 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeA Step Towards Preserving Speakers' Identity While Detecting Depression Via Speaker Disentanglement
Jun 29, 2022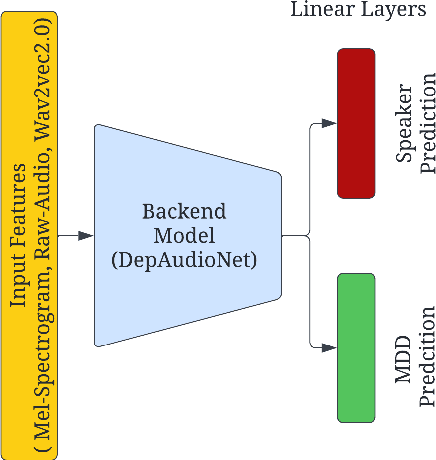
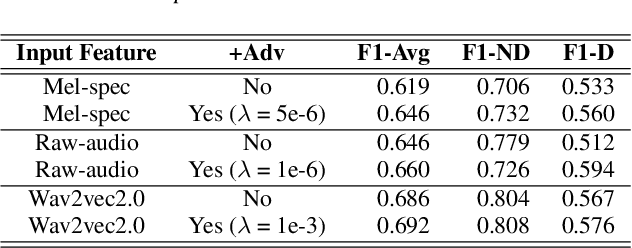
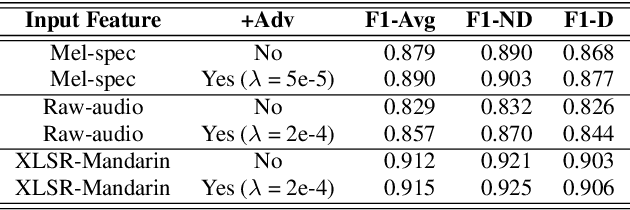

Preserving a patient's identity is a challenge for automatic, speech-based diagnosis of mental health disorders. In this paper, we address this issue by proposing adversarial disentanglement of depression characteristics and speaker identity. The model used for depression classification is trained in a speaker-identity-invariant manner by minimizing depression prediction loss and maximizing speaker prediction loss during training. The effectiveness of the proposed method is demonstrated on two datasets - DAIC-WOZ (English) and CONVERGE (Mandarin), with three feature sets (Mel-spectrograms, raw-audio signals, and the last-hidden-state of Wav2vec2.0), using a modified DepAudioNet model. With adversarial training, depression classification improves for every feature when compared to the baseline. Wav2vec2.0 features with adversarial learning resulted in the best performance (F1-score of 69.2% for DAIC-WOZ and 91.5% for CONVERGE). Analysis of the class-separability measure (J-ratio) of the hidden states of the DepAudioNet model shows that when adversarial learning is applied, the backend model loses some speaker-discriminability while it improves depression-discriminability. These results indicate that there are some components of speaker identity that may not be useful for depression detection and minimizing their effects provides a more accurate diagnosis of the underlying disorder and can safeguard a speaker's identity.
Unsupervised Instance Discriminative Learning for Depression Detection from Speech Signals
Jun 27, 2022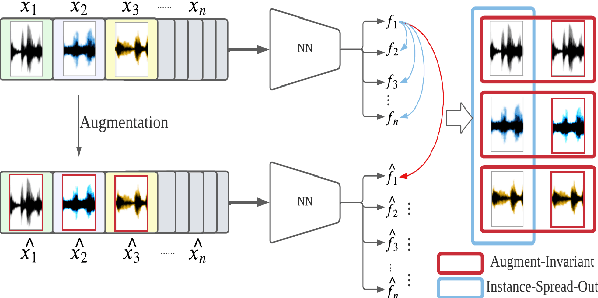
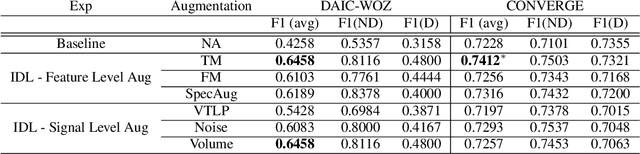
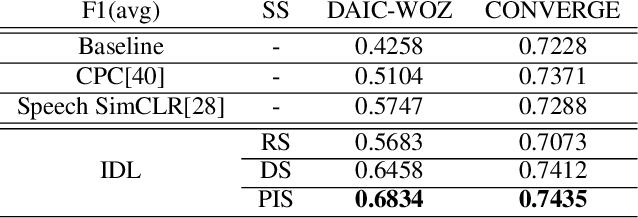
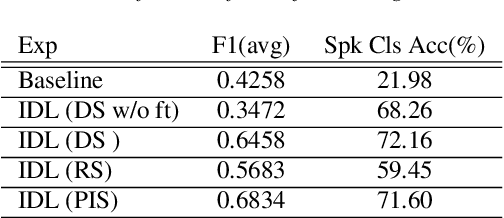
Major Depressive Disorder (MDD) is a severe illness that affects millions of people, and it is critical to diagnose this disorder as early as possible. Detecting depression from voice signals can be of great help to physicians and can be done without any invasive procedure. Since relevant labelled data are scarce, we propose a modified Instance Discriminative Learning (IDL) method, an unsupervised pre-training technique, to extract augment-invariant and instance-spread-out embeddings. In terms of learning augment-invariant embeddings, various data augmentation methods for speech are investigated, and time-masking yields the best performance. To learn instance-spread-out embeddings, we explore methods for sampling instances for a training batch (distinct speaker-based and random sampling). It is found that the distinct speaker-based sampling provides better performance than the random one, and we hypothesize that this result is because relevant speaker information is preserved in the embedding. Additionally, we propose a novel sampling strategy, Pseudo Instance-based Sampling (PIS), based on clustering algorithms, to enhance spread-out characteristics of the embeddings. Experiments are conducted with DepAudioNet on DAIC-WOZ (English) and CONVERGE (Mandarin) datasets, and statistically significant improvements, with p-value 0.0015 and 0.05, respectively, are observed using PIS in the detection of MDD relative to the baseline without pre-training.
FrAUG: A Frame Rate Based Data Augmentation Method for Depression Detection from Speech Signals
Feb 11, 2022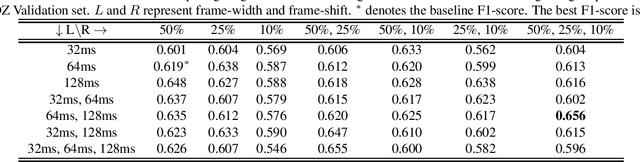
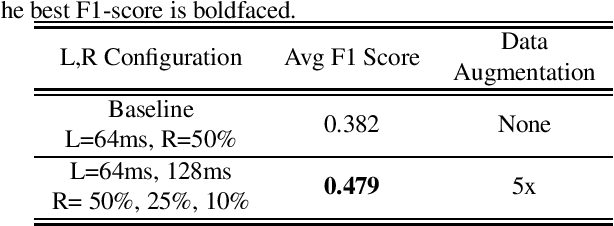
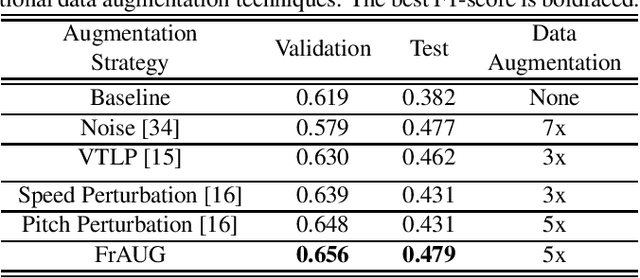
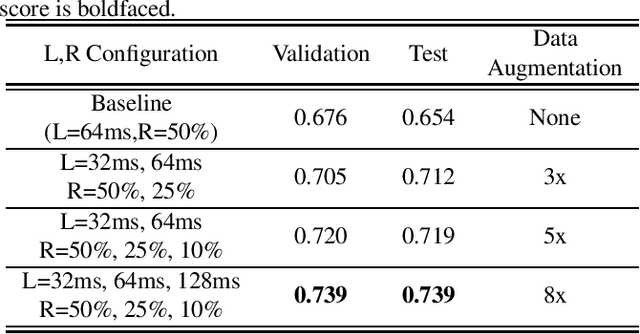
In this paper, a data augmentation method is proposed for depression detection from speech signals. Samples for data augmentation were created by changing the frame-width and the frame-shift parameters during the feature extraction process. Unlike other data augmentation methods (such as VTLP, pitch perturbation, or speed perturbation), the proposed method does not explicitly change acoustic parameters but rather the time-frequency resolution of frame-level features. The proposed method was evaluated using two different datasets, models, and input acoustic features. For the DAIC-WOZ (English) dataset when using the DepAudioNet model and mel-Spectrograms as input, the proposed method resulted in an improvement of 5.97% (validation) and 25.13% (test) when compared to the baseline. The improvements for the CONVERGE (Mandarin) dataset when using the x-vector embeddings with CNN as the backend and MFCCs as input features were 9.32% (validation) and 12.99% (test). Baseline systems do not incorporate any data augmentation. Further, the proposed method outperformed commonly used data-augmentation methods such as noise augmentation, VTLP, Speed, and Pitch Perturbation. All improvements were statistically significant.