 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"speech": models, code, and papers
Spell my name: keyword boosted speech recognition
Oct 06, 2021
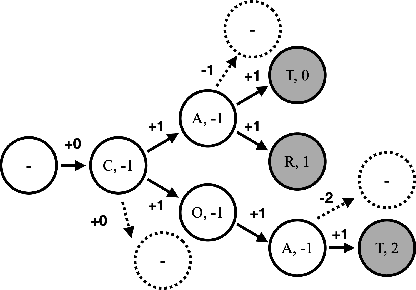

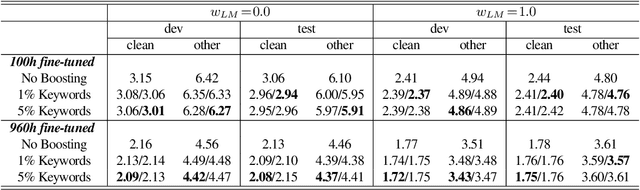
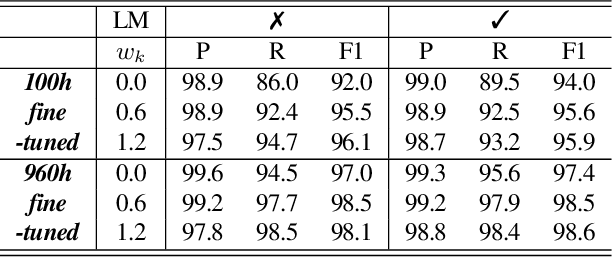
Recognition of uncommon words such as names and technical terminology is important to understanding conversations in context. However, the ability to recognise such words remains a challenge in modern automatic speech recognition (ASR) systems. In this paper, we propose a simple but powerful ASR decoding method that can better recognise these uncommon keywords, which in turn enables better readability of the results. The method boosts the probabilities of given keywords in a beam search based on acoustic model predictions. The method does not require any training in advance. We demonstrate the effectiveness of our method on the LibriSpeeech test sets and also internal data of real-world conversations. Our method significantly boosts keyword accuracy on the test sets, while maintaining the accuracy of the other words, and as well as providing significant qualitative improvements. This method is applicable to other tasks such as machine translation, or wherever unseen and difficult keywords need to be recognised in beam search.
Multilingual Speech Recognition for Low-Resource Indian Languages using Multi-Task conformer
Sep 10, 2021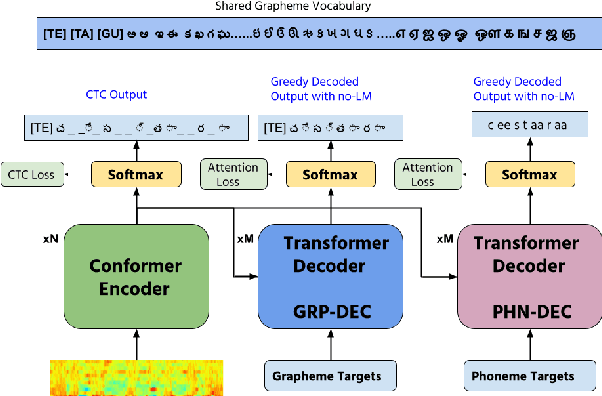

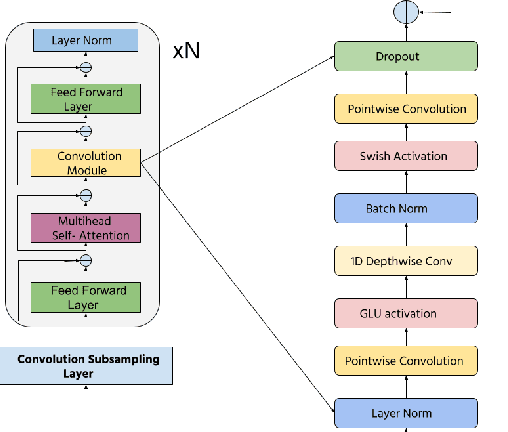
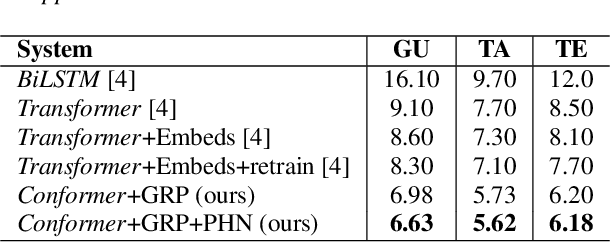
Transformers have recently become very popular for sequence-to-sequence applications such as machine translation and speech recognition. In this work, we propose a multi-task learning-based transformer model for low-resource multilingual speech recognition for Indian languages. Our proposed model consists of a conformer [1] encoder and two parallel transformer decoders. We use a phoneme decoder (PHN-DEC) for the phoneme recognition task and a grapheme decoder (GRP-DEC) to predict grapheme sequence. We consider the phoneme recognition task as an auxiliary task for our multi-task learning framework. We jointly optimize the network for both phoneme and grapheme recognition tasks using Joint CTC-Attention [2] training. We use a conditional decoding scheme to inject the language information into the model before predicting the grapheme sequence. Our experiments show that our proposed approach can obtain significant improvement over previous approaches [4]. We also show that our conformer-based dual-decoder approach outperforms both the transformer-based dual-decoder approach and single decoder approach. Finally, We compare monolingual ASR models with our proposed multilingual ASR approach.
Impact and dynamics of hate and counter speech online
Sep 18, 2020
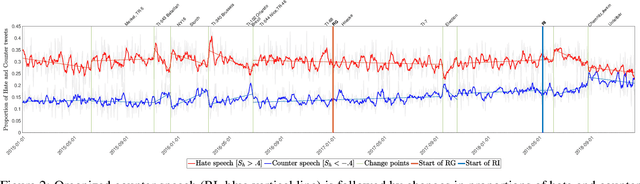
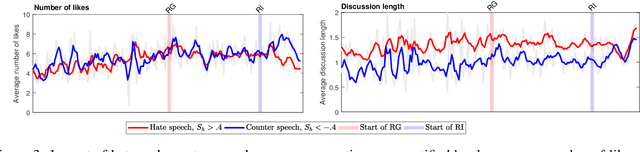
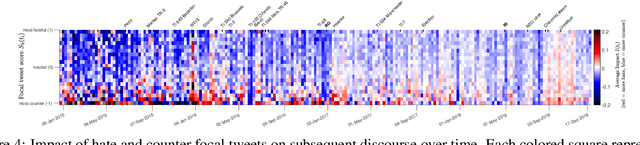
Citizen-generated counter speech is a promising way to fight hate speech and promote peaceful, non-polarized discourse. However, there is a lack of large-scale longitudinal studies of its effectiveness for reducing hate speech. We investigate the effectiveness of counter speech using several different macro- and micro-level measures of over 180,000 political conversations that took place on German Twitter over four years. We report on the dynamic interactions of hate and counter speech over time and provide insights into whether, as in `classic' bullying situations, organized efforts are more effective than independent individuals in steering online discourse. Taken together, our results build a multifaceted picture of the dynamics of hate and counter speech online. They suggest that organized hate speech produced changes in the public discourse. Counter speech, especially when organized, could help in curbing hate speech in online discussions.
The Use of Voice Source Features for Sung Speech Recognition
Feb 20, 2021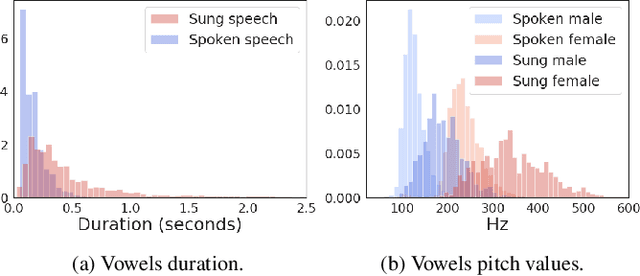
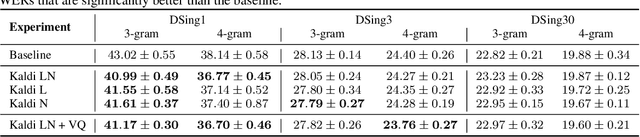
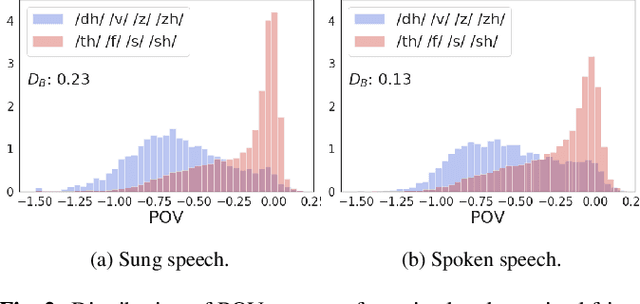
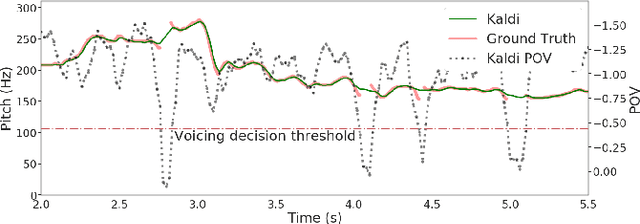
In this paper, we ask whether vocal source features (pitch, shimmer, jitter, etc) can improve the performance of automatic sung speech recognition, arguing that conclusions previously drawn from spoken speech studies may not be valid in the sung speech domain. We first use a parallel singing/speaking corpus (NUS-48E) to illustrate differences in sung vs spoken voicing characteristics including pitch range, syllables duration, vibrato, jitter and shimmer. We then use this analysis to inform speech recognition experiments on the sung speech DSing corpus, using a state of the art acoustic model and augmenting conventional features with various voice source parameters. Experiments are run with three standard (increasingly large) training sets, DSing1 (15.1 hours), DSing3 (44.7 hours) and DSing30 (149.1 hours). Pitch combined with degree of voicing produces a significant decrease in WER from 38.1% to 36.7% when training with DSing1 however smaller decreases in WER observed when training with the larger more varied DSing3 and DSing30 sets were not seen to be statistically significant. Voicing quality characteristics did not improve recognition performance although analysis suggests that they do contribute to an improved discrimination between voiced/unvoiced phoneme pairs.
Multi-modal fusion with gating using audio, lexical and disfluency features for Alzheimer's Dementia recognition from spontaneous speech
Jun 17, 2021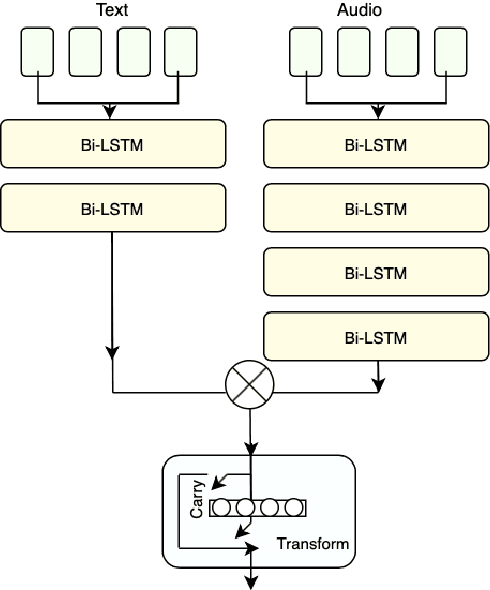

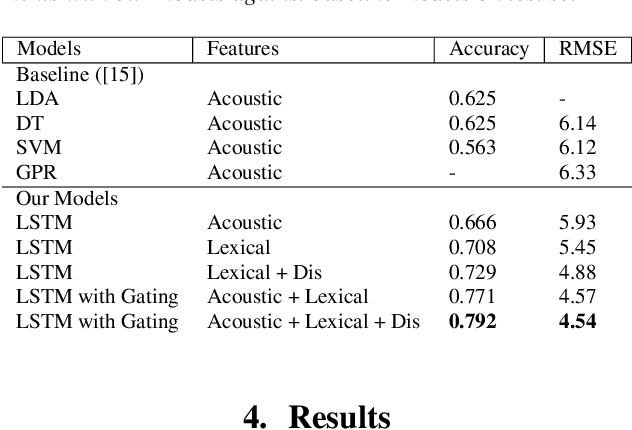
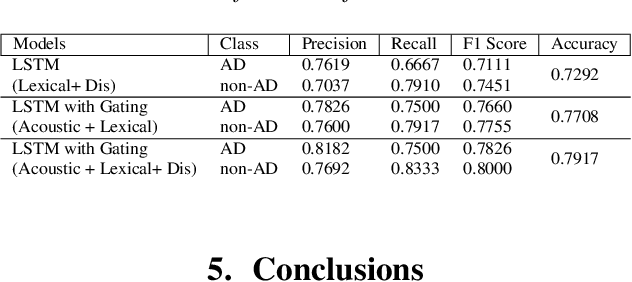
This paper is a submission to the Alzheimer's Dementia Recognition through Spontaneous Speech (ADReSS) challenge, which aims to develop methods that can assist in the automated prediction of severity of Alzheimer's Disease from speech data. We focus on acoustic and natural language features for cognitive impairment detection in spontaneous speech in the context of Alzheimer's Disease Diagnosis and the mini-mental state examination (MMSE) score prediction. We proposed a model that obtains unimodal decisions from different LSTMs, one for each modality of text and audio, and then combines them using a gating mechanism for the final prediction. We focused on sequential modelling of text and audio and investigated whether the disfluencies present in individuals' speech relate to the extent of their cognitive impairment. Our results show that the proposed classification and regression schemes obtain very promising results on both development and test sets. This suggests Alzheimer's Disease can be detected successfully with sequence modeling of the speech data of medical sessions.
Learning robust speech representation with an articulatory-regularized variational autoencoder
Apr 07, 2021
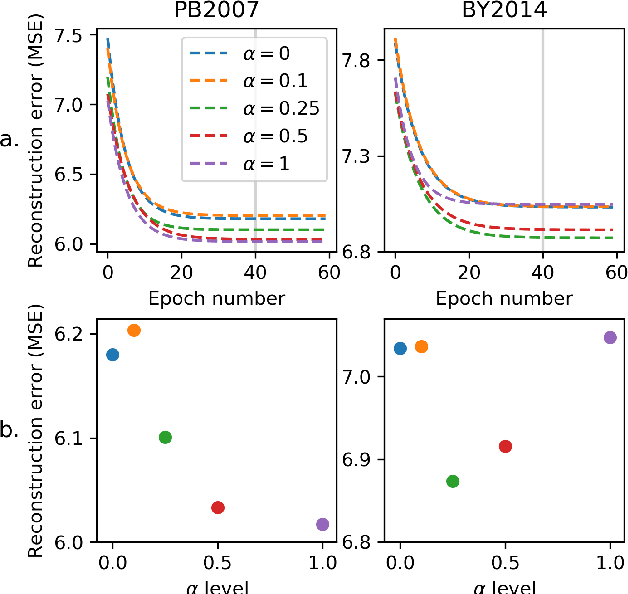
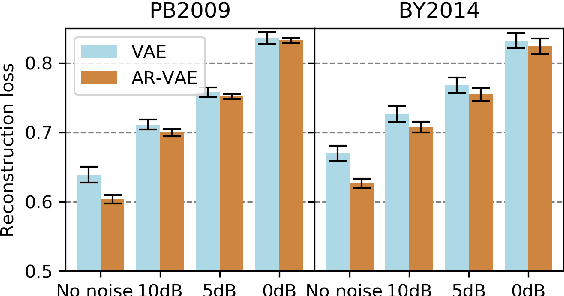
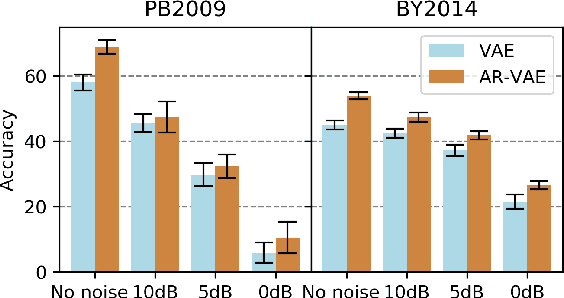
It is increasingly considered that human speech perception and production both rely on articulatory representations. In this paper, we investigate whether this type of representation could improve the performances of a deep generative model (here a variational autoencoder) trained to encode and decode acoustic speech features. First we develop an articulatory model able to associate articulatory parameters describing the jaw, tongue, lips and velum configurations with vocal tract shapes and spectral features. Then we incorporate these articulatory parameters into a variational autoencoder applied on spectral features by using a regularization technique that constraints part of the latent space to follow articulatory trajectories. We show that this articulatory constraint improves model training by decreasing time to convergence and reconstruction loss at convergence, and yields better performance in a speech denoising task.
Practical Speech Re-use Prevention in Voice-driven Services
Jan 12, 2021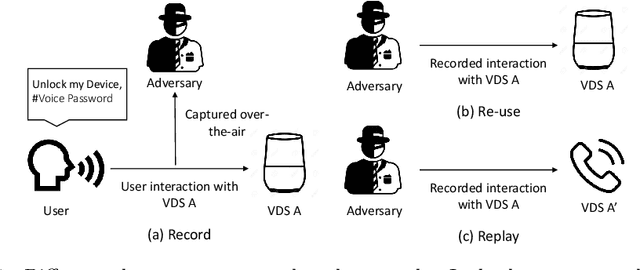

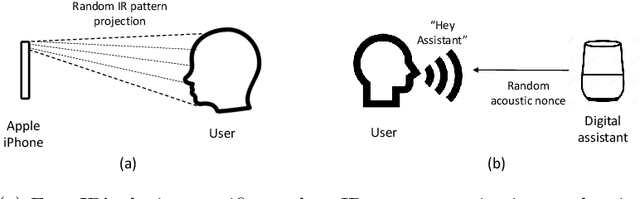

Voice-driven services (VDS) are being used in a variety of applications ranging from smart home control to payments using digital assistants. The input to such services is often captured via an open voice channel, e.g., using a microphone, in an unsupervised setting. One of the key operational security requirements in such setting is the freshness of the input speech. We present AEOLUS, a security overlay that proactively embeds a dynamic acoustic nonce at the time of user interaction, and detects the presence of the embedded nonce in the recorded speech to ensure freshness. We demonstrate that acoustic nonce can (i) be reliably embedded and retrieved, and (ii) be non-disruptive (and even imperceptible) to a VDS user. Optimal parameters (acoustic nonce's operating frequency, amplitude, and bitrate) are determined for (i) and (ii) from a practical perspective. Experimental results show that AEOLUS yields 0.5% FRR at 0% FAR for speech re-use prevention upto a distance of 4 meters in three real-world environments with different background noise levels. We also conduct a user study with 120 participants, which shows that the acoustic nonce does not degrade overall user experience for 94.16% of speech samples, on average, in these environments. AEOLUS can therefore be used in practice to prevent speech re-use and ensure the freshness of speech input.
Distribution Aware Metrics for Conditional Natural Language Generation
Sep 29, 2022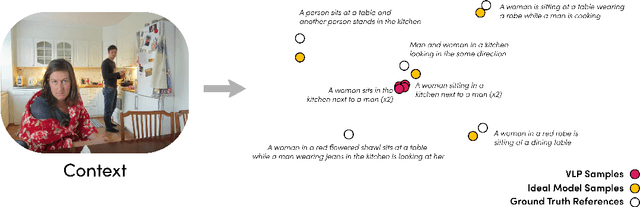

Traditional automated metrics for evaluating conditional natural language generation use pairwise comparisons between a single generated text and the best-matching gold-standard ground truth text. When multiple ground truths are available, scores are aggregated using an average or max operation across references. While this approach works well when diversity in the ground truth data (i.e. dispersion of the distribution of conditional texts) can be ascribed to noise, such as in automated speech recognition, it does not allow for robust evaluation in the case where diversity in the ground truths represents signal for the model. In this work we argue that existing metrics are not appropriate for domains such as visual description or summarization where ground truths are semantically diverse, and where the diversity in those captions captures useful additional information about the context. We propose a novel paradigm for multi-candidate evaluation of conditional language generation models, and a new family of metrics that compare the distributions of reference and model-generated caption sets using small sample sets of each. We demonstrate the utility of our approach with a case study in visual description: where we show that existing models optimize for single-description quality over diversity, and gain some insights into how sampling methods and temperature impact description quality and diversity.
Improving Confidence Estimation on Out-of-Domain Data for End-to-End Speech Recognition
Oct 07, 2021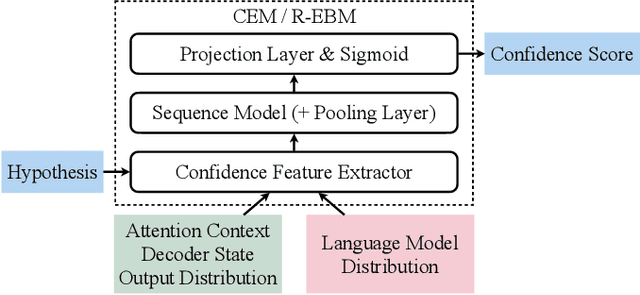
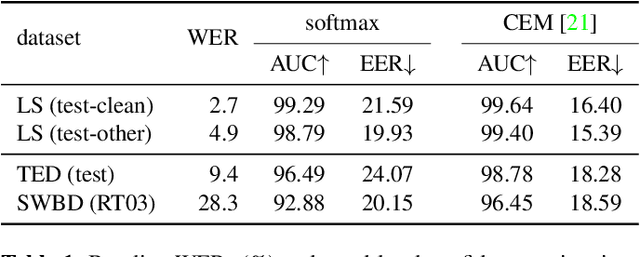
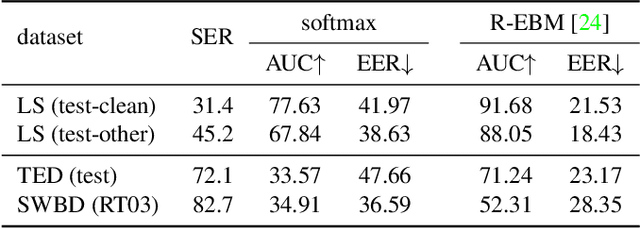
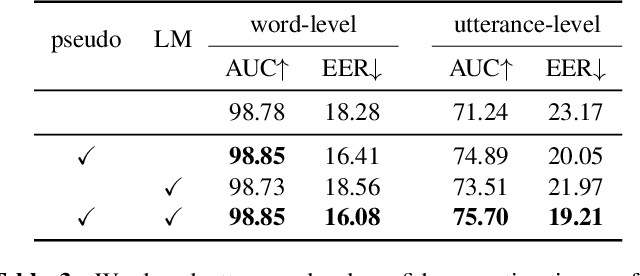
As end-to-end automatic speech recognition (ASR) models reach promising performance, various downstream tasks rely on good confidence estimators for these systems. Recent research has shown that model-based confidence estimators have a significant advantage over using the output softmax probabilities. If the input data to the speech recogniser is from mismatched acoustic and linguistic conditions, the ASR performance and the corresponding confidence estimators may exhibit severe degradation. Since confidence models are often trained on the same in-domain data as the ASR, generalising to out-of-domain (OOD) scenarios is challenging. By keeping the ASR model untouched, this paper proposes two approaches to improve the model-based confidence estimators on OOD data: using pseudo transcriptions and an additional OOD language model. With an ASR model trained on LibriSpeech, experiments show that the proposed methods can significantly improve the confidence metrics on TED-LIUM and Switchboard datasets while preserving in-domain performance. Furthermore, the improved confidence estimators are better calibrated on OOD data and can provide a much more reliable criterion for data selection.