 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSelf-Routing: Parameter-Free Expert Routing from Hidden States
Apr 01, 2026Mixture-of-Experts (MoE) layers increase model capacity by activating only a small subset of experts per token, and typically rely on a learned router to map hidden states to expert assignments. In this work, we ask whether a dedicated learned router is strictly necessary in the MoE settings we study. We propose Self-Routing, a parameter-free routing mechanism that uses a designated subspace of the token hidden state directly as expert logits, eliminating the router projection entirely while leaving the rest of the MoE layer unchanged. We evaluate Self-Routing on GPT-2-scale language modeling and ImageNet-1K classification by comparing it against a standard learned router, random-routing baselines, and dense non-MoE baselines. Our results show that Self-Routing remains competitive with the learned-router baseline while removing all dedicated routing parameters, and yields more balanced expert utilization, with about 17 % higher average normalized routing entropy and no explicit load-balancing loss. On ImageNet-1K with DeiT-S/16, Self-Routing also slightly improves over the corresponding learned-router MoE. These findings suggest that effective MoE routing can emerge from the hidden representation itself without requiring a separate learned router module.
Leveraging LLMs as Meta-Judges: A Multi-Agent Framework for Evaluating LLM Judgments
Apr 23, 2025Large language models (LLMs) are being widely applied across various fields, but as tasks become more complex, evaluating their responses is increasingly challenging. Compared to human evaluators, the use of LLMs to support performance evaluation offers a more efficient alternative. However, most studies focus mainly on aligning LLMs' judgments with human preferences, overlooking the existence of biases and mistakes in human judgment. Furthermore, how to select suitable LLM judgments given multiple potential LLM responses remains underexplored. To address these two aforementioned issues, we propose a three-stage meta-judge selection pipeline: 1) developing a comprehensive rubric with GPT-4 and human experts, 2) using three advanced LLM agents to score judgments, and 3) applying a threshold to filter out low-scoring judgments. Compared to methods using a single LLM as both judge and meta-judge, our pipeline introduces multi-agent collaboration and a more comprehensive rubric. Experimental results on the JudgeBench dataset show about 15.55\% improvement compared to raw judgments and about 8.37\% improvement over the single-agent baseline. Our work demonstrates the potential of LLMs as meta-judges and lays the foundation for future research on constructing preference datasets for LLM-as-a-judge reinforcement learning.
Towards Foundational Models for Molecular Learning on Large-Scale Multi-Task Datasets
Oct 18, 2023



Recently, pre-trained foundation models have enabled significant advancements in multiple fields. In molecular machine learning, however, where datasets are often hand-curated, and hence typically small, the lack of datasets with labeled features, and codebases to manage those datasets, has hindered the development of foundation models. In this work, we present seven novel datasets categorized by size into three distinct categories: ToyMix, LargeMix and UltraLarge. These datasets push the boundaries in both the scale and the diversity of supervised labels for molecular learning. They cover nearly 100 million molecules and over 3000 sparsely defined tasks, totaling more than 13 billion individual labels of both quantum and biological nature. In comparison, our datasets contain 300 times more data points than the widely used OGB-LSC PCQM4Mv2 dataset, and 13 times more than the quantum-only QM1B dataset. In addition, to support the development of foundational models based on our proposed datasets, we present the Graphium graph machine learning library which simplifies the process of building and training molecular machine learning models for multi-task and multi-level molecular datasets. Finally, we present a range of baseline results as a starting point of multi-task and multi-level training on these datasets. Empirically, we observe that performance on low-resource biological datasets show improvement by also training on large amounts of quantum data. This indicates that there may be potential in multi-task and multi-level training of a foundation model and fine-tuning it to resource-constrained downstream tasks.
Fast Development of ASR in African Languages using Self Supervised Speech Representation Learning
Mar 16, 2021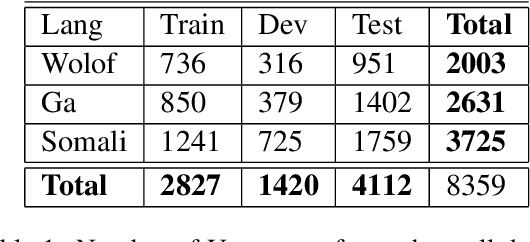
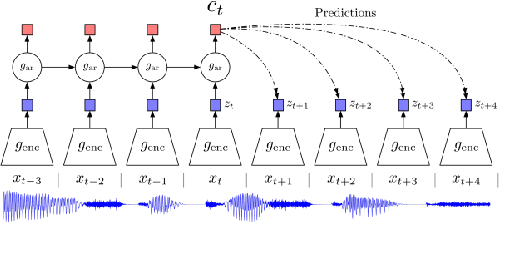
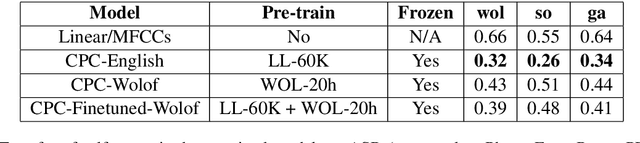
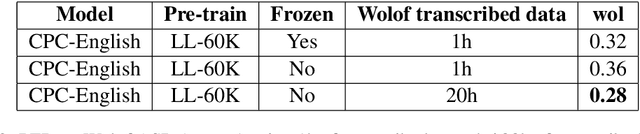
This paper describes the results of an informal collaboration launched during the African Master of Machine Intelligence (AMMI) in June 2020. After a series of lectures and labs on speech data collection using mobile applications and on self-supervised representation learning from speech, a small group of students and the lecturer continued working on automatic speech recognition (ASR) project for three languages: Wolof, Ga, and Somali. This paper describes how data was collected and ASR systems developed with a small amount (1h) of transcribed speech as training data. In these low resource conditions, pre-training a model on large amounts of raw speech was fundamental for the efficiency of ASR systems developed.