 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeD-SECURE: Dual-Source Evidence Combination for Unified Reasoning in Misinformation Detection
Feb 16, 2026Multimodal misinformation increasingly mixes realistic im-age edits with fluent but misleading text, producing persuasive posts that are difficult to verify. Existing systems usually rely on a single evidence source. Content-based detectors identify local inconsistencies within an image and its caption but cannot determine global factual truth. Retrieval-based fact-checkers reason over external evidence but treat inputs as coarse claims and often miss subtle visual or textual manipulations. This separation creates failure cases where internally consistent fabrications bypass manipulation detectors and fact-checkers verify claims that contain pixel-level or token-level corruption. We present D-SECURE, a framework that combines internal manipulation detection with external evidence-based reasoning for news-style posts. D-SECURE integrates the HAMMER manipulation detector with the DEFAME retrieval pipeline. DEFAME performs broad verification, and HAMMER analyses residual or uncertain cases that may contain fine-grained edits. Experiments on DGM4 and ClaimReview samples highlight the complementary strengths of both systems and motivate their fusion. We provide a unified, explainable report that incorporates manipulation cues and external evidence.
From Prediction to Explanation: Multimodal, Explainable, and Interactive Deepfake Detection Framework for Non-Expert Users
Aug 11, 2025The proliferation of deepfake technologies poses urgent challenges and serious risks to digital integrity, particularly within critical sectors such as forensics, journalism, and the legal system. While existing detection systems have made significant progress in classification accuracy, they typically function as black-box models, offering limited transparency and minimal support for human reasoning. This lack of interpretability hinders their usability in real-world decision-making contexts, especially for non-expert users. In this paper, we present DF-P2E (Deepfake: Prediction to Explanation), a novel multimodal framework that integrates visual, semantic, and narrative layers of explanation to make deepfake detection interpretable and accessible. The framework consists of three modular components: (1) a deepfake classifier with Grad-CAM-based saliency visualisation, (2) a visual captioning module that generates natural language summaries of manipulated regions, and (3) a narrative refinement module that uses a fine-tuned Large Language Model (LLM) to produce context-aware, user-sensitive explanations. We instantiate and evaluate the framework on the DF40 benchmark, the most diverse deepfake dataset to date. Experiments demonstrate that our system achieves competitive detection performance while providing high-quality explanations aligned with Grad-CAM activations. By unifying prediction and explanation in a coherent, human-aligned pipeline, this work offers a scalable approach to interpretable deepfake detection, advancing the broader vision of trustworthy and transparent AI systems in adversarial media environments.
Random Client Selection on Contrastive Federated Learning for Tabular Data
May 16, 2025



Vertical Federated Learning (VFL) has revolutionised collaborative machine learning by enabling privacy-preserving model training across multiple parties. However, it remains vulnerable to information leakage during intermediate computation sharing. While Contrastive Federated Learning (CFL) was introduced to mitigate these privacy concerns through representation learning, it still faces challenges from gradient-based attacks. This paper presents a comprehensive experimental analysis of gradient-based attacks in CFL environments and evaluates random client selection as a defensive strategy. Through extensive experimentation, we demonstrate that random client selection proves particularly effective in defending against gradient attacks in the CFL network. Our findings provide valuable insights for implementing robust security measures in contrastive federated learning systems, contributing to the development of more secure collaborative learning frameworks
Continual Contrastive Learning on Tabular Data with Out of Distribution
Mar 19, 2025Out-of-distribution (OOD) prediction remains a significant challenge in machine learning, particularly for tabular data where traditional methods often fail to generalize beyond their training distribution. This paper introduces Tabular Continual Contrastive Learning (TCCL), a novel framework designed to address OOD challenges in tabular data processing. TCCL integrates contrastive learning principles with continual learning mechanisms, featuring a three-component architecture: an Encoder for data transformation, a Decoder for representation learning, and a Learner Head. We evaluate TCCL against 14 baseline models, including state-of-the-art deep learning approaches and gradient-boosted decision trees (GBDT), across eight diverse tabular datasets. Our experimental results demonstrate that TCCL consistently outperforms existing methods in both classification and regression tasks on OOD data, with particular strength in handling distribution shifts. These findings suggest that TCCL represents a significant advancement in handling OOD scenarios for tabular data.
Towards Explainable Network Intrusion Detection using Large Language Models
Aug 08, 2024



Large Language Models (LLMs) have revolutionised natural language processing tasks, particularly as chat agents. However, their applicability to threat detection problems remains unclear. This paper examines the feasibility of employing LLMs as a Network Intrusion Detection System (NIDS), despite their high computational requirements, primarily for the sake of explainability. Furthermore, considerable resources have been invested in developing LLMs, and they may offer utility for NIDS. Current state-of-the-art NIDS rely on artificial benchmarking datasets, resulting in skewed performance when applied to real-world networking environments. Therefore, we compare the GPT-4 and LLama3 models against traditional architectures and transformer-based models to assess their ability to detect malicious NetFlows without depending on artificially skewed datasets, but solely on their vast pre-trained acquired knowledge. Our results reveal that, although LLMs struggle with precise attack detection, they hold significant potential for a path towards explainable NIDS. Our preliminary exploration shows that LLMs are unfit for the detection of Malicious NetFlows. Most promisingly, however, these exhibit significant potential as complementary agents in NIDS, particularly in providing explanations and aiding in threat response when integrated with Retrieval Augmented Generation (RAG) and function calling capabilities.
Detection of AI Synthesized Hindi Speech
Mar 07, 2022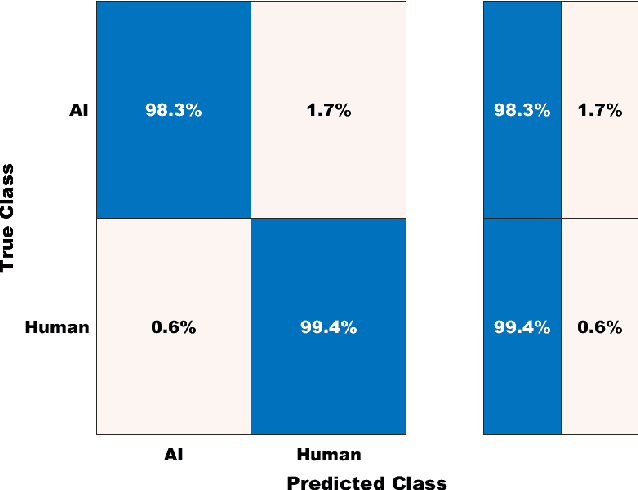
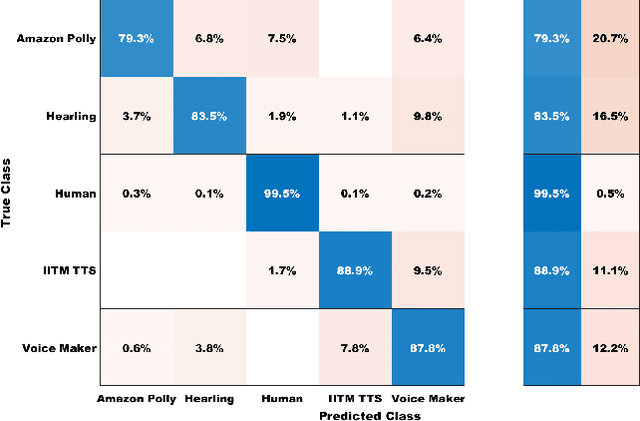
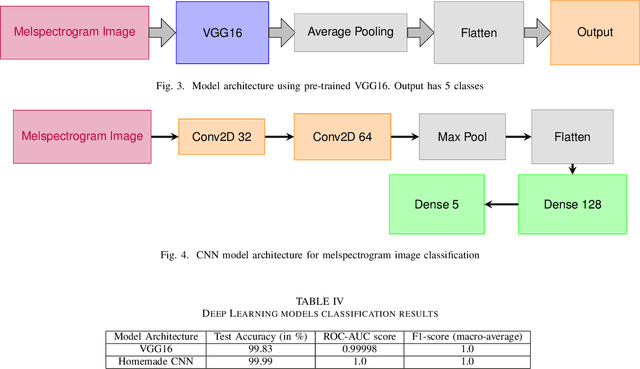
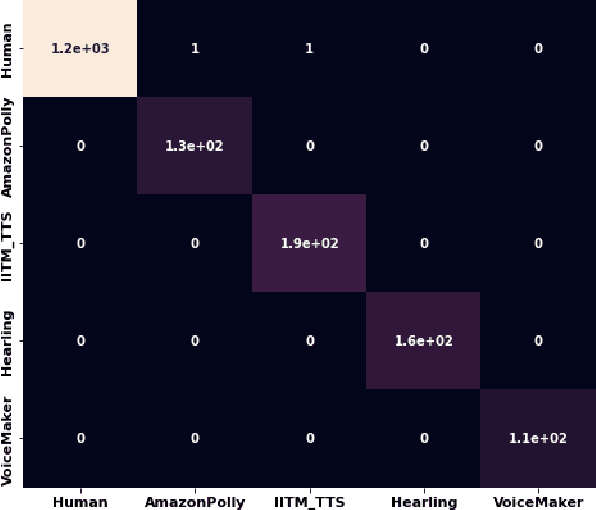
The recent advancements in generative artificial speech models have made possible the generation of highly realistic speech signals. At first, it seems exciting to obtain these artificially synthesized signals such as speech clones or deep fakes but if left unchecked, it may lead us to digital dystopia. One of the primary focus in audio forensics is validating the authenticity of a speech. Though some solutions are proposed for English speeches but the detection of synthetic Hindi speeches have not gained much attention. Here, we propose an approach for discrimination of AI synthesized Hindi speech from an actual human speech. We have exploited the Bicoherence Phase, Bicoherence Magnitude, Mel Frequency Cepstral Coefficient (MFCC), Delta Cepstral, and Delta Square Cepstral as the discriminating features for machine learning models. Also, we extend the study to using deep neural networks for extensive experiments, specifically VGG16 and homemade CNN as the architecture models. We obtained an accuracy of 99.83% with VGG16 and 99.99% with homemade CNN models.
Using Deep Learning Techniques and Inferential Speech Statistics for AI Synthesised Speech Recognition
Jul 23, 2021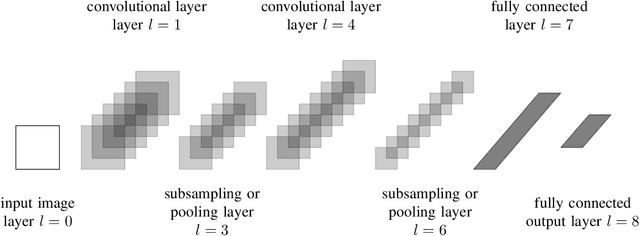
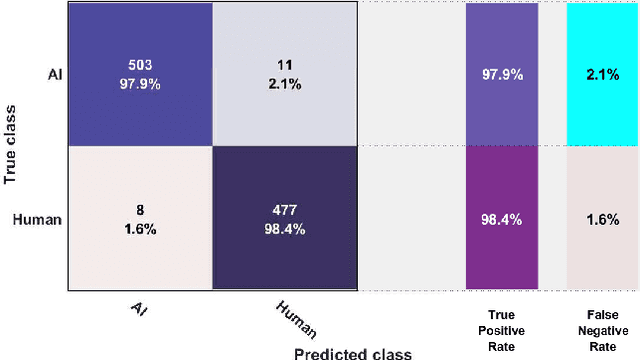
The recent developments in technology have re-warded us with amazing audio synthesis models like TACOTRON and WAVENETS. On the other side, it poses greater threats such as speech clones and deep fakes, that may go undetected. To tackle these alarming situations, there is an urgent need to propose models that can help discriminate a synthesized speech from an actual human speech and also identify the source of such a synthesis. Here, we propose a model based on Convolutional Neural Network (CNN) and Bidirectional Recurrent Neural Network (BiRNN) that helps to achieve both the aforementioned objectives. The temporal dependencies present in AI synthesized speech are exploited using Bidirectional RNN and CNN. The model outperforms the state-of-the-art approaches by classifying the AI synthesized audio from real human speech with an error rate of 1.9% and detecting the underlying architecture with an accuracy of 97%.
Explainable AI: current status and future directions
Jul 12, 2021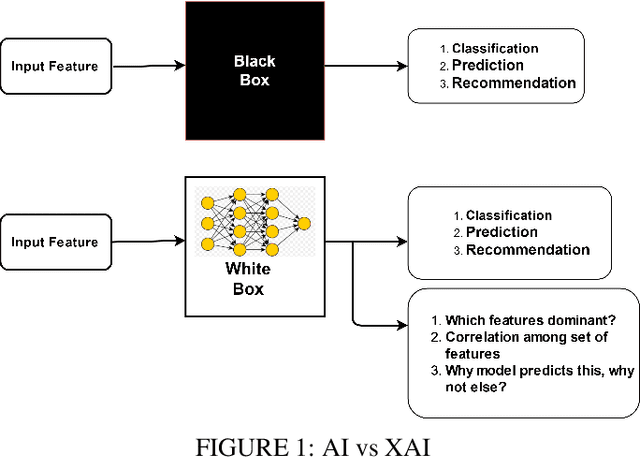
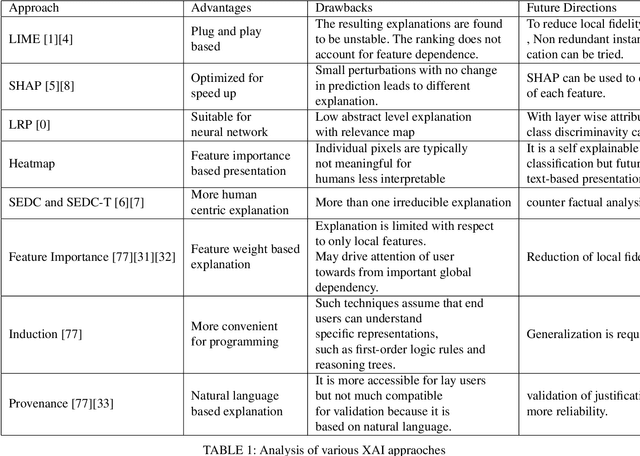
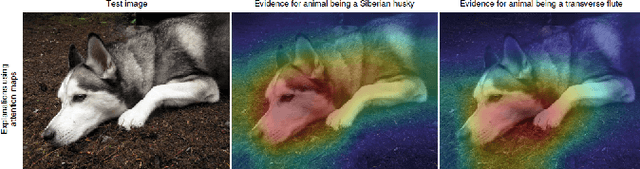

Explainable Artificial Intelligence (XAI) is an emerging area of research in the field of Artificial Intelligence (AI). XAI can explain how AI obtained a particular solution (e.g., classification or object detection) and can also answer other "wh" questions. This explainability is not possible in traditional AI. Explainability is essential for critical applications, such as defense, health care, law and order, and autonomous driving vehicles, etc, where the know-how is required for trust and transparency. A number of XAI techniques so far have been purposed for such applications. This paper provides an overview of these techniques from a multimedia (i.e., text, image, audio, and video) point of view. The advantages and shortcomings of these techniques have been discussed, and pointers to some future directions have also been provided.
Detection of AI-Synthesized Speech Using Cepstral & Bispectral Statistics
Sep 03, 2020
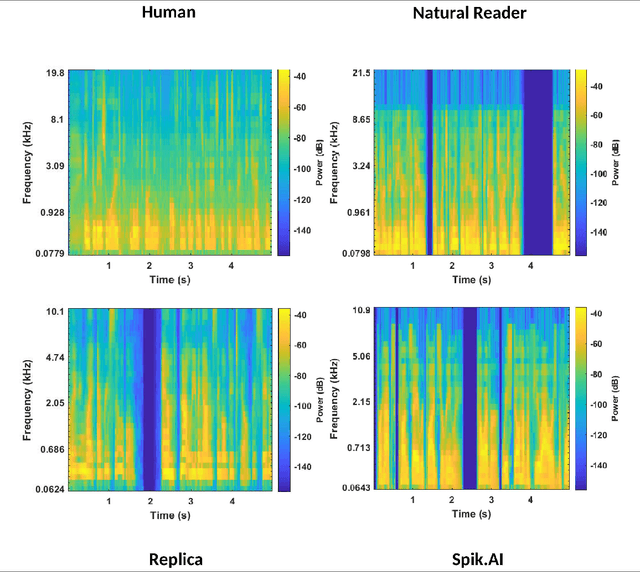
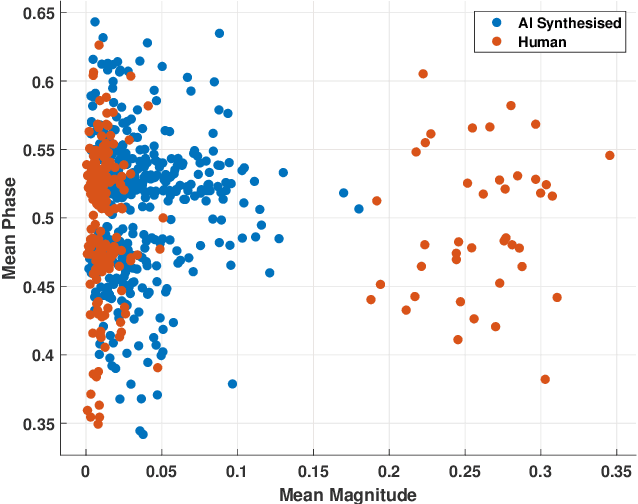
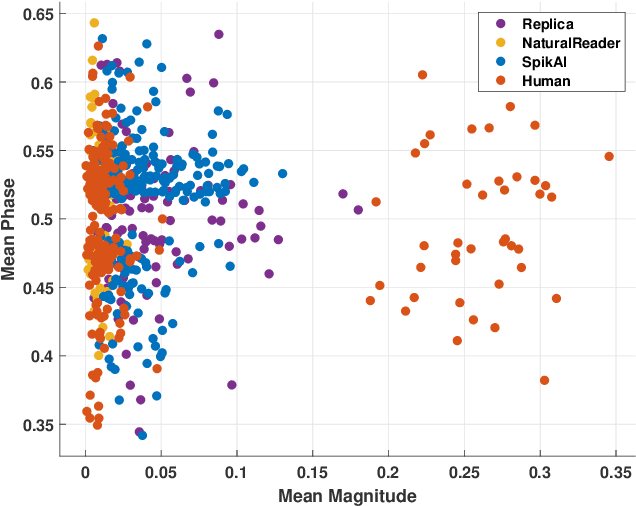
Digital technology has made possible unimaginable applications come true. It seems exciting to have a handful of tools for easy editing and manipulation, but it raises alarming concerns that can propagate as speech clones, duplicates, or maybe deep fakes. Validating the authenticity of a speech is one of the primary problems of digital audio forensics. We propose an approach to distinguish human speech from AI synthesized speech exploiting the Bi-spectral and Cepstral analysis. Higher-order statistics have less correlation for human speech in comparison to a synthesized speech. Also, Cepstral analysis revealed a durable power component in human speech that is missing for a synthesized speech. We integrate both these analyses and propose a machine learning model to detect AI synthesized speech.