 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAssessing the Answerability of Queries in Retrieval-Augmented Code Generation
Nov 08, 2024



Thanks to unprecedented language understanding and generation capabilities of large language model (LLM), Retrieval-augmented Code Generation (RaCG) has recently been widely utilized among software developers. While this has increased productivity, there are still frequent instances of incorrect codes being provided. In particular, there are cases where plausible yet incorrect codes are generated for queries from users that cannot be answered with the given queries and API descriptions. This study proposes a task for evaluating answerability, which assesses whether valid answers can be generated based on users' queries and retrieved APIs in RaCG. Additionally, we build a benchmark dataset called Retrieval-augmented Code Generability Evaluation (RaCGEval) to evaluate the performance of models performing this task. Experimental results show that this task remains at a very challenging level, with baseline models exhibiting a low performance of 46.7%. Furthermore, this study discusses methods that could significantly improve performance.
Shortened LLaMA: A Simple Depth Pruning for Large Language Models
Feb 05, 2024



Structured pruning of modern large language models (LLMs) has emerged as a way of decreasing their high computational needs. Width pruning reduces the size of projection weight matrices (e.g., by removing attention heads) while maintaining the number of layers. Depth pruning, in contrast, removes entire layers or blocks, while keeping the size of the remaining weights unchanged. Most current research focuses on either width-only or a blend of width and depth pruning, with little comparative analysis between the two units (width vs. depth) concerning their impact on LLM inference efficiency. In this work, we show that a simple depth pruning approach can compete with recent width pruning methods in terms of zero-shot task performance. Our pruning method boosts inference speeds, especially under memory-constrained conditions that require limited batch sizes for running LLMs, where width pruning is ineffective. We hope this work can help deploy LLMs on local and edge devices.
Encoder-decoder multimodal speaker change detection
Jun 01, 2023The task of speaker change detection (SCD), which detects points where speakers change in an input, is essential for several applications. Several studies solved the SCD task using audio inputs only and have shown limited performance. Recently, multimodal SCD (MMSCD) models, which utilise text modality in addition to audio, have shown improved performance. In this study, the proposed model are built upon two main proposals, a novel mechanism for modality fusion and the adoption of a encoder-decoder architecture. Different to previous MMSCD works that extract speaker embeddings from extremely short audio segments, aligned to a single word, we use a speaker embedding extracted from 1.5s. A transformer decoder layer further improves the performance of an encoder-only MMSCD model. The proposed model achieves state-of-the-art results among studies that report SCD performance and is also on par with recent work that combines SCD with automatic speech recognition via human transcription.
Back from the future: bidirectional CTC decoding using future information in speech recognition
Oct 07, 2021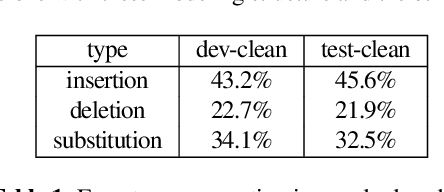

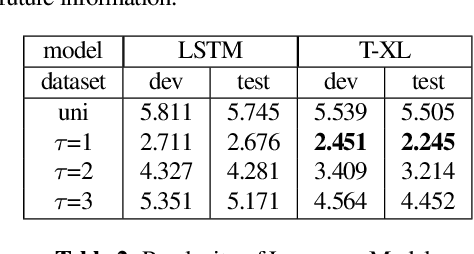
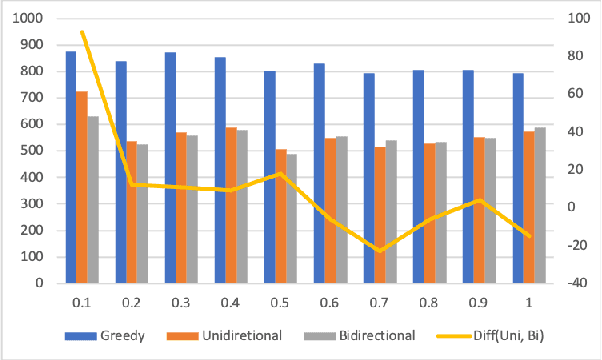
In this paper, we propose a simple but effective method to decode the output of Connectionist Temporal Classifier (CTC) model using a bi-directional neural language model. The bidirectional language model uses the future as well as the past information in order to predict the next output in the sequence. The proposed method based on bi-directional beam search takes advantage of the CTC greedy decoding output to represent the noisy future information. Experiments on the Librispeechdataset demonstrate the superiority of our proposed method compared to baselines using unidirectional decoding. In particular, the boost inaccuracy is most apparent at the start of a sequence which is the most erroneous part for existing systems based on unidirectional decoding.
Spell my name: keyword boosted speech recognition
Oct 06, 2021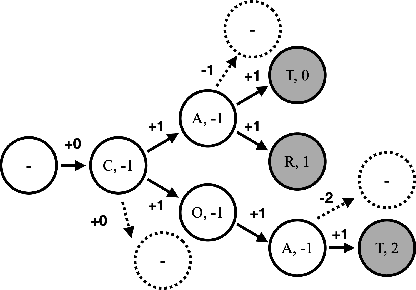

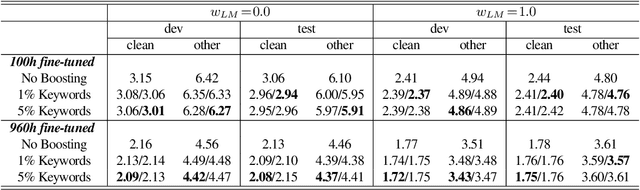
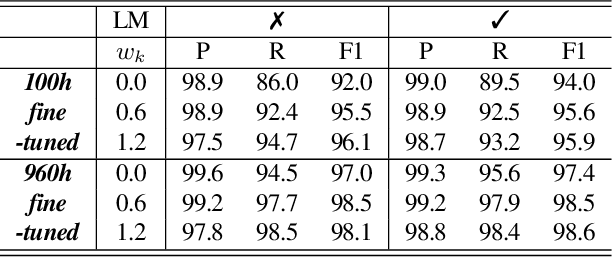
Recognition of uncommon words such as names and technical terminology is important to understanding conversations in context. However, the ability to recognise such words remains a challenge in modern automatic speech recognition (ASR) systems. In this paper, we propose a simple but powerful ASR decoding method that can better recognise these uncommon keywords, which in turn enables better readability of the results. The method boosts the probabilities of given keywords in a beam search based on acoustic model predictions. The method does not require any training in advance. We demonstrate the effectiveness of our method on the LibriSpeeech test sets and also internal data of real-world conversations. Our method significantly boosts keyword accuracy on the test sets, while maintaining the accuracy of the other words, and as well as providing significant qualitative improvements. This method is applicable to other tasks such as machine translation, or wherever unseen and difficult keywords need to be recognised in beam search.
Semi-supervised Disentanglement with Independent Vector Variational Autoencoders
Mar 14, 2020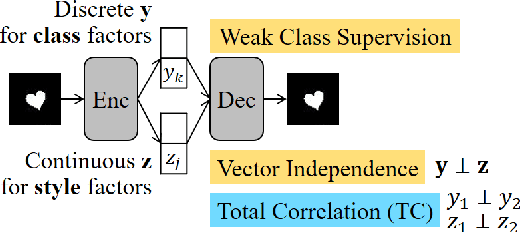
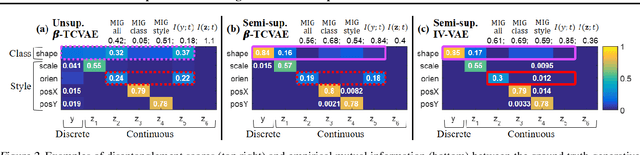

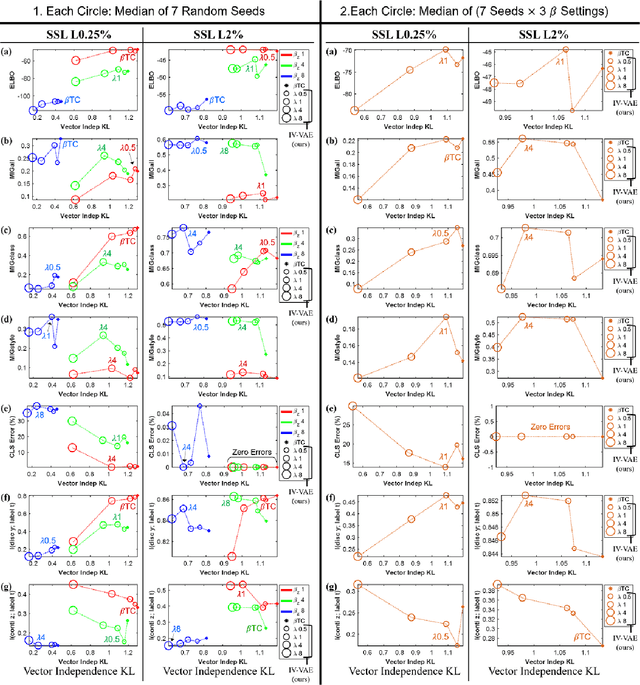
We aim to separate the generative factors of data into two latent vectors in a variational autoencoder. One vector captures class factors relevant to target classification tasks, while the other vector captures style factors relevant to the remaining information. To learn the discrete class features, we introduce supervision using a small amount of labeled data, which can simply yet effectively reduce the effort required for hyperparameter tuning performed in existing unsupervised methods. Furthermore, we introduce a learning objective to encourage statistical independence between the vectors. We show that (i) this vector independence term exists within the result obtained on decomposing the evidence lower bound with multiple latent vectors, and (ii) encouraging such independence along with reducing the total correlation within the vectors enhances disentanglement performance. Experiments conducted on several image datasets demonstrate that the disentanglement achieved via our method can improve classification performance and generation controllability.
Unpaired Speech Enhancement by Acoustic and Adversarial Supervision for Speech Recognition
Nov 06, 2018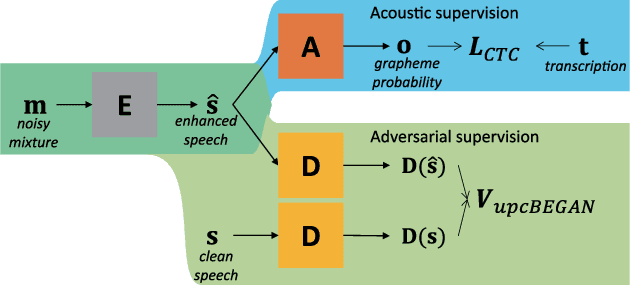
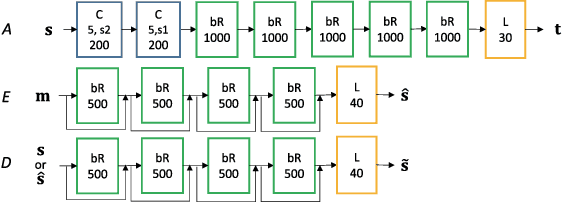
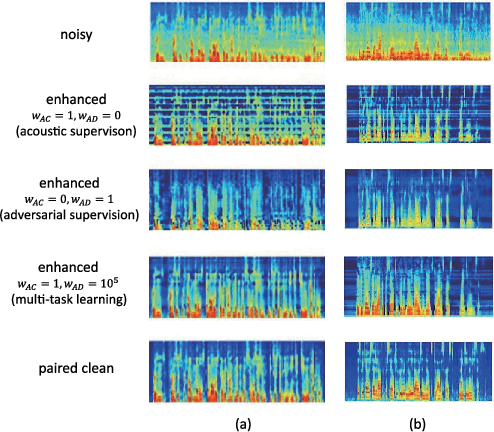
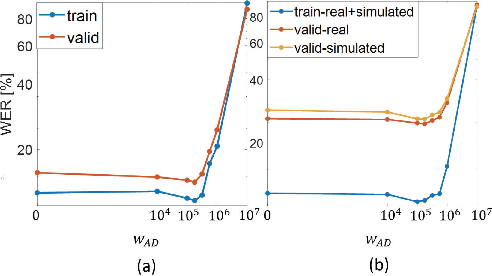
Many speech enhancement methods try to learn the relationship between noisy and clean speech, obtained using an acoustic room simulator. We point out several limitations of enhancement methods relying on clean speech targets; the goal of this work is proposing an alternative learning algorithm, called acoustic and adversarial supervision (AAS). AAS makes the enhanced output both maximizing the likelihood of transcription on the pre-trained acoustic model and having general characteristics of clean speech, which improve generalization on unseen noisy speeches. We employ the connectionist temporal classification and the unpaired conditional boundary equilibrium generative adversarial network as the loss function of AAS. AAS is tested on two datasets including additive noise without and with reverberation, Librispeech + DEMAND and CHiME-4. By visualizing the enhanced speech with different loss combinations, we demonstrate the role of each supervision. AAS achieves a lower word error rate than other state-of-the-art methods using the clean speech target in both datasets.
Deep CNNs along the Time Axis with Intermap Pooling for Robustness to Spectral Variations
Jul 12, 2016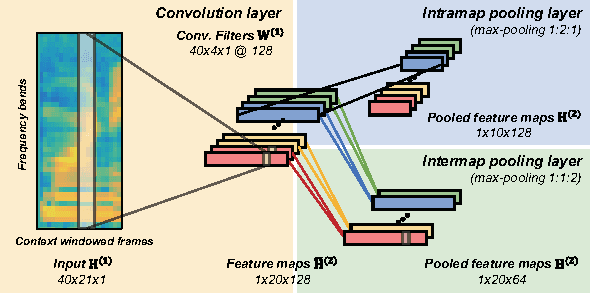
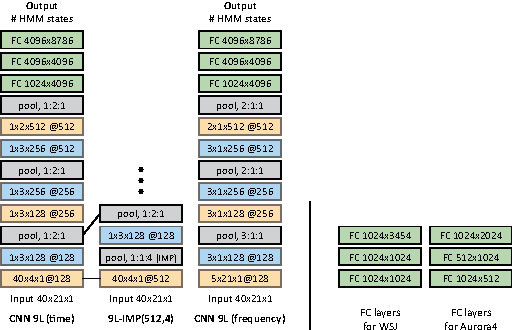
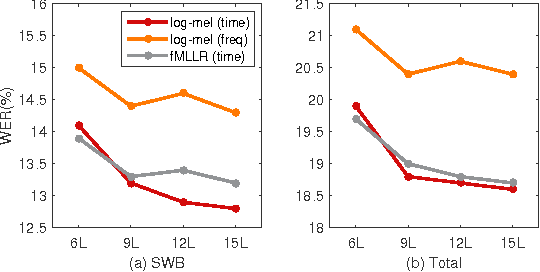
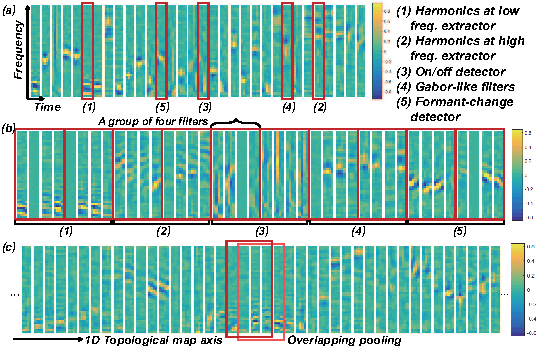
Convolutional neural networks (CNNs) with convolutional and pooling operations along the frequency axis have been proposed to attain invariance to frequency shifts of features. However, this is inappropriate with regard to the fact that acoustic features vary in frequency. In this paper, we contend that convolution along the time axis is more effective. We also propose the addition of an intermap pooling (IMP) layer to deep CNNs. In this layer, filters in each group extract common but spectrally variant features, then the layer pools the feature maps of each group. As a result, the proposed IMP CNN can achieve insensitivity to spectral variations characteristic of different speakers and utterances. The effectiveness of the IMP CNN architecture is demonstrated on several LVCSR tasks. Even without speaker adaptation techniques, the architecture achieved a WER of 12.7% on the SWB part of the Hub5'2000 evaluation test set, which is competitive with other state-of-the-art methods.
Compositional Sentence Representation from Character within Large Context Text
Jun 03, 2016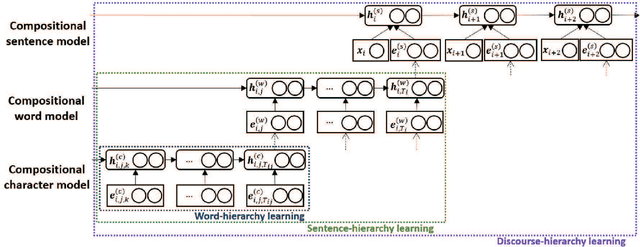
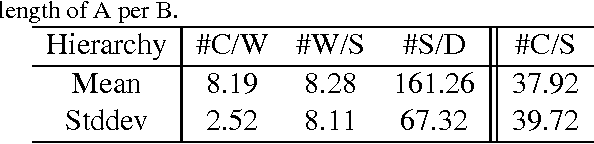
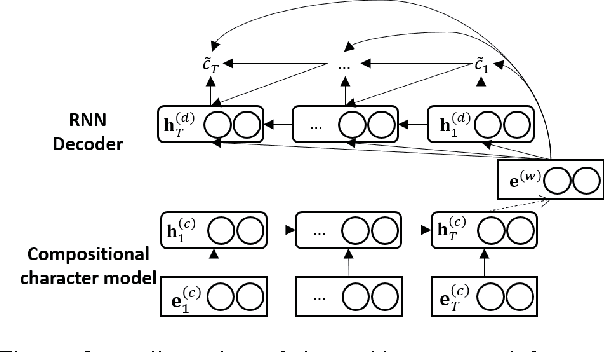
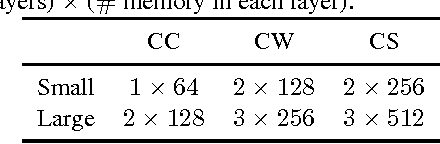
This paper describes a Hierarchical Composition Recurrent Network (HCRN) consisting of a 3-level hierarchy of compositional models: character, word and sentence. This model is designed to overcome two problems of representing a sentence on the basis of a constituent word sequence. The first is a data-sparsity problem in word embedding, and the other is a no usage of inter-sentence dependency. In the HCRN, word representations are built from characters, thus resolving the data-sparsity problem, and inter-sentence dependency is embedded into sentence representation at the level of sentence composition. We adopt a hierarchy-wise learning scheme in order to alleviate the optimization difficulties of learning deep hierarchical recurrent network in end-to-end fashion. The HCRN was quantitatively and qualitatively evaluated on a dialogue act classification task. Especially, sentence representations with an inter-sentence dependency are able to capture both implicit and explicit semantics of sentence, significantly improving performance. In the end, the HCRN achieved state-of-the-art performance with a test error rate of 22.7% for dialogue act classification on the SWBD-DAMSL database.