 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"speech": models, code, and papers
Deep Multi-Frame MVDR Filtering for Binaural Noise Reduction
May 18, 2022
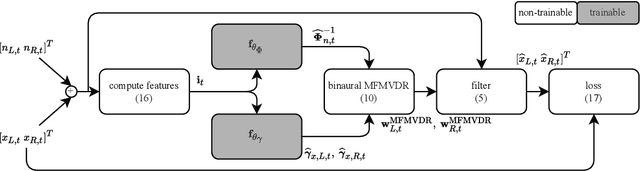
To improve speech intelligibility and speech quality in noisy environments, binaural noise reduction algorithms for head-mounted assistive listening devices are of crucial importance. Several binaural noise reduction algorithms such as the well-known binaural minimum variance distortionless response (MVDR) beamformer have been proposed, which exploit spatial correlations of both the target speech and the noise components. Furthermore, for single-microphone scenarios, multi-frame algorithms such as the multi-frame MVDR (MFMVDR) filter have been proposed, which exploit temporal instead of spatial correlations. In this contribution, we propose a binaural extension of the MFMVDR filter, which exploits both spatial and temporal correlations. The binaural MFMVDR filters are embedded in an end-to-end deep learning framework, where the required parameters, i.e., the speech spatio-temporal correlation vectors as well as the (inverse) noise spatio-temporal covariance matrix, are estimated by temporal convolutional networks (TCNs) that are trained by minimizing the mean spectral absolute error loss function. Simulation results comprising measured binaural room impulses and diverse noise sources at signal-to-noise ratios from -5 dB to 20 dB demonstrate the advantage of utilizing the binaural MFMVDR filter structure over directly estimating the binaural multi-frame filter coefficients with TCNs.
FrAUG: A Frame Rate Based Data Augmentation Method for Depression Detection from Speech Signals
Feb 11, 2022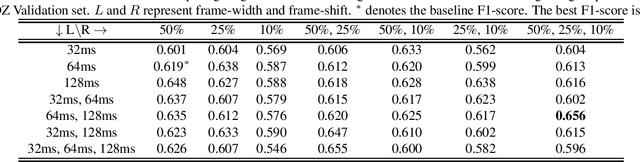
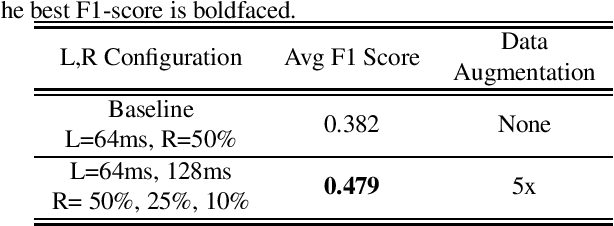
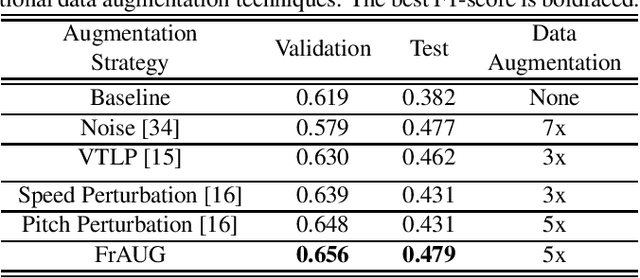
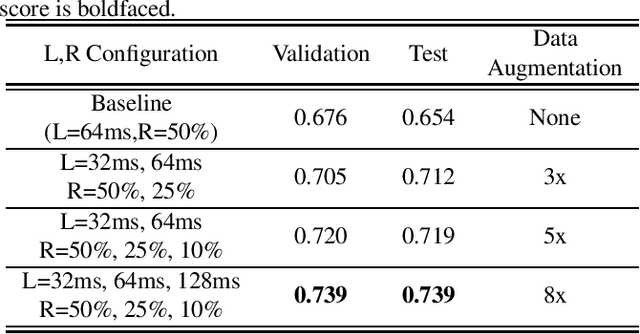
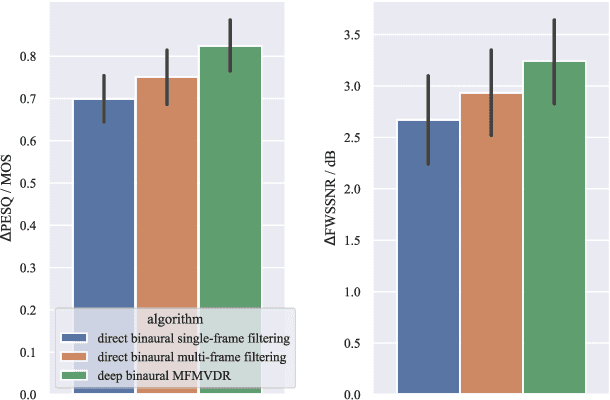
In this paper, a data augmentation method is proposed for depression detection from speech signals. Samples for data augmentation were created by changing the frame-width and the frame-shift parameters during the feature extraction process. Unlike other data augmentation methods (such as VTLP, pitch perturbation, or speed perturbation), the proposed method does not explicitly change acoustic parameters but rather the time-frequency resolution of frame-level features. The proposed method was evaluated using two different datasets, models, and input acoustic features. For the DAIC-WOZ (English) dataset when using the DepAudioNet model and mel-Spectrograms as input, the proposed method resulted in an improvement of 5.97% (validation) and 25.13% (test) when compared to the baseline. The improvements for the CONVERGE (Mandarin) dataset when using the x-vector embeddings with CNN as the backend and MFCCs as input features were 9.32% (validation) and 12.99% (test). Baseline systems do not incorporate any data augmentation. Further, the proposed method outperformed commonly used data-augmentation methods such as noise augmentation, VTLP, Speed, and Pitch Perturbation. All improvements were statistically significant.
Adaptive Natural Language Generation for Task-oriented Dialogue via Reinforcement Learning
Sep 16, 2022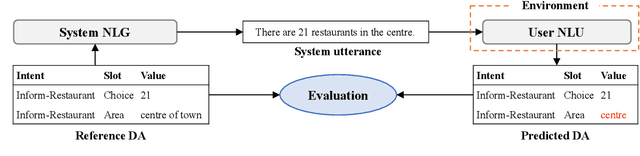
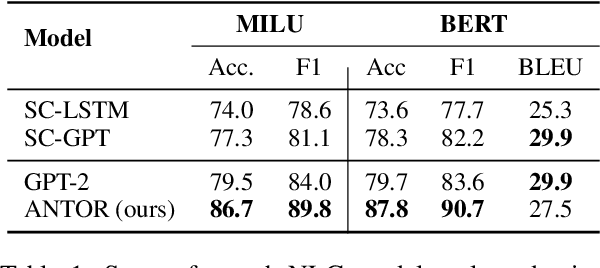
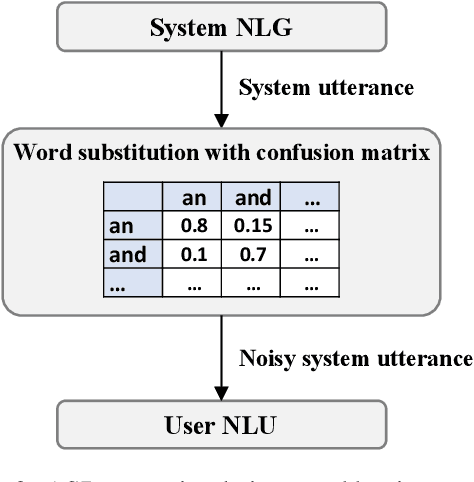
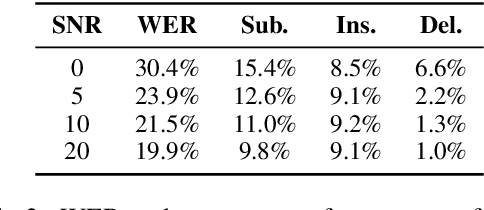
When a natural language generation (NLG) component is implemented in a real-world task-oriented dialogue system, it is necessary to generate not only natural utterances as learned on training data but also utterances adapted to the dialogue environment (e.g., noise from environmental sounds) and the user (e.g., users with low levels of understanding ability). Inspired by recent advances in reinforcement learning (RL) for language generation tasks, we propose ANTOR, a method for Adaptive Natural language generation for Task-Oriented dialogue via Reinforcement learning. In ANTOR, a natural language understanding (NLU) module, which corresponds to the user's understanding of system utterances, is incorporated into the objective function of RL. If the NLG's intentions are correctly conveyed to the NLU, which understands a system's utterances, the NLG is given a positive reward. We conducted experiments on the MultiWOZ dataset, and we confirmed that ANTOR could generate adaptive utterances against speech recognition errors and the different vocabulary levels of users.
Effectiveness of Mining Audio and Text Pairs from Public Data for Improving ASR Systems for Low-Resource Languages
Aug 26, 2022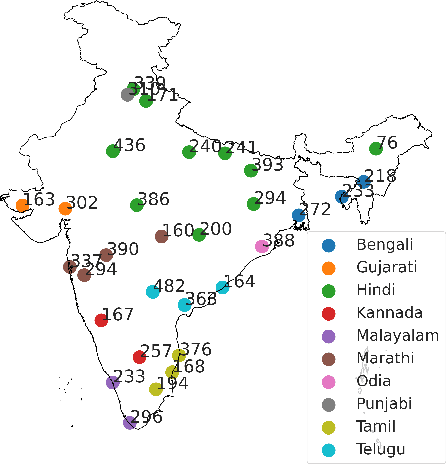
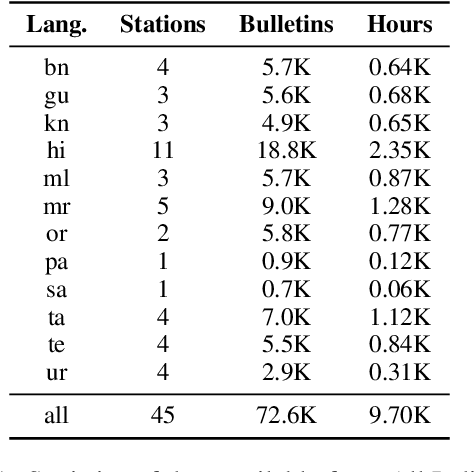

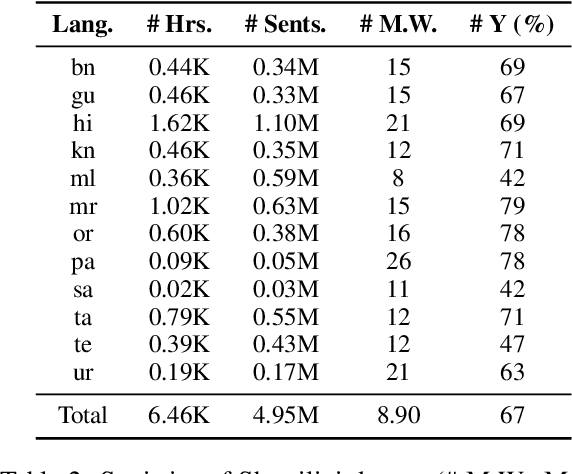
End-to-end (E2E) models have become the default choice for state-of-the-art speech recognition systems. Such models are trained on large amounts of labelled data, which are often not available for low-resource languages. Techniques such as self-supervised learning and transfer learning hold promise, but have not yet been effective in training accurate models. On the other hand, collecting labelled datasets on a diverse set of domains and speakers is very expensive. In this work, we demonstrate an inexpensive and effective alternative to these approaches by ``mining'' text and audio pairs for Indian languages from public sources, specifically from the public archives of All India Radio. As a key component, we adapt the Needleman-Wunsch algorithm to align sentences with corresponding audio segments given a long audio and a PDF of its transcript, while being robust to errors due to OCR, extraneous text, and non-transcribed speech. We thus create Shrutilipi, a dataset which contains over 6,400 hours of labelled audio across 12 Indian languages totalling to 4.95M sentences. On average, Shrutilipi results in a 2.3x increase over publicly available labelled data. We establish the quality of Shrutilipi with 21 human evaluators across the 12 languages. We also establish the diversity of Shrutilipi in terms of represented regions, speakers, and mentioned named entities. Significantly, we show that adding Shrutilipi to the training set of Wav2Vec models leads to an average decrease in WER of 5.8\% for 7 languages on the IndicSUPERB benchmark. For Hindi, which has the most benchmarks (7), the average WER falls from 18.8% to 13.5%. This improvement extends to efficient models: We show a 2.3% drop in WER for a Conformer model (10x smaller than Wav2Vec). Finally, we demonstrate the diversity of Shrutilipi by showing that the model trained with it is more robust to noisy input.
UserLibri: A Dataset for ASR Personalization Using Only Text
Jul 02, 2022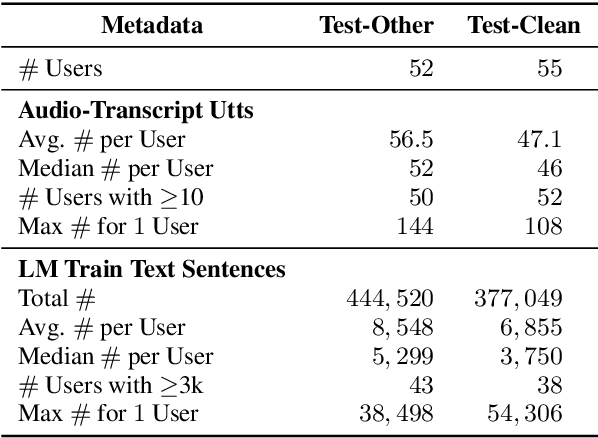
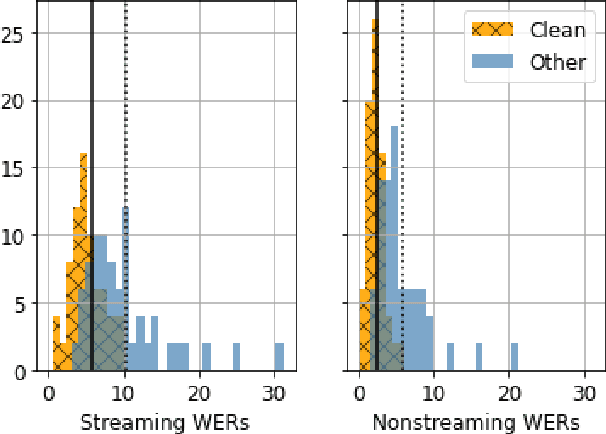
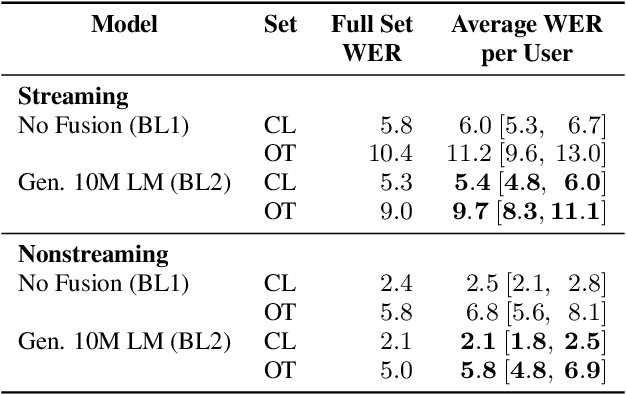
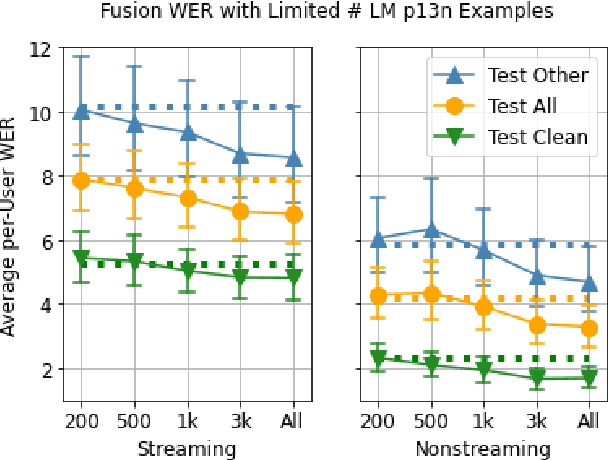
Personalization of speech models on mobile devices (on-device personalization) is an active area of research, but more often than not, mobile devices have more text-only data than paired audio-text data. We explore training a personalized language model on text-only data, used during inference to improve speech recognition performance for that user. We experiment on a user-clustered LibriSpeech corpus, supplemented with personalized text-only data for each user from Project Gutenberg. We release this User-Specific LibriSpeech (UserLibri) dataset to aid future personalization research. LibriSpeech audio-transcript pairs are grouped into 55 users from the test-clean dataset and 52 users from test-other. We are able to lower the average word error rate per user across both sets in streaming and nonstreaming models, including an improvement of 2.5 for the harder set of test-other users when streaming.
WaDeNet: Wavelet Decomposition based CNN for Speech Processing
Nov 11, 2020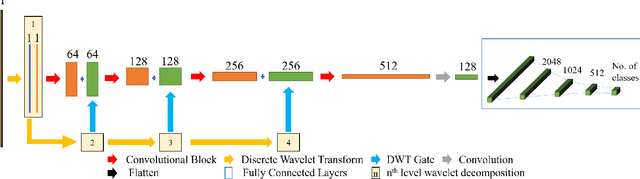
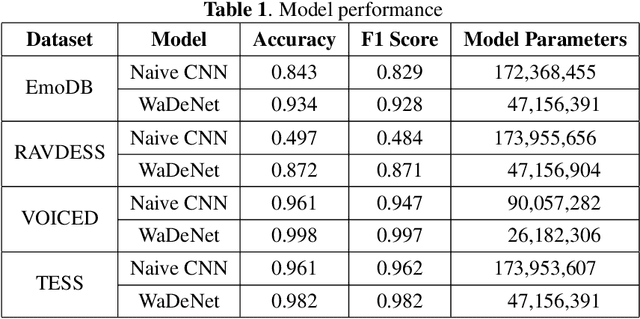
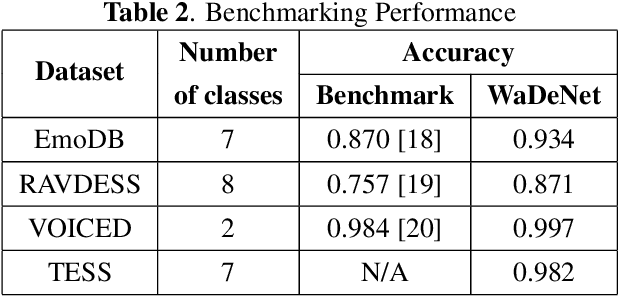
Existing speech processing systems consist of different modules, individually optimized for a specific task such as acoustic modelling or feature extraction. In addition to not assuring optimality of the system, the disjoint nature of current speech processing systems make them unsuitable for ubiquitous health applications. We propose WaDeNet, an end-to-end model for mobile speech processing. In order to incorporate spectral features, WaDeNet embeds wavelet decomposition of the speech signal within the architecture. This allows WaDeNet to learn from spectral features in an end-to-end manner, thus alleviating the need for feature extraction and successive modules that are currently present in speech processing systems. WaDeNet outperforms the current state of the art in datasets that involve speech for mobile health applications such as non-invasive emotion recognition. WaDeNet achieves an average increase in accuracy of 6.36% when compared to the existing state of the art models. Additionally, WaDeNet is considerably lighter than a simple CNNs with a similar architecture.
Speaker and Direction Inferred Dual-channel Speech Separation
Feb 08, 2021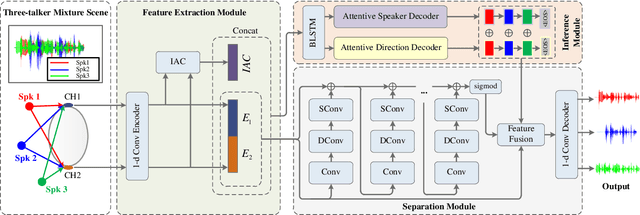
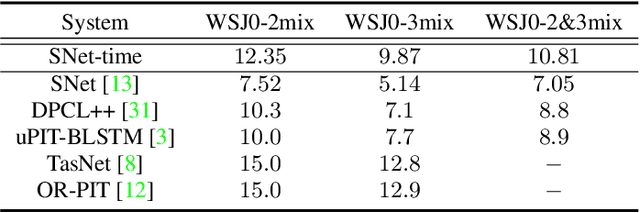
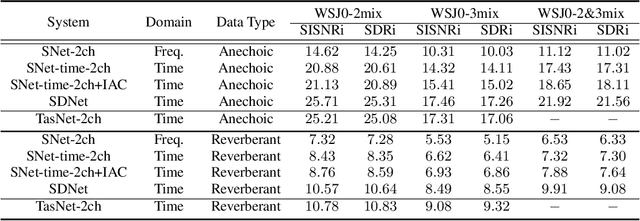
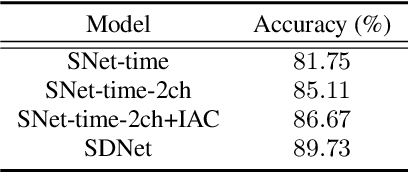
Most speech separation methods, trying to separate all channel sources simultaneously, are still far from having enough general- ization capabilities for real scenarios where the number of input sounds is usually uncertain and even dynamic. In this work, we employ ideas from auditory attention with two ears and propose a speaker and direction inferred speech separation network (dubbed SDNet) to solve the cocktail party problem. Specifically, our SDNet first parses out the respective perceptual representations with their speaker and direction characteristics from the mixture of the scene in a sequential manner. Then, the perceptual representations are utilized to attend to each corresponding speech. Our model gener- ates more precise perceptual representations with the help of spatial features and successfully deals with the problem of the unknown number of sources and the selection of outputs. The experiments on standard fully-overlapped speech separation benchmarks, WSJ0- 2mix, WSJ0-3mix, and WSJ0-2&3mix, show the effectiveness, and our method achieves SDR improvements of 25.31 dB, 17.26 dB, and 21.56 dB under anechoic settings. Our codes will be released at https://github.com/aispeech-lab/SDNet.
Fast Development of ASR in African Languages using Self Supervised Speech Representation Learning
Mar 16, 2021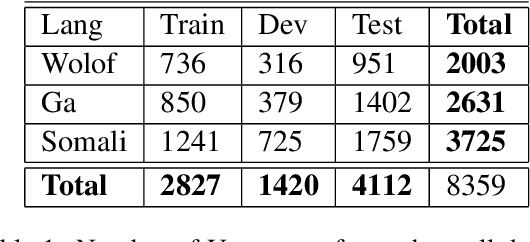
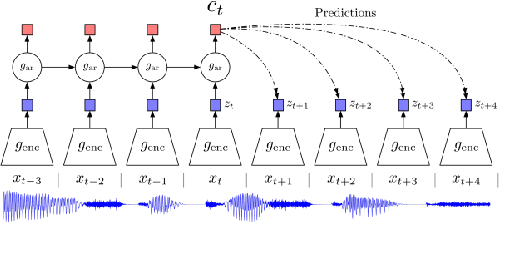
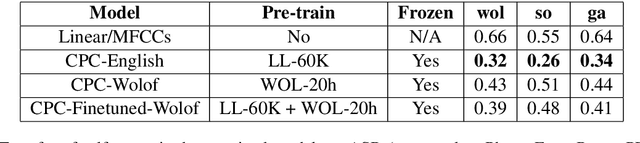
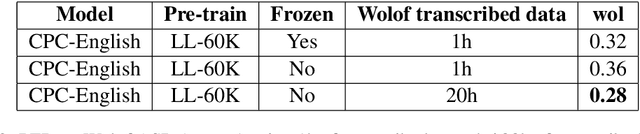
This paper describes the results of an informal collaboration launched during the African Master of Machine Intelligence (AMMI) in June 2020. After a series of lectures and labs on speech data collection using mobile applications and on self-supervised representation learning from speech, a small group of students and the lecturer continued working on automatic speech recognition (ASR) project for three languages: Wolof, Ga, and Somali. This paper describes how data was collected and ASR systems developed with a small amount (1h) of transcribed speech as training data. In these low resource conditions, pre-training a model on large amounts of raw speech was fundamental for the efficiency of ASR systems developed.
Speaker Separation Using Speaker Inventories and Estimated Speech
Oct 20, 2020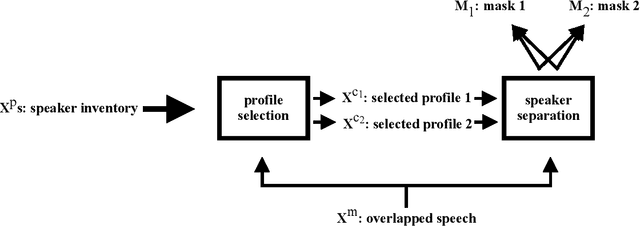
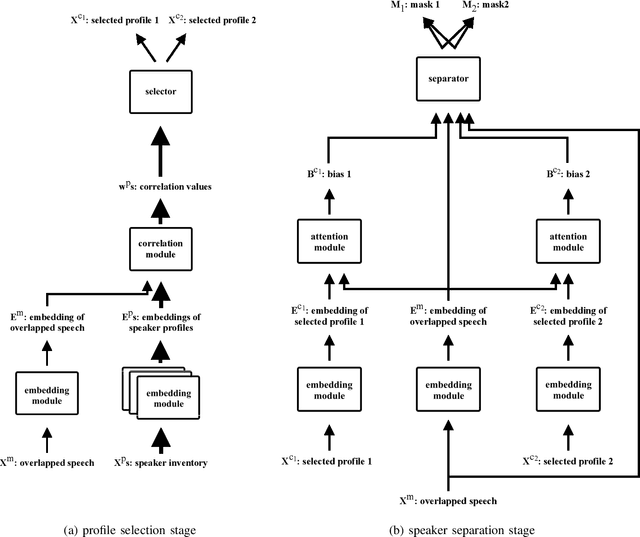
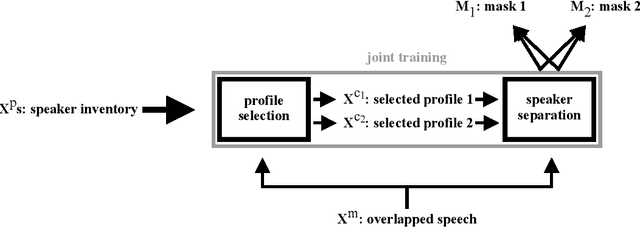
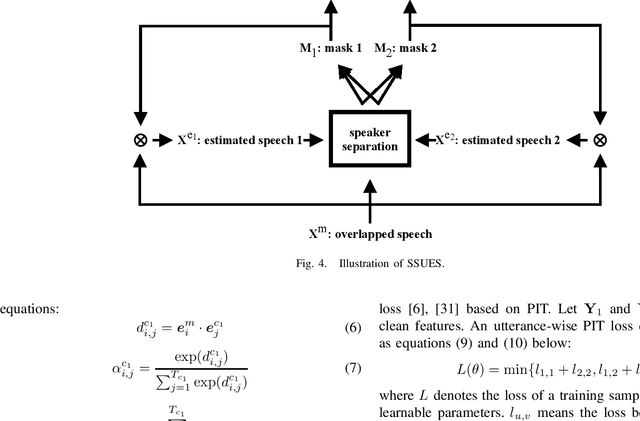
We propose speaker separation using speaker inventories and estimated speech (SSUSIES), a framework leveraging speaker profiles and estimated speech for speaker separation. SSUSIES contains two methods, speaker separation using speaker inventories (SSUSI) and speaker separation using estimated speech (SSUES). SSUSI performs speaker separation with the help of speaker inventory. By combining the advantages of permutation invariant training (PIT) and speech extraction, SSUSI significantly outperforms conventional approaches. SSUES is a widely applicable technique that can substantially improve speaker separation performance using the output of first-pass separation. We evaluate the models on both speaker separation and speech recognition metrics.
Visual Speech Enhancement Without A Real Visual Stream
Dec 20, 2020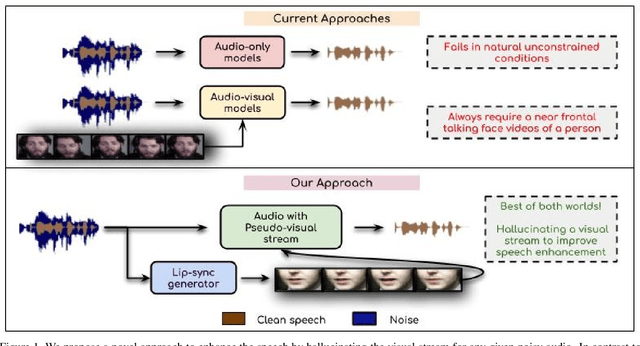

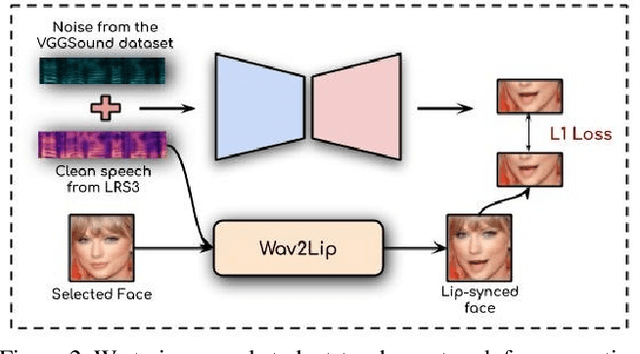
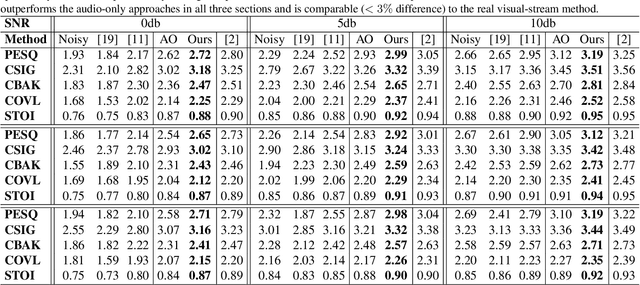
In this work, we re-think the task of speech enhancement in unconstrained real-world environments. Current state-of-the-art methods use only the audio stream and are limited in their performance in a wide range of real-world noises. Recent works using lip movements as additional cues improve the quality of generated speech over "audio-only" methods. But, these methods cannot be used for several applications where the visual stream is unreliable or completely absent. We propose a new paradigm for speech enhancement by exploiting recent breakthroughs in speech-driven lip synthesis. Using one such model as a teacher network, we train a robust student network to produce accurate lip movements that mask away the noise, thus acting as a "visual noise filter". The intelligibility of the speech enhanced by our pseudo-lip approach is comparable (< 3% difference) to the case of using real lips. This implies that we can exploit the advantages of using lip movements even in the absence of a real video stream. We rigorously evaluate our model using quantitative metrics as well as human evaluations. Additional ablation studies and a demo video on our website containing qualitative comparisons and results clearly illustrate the effectiveness of our approach. We provide a demo video which clearly illustrates the effectiveness of our proposed approach on our website: \url{http://cvit.iiit.ac.in/research/projects/cvit-projects/visual-speech-enhancement-without-a-real-visual-stream}. The code and models are also released for future research: \url{https://github.com/Sindhu-Hegde/pseudo-visual-speech-denoising}.