 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTriage knowledge distillation for speaker verification
Jan 21, 2026Deploying speaker verification on resource-constrained devices remains challenging due to the computational cost of high-capacity models; knowledge distillation (KD) offers a remedy. Classical KD entangles target confidence with non-target structure in a Kullback-Leibler term, limiting the transfer of relational information. Decoupled KD separates these signals into target and non-target terms, yet treats non-targets uniformly and remains vulnerable to the long tail of low-probability classes in large-class settings. We introduce Triage KD (TRKD), a distillation scheme that operationalizes assess-prioritize-focus. TRKD introduces a cumulative-probability cutoff $τ$ to assess per-example difficulty and partition the teacher posterior into three groups: the target class, a high-probability non-target confusion-set, and a background-set. To prioritize informative signals, TRKD distills the confusion-set conditional distribution and discards the background. Concurrently, it transfers a three-mass (target/confusion/background) that capture sample difficulty and inter-class confusion. Finally, TRKD focuses learning via a curriculum on $τ$: training begins with a larger $τ$ to convey broad non-target context, then $τ$ is progressively decreased to shrink the confusion-set, concentrating supervision on the most confusable classes. In extensive experiments on VoxCeleb1 with both homogeneous and heterogeneous teacher-student pairs, TRKD was consistently superior to recent KD variants and attained the lowest EER across all protocols.
MATE: Matryoshka Audio-Text Embeddings for Open-Vocabulary Keyword Spotting
Jan 20, 2026Open-vocabulary keyword spotting (KWS) with text-based enrollment has emerged as a flexible alternative to fixed-phrase triggers. Prior utterance-level matching methods, from an embedding-learning standpoint, learn embeddings at a single fixed dimensionality. We depart from this design and propose Matryoshka Audio-Text Embeddings (MATE), a dual-encoder framework that encodes multiple embedding granularities within a single vector via nested sub-embeddings ("prefixes"). Specifically, we introduce a PCA-guided prefix alignment: PCA-compressed versions of the full text embedding for each prefix size serve as teacher targets to align both audio and text prefixes. This alignment concentrates salient keyword cues in lower-dimensional prefixes, while higher dimensions add detail. MATE is trained with standard deep metric learning objectives for audio-text KWS, and is loss-agnostic. To our knowledge, this is the first application of matryoshka-style embeddings to KWS, achieving state-of-the-art results on WSJ and LibriPhrase without any inference overhead.
DAME: Duration-Aware Matryoshka Embedding for Duration-Robust Speaker Verification
Jan 20, 2026Short-utterance speaker verification remains challenging due to limited speaker-discriminative cues in short speech segments. While existing methods focus on enhancing speaker encoders, the embedding learning strategy still forces a single fixed-dimensional representation reused for utterances of any length, leaving capacity misaligned with the information available at different durations. We propose Duration-Aware Matryoshka Embedding (DAME), a model-agnostic framework that builds a nested hierarchy of sub-embeddings aligned to utterance durations: lower-dimensional representations capture compact speaker traits from short utterances, while higher dimensions encode richer details from longer speech. DAME supports both training from scratch and fine-tuning, and serves as a direct alternative to conventional large-margin fine-tuning, consistently improving performance across durations. On the VoxCeleb1-O/E/H and VOiCES evaluation sets, DAME consistently reduces the equal error rate on 1-s and other short-duration trials, while maintaining full-length performance with no additional inference cost. These gains generalize across various speaker encoder architectures under both general training and fine-tuning setups.
Adversarial Deep Metric Learning for Cross-Modal Audio-Text Alignment in Open-Vocabulary Keyword Spotting
May 22, 2025



For text enrollment-based open-vocabulary keyword spotting (KWS), acoustic and text embeddings are typically compared at either the phoneme or utterance level. To facilitate this, we optimize acoustic and text encoders using deep metric learning (DML), enabling direct comparison of multi-modal embeddings in a shared embedding space. However, the inherent heterogeneity between audio and text modalities presents a significant challenge. To address this, we propose Modality Adversarial Learning (MAL), which reduces the domain gap in heterogeneous modality representations. Specifically, we train a modality classifier adversarially to encourage both encoders to generate modality-invariant embeddings. Additionally, we apply DML to achieve phoneme-level alignment between audio and text, and conduct comprehensive comparisons across various DML objectives. Experiments on the Wall Street Journal (WSJ) and LibriPhrase datasets demonstrate the effectiveness of the proposed approach.
Text-Aware Adapter for Few-Shot Keyword Spotting
Dec 24, 2024



Recent advances in flexible keyword spotting (KWS) with text enrollment allow users to personalize keywords without uttering them during enrollment. However, there is still room for improvement in target keyword performance. In this work, we propose a novel few-shot transfer learning method, called text-aware adapter (TA-adapter), designed to enhance a pre-trained flexible KWS model for specific keywords with limited speech samples. To adapt the acoustic encoder, we leverage a jointly pre-trained text encoder to generate a text embedding that acts as a representative vector for the keyword. By fine-tuning only a small portion of the network while keeping the core components' weights intact, the TA-adapter proves highly efficient for few-shot KWS, enabling a seamless return to the original pre-trained model. In our experiments, the TA-adapter demonstrated significant performance improvements across 35 distinct keywords from the Google Speech Commands V2 dataset, with only a 0.14% increase in the total number of parameters.
CTC-aligned Audio-Text Embedding for Streaming Open-vocabulary Keyword Spotting
Jun 12, 2024This paper introduces a novel approach for streaming openvocabulary keyword spotting (KWS) with text-based keyword enrollment. For every input frame, the proposed method finds the optimal alignment ending at the frame using connectionist temporal classification (CTC) and aggregates the frame-level acoustic embedding (AE) to obtain higher-level (i.e., character, word, or phrase) AE that aligns with the text embedding (TE) of the target keyword text. After that, we calculate the similarity of the aggregated AE and the TE. To the best of our knowledge, this is the first attempt to dynamically align the audio and the keyword text on-the-fly to attain the joint audio-text embedding for KWS. Despite operating in a streaming fashion, our approach achieves competitive performance on the LibriPhrase dataset compared to the non-streaming methods with a mere 155K model parameters and a decoding algorithm with time complexity O(U), where U is the length of the target keyword at inference time.
Relational Proxy Loss for Audio-Text based Keyword Spotting
Jun 08, 2024



In recent years, there has been an increasing focus on user convenience, leading to increased interest in text-based keyword enrollment systems for keyword spotting (KWS). Since the system utilizes text input during the enrollment phase and audio input during actual usage, we call this task audio-text based KWS. To enable this task, both acoustic and text encoders are typically trained using deep metric learning loss functions, such as triplet- and proxy-based losses. This study aims to improve existing methods by leveraging the structural relations within acoustic embeddings and within text embeddings. Unlike previous studies that only compare acoustic and text embeddings on a point-to-point basis, our approach focuses on the relational structures within the embedding space by introducing the concept of Relational Proxy Loss (RPL). By incorporating RPL, we demonstrated improved performance on the Wall Street Journal (WSJ) corpus.
FitHuBERT: Going Thinner and Deeper for Knowledge Distillation of Speech Self-Supervised Learning
Jul 01, 2022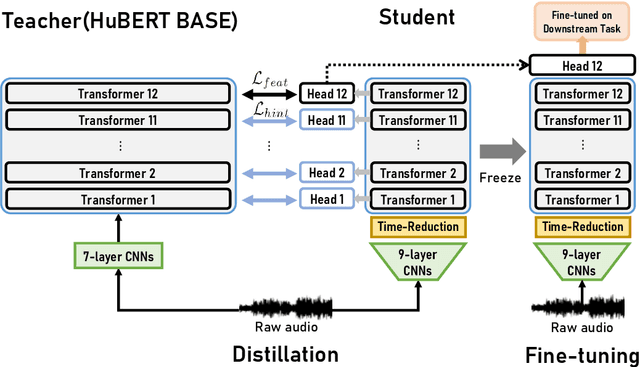
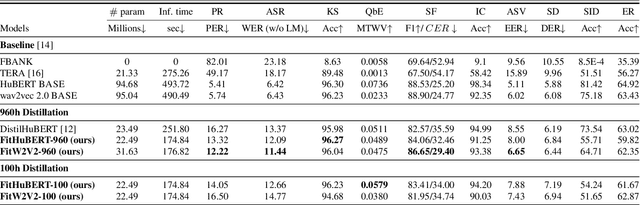
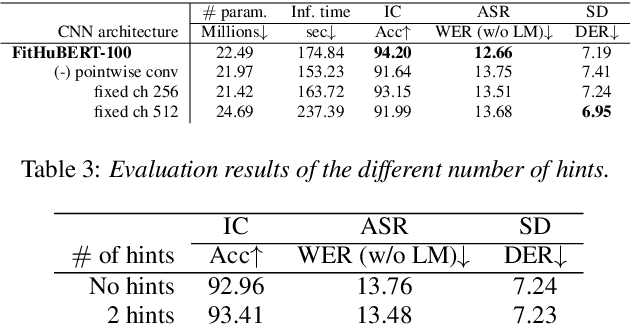

Large-scale speech self-supervised learning (SSL) has emerged to the main field of speech processing, however, the problem of computational cost arising from its vast size makes a high entry barrier to academia. In addition, existing distillation techniques of speech SSL models compress the model by reducing layers, which induces performance degradation in linguistic pattern recognition tasks such as phoneme recognition (PR). In this paper, we propose FitHuBERT, which makes thinner in dimension throughout almost all model components and deeper in layer compared to prior speech SSL distillation works. Moreover, we employ a time-reduction layer to speed up inference time and propose a method of hint-based distillation for less performance degradation. Our method reduces the model to 23.8% in size and 35.9% in inference time compared to HuBERT. Also, we achieve 12.1% word error rate and 13.3% phoneme error rate on the SUPERB benchmark which is superior than prior work.
Perceptually Guided End-to-End Text-to-Speech
Nov 02, 2020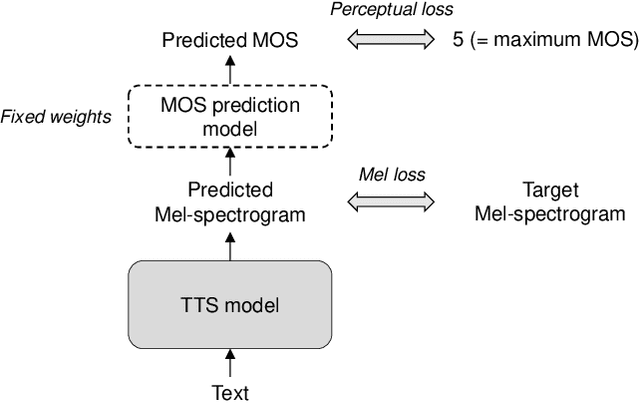
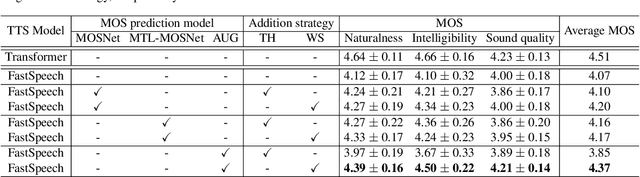
Several fast text-to-speech (TTS) models have been proposed for real-time processing, but there is room for improvement in speech quality. Meanwhile, there is a mismatch between the loss function for training and the mean opinion score (MOS) for evaluation, which may limit the speech quality of TTS models. In this work, we propose a method that can improve the speech quality of a fast TTS model while maintaining the inference speed. To do so, we train a TTS model using a perceptual loss based on the predicted MOS. Under the supervision of a MOS prediction model, a TTS model can learn to increase the perceptual quality of speech directly. In experiments, we train FastSpeech on our internal Korean dataset using the MOS prediction model pre-trained on the Voice Conversion Challenge 2018 evaluation results. The MOS test results show that our proposed approach outperforms FastSpeech in speech quality.
A Unified Deep Learning Framework for Short-Duration Speaker Verification in Adverse Environments
Oct 06, 2020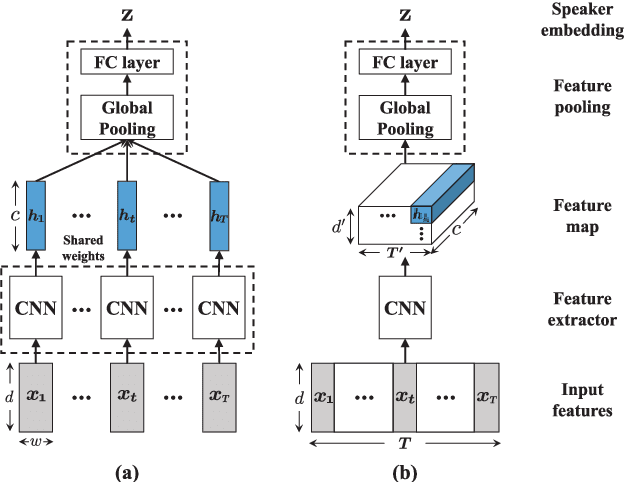
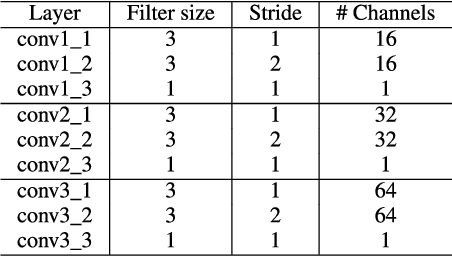
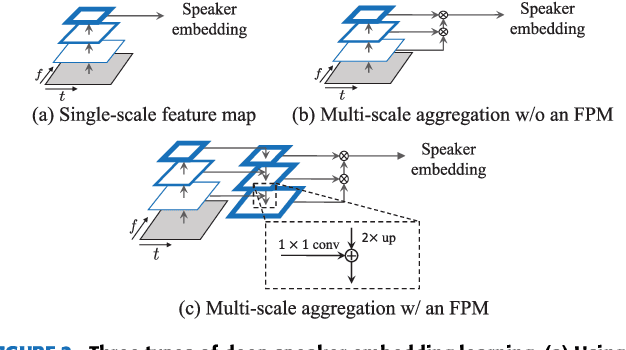
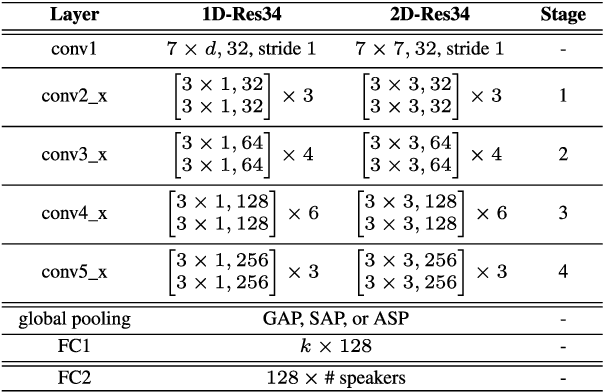
Speaker verification (SV) has recently attracted considerable research interest due to the growing popularity of virtual assistants. At the same time, there is an increasing requirement for an SV system: it should be robust to short speech segments, especially in noisy and reverberant environments. In this paper, we consider one more important requirement for practical applications: the system should be robust to an audio stream containing long non-speech segments, where a voice activity detection (VAD) is not applied. To meet these two requirements, we introduce feature pyramid module (FPM)-based multi-scale aggregation (MSA) and self-adaptive soft VAD (SAS-VAD). We present the FPM-based MSA to deal with short speech segments in noisy and reverberant environments. Also, we use the SAS-VAD to increase the robustness to long non-speech segments. To further improve the robustness to acoustic distortions (i.e., noise and reverberation), we apply a masking-based speech enhancement (SE) method. We combine SV, VAD, and SE models in a unified deep learning framework and jointly train the entire network in an end-to-end manner. To the best of our knowledge, this is the first work combining these three models in a deep learning framework. We conduct experiments on Korean indoor (KID) and VoxCeleb datasets, which are corrupted by noise and reverberation. The results show that the proposed method is effective for SV in the challenging conditions and performs better than the baseline i-vector and deep speaker embedding systems.
* 19 pages, 10 figures, 13 tables