 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"speech": models, code, and papers
A Study of Dropout-Induced Modality Bias on Robustness to Missing Video Frames for Audio-Visual Speech Recognition
Mar 07, 2024
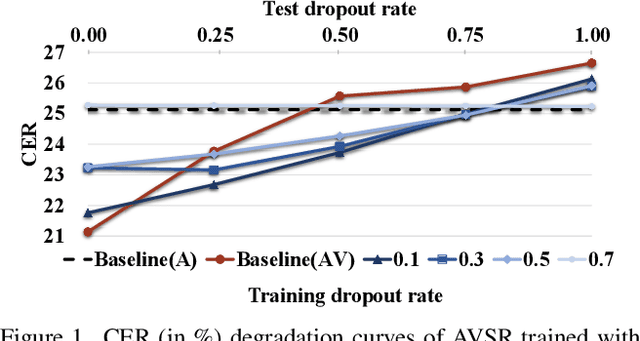

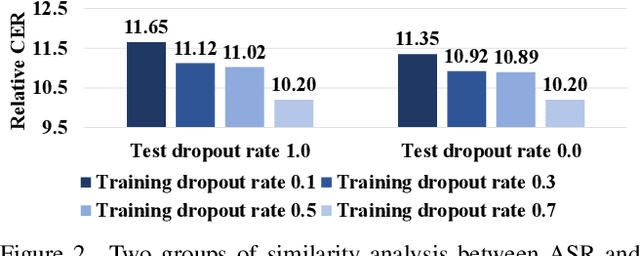
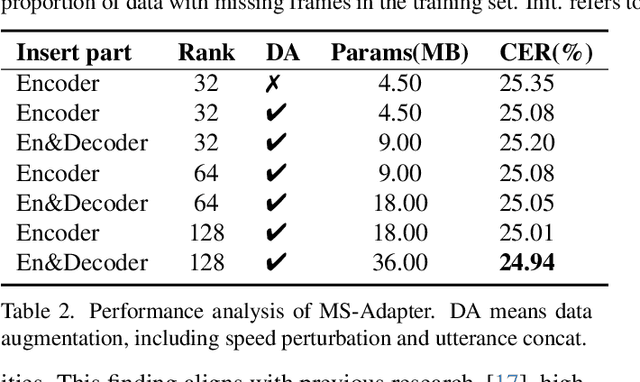
Advanced Audio-Visual Speech Recognition (AVSR) systems have been observed to be sensitive to missing video frames, performing even worse than single-modality models. While applying the dropout technique to the video modality enhances robustness to missing frames, it simultaneously results in a performance loss when dealing with complete data input. In this paper, we investigate this contrasting phenomenon from the perspective of modality bias and reveal that an excessive modality bias on the audio caused by dropout is the underlying reason. Moreover, we present the Modality Bias Hypothesis (MBH) to systematically describe the relationship between modality bias and robustness against missing modality in multimodal systems. Building on these findings, we propose a novel Multimodal Distribution Approximation with Knowledge Distillation (MDA-KD) framework to reduce over-reliance on the audio modality and to maintain performance and robustness simultaneously. Finally, to address an entirely missing modality, we adopt adapters to dynamically switch decision strategies. The effectiveness of our proposed approach is evaluated and validated through a series of comprehensive experiments using the MISP2021 and MISP2022 datasets. Our code is available at https://github.com/dalision/ModalBiasAVSR
Don't Go To Extremes: Revealing the Excessive Sensitivity and Calibration Limitations of LLMs in Implicit Hate Speech Detection
Feb 26, 2024The fairness and trustworthiness of Large Language Models (LLMs) are receiving increasing attention. Implicit hate speech, which employs indirect language to convey hateful intentions, occupies a significant portion of practice. However, the extent to which LLMs effectively address this issue remains insufficiently examined. This paper delves into the capability of LLMs to detect implicit hate speech (Classification Task) and express confidence in their responses (Calibration Task). Our evaluation meticulously considers various prompt patterns and mainstream uncertainty estimation methods. Our findings highlight that LLMs exhibit two extremes: (1) LLMs display excessive sensitivity towards groups or topics that may cause fairness issues, resulting in misclassifying benign statements as hate speech. (2) LLMs' confidence scores for each method excessively concentrate on a fixed range, remaining unchanged regardless of the dataset's complexity. Consequently, the calibration performance is heavily reliant on primary classification accuracy. These discoveries unveil new limitations of LLMs, underscoring the need for caution when optimizing models to ensure they do not veer towards extremes. This serves as a reminder to carefully consider sensitivity and confidence in the pursuit of model fairness.
Regularized Adaptive Momentum Dual Averaging with an Efficient Inexact Subproblem Solver for Training Structured Neural Network
Mar 21, 2024
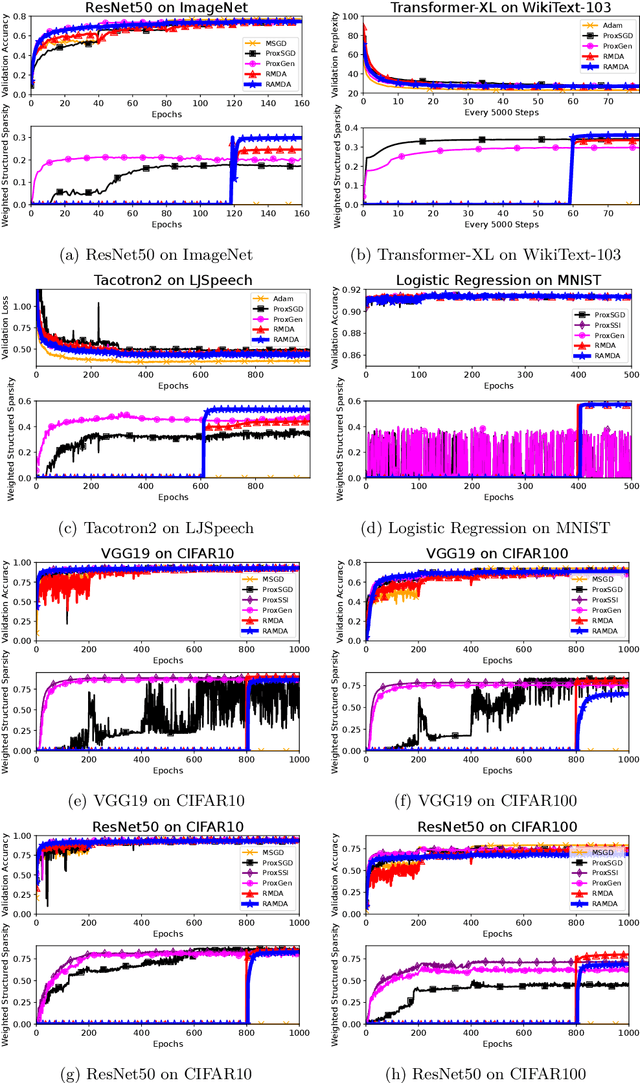
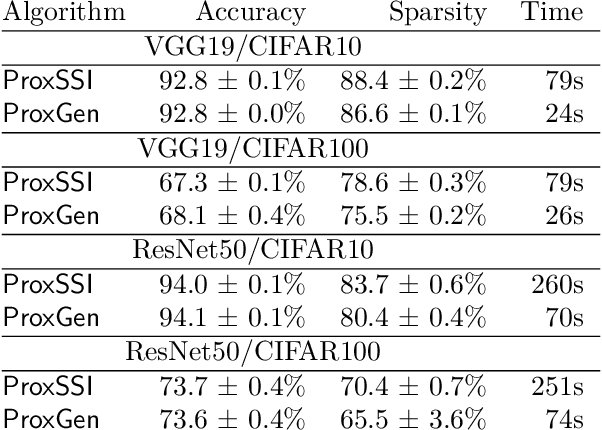
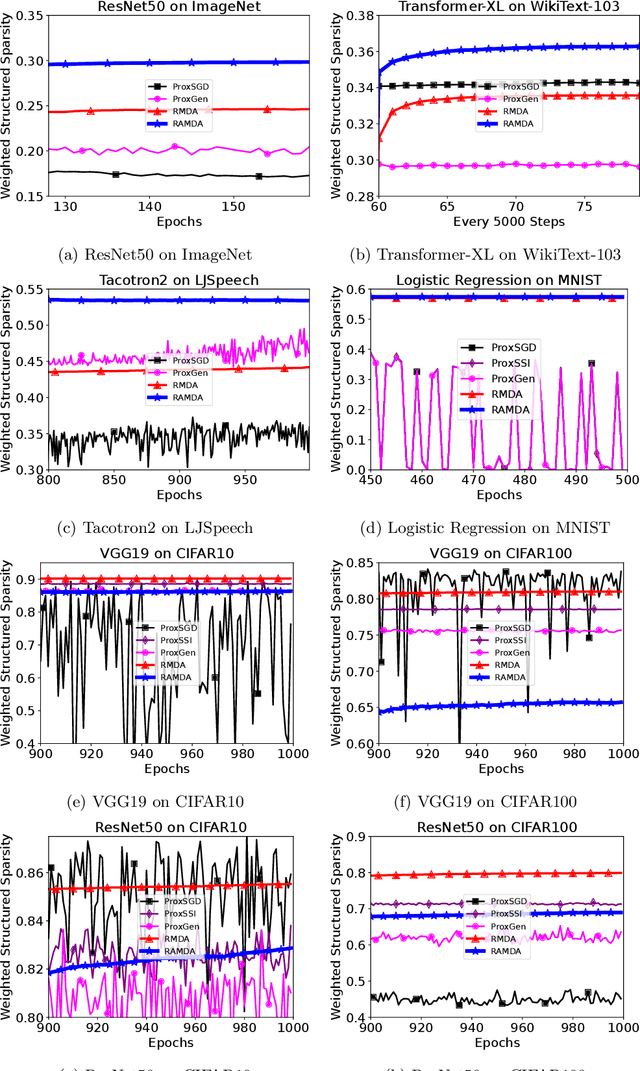
We propose a Regularized Adaptive Momentum Dual Averaging (RAMDA) algorithm for training structured neural networks. Similar to existing regularized adaptive methods, the subproblem for computing the update direction of RAMDA involves a nonsmooth regularizer and a diagonal preconditioner, and therefore does not possess a closed-form solution in general. We thus also carefully devise an implementable inexactness condition that retains convergence guarantees similar to the exact versions, and propose a companion efficient solver for the subproblems of both RAMDA and existing methods to make them practically feasible. We leverage the theory of manifold identification in variational analysis to show that, even in the presence of such inexactness, the iterates of RAMDA attain the ideal structure induced by the regularizer at the stationary point of asymptotic convergence. This structure is locally optimal near the point of convergence, so RAMDA is guaranteed to obtain the best structure possible among all methods converging to the same point, making it the first regularized adaptive method outputting models that possess outstanding predictive performance while being (locally) optimally structured. Extensive numerical experiments in large-scale modern computer vision, language modeling, and speech tasks show that the proposed RAMDA is efficient and consistently outperforms state of the art for training structured neural network. Implementation of our algorithm is available at http://www.github.com/ismoptgroup/RAMDA/.
Prompt-based Graph Model for Joint Liberal Event Extraction and Event Schema Induction
Mar 19, 2024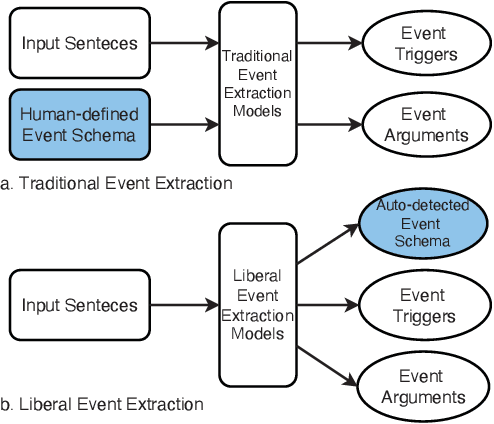


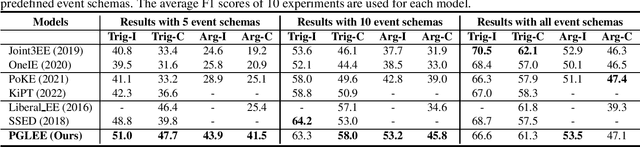
Events are essential components of speech and texts, describing the changes in the state of entities. The event extraction task aims to identify and classify events and find their participants according to event schemas. Manually predefined event schemas have limited coverage and are hard to migrate across domains. Therefore, the researchers propose Liberal Event Extraction (LEE), which aims to extract events and discover event schemas simultaneously. However, existing LEE models rely heavily on external language knowledge bases and require the manual development of numerous rules for noise removal and knowledge alignment, which is complex and laborious. To this end, we propose a Prompt-based Graph Model for Liberal Event Extraction (PGLEE). Specifically, we use a prompt-based model to obtain candidate triggers and arguments, and then build heterogeneous event graphs to encode the structures within and between events. Experimental results prove that our approach achieves excellent performance with or without predefined event schemas, while the automatically detected event schemas are proven high quality.
Decoding Continuous Character-based Language from Non-invasive Brain Recordings
Mar 19, 2024Deciphering natural language from brain activity through non-invasive devices remains a formidable challenge. Previous non-invasive decoders either require multiple experiments with identical stimuli to pinpoint cortical regions and enhance signal-to-noise ratios in brain activity, or they are limited to discerning basic linguistic elements such as letters and words. We propose a novel approach to decoding continuous language from single-trial non-invasive fMRI recordings, in which a three-dimensional convolutional network augmented with information bottleneck is developed to automatically identify responsive voxels to stimuli, and a character-based decoder is designed for the semantic reconstruction of continuous language characterized by inherent character structures. The resulting decoder can produce intelligible textual sequences that faithfully capture the meaning of perceived speech both within and across subjects, while existing decoders exhibit significantly inferior performance in cross-subject contexts. The ability to decode continuous language from single trials across subjects demonstrates the promising applications of non-invasive language brain-computer interfaces in both healthcare and neuroscience.
Prompt-Singer: Controllable Singing-Voice-Synthesis with Natural Language Prompt
Mar 18, 2024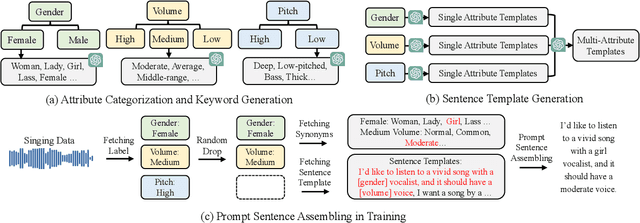
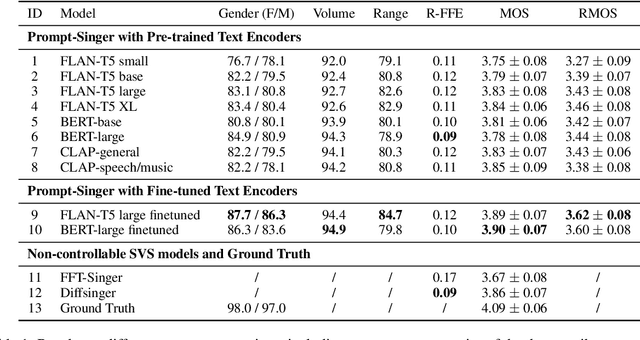
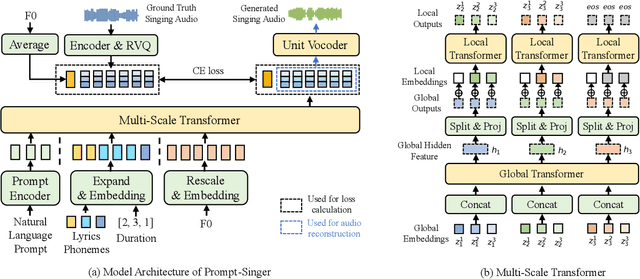
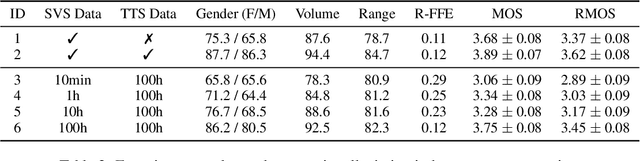
Recent singing-voice-synthesis (SVS) methods have achieved remarkable audio quality and naturalness, yet they lack the capability to control the style attributes of the synthesized singing explicitly. We propose Prompt-Singer, the first SVS method that enables attribute controlling on singer gender, vocal range and volume with natural language. We adopt a model architecture based on a decoder-only transformer with a multi-scale hierarchy, and design a range-melody decoupled pitch representation that enables text-conditioned vocal range control while keeping melodic accuracy. Furthermore, we explore various experiment settings, including different types of text representations, text encoder fine-tuning, and introducing speech data to alleviate data scarcity, aiming to facilitate further research. Experiments show that our model achieves favorable controlling ability and audio quality. Audio samples are available at http://prompt-singer.github.io .
The Effect of Batch Size on Contrastive Self-Supervised Speech Representation Learning
Feb 21, 2024Foundation models in speech are often trained using many GPUs, which implicitly leads to large effective batch sizes. In this paper we study the effect of batch size on pre-training, both in terms of statistics that can be monitored during training, and in the effect on the performance of a downstream fine-tuning task. By using batch sizes varying from 87.5 seconds to 80 minutes of speech we show that, for a fixed amount of iterations, larger batch sizes result in better pre-trained models. However, there is lower limit for stability, and an upper limit for effectiveness. We then show that the quality of the pre-trained model depends mainly on the amount of speech data seen during training, i.e., on the product of batch size and number of iterations. All results are produced with an independent implementation of the wav2vec 2.0 architecture, which to a large extent reproduces the results of the original work (arXiv:2006.11477). Our extensions can help researchers choose effective operating conditions when studying self-supervised learning in speech, and hints towards benchmarking self-supervision with a fixed amount of seen data. Code and model checkpoints are available at https://github.com/nikvaessen/w2v2-batch-size.
Exploring Green AI for Audio Deepfake Detection
Mar 21, 2024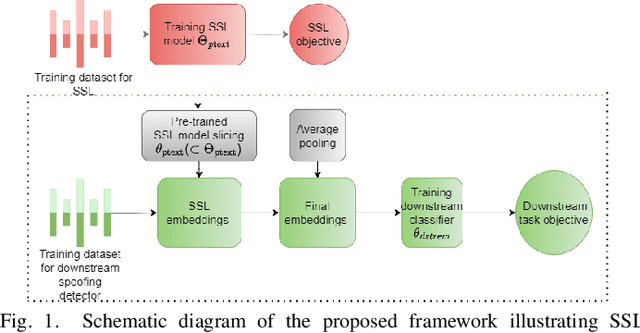
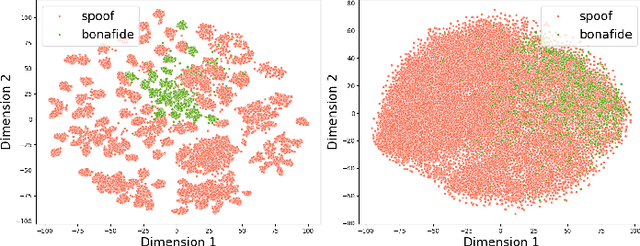
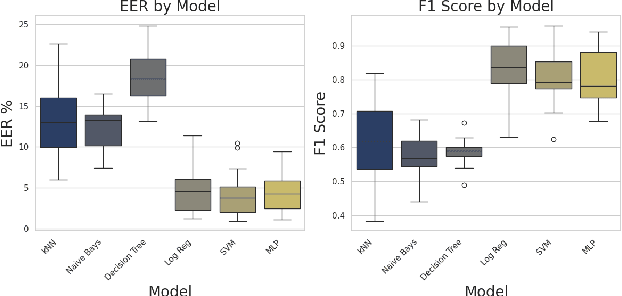
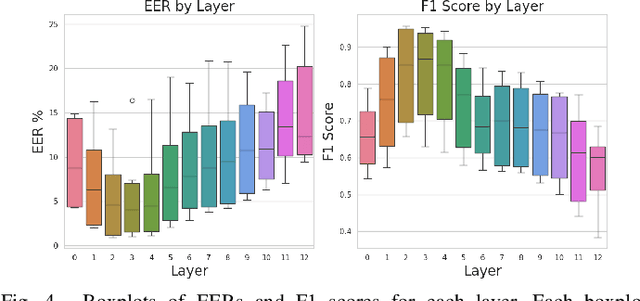
The state-of-the-art audio deepfake detectors leveraging deep neural networks exhibit impressive recognition performance. Nonetheless, this advantage is accompanied by a significant carbon footprint. This is mainly due to the use of high-performance computing with accelerators and high training time. Studies show that average deep NLP model produces around 626k lbs of CO\textsubscript{2} which is equivalent to five times of average US car emission at its lifetime. This is certainly a massive threat to the environment. To tackle this challenge, this study presents a novel framework for audio deepfake detection that can be seamlessly trained using standard CPU resources. Our proposed framework utilizes off-the-shelve self-supervised learning (SSL) based models which are pre-trained and available in public repositories. In contrast to existing methods that fine-tune SSL models and employ additional deep neural networks for downstream tasks, we exploit classical machine learning algorithms such as logistic regression and shallow neural networks using the SSL embeddings extracted using the pre-trained model. Our approach shows competitive results compared to the commonly used high-carbon footprint approaches. In experiments with the ASVspoof 2019 LA dataset, we achieve a 0.90\% equal error rate (EER) with less than 1k trainable model parameters. To encourage further research in this direction and support reproducible results, the Python code will be made publicly accessible following acceptance. Github: https://github.com/sahasubhajit/Speech-Spoofing-
Beyond Hate Speech: NLP's Challenges and Opportunities in Uncovering Dehumanizing Language
Feb 21, 2024Dehumanization, characterized as a subtle yet harmful manifestation of hate speech, involves denying individuals of their human qualities and often results in violence against marginalized groups. Despite significant progress in Natural Language Processing across various domains, its application in detecting dehumanizing language is limited, largely due to the scarcity of publicly available annotated data for this domain. This paper evaluates the performance of cutting-edge NLP models, including GPT-4, GPT-3.5, and LLAMA-2, in identifying dehumanizing language. Our findings reveal that while these models demonstrate potential, achieving a 70\% accuracy rate in distinguishing dehumanizing language from broader hate speech, they also display biases. They are over-sensitive in classifying other forms of hate speech as dehumanization for a specific subset of target groups, while more frequently failing to identify clear cases of dehumanization for other target groups. Moreover, leveraging one of the best-performing models, we automatically annotated a larger dataset for training more accessible models. However, our findings indicate that these models currently do not meet the high-quality data generation threshold necessary for this task.
Leveraging Linguistically Enhanced Embeddings for Open Information Extraction
Mar 20, 2024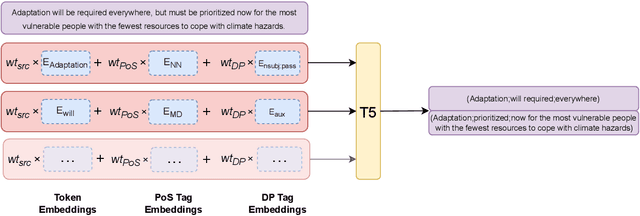

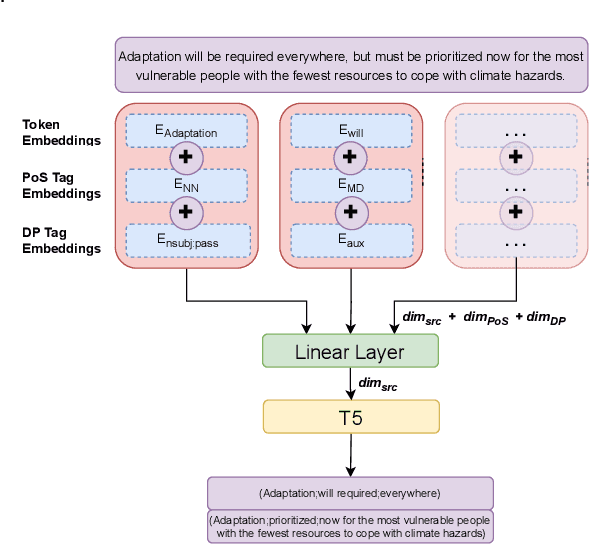
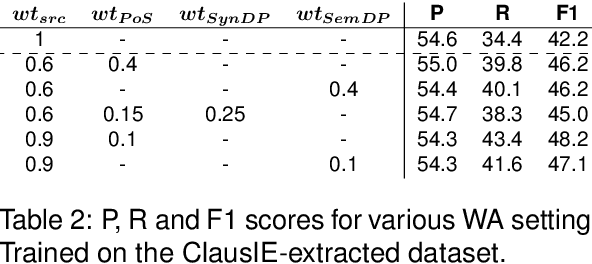
Open Information Extraction (OIE) is a structured prediction (SP) task in Natural Language Processing (NLP) that aims to extract structured $n$-ary tuples - usually subject-relation-object triples - from free text. The word embeddings in the input text can be enhanced with linguistic features, usually Part-of-Speech (PoS) and Syntactic Dependency Parse (SynDP) labels. However, past enhancement techniques cannot leverage the power of pretrained language models (PLMs), which themselves have been hardly used for OIE. To bridge this gap, we are the first to leverage linguistic features with a Seq2Seq PLM for OIE. We do so by introducing two methods - Weighted Addition and Linearized Concatenation. Our work can give any neural OIE architecture the key performance boost from both PLMs and linguistic features in one go. In our settings, this shows wide improvements of up to 24.9%, 27.3% and 14.9% on Precision, Recall and F1 scores respectively over the baseline. Beyond this, we address other important challenges in the field: to reduce compute overheads with the features, we are the first ones to exploit Semantic Dependency Parse (SemDP) tags; to address flaws in current datasets, we create a clean synthetic dataset; finally, we contribute the first known study of OIE behaviour in SP models.