 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"speech": models, code, and papers
Automatic Speech Recognition of Low-Resource Languages Based on Chukchi
Oct 11, 2022

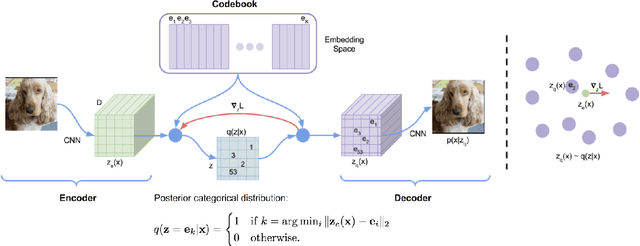
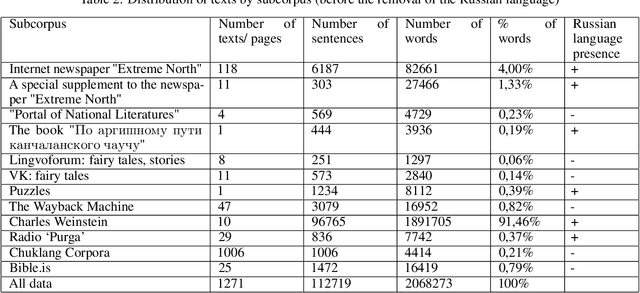
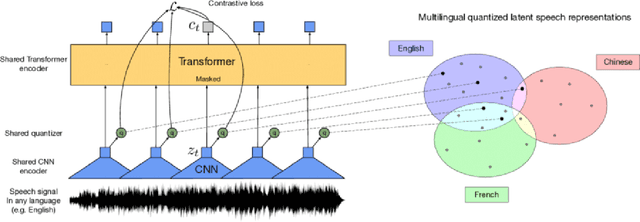
The following paper presents a project focused on the research and creation of a new Automatic Speech Recognition (ASR) based in the Chukchi language. There is no one complete corpus of the Chukchi language, so most of the work consisted in collecting audio and texts in the Chukchi language from open sources and processing them. We managed to collect 21:34:23 hours of audio recordings and 112,719 sentences (or 2,068,273 words) of text in the Chukchi language. The XLSR model was trained on the obtained data, which showed good results even with a small amount of data. Besides the fact that the Chukchi language is a low-resource language, it is also polysynthetic, which significantly complicates any automatic processing. Thus, the usual WER metric for evaluating ASR becomes less indicative for a polysynthetic language. However, the CER metric showed good results. The question of metrics for polysynthetic languages remains open.
Visually Grounded Keyword Detection and Localisation for Low-Resource Languages
Feb 01, 2023
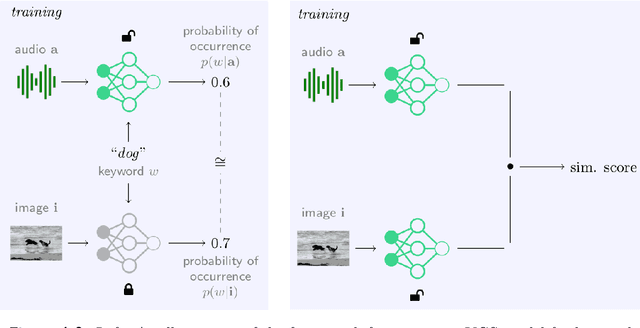
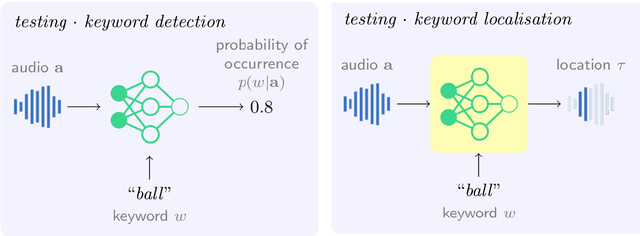
This study investigates the use of Visually Grounded Speech (VGS) models for keyword localisation in speech. The study focusses on two main research questions: (1) Is keyword localisation possible with VGS models and (2) Can keyword localisation be done cross-lingually in a real low-resource setting? Four methods for localisation are proposed and evaluated on an English dataset, with the best-performing method achieving an accuracy of 57%. A new dataset containing spoken captions in Yoruba language is also collected and released for cross-lingual keyword localisation. The cross-lingual model obtains a precision of 16% in actual keyword localisation and this performance can be improved by initialising from a model pretrained on English data. The study presents a detailed analysis of the model's success and failure modes and highlights the challenges of using VGS models for keyword localisation in low-resource settings.
Personalized Adversarial Data Augmentation for Dysarthric and Elderly Speech Recognition
May 13, 2022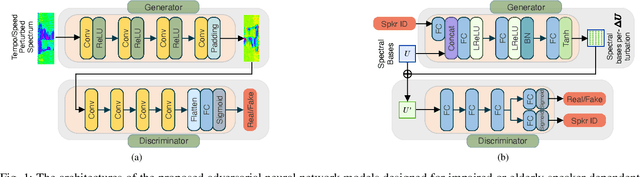
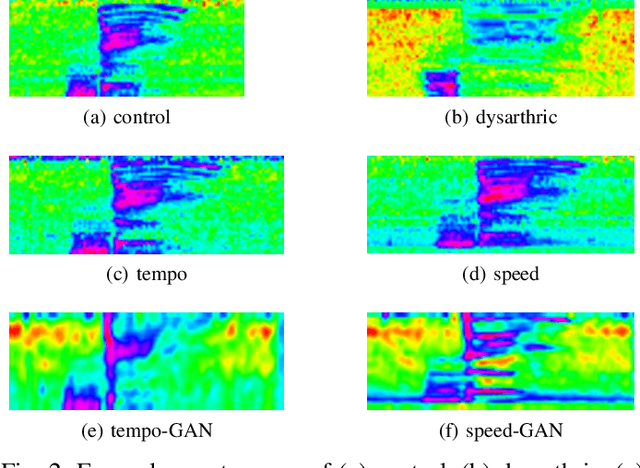
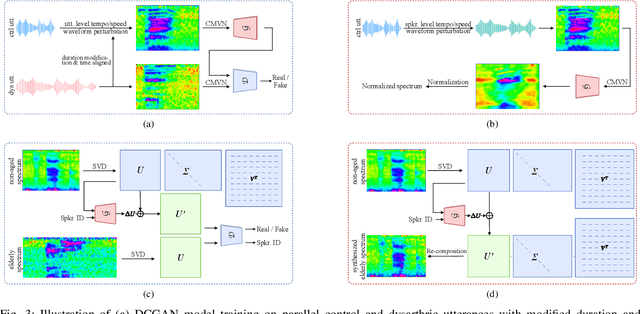
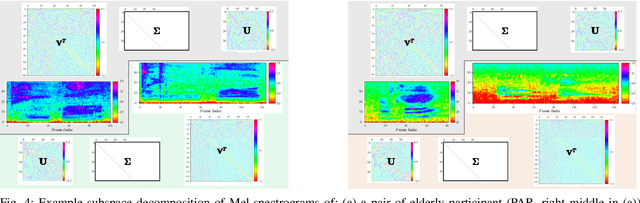
Despite the rapid progress of automatic speech recognition (ASR) technologies targeting normal speech, accurate recognition of dysarthric and elderly speech remains highly challenging tasks to date. It is difficult to collect large quantities of such data for ASR system development due to the mobility issues often found among these users. To this end, data augmentation techniques play a vital role. In contrast to existing data augmentation techniques only modifying the speaking rate or overall shape of spectral contour, fine-grained spectro-temporal differences between dysarthric, elderly and normal speech are modelled using a novel set of speaker dependent (SD) generative adversarial networks (GAN) based data augmentation approaches in this paper. These flexibly allow both: a) temporal or speed perturbed normal speech spectra to be modified and closer to those of an impaired speaker when parallel speech data is available; and b) for non-parallel data, the SVD decomposed normal speech spectral basis features to be transformed into those of a target elderly speaker before being re-composed with the temporal bases to produce the augmented data for state-of-the-art TDNN and Conformer ASR system training. Experiments are conducted on four tasks: the English UASpeech and TORGO dysarthric speech corpora; the English DementiaBank Pitt and Cantonese JCCOCC MoCA elderly speech datasets. The proposed GAN based data augmentation approaches consistently outperform the baseline speed perturbation method by up to 0.91% and 3.0% absolute (9.61% and 6.4% relative) WER reduction on the TORGO and DementiaBank data respectively. Consistent performance improvements are retained after applying LHUC based speaker adaptation.
An Overview on Language Models: Recent Developments and Outlook
Mar 10, 2023

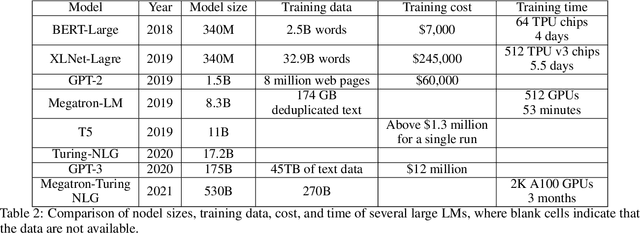
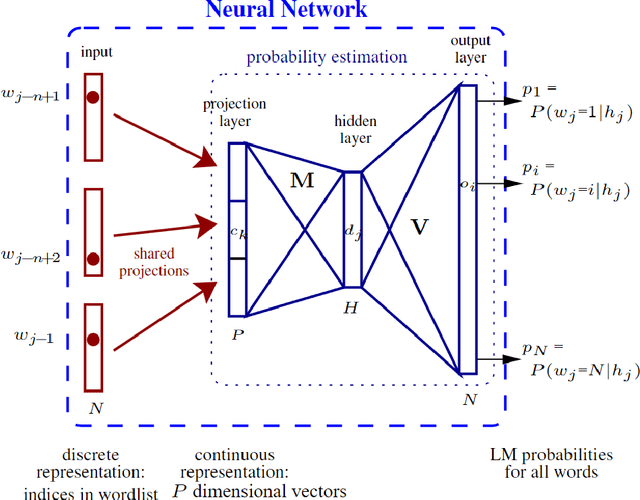
Language modeling studies the probability distributions over strings of texts. It is one of the most fundamental tasks in natural language processing (NLP). It has been widely used in text generation, speech recognition, machine translation, etc. Conventional language models (CLMs) aim to predict the probability of linguistic sequences in a causal manner. In contrast, pre-trained language models (PLMs) cover broader concepts and can be used in both causal sequential modeling and fine-tuning for downstream applications. PLMs have their own training paradigms (usually self-supervised) and serve as foundation models in modern NLP systems. This overview paper provides an introduction to both CLMs and PLMs from five aspects, i.e., linguistic units, structures, training methods, evaluation methods, and applications. Furthermore, we discuss the relationship between CLMs and PLMs and shed light on the future directions of language modeling in the pre-trained era.
Automatic Generation of Multiple-Choice Questions
Mar 25, 2023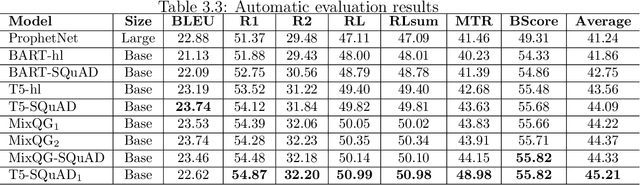
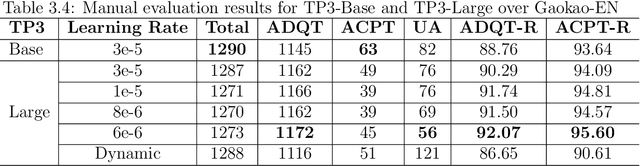
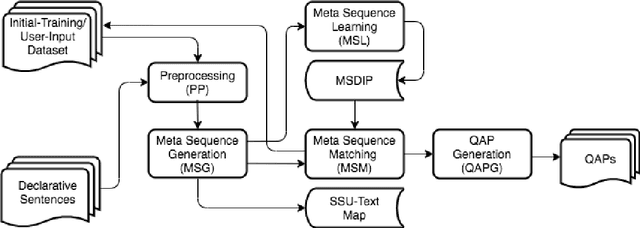
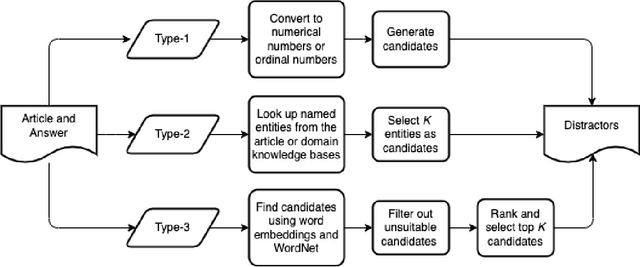
Creating multiple-choice questions to assess reading comprehension of a given article involves generating question-answer pairs (QAPs) and adequate distractors. We present two methods to tackle the challenge of QAP generations: (1) A deep-learning-based end-to-end question generation system based on T5 Transformer with Preprocessing and Postprocessing Pipelines (TP3). We use the finetuned T5 model for our downstream task of question generation and improve accuracy using a combination of various NLP tools and algorithms in preprocessing and postprocessing to select appropriate answers and filter undesirable questions. (2) A sequence-learning-based scheme to generate adequate QAPs via meta-sequence representations of sentences. A meta-sequence is a sequence of vectors comprising semantic and syntactic tags. we devise a scheme called MetaQA to learn meta sequences from training data to form pairs of a meta sequence for a declarative sentence and a corresponding interrogative sentence. The TP3 works well on unseen data, which is complemented by MetaQA. Both methods can generate well-formed and grammatically correct questions. Moreover, we present a novel approach to automatically generate adequate distractors for a given QAP. The method is a combination of part-of-speech tagging, named-entity tagging, semantic-role labeling, regular expressions, domain knowledge bases, word embeddings, word edit distance, WordNet, and other algorithms.
Multi-channel target speech enhancement based on ERB-scaled spatial coherence features
Jul 17, 2022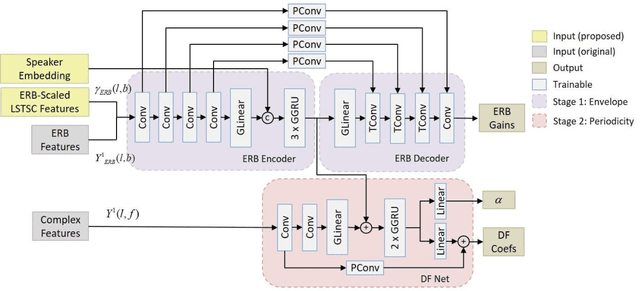
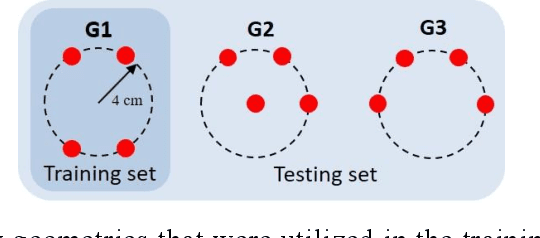
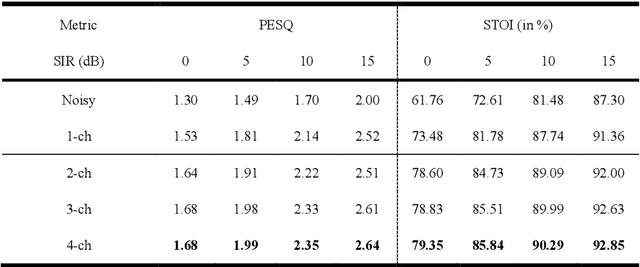
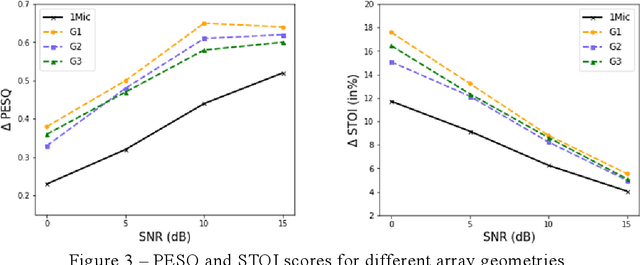
Recently, speech enhancement technologies that are based on deep learning have received considerable research attention. If the spatial information in microphone signals is exploited, microphone arrays can be advantageous under some adverse acoustic conditions compared with single-microphone systems. However, multichannel speech enhancement is often performed in the short-time Fourier transform (STFT) domain, which renders the enhancement approach computationally expensive. To remedy this problem, we propose a novel equivalent rectangular bandwidth (ERB)-scaled spatial coherence feature that is dependent on the target speaker activity between two ERB bands. Experiments conducted using a four-microphone array in a reverberant environment, which involved speech interference, demonstrated the efficacy of the proposed system. This study also demonstrated that a network that was trained with the ERB-scaled spatial feature was robust against variations in the geometry and number of the microphones in the array.
Visual Context-driven Audio Feature Enhancement for Robust End-to-End Audio-Visual Speech Recognition
Jul 13, 2022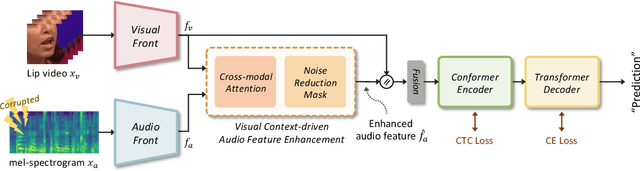
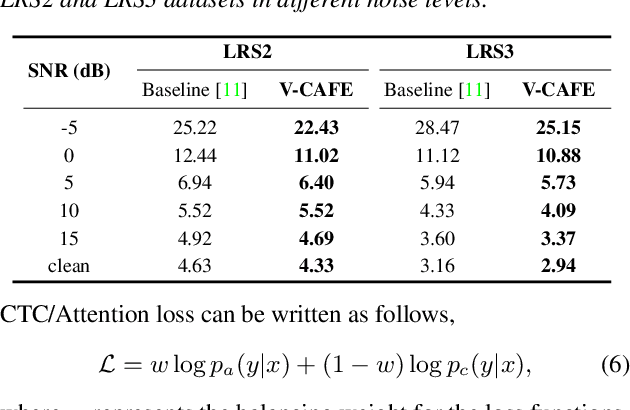
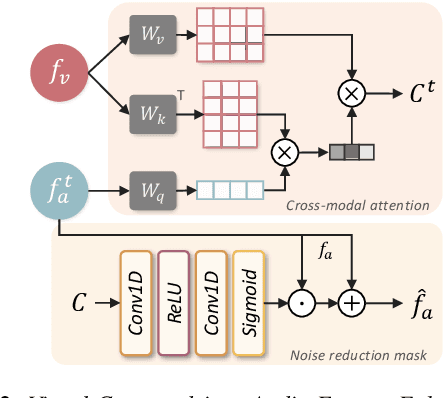
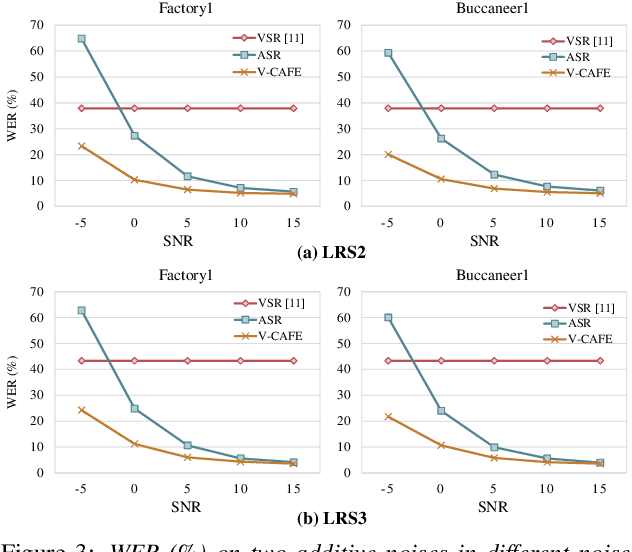
This paper focuses on designing a noise-robust end-to-end Audio-Visual Speech Recognition (AVSR) system. To this end, we propose Visual Context-driven Audio Feature Enhancement module (V-CAFE) to enhance the input noisy audio speech with a help of audio-visual correspondence. The proposed V-CAFE is designed to capture the transition of lip movements, namely visual context and to generate a noise reduction mask by considering the obtained visual context. Through context-dependent modeling, the ambiguity in viseme-to-phoneme mapping can be refined for mask generation. The noisy representations are masked out with the noise reduction mask resulting in enhanced audio features. The enhanced audio features are fused with the visual features and taken to an encoder-decoder model composed of Conformer and Transformer for speech recognition. We show the proposed end-to-end AVSR with the V-CAFE can further improve the noise-robustness of AVSR. The effectiveness of the proposed method is evaluated in noisy speech recognition and overlapped speech recognition experiments using the two largest audio-visual datasets, LRS2 and LRS3.
Chain-based Discriminative Autoencoders for Speech Recognition
Mar 28, 2022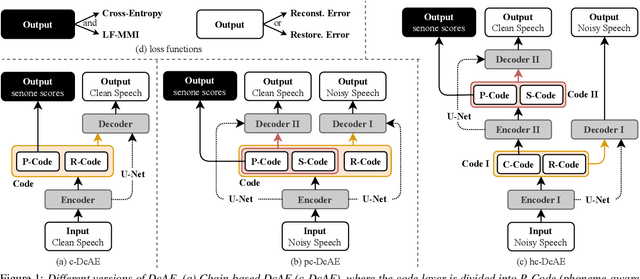
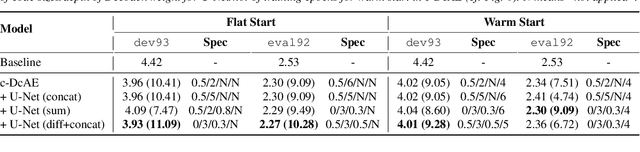
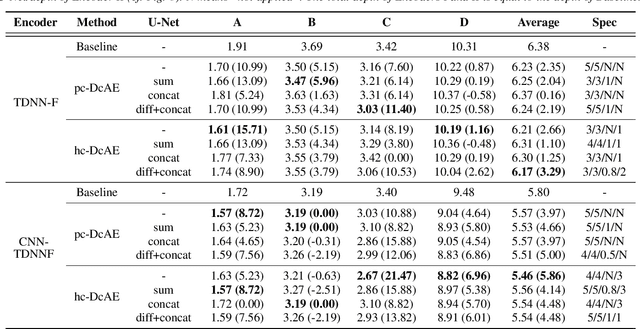
In our previous work, we proposed a discriminative autoencoder (DcAE) for speech recognition. DcAE combines two training schemes into one. First, since DcAE aims to learn encoder-decoder mappings, the squared error between the reconstructed speech and the input speech is minimized. Second, in the code layer, frame-based phonetic embeddings are obtained by minimizing the categorical cross-entropy between ground truth labels and predicted triphone-state scores. DcAE is developed based on the Kaldi toolkit by treating various TDNN models as encoders. In this paper, we further propose three new versions of DcAE. First, a new objective function that considers both categorical cross-entropy and mutual information between ground truth and predicted triphone-state sequences is used. The resulting DcAE is called a chain-based DcAE (c-DcAE). For application to robust speech recognition, we further extend c-DcAE to hierarchical and parallel structures, resulting in hc-DcAE and pc-DcAE. In these two models, both the error between the reconstructed noisy speech and the input noisy speech and the error between the enhanced speech and the reference clean speech are taken into the objective function. Experimental results on the WSJ and Aurora-4 corpora show that our DcAE models outperform baseline systems.
Self-FiLM: Conditioning GANs with self-supervised representations for bandwidth extension based speaker recognition
Mar 07, 2023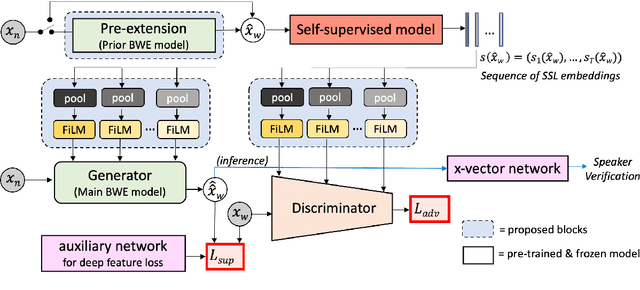
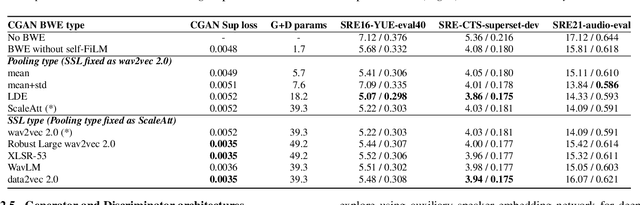
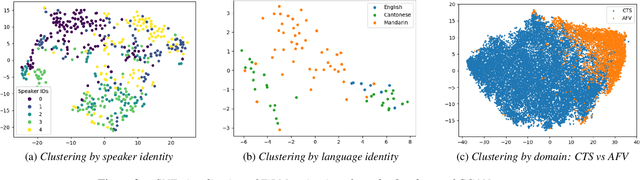
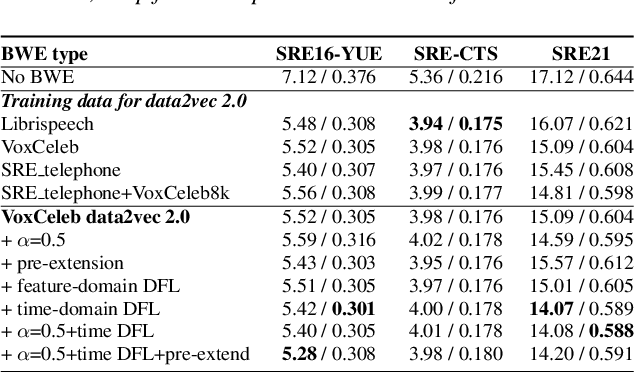
Speech super-resolution/Bandwidth Extension (BWE) can improve downstream tasks like Automatic Speaker Verification (ASV). We introduce a simple novel technique called Self-FiLM to inject self-supervision into existing BWE models via Feature-wise Linear Modulation. We hypothesize that such information captures domain/environment information, which can give zero-shot generalization. Self-FiLM Conditional GAN (CGAN) gives 18% relative improvement in Equal Error Rate and 8.5% in minimum Decision Cost Function using state-of-the-art ASV system on SRE21 test. We further by 1) deep feature loss from time-domain models and 2) re-training of data2vec 2.0 models on naturalistic wideband (VoxCeleb) and telephone data (SRE Superset etc.). Lastly, we integrate self-supervision with CycleGAN to present a completely unsupervised solution that matches the semi-supervised performance.
Improving Self-Supervised Learning for Audio Representations by Feature Diversity and Decorrelation
Mar 07, 2023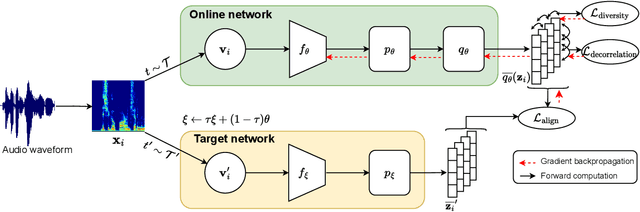
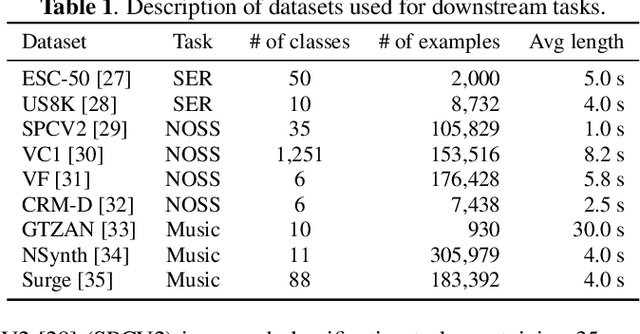
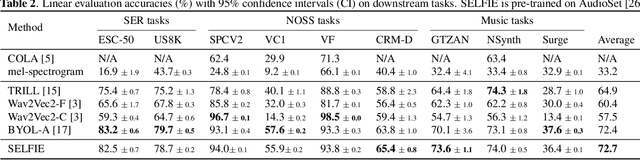
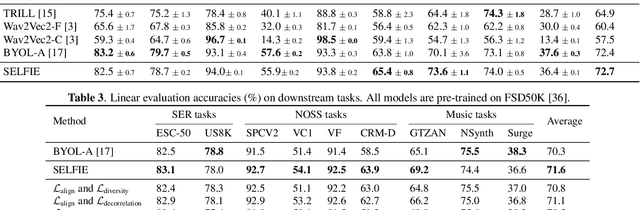
Self-supervised learning (SSL) has recently shown remarkable results in closing the gap between supervised and unsupervised learning. The idea is to learn robust features that are invariant to distortions of the input data. Despite its success, this idea can suffer from a collapsing issue where the network produces a constant representation. To this end, we introduce SELFIE, a novel Self-supervised Learning approach for audio representation via Feature Diversity and Decorrelation. SELFIE avoids the collapsing issue by ensuring that the representation (i) maintains a high diversity among embeddings and (ii) decorrelates the dependencies between dimensions. SELFIE is pre-trained on the large-scale AudioSet dataset and its embeddings are validated on nine audio downstream tasks, including speech, music, and sound event recognition. Experimental results show that SELFIE outperforms existing SSL methods in several tasks.