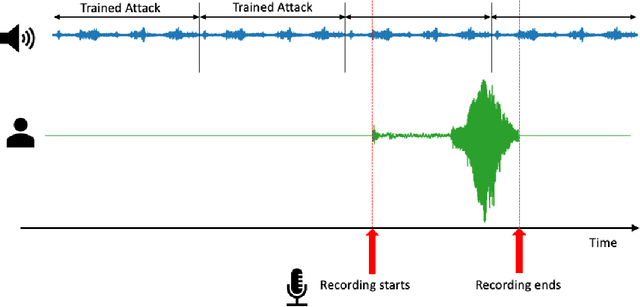
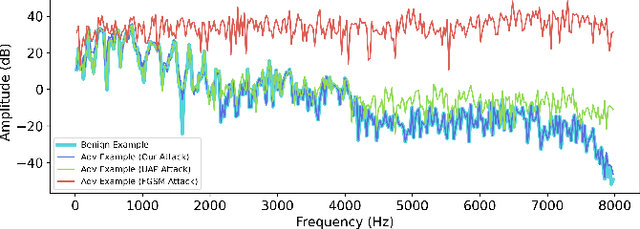
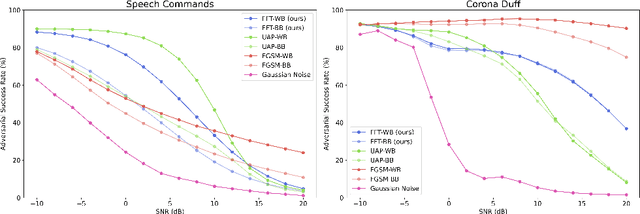
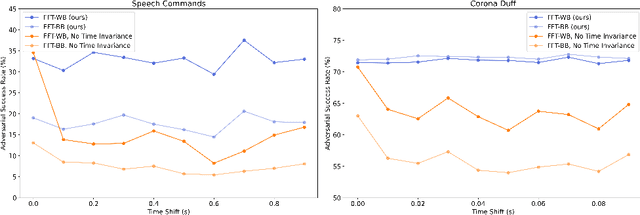
A wide variety of adversarial attacks have been proposed and explored using image and audio data. These attacks are notoriously easy to generate digitally when the attacker can directly manipulate the input to a model, but are much more difficult to implement in the real-world. In this paper we present a universal, time invariant attack for general time series data such that the attack has a frequency spectrum primarily composed of the frequencies present in the original data. The universality of the attack makes it fast and easy to implement as no computation is required to add it to an input, while time invariance is useful for real-world deployment. Additionally, the frequency constraint ensures the attack can withstand filtering. We demonstrate the effectiveness of the attack in two different domains, speech recognition and unintended radiated emission, and show that the attack is robust against common transform-and-compare defense pipelines.
Building a great multi-lingual teacher with sparsely-gated mixture of experts for speech recognition
Jan 04, 2022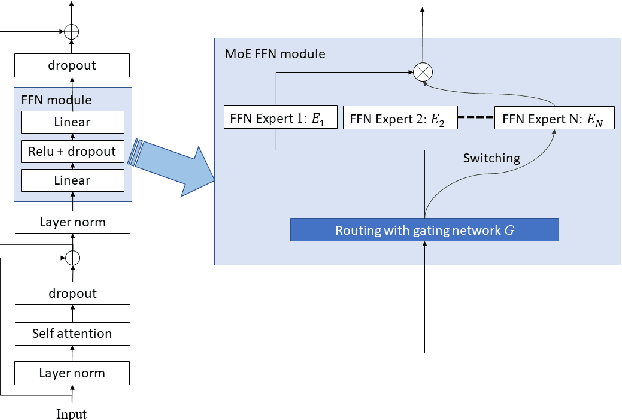
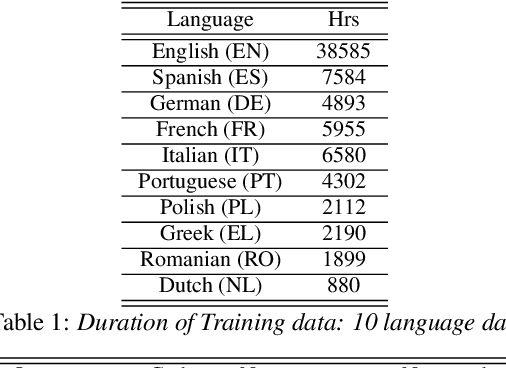
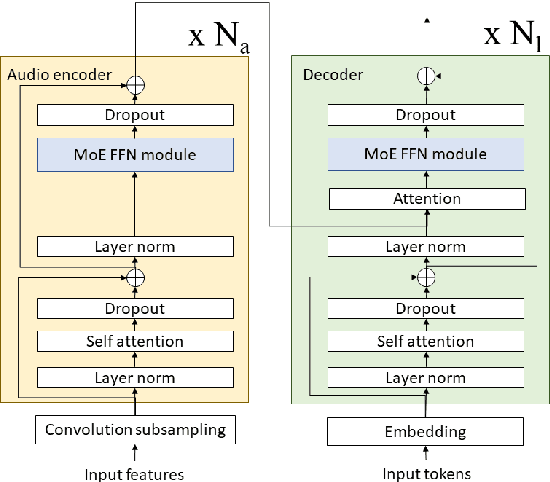
The sparsely-gated Mixture of Experts (MoE) can magnify a network capacity with a little computational complexity. In this work, we investigate how multi-lingual Automatic Speech Recognition (ASR) networks can be scaled up with a simple routing algorithm in order to achieve better accuracy. More specifically, we apply the sparsely-gated MoE technique to two types of networks: Sequence-to-Sequence Transformer (S2S-T) and Transformer Transducer (T-T). We demonstrate through a set of ASR experiments on multiple language data that the MoE networks can reduce the relative word error rates by 16.3% and 4.6% with the S2S-T and T-T, respectively. Moreover, we thoroughly investigate the effect of the MoE on the T-T architecture in various conditions: streaming mode, non-streaming mode, the use of language ID and the label decoder with the MoE.
Self-move and Other-move: Quantum Categorical Foundations of Japanese
Oct 10, 2022

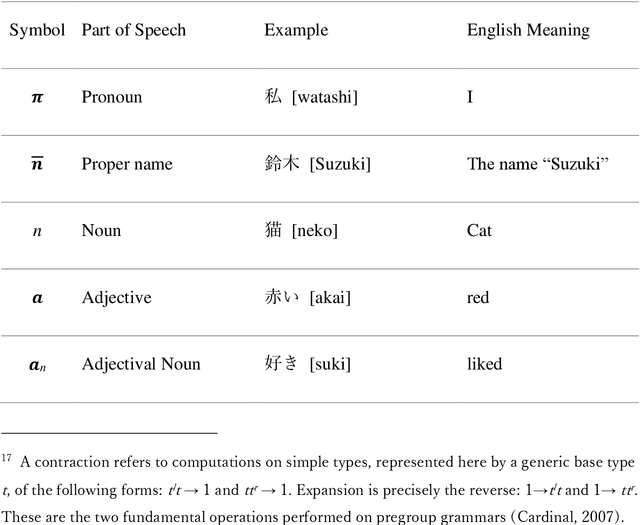

The purpose of this work is to contribute toward the larger goal of creating a Quantum Natural Language Processing (QNLP) translator program. This work contributes original diagrammatic representations of the Japanese language based on prior work that accomplished on the English language based on category theory. The germane differences between the English and Japanese languages are emphasized to help address English language bias in the current body of research. Additionally, topological principles of these diagrams and many potential avenues for further research are proposed. Why is this endeavor important? Hundreds of languages have developed over the course of millennia coinciding with the evolution of human interaction across time and geographic location. These languages are foundational to human survival, experience, flourishing, and living the good life. They are also, however, the strongest barrier between people groups. Over the last several decades, advancements in Natural Language Processing (NLP) have made it easier to bridge the gap between individuals who do not share a common language or culture. Tools like Google Translate and DeepL make it easier than ever before to share our experiences with people globally. Nevertheless, these tools are still inadequate as they fail to convey our ideas across the language barrier fluently, leaving people feeling anxious and embarrassed. This is particularly true of languages born out of substantially different cultures, such as English and Japanese. Quantum computers offer the best chance to achieve translation fluency in that they are better suited to simulating the natural world and natural phenomenon such as natural speech. Keywords: category theory, DisCoCat, DisCoCirc, Japanese grammar, English grammar, translation, topology, Quantum Natural Language Processing, Natural Language Processing
Training Strategies for Own Voice Reconstruction in Hearing Protection Devices using an In-ear Microphone
May 12, 2022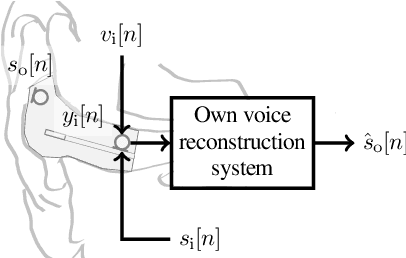
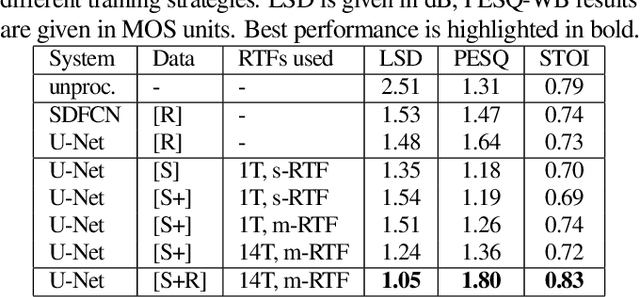
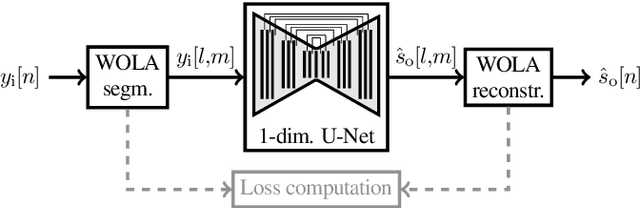
In-ear microphones in hearing protection devices can be utilized to capture the own voice speech of the person wearing the devices in noisy environments. Since in-ear recordings of the own voice are typically band-limited, an own voice reconstruction system is required to recover clean broadband speech from the in-ear signals. However, the availability of speech data for this scenario is typically limited due to device-specific transfer characteristics and the need to collect data from in-situ measurements. In this paper, we apply a deep learning-based bandwidth-extension system to the own voice reconstruction task and investigate different training strategies in order to overcome the limited availability of training data. Experimental results indicate that the use of simulated training data based on recordings of several talkers in combination with a fine-tuning approach using real data is advantageous compared to directly training on a small real dataset.