 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeThe Equalizer: Introducing Shape-Gain Decomposition in Neural Audio Codecs
Feb 17, 2026Neural audio codecs (NACs) typically encode the short-term energy (gain) and normalized structure (shape) of speech/audio signals jointly within the same latent space. As a result, they are poorly robust to a global variation of the input signal level in the sense that such variation has strong influence on the embedding vectors at the output of the encoder and their quantization. This methodology is inherently inefficient, leading to codebook redundancy and suboptimal bitrate-distortion performance. To address these limitations, we propose to introduce shape-gain decomposition, widely used in classical speech/audio coding, into the NAC framework. The principle of the proposed Equalizer methodology is to decompose the input signal -- before the NAC encoder -- into gain and normalized shape vector on a short-term basis. The shape vector is processed by the NAC, while the gain is quantized with scalar quantization and transmitted separately. The output (decoded) signal is reconstructed from the normalized output of the NAC and the quantized gain. Our experiments conducted on speech signals show that this general methodology, easily applicable to any NAC, enables a substantial gain in bitrate-distortion performance, as well as a massive reduction in complexity.
AnCoGen: Analysis, Control and Generation of Speech with a Masked Autoencoder
Jan 09, 2025This article introduces AnCoGen, a novel method that leverages a masked autoencoder to unify the analysis, control, and generation of speech signals within a single model. AnCoGen can analyze speech by estimating key attributes, such as speaker identity, pitch, content, loudness, signal-to-noise ratio, and clarity index. In addition, it can generate speech from these attributes and allow precise control of the synthesized speech by modifying them. Extensive experiments demonstrated the effectiveness of AnCoGen across speech analysis-resynthesis, pitch estimation, pitch modification, and speech enhancement.
Fill in the Gap! Combining Self-supervised Representation Learning with Neural Audio Synthesis for Speech Inpainting
May 30, 2024



Most speech self-supervised learning (SSL) models are trained with a pretext task which consists in predicting missing parts of the input signal, either future segments (causal prediction) or segments masked anywhere within the input (non-causal prediction). Learned speech representations can then be efficiently transferred to downstream tasks (e.g., automatic speech or speaker recognition). In the present study, we investigate the use of a speech SSL model for speech inpainting, that is reconstructing a missing portion of a speech signal from its surrounding context, i.e., fulfilling a downstream task that is very similar to the pretext task. To that purpose, we combine an SSL encoder, namely HuBERT, with a neural vocoder, namely HiFiGAN, playing the role of a decoder. In particular, we propose two solutions to match the HuBERT output with the HiFiGAN input, by freezing one and fine-tuning the other, and vice versa. Performance of both approaches was assessed in single- and multi-speaker settings, for both informed and blind inpainting configurations (i.e., the position of the mask is known or unknown, respectively), with different objective metrics and a perceptual evaluation. Performances show that if both solutions allow to correctly reconstruct signal portions up to the size of 200ms (and even 400ms in some cases), fine-tuning the SSL encoder provides a more accurate signal reconstruction in the single-speaker setting case, while freezing it (and training the neural vocoder instead) is a better strategy when dealing with multi-speaker data.
Mixture of Dynamical Variational Autoencoders for Multi-Source Trajectory Modeling and Separation
Dec 07, 2023



In this paper, we propose a latent-variable generative model called mixture of dynamical variational autoencoders (MixDVAE) to model the dynamics of a system composed of multiple moving sources. A DVAE model is pre-trained on a single-source dataset to capture the source dynamics. Then, multiple instances of the pre-trained DVAE model are integrated into a multi-source mixture model with a discrete observation-to-source assignment latent variable. The posterior distributions of both the discrete observation-to-source assignment variable and the continuous DVAE variables representing the sources content/position are estimated using a variational expectation-maximization algorithm, leading to multi-source trajectories estimation. We illustrate the versatility of the proposed MixDVAE model on two tasks: a computer vision task, namely multi-object tracking, and an audio processing task, namely single-channel audio source separation. Experimental results show that the proposed method works well on these two tasks, and outperforms several baseline methods.
Unsupervised speech enhancement with deep dynamical generative speech and noise models
Jun 13, 2023

This work builds on a previous work on unsupervised speech enhancement using a dynamical variational autoencoder (DVAE) as the clean speech model and non-negative matrix factorization (NMF) as the noise model. We propose to replace the NMF noise model with a deep dynamical generative model (DDGM) depending either on the DVAE latent variables, or on the noisy observations, or on both. This DDGM can be trained in three configurations: noise-agnostic, noise-dependent and noise adaptation after noise-dependent training. Experimental results show that the proposed method achieves competitive performance compared to state-of-the-art unsupervised speech enhancement methods, while the noise-dependent training configuration yields a much more time-efficient inference process.
A Multimodal Dynamical Variational Autoencoder for Audiovisual Speech Representation Learning
May 05, 2023In this paper, we present a multimodal \textit{and} dynamical VAE (MDVAE) applied to unsupervised audio-visual speech representation learning. The latent space is structured to dissociate the latent dynamical factors that are shared between the modalities from those that are specific to each modality. A static latent variable is also introduced to encode the information that is constant over time within an audiovisual speech sequence. The model is trained in an unsupervised manner on an audiovisual emotional speech dataset, in two stages. In the first stage, a vector quantized VAE (VQ-VAE) is learned independently for each modality, without temporal modeling. The second stage consists in learning the MDVAE model on the intermediate representation of the VQ-VAEs before quantization. The disentanglement between static versus dynamical and modality-specific versus modality-common information occurs during this second training stage. Extensive experiments are conducted to investigate how audiovisual speech latent factors are encoded in the latent space of MDVAE. These experiments include manipulating audiovisual speech, audiovisual facial image denoising, and audiovisual speech emotion recognition. The results show that MDVAE effectively combines the audio and visual information in its latent space. They also show that the learned static representation of audiovisual speech can be used for emotion recognition with few labeled data, and with better accuracy compared with unimodal baselines and a state-of-the-art supervised model based on an audiovisual transformer architecture.
Speech Modeling with a Hierarchical Transformer Dynamical VAE
Mar 07, 2023



The dynamical variational autoencoders (DVAEs) are a family of latent-variable deep generative models that extends the VAE to model a sequence of observed data and a corresponding sequence of latent vectors. In almost all the DVAEs of the literature, the temporal dependencies within each sequence and across the two sequences are modeled with recurrent neural networks. In this paper, we propose to model speech signals with the Hierarchical Transformer DVAE (HiT-DVAE), which is a DVAE with two levels of latent variable (sequence-wise and frame-wise) and in which the temporal dependencies are implemented with the Transformer architecture. We show that HiT-DVAE outperforms several other DVAEs for speech spectrogram modeling, while enabling a simpler training procedure, revealing its high potential for downstream low-level speech processing tasks such as speech enhancement.
BERT, can HE predict contrastive focus? Predicting and controlling prominence in neural TTS using a language model
Jul 04, 2022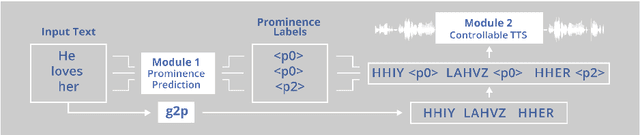

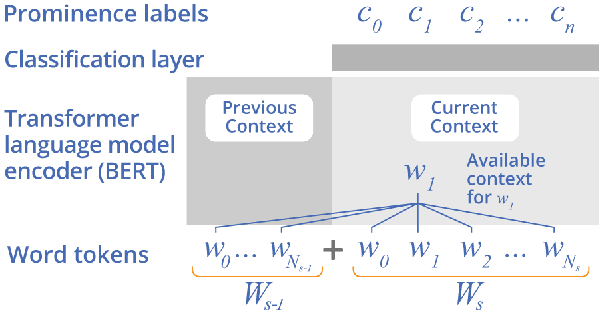
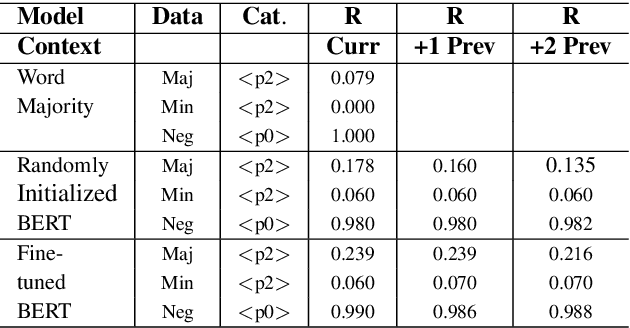
Several recent studies have tested the use of transformer language model representations to infer prosodic features for text-to-speech synthesis (TTS). While these studies have explored prosody in general, in this work, we look specifically at the prediction of contrastive focus on personal pronouns. This is a particularly challenging task as it often requires semantic, discursive and/or pragmatic knowledge to predict correctly. We collect a corpus of utterances containing contrastive focus and we evaluate the accuracy of a BERT model, finetuned to predict quantized acoustic prominence features, on these samples. We also investigate how past utterances can provide relevant information for this prediction. Furthermore, we evaluate the controllability of pronoun prominence in a TTS model conditioned on acoustic prominence features.
Learning and controlling the source-filter representation of speech with a variational autoencoder
Apr 14, 2022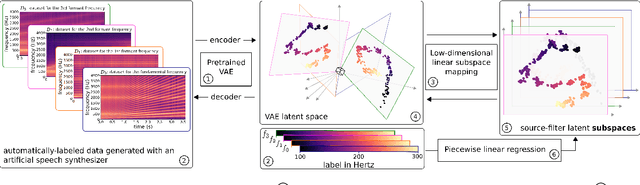
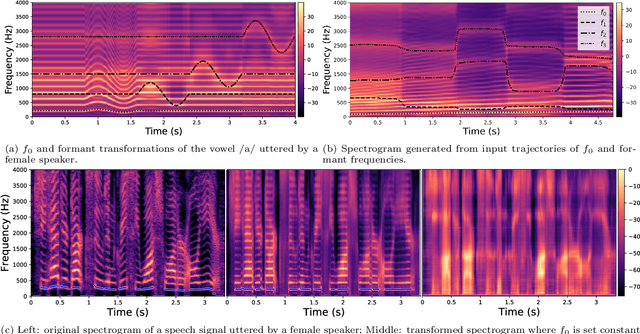
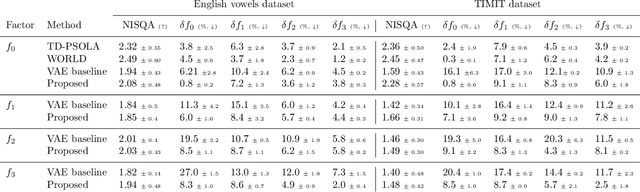
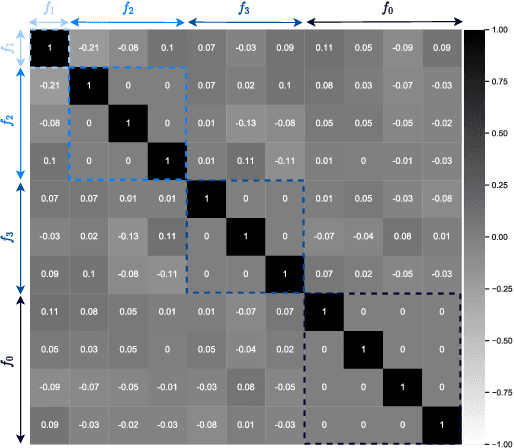
Understanding and controlling latent representations in deep generative models is a challenging yet important problem for analyzing, transforming and generating various types of data. In speech processing, inspiring from the anatomical mechanisms of phonation, the source-filter model considers that speech signals are produced from a few independent and physically meaningful continuous latent factors, among which the fundamental frequency $f_0$ and the formants are of primary importance. In this work, we show that the source-filter model of speech production naturally arises in the latent space of a variational autoencoder (VAE) trained in an unsupervised manner on a dataset of natural speech signals. Using only a few seconds of labeled speech signals generated with an artificial speech synthesizer, we experimentally illustrate that $f_0$ and the formant frequencies are encoded in orthogonal subspaces of the VAE latent space and we develop a weakly-supervised method to accurately and independently control these speech factors of variation within the learned latent subspaces. Without requiring additional information such as text or human-labeled data, this results in a deep generative model of speech spectrograms that is conditioned on $f_0$ and the formant frequencies, and which is applied to the transformation of speech signals.
Repeat after me: Self-supervised learning of acoustic-to-articulatory mapping by vocal imitation
Apr 05, 2022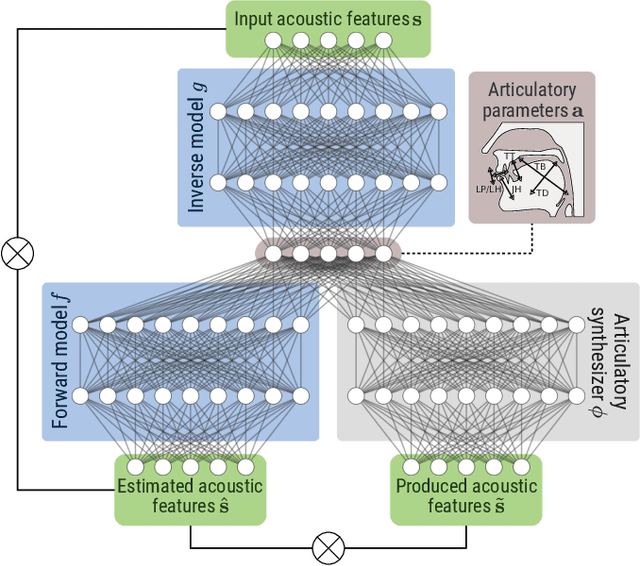
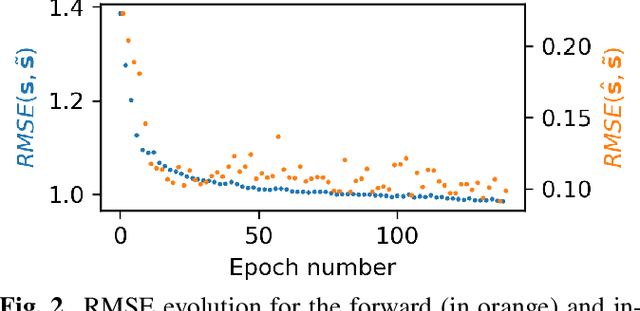
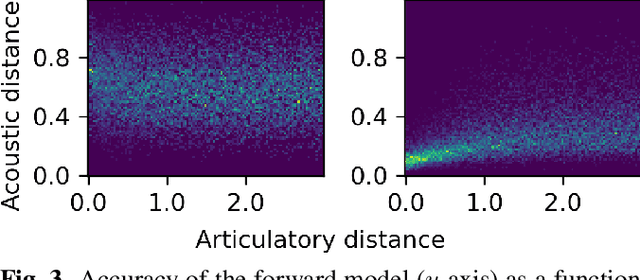
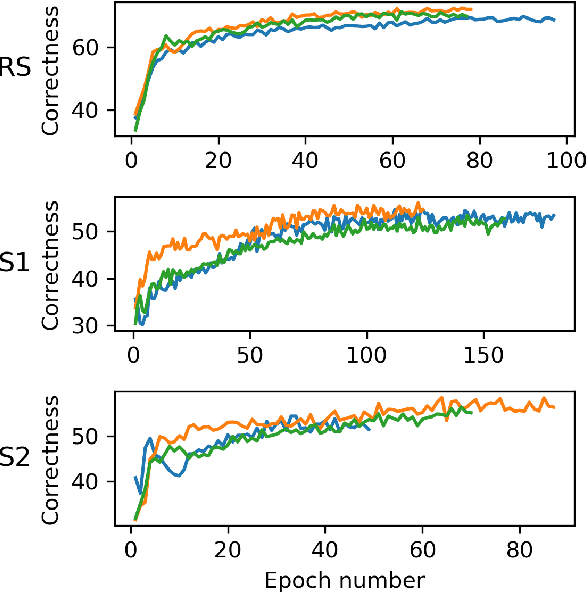
We propose a computational model of speech production combining a pre-trained neural articulatory synthesizer able to reproduce complex speech stimuli from a limited set of interpretable articulatory parameters, a DNN-based internal forward model predicting the sensory consequences of articulatory commands, and an internal inverse model based on a recurrent neural network recovering articulatory commands from the acoustic speech input. Both forward and inverse models are jointly trained in a self-supervised way from raw acoustic-only speech data from different speakers. The imitation simulations are evaluated objectively and subjectively and display quite encouraging performances.