 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"speech": models, code, and papers
Fast-U2++: Fast and Accurate End-to-End Speech Recognition in Joint CTC/Attention Frames
Nov 02, 2022
Recently, the unified streaming and non-streaming two-pass (U2/U2++) end-to-end model for speech recognition has shown great performance in terms of streaming capability, accuracy and latency. In this paper, we present fast-U2++, an enhanced version of U2++ to further reduce partial latency. The core idea of fast-U2++ is to output partial results of the bottom layers in its encoder with a small chunk, while using a large chunk in the top layers of its encoder to compensate the performance degradation caused by the small chunk. Moreover, we use knowledge distillation method to reduce the token emission latency. We present extensive experiments on Aishell-1 dataset. Experiments and ablation studies show that compared to U2++, fast-U2++ reduces model latency from 320ms to 80ms, and achieves a character error rate (CER) of 5.06% with a streaming setup.
Detection of AI Synthesized Hindi Speech
Mar 07, 2022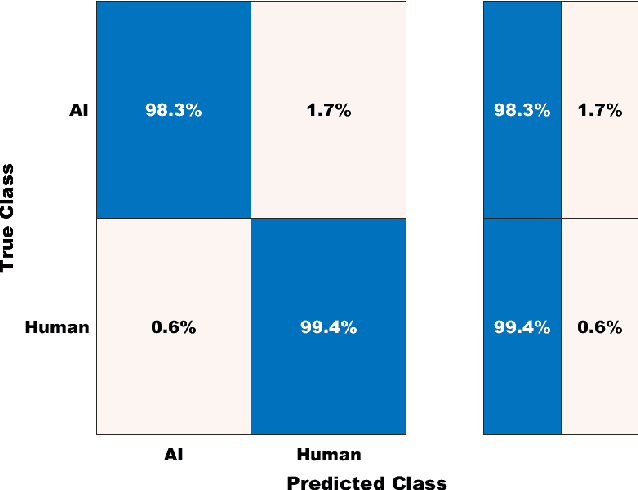
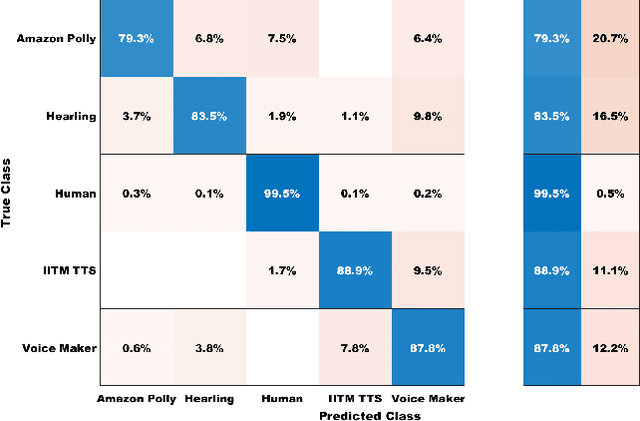
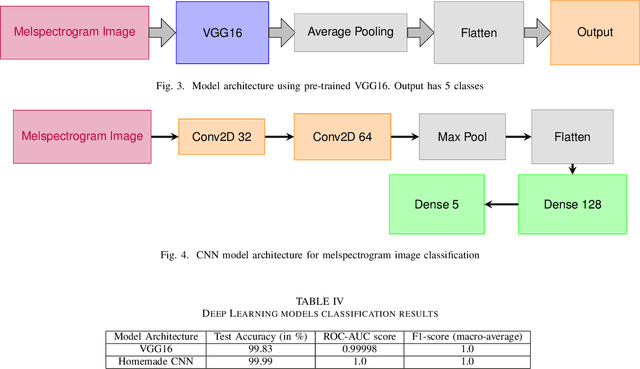
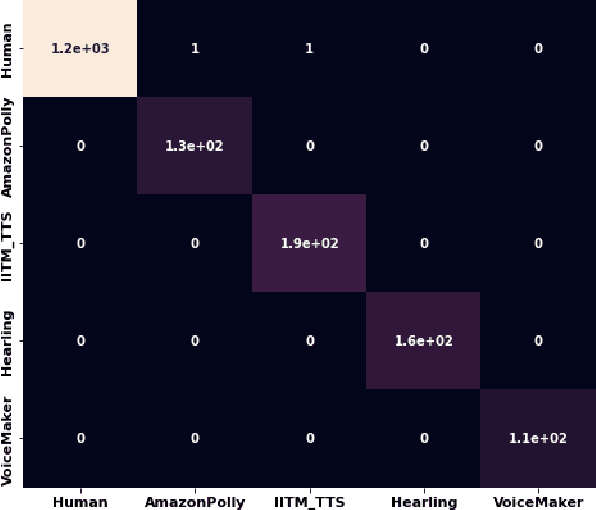
The recent advancements in generative artificial speech models have made possible the generation of highly realistic speech signals. At first, it seems exciting to obtain these artificially synthesized signals such as speech clones or deep fakes but if left unchecked, it may lead us to digital dystopia. One of the primary focus in audio forensics is validating the authenticity of a speech. Though some solutions are proposed for English speeches but the detection of synthetic Hindi speeches have not gained much attention. Here, we propose an approach for discrimination of AI synthesized Hindi speech from an actual human speech. We have exploited the Bicoherence Phase, Bicoherence Magnitude, Mel Frequency Cepstral Coefficient (MFCC), Delta Cepstral, and Delta Square Cepstral as the discriminating features for machine learning models. Also, we extend the study to using deep neural networks for extensive experiments, specifically VGG16 and homemade CNN as the architecture models. We obtained an accuracy of 99.83% with VGG16 and 99.99% with homemade CNN models.
FitHuBERT: Going Thinner and Deeper for Knowledge Distillation of Speech Self-Supervised Learning
Jul 01, 2022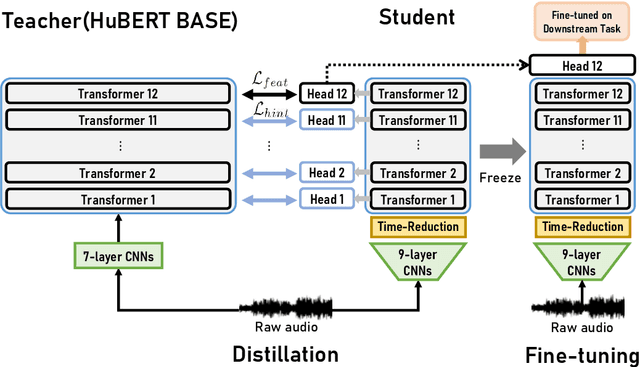
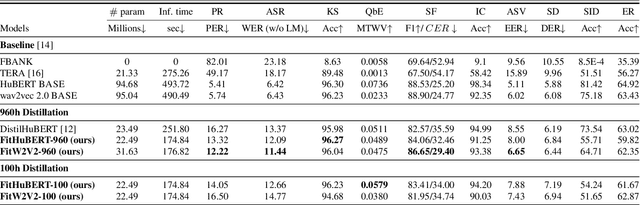
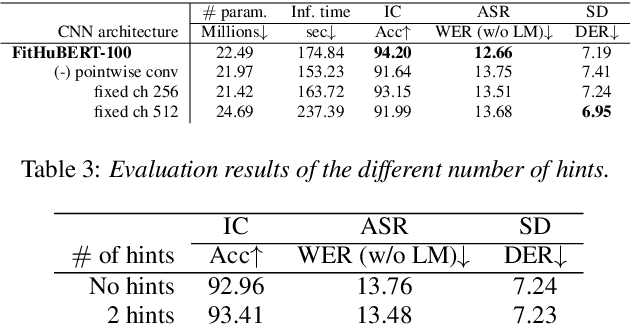

Large-scale speech self-supervised learning (SSL) has emerged to the main field of speech processing, however, the problem of computational cost arising from its vast size makes a high entry barrier to academia. In addition, existing distillation techniques of speech SSL models compress the model by reducing layers, which induces performance degradation in linguistic pattern recognition tasks such as phoneme recognition (PR). In this paper, we propose FitHuBERT, which makes thinner in dimension throughout almost all model components and deeper in layer compared to prior speech SSL distillation works. Moreover, we employ a time-reduction layer to speed up inference time and propose a method of hint-based distillation for less performance degradation. Our method reduces the model to 23.8% in size and 35.9% in inference time compared to HuBERT. Also, we achieve 12.1% word error rate and 13.3% phoneme error rate on the SUPERB benchmark which is superior than prior work.
Extending DNN-based Multiplicative Masking to Deep Subband Filtering for Improved Dereverberation
Mar 01, 2023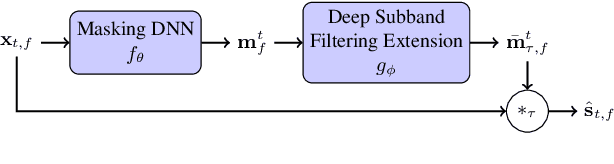
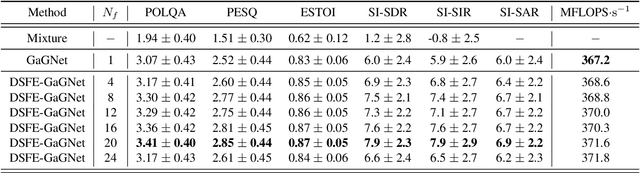
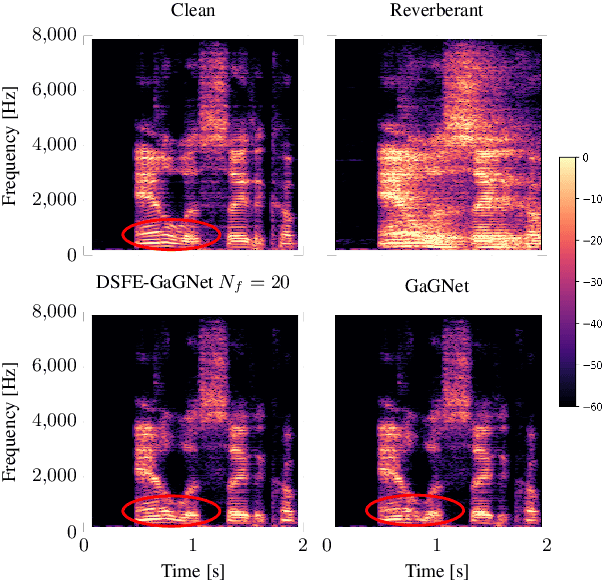
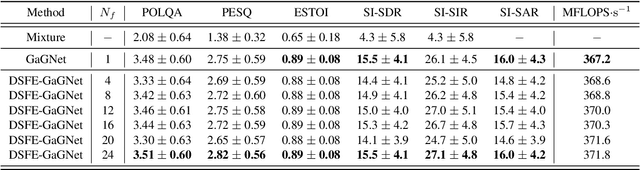
In this paper, we present a scheme for extending deep neural network-based multiplicative maskers to deep subband filters for speech restoration in the time-frequency domain. The resulting method can be generically applied to any deep neural network providing masks in the time-frequency domain, while requiring only few more trainable parameters and a computational overhead that is negligible for state-of-the-art neural networks. We demonstrate that the resulting deep subband filtering scheme outperforms multiplicative masking for dereverberation, while leaving the denoising performance virtually the same. We argue that this is because deep subband filtering in the time-frequency domain fits the subband approximation often assumed in the dereverberation literature, whereas multiplicative masking corresponds to the narrowband approximation generally employed in denoising.
Controlling High-Dimensional Data With Sparse Input
Mar 14, 2023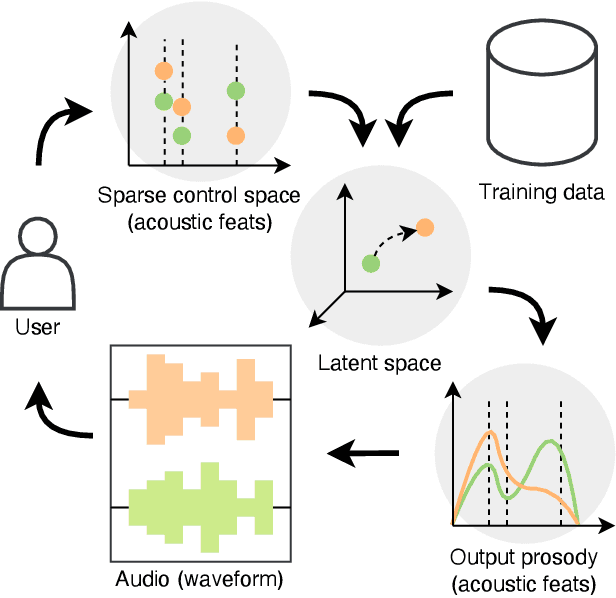
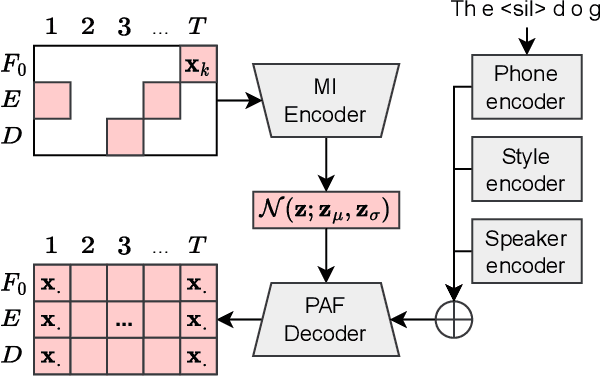
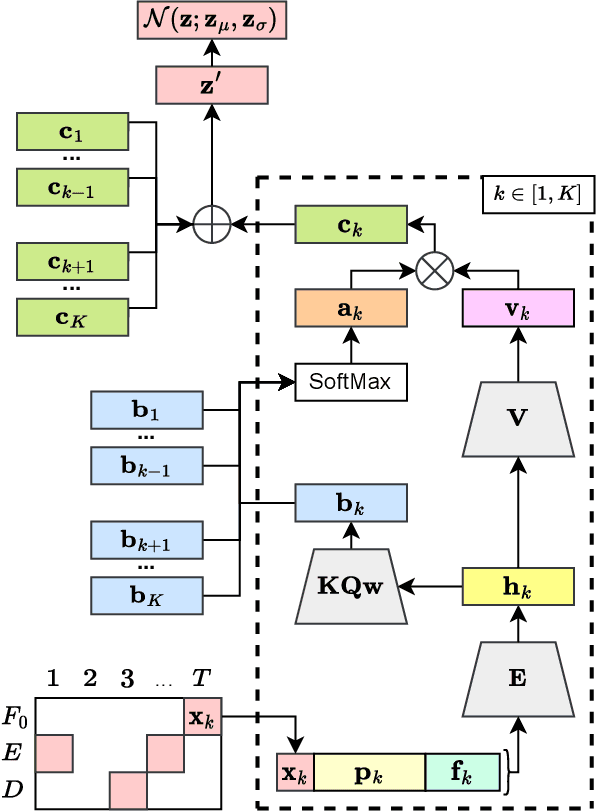
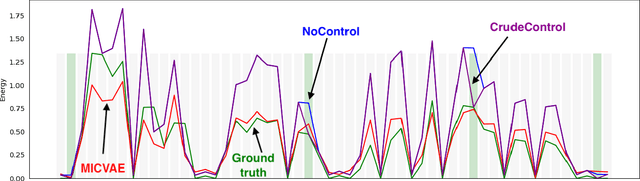
We address the problem of human-in-the-loop control for generating highly-structured data. This task is challenging because existing generative models lack an efficient interface through which users can modify the output. Users have the option to either manually explore a non-interpretable latent space, or to laboriously annotate the data with conditioning labels. To solve this, we introduce a novel framework whereby an encoder maps a sparse, human interpretable control space onto the latent space of a generative model. We apply this framework to the task of controlling prosody in text-to-speech synthesis. We propose a model, called Multiple-Instance CVAE (MICVAE), that is specifically designed to encode sparse prosodic features and output complete waveforms. We show empirically that MICVAE displays desirable qualities of a sparse human-in-the-loop control mechanism: efficiency, robustness, and faithfulness. With even a very small number of input values (~4), MICVAE enables users to improve the quality of the output significantly, in terms of listener preference (4:1).
GLD-Net: Improving Monaural Speech Enhancement by Learning Global and Local Dependency Features with GLD Block
Jun 30, 2022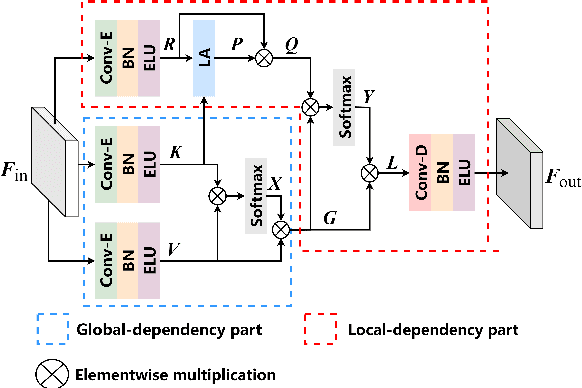
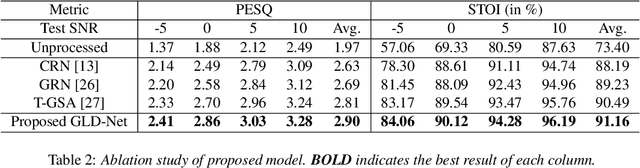
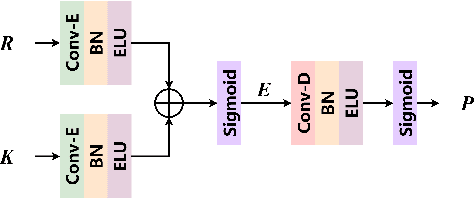

For monaural speech enhancement, contextual information is important for accurate speech estimation. However, commonly used convolution neural networks (CNNs) are weak in capturing temporal contexts since they only build blocks that process one local neighborhood at a time. To address this problem, we learn from human auditory perception to introduce a two-stage trainable reasoning mechanism, referred as global-local dependency (GLD) block. GLD blocks capture long-term dependency of time-frequency bins both in global level and local level from the noisy spectrogram to help detecting correlations among speech part, noise part, and whole noisy input. What is more, we conduct a monaural speech enhancement network called GLD-Net, which adopts encoder-decoder architecture and consists of speech object branch, interference branch, and global noisy branch. The extracted speech feature at global-level and local-level are efficiently reasoned and aggregated in each of the branches. We compare the proposed GLD-Net with existing state-of-art methods on WSJ0 and DEMAND dataset. The results show that GLD-Net outperforms the state-of-the-art methods in terms of PESQ and STOI.
Investigating Self-supervised Pretraining Frameworks for Pathological Speech Recognition
Mar 30, 2022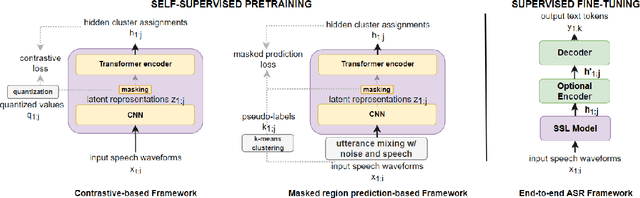
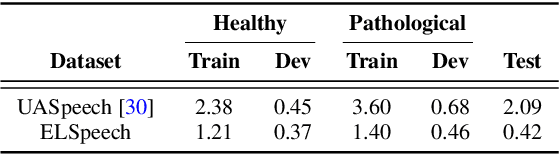
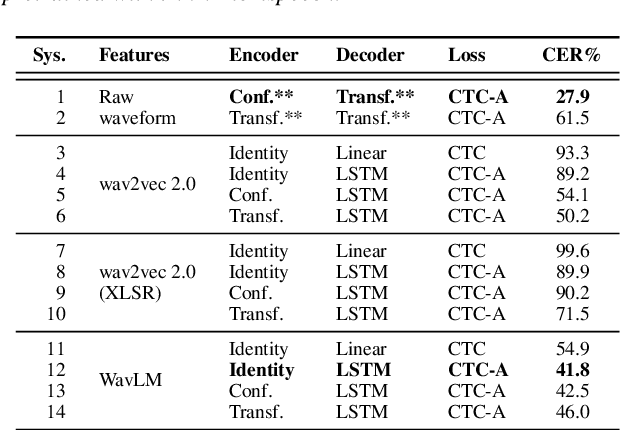
We investigate the performance of self-supervised pretraining frameworks on pathological speech datasets used for automatic speech recognition (ASR). Modern end-to-end models require thousands of hours of data to train well, but only a small number of pathological speech datasets are publicly available. A proven solution to this problem is by first pretraining the model on a huge number of healthy speech datasets and then fine-tuning it on the pathological speech datasets. One new pretraining framework called self-supervised learning (SSL) trains a network using only speech data, providing more flexibility in training data requirements and allowing more speech data to be used in pretraining. We investigate SSL frameworks such as the wav2vec 2.0 and WavLM models using different setups and compare their performance with different supervised pretraining setups, using two types of pathological speech, namely, Japanese electrolaryngeal and English dysarthric. Although the SSL setup is promising against Transformer-based supervised setups, other supervised setups such as the Conformer still outperform SSL pretraining. Our results show that the best supervised setup outperforms the best SSL setup by 13.9% character error rate in electrolaryngeal speech and 16.8% word error rate in dysarthric speech.
Unified Keyword Spotting and Audio Tagging on Mobile Devices with Transformers
Mar 03, 2023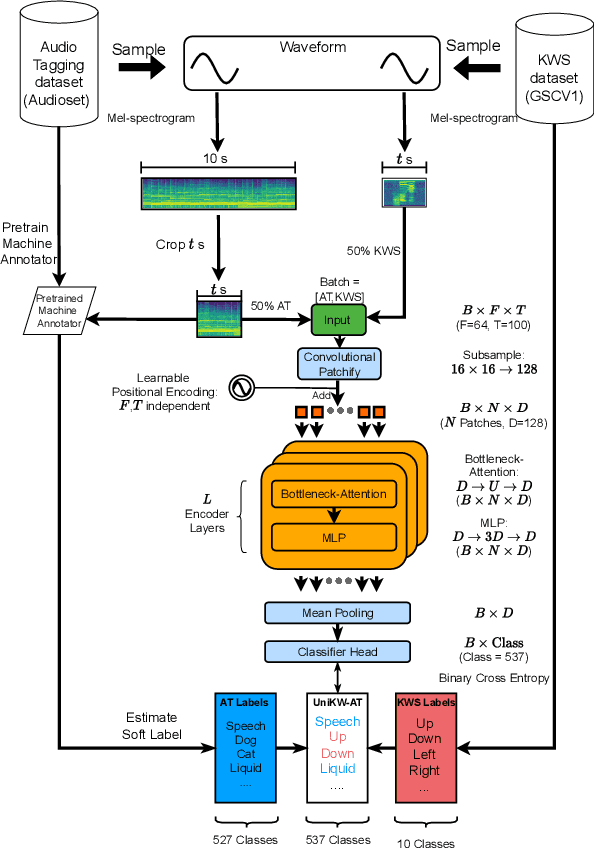
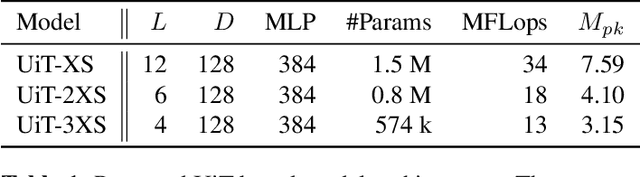
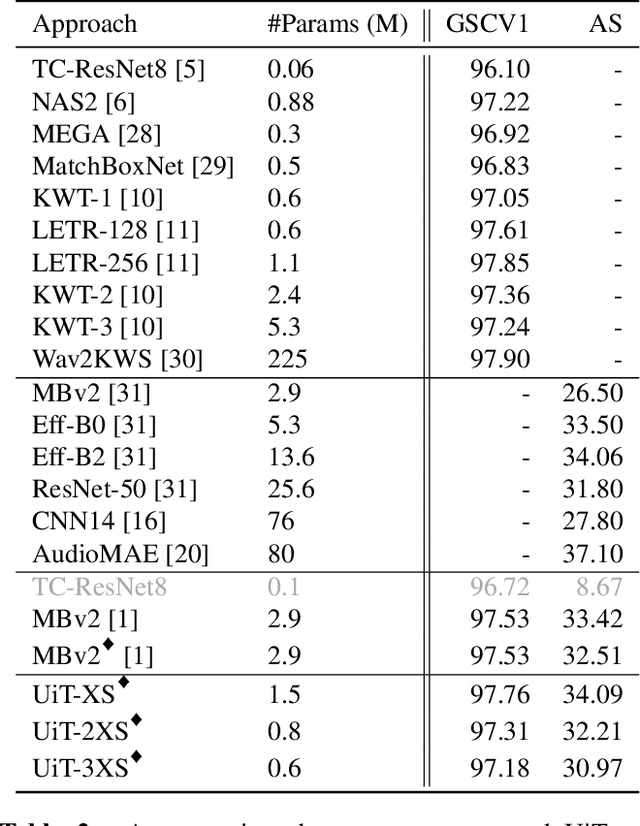
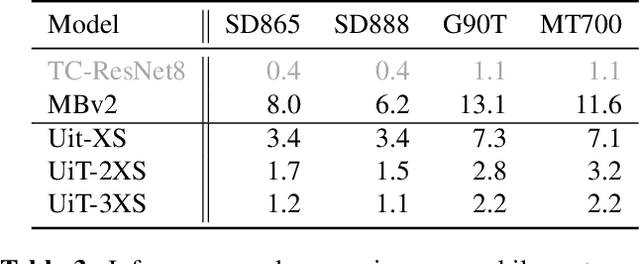
Keyword spotting (KWS) is a core human-machine-interaction front-end task for most modern intelligent assistants. Recently, a unified (UniKW-AT) framework has been proposed that adds additional capabilities in the form of audio tagging (AT) to a KWS model. However, previous work did not consider the real-world deployment of a UniKW-AT model, where factors such as model size and inference speed are more important than performance alone. This work introduces three mobile-device deployable models named Unified Transformers (UiT). Our best model achieves an mAP of 34.09 on Audioset, and an accuracy of 97.76 on the public Google Speech Commands V1 dataset. Further, we benchmark our proposed approaches on four mobile platforms, revealing that the proposed UiT models can achieve a speedup of 2 - 6 times against a competitive MobileNetV2.
Prosodic features improve sentence segmentation and parsing
Feb 23, 2023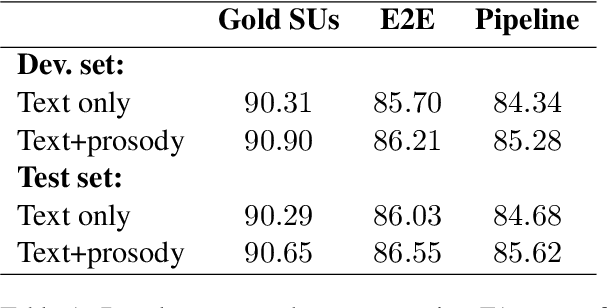
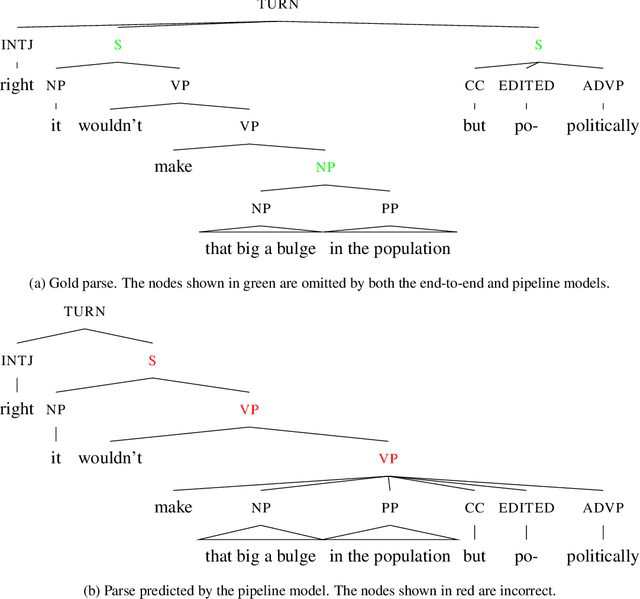
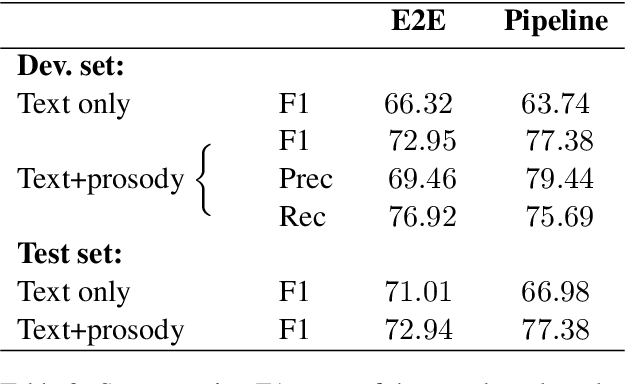
Parsing spoken dialogue presents challenges that parsing text does not, including a lack of clear sentence boundaries. We know from previous work that prosody helps in parsing single sentences (Tran et al. 2018), but we want to show the effect of prosody on parsing speech that isn't segmented into sentences. In experiments on the English Switchboard corpus, we find prosody helps our model both with parsing and with accurately identifying sentence boundaries. However, we find that the best-performing parser is not necessarily the parser that produces the best sentence segmentation performance. We suggest that the best parses instead come from modelling sentence boundaries jointly with other constituent boundaries.
Automatic Heteronym Resolution Pipeline Using RAD-TTS Aligners
Feb 28, 2023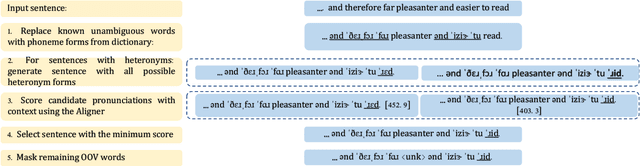


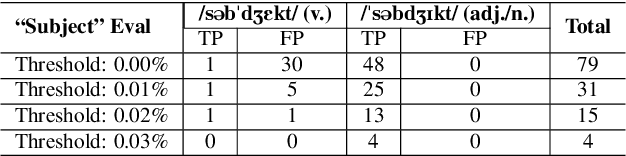
Grapheme-to-phoneme (G2P) transduction is part of the standard text-to-speech (TTS) pipeline. However, G2P conversion is difficult for languages that contain heteronyms -- words that have one spelling but can be pronounced in multiple ways. G2P datasets with annotated heteronyms are limited in size and expensive to create, as human labeling remains the primary method for heteronym disambiguation. We propose a RAD-TTS Aligner-based pipeline to automatically disambiguate heteronyms in datasets that contain both audio with text transcripts. The best pronunciation can be chosen by generating all possible candidates for each heteronym and scoring them with an Aligner model. The resulting labels can be used to create training datasets for use in both multi-stage and end-to-end G2P systems.