 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"speech": models, code, and papers
Self-supervised Neural Factor Analysis for Disentangling Utterance-level Speech Representations
May 18, 2023

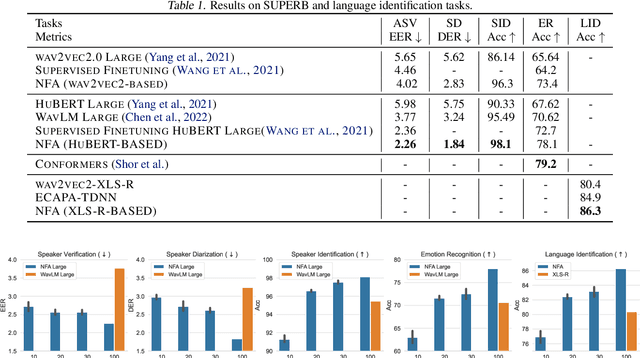
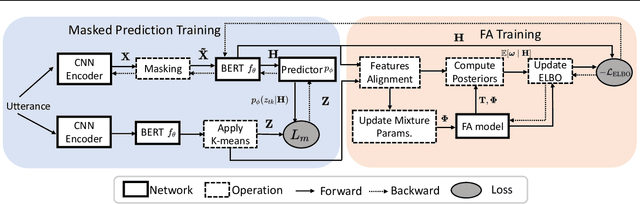
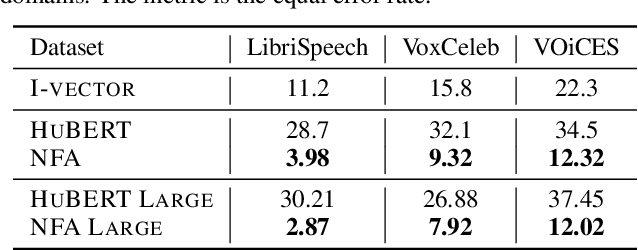
Self-supervised learning (SSL) speech models such as wav2vec and HuBERT have demonstrated state-of-the-art performance on automatic speech recognition (ASR) and proved to be extremely useful in low label-resource settings. However, the success of SSL models has yet to transfer to utterance-level tasks such as speaker, emotion, and language recognition, which still require supervised fine-tuning of the SSL models to obtain good performance. We argue that the problem is caused by the lack of disentangled representations and an utterance-level learning objective for these tasks. Inspired by how HuBERT uses clustering to discover hidden acoustic units, we formulate a factor analysis (FA) model that uses the discovered hidden acoustic units to align the SSL features. The underlying utterance-level representations are disentangled from the content of speech using probabilistic inference on the aligned features. Furthermore, the variational lower bound derived from the FA model provides an utterance-level objective, allowing error gradients to be backpropagated to the Transformer layers to learn highly discriminative acoustic units. When used in conjunction with HuBERT's masked prediction training, our models outperform the current best model, WavLM, on all utterance-level non-semantic tasks on the SUPERB benchmark with only 20% of labeled data.
Mitigating Negative Transfer with Task Awareness for Sexism, Hate Speech, and Toxic Language Detection
Jul 07, 2023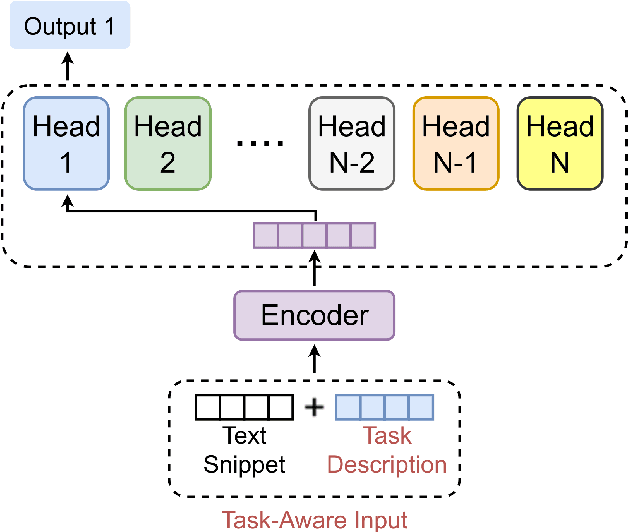
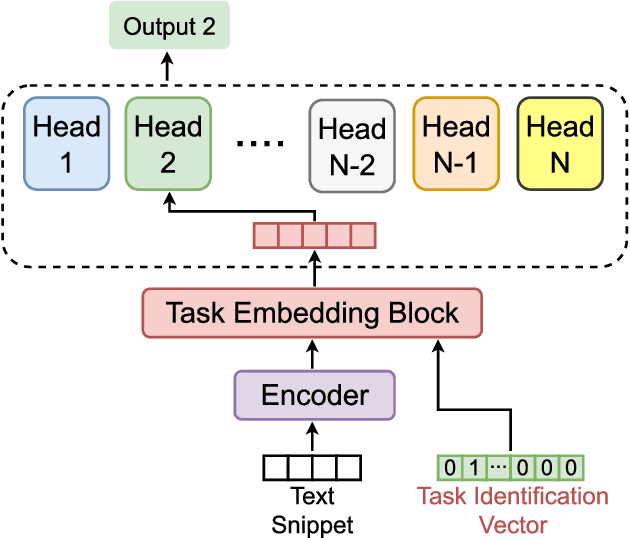
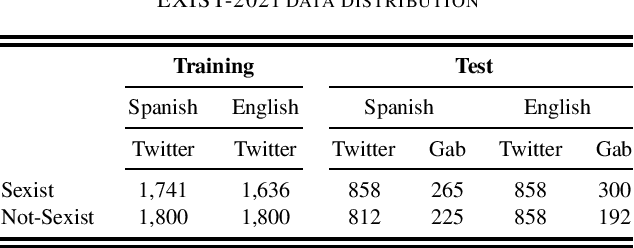
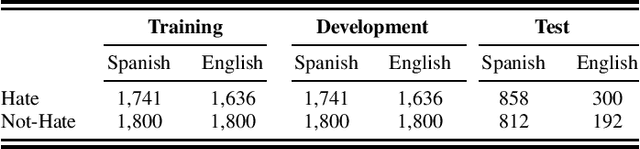
This paper proposes a novelty approach to mitigate the negative transfer problem. In the field of machine learning, the common strategy is to apply the Single-Task Learning approach in order to train a supervised model to solve a specific task. Training a robust model requires a lot of data and a significant amount of computational resources, making this solution unfeasible in cases where data are unavailable or expensive to gather. Therefore another solution, based on the sharing of information between tasks, has been developed: Multi-Task Learning (MTL). Despite the recent developments regarding MTL, the problem of negative transfer has still to be solved. Negative transfer is a phenomenon that occurs when noisy information is shared between tasks, resulting in a drop in performance. This paper proposes a new approach to mitigate the negative transfer problem based on the task awareness concept. The proposed approach results in diminishing the negative transfer together with an improvement of performance over classic MTL solution. Moreover, the proposed approach has been implemented in two unified architectures to detect Sexism, Hate Speech, and Toxic Language in text comments. The proposed architectures set a new state-of-the-art both in EXIST-2021 and HatEval-2019 benchmarks.
DGSD: Dynamical Graph Self-Distillation for EEG-Based Auditory Spatial Attention Detection
Sep 07, 2023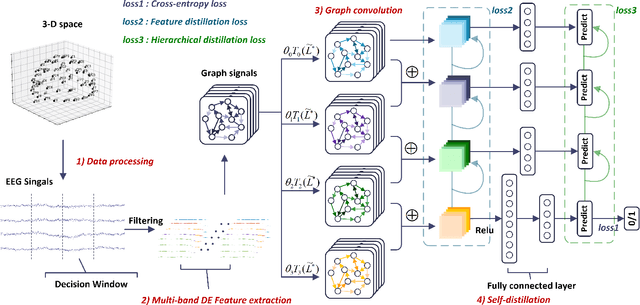
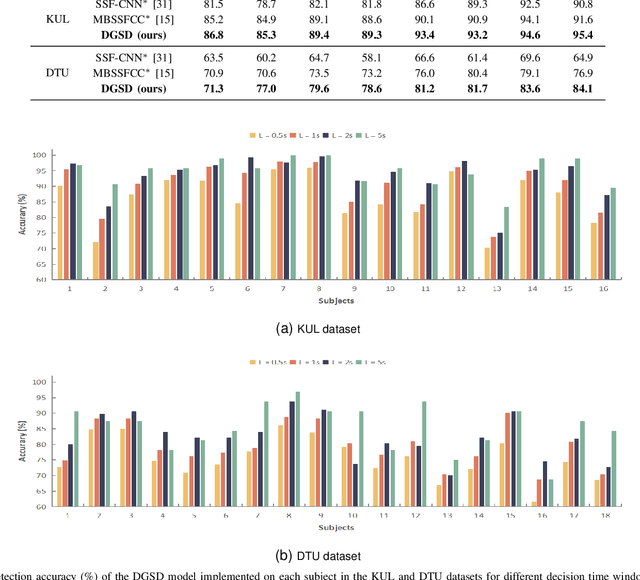
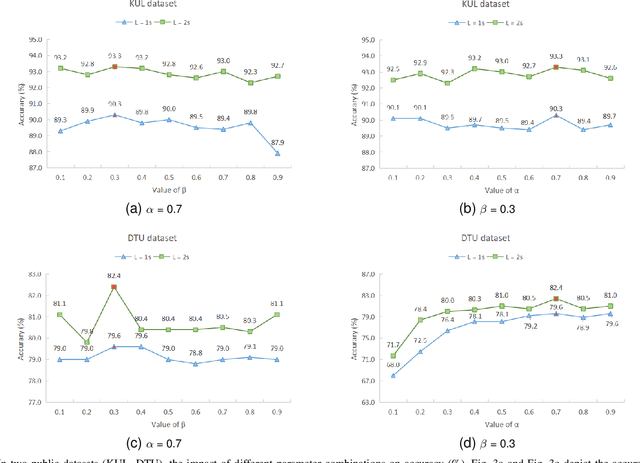

Auditory Attention Detection (AAD) aims to detect target speaker from brain signals in a multi-speaker environment. Although EEG-based AAD methods have shown promising results in recent years, current approaches primarily rely on traditional convolutional neural network designed for processing Euclidean data like images. This makes it challenging to handle EEG signals, which possess non-Euclidean characteristics. In order to address this problem, this paper proposes a dynamical graph self-distillation (DGSD) approach for AAD, which does not require speech stimuli as input. Specifically, to effectively represent the non-Euclidean properties of EEG signals, dynamical graph convolutional networks are applied to represent the graph structure of EEG signals, which can also extract crucial features related to auditory spatial attention in EEG signals. In addition, to further improve AAD detection performance, self-distillation, consisting of feature distillation and hierarchical distillation strategies at each layer, is integrated. These strategies leverage features and classification results from the deepest network layers to guide the learning of shallow layers. Our experiments are conducted on two publicly available datasets, KUL and DTU. Under a 1-second time window, we achieve results of 90.0\% and 79.6\% accuracy on KUL and DTU, respectively. We compare our DGSD method with competitive baselines, and the experimental results indicate that the detection performance of our proposed DGSD method is not only superior to the best reproducible baseline but also significantly reduces the number of trainable parameters by approximately 100 times.
Towards robust paralinguistic assessment for real-world mobile health (mHealth) monitoring: an initial study of reverberation effects on speech
May 21, 2023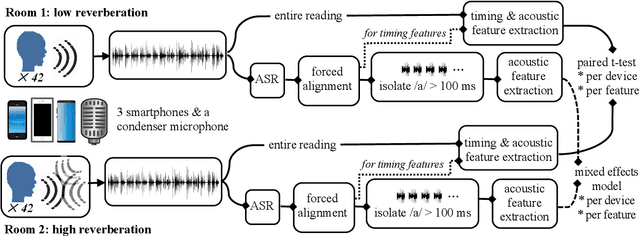

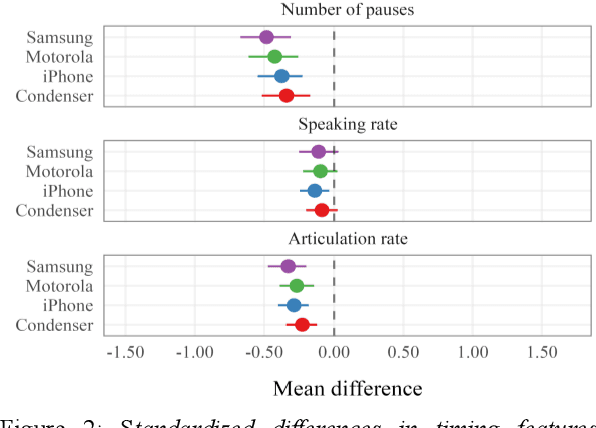
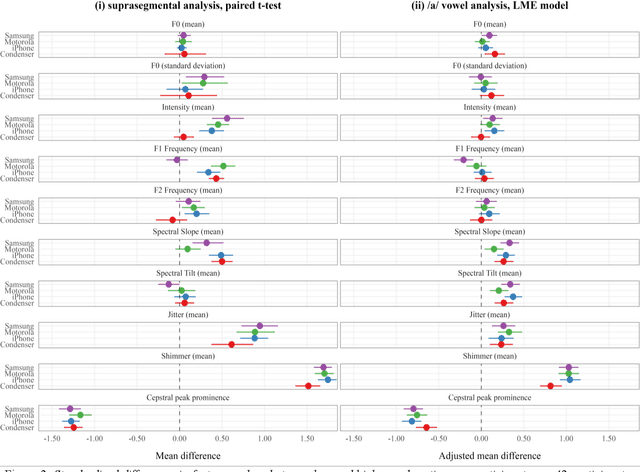
Speech is promising as an objective, convenient tool to monitor health remotely over time using mobile devices. Numerous paralinguistic features have been demonstrated to contain salient information related to an individual's health. However, mobile device specification and acoustic environments vary widely, risking the reliability of the extracted features. In an initial step towards quantifying these effects, we report the variability of 13 exemplar paralinguistic features commonly reported in the speech-health literature and extracted from the speech of 42 healthy volunteers recorded consecutively in rooms with low and high reverberation with one budget and two higher-end smartphones and a condenser microphone. Our results show reverberation has a clear effect on several features, in particular voice quality markers. They point to new research directions investigating how best to record and process in-the-wild speech for reliable longitudinal health state assessment.
Unsupervised Speech Representation Pooling Using Vector Quantization
Apr 08, 2023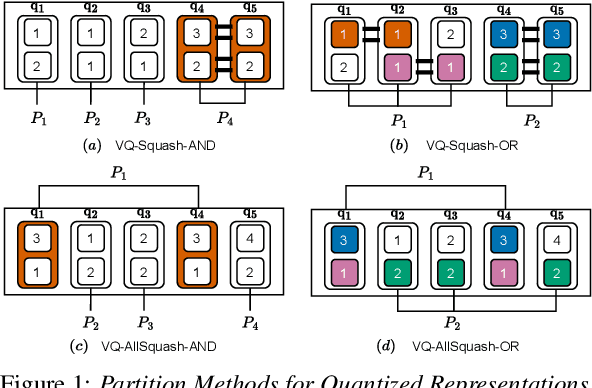
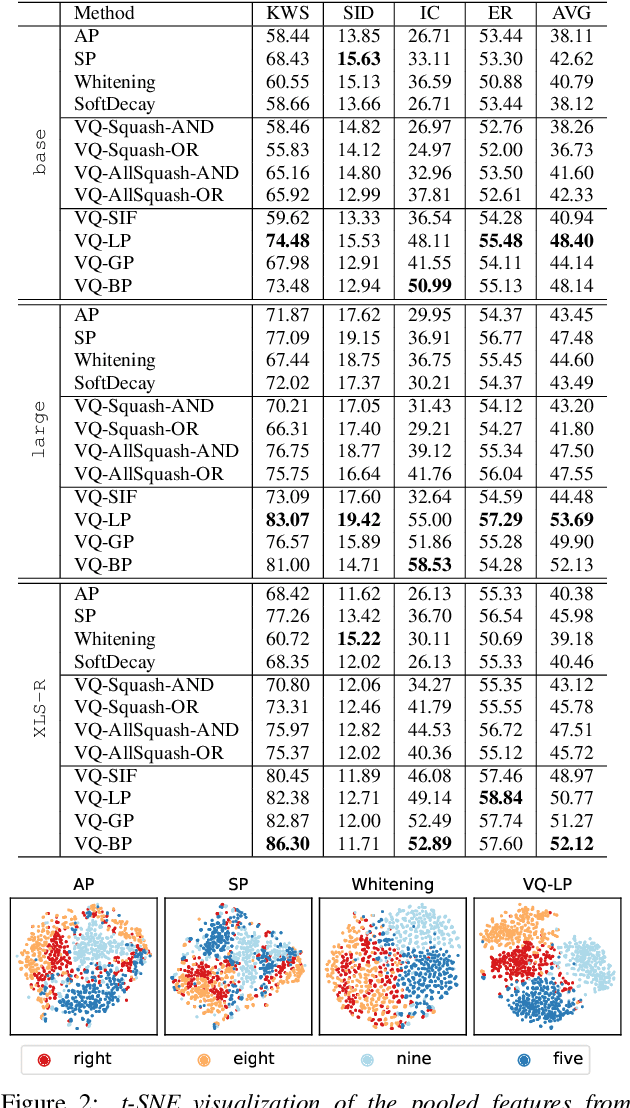
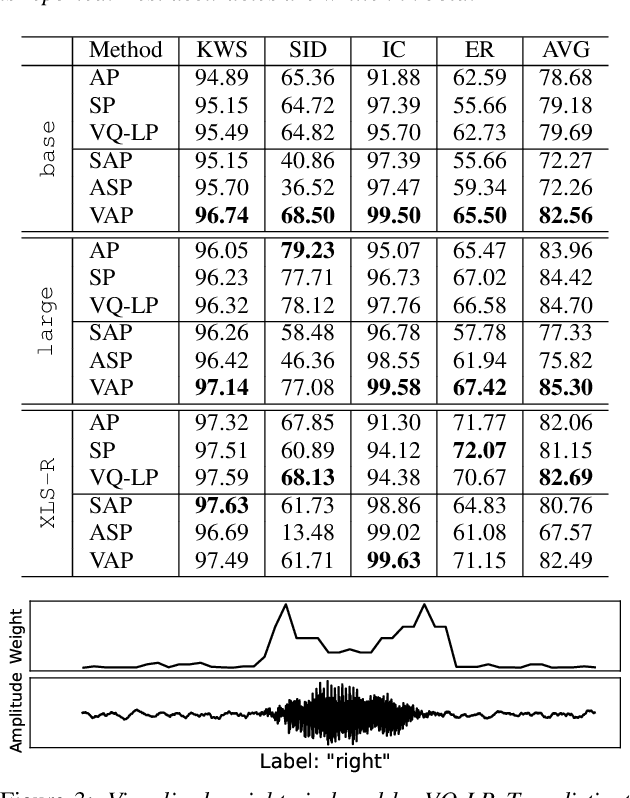
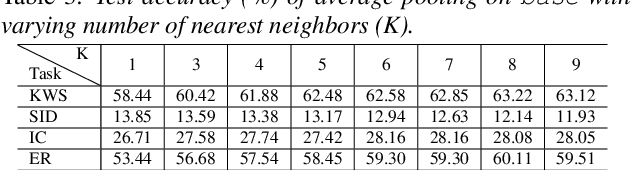
With the advent of general-purpose speech representations from large-scale self-supervised models, applying a single model to multiple downstream tasks is becoming a de-facto approach. However, the pooling problem remains; the length of speech representations is inherently variable. The naive average pooling is often used, even though it ignores the characteristics of speech, such as differently lengthed phonemes. Hence, we design a novel pooling method to squash acoustically similar representations via vector quantization, which does not require additional training, unlike attention-based pooling. Further, we evaluate various unsupervised pooling methods on various self-supervised models. We gather diverse methods scattered around speech and text to evaluate on various tasks: keyword spotting, speaker identification, intent classification, and emotion recognition. Finally, we quantitatively and qualitatively analyze our method, comparing it with supervised pooling methods.
The DKU-MSXF Diarization System for the VoxCeleb Speaker Recognition Challenge 2023
Aug 17, 2023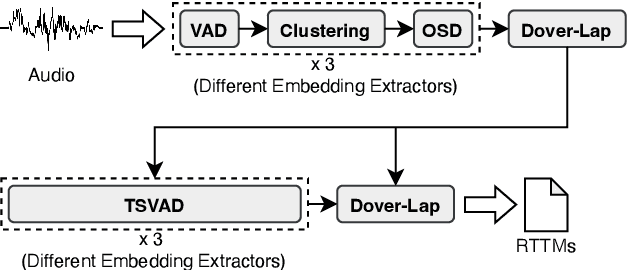
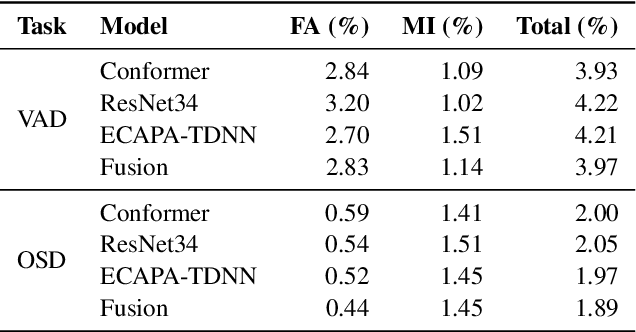

This paper describes the DKU-MSXF submission to track 4 of the VoxCeleb Speaker Recognition Challenge 2023 (VoxSRC-23). Our system pipeline contains voice activity detection, clustering-based diarization, overlapped speech detection, and target-speaker voice activity detection, where each procedure has a fused output from 3 sub-models. Finally, we fuse different clustering-based and TSVAD-based diarization systems using DOVER-Lap and achieve the 4.30% diarization error rate (DER), which ranks first place on track 4 of the challenge leaderboard.
ReZero: Region-customizable Sound Extraction
Aug 31, 2023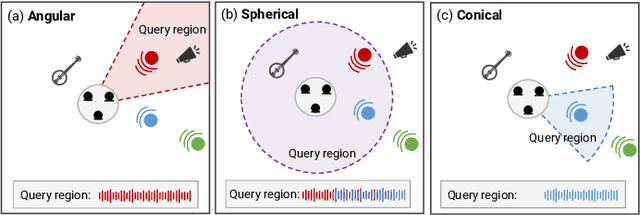
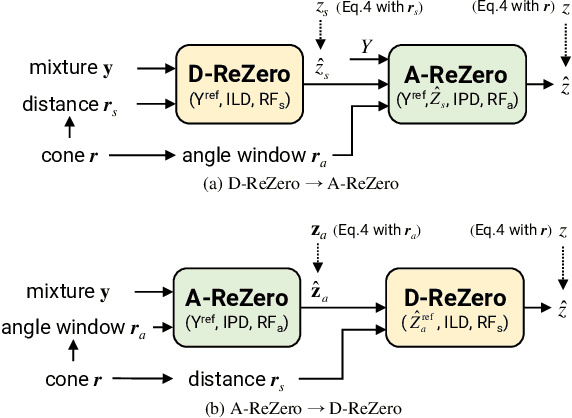
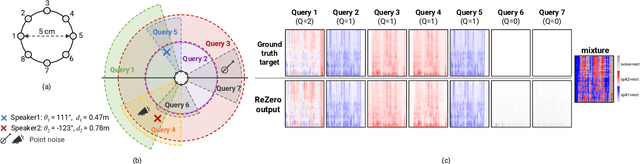

We introduce region-customizable sound extraction (ReZero), a general and flexible framework for the multi-channel region-wise sound extraction (R-SE) task. R-SE task aims at extracting all active target sounds (e.g., human speech) within a specific, user-defined spatial region, which is different from conventional and existing tasks where a blind separation or a fixed, predefined spatial region are typically assumed. The spatial region can be defined as an angular window, a sphere, a cone, or other geometric patterns. Being a solution to the R-SE task, the proposed ReZero framework includes (1) definitions of different types of spatial regions, (2) methods for region feature extraction and aggregation, and (3) a multi-channel extension of the band-split RNN (BSRNN) model specified for the R-SE task. We design experiments for different microphone array geometries, different types of spatial regions, and comprehensive ablation studies on different system configurations. Experimental results on both simulated and real-recorded data demonstrate the effectiveness of ReZero. Demos are available at https://innerselfm.github.io/rezero/.
On Monotonic Aggregation for Open-domain QA
Aug 08, 2023
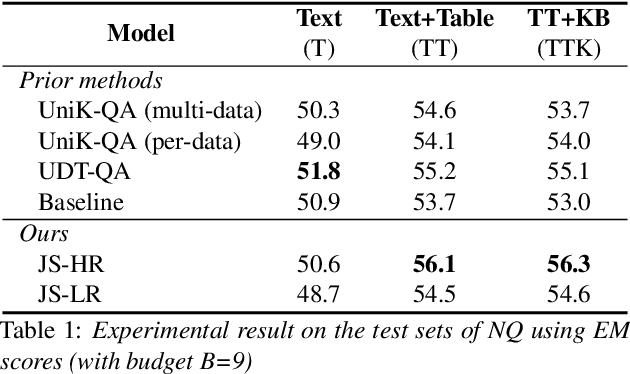
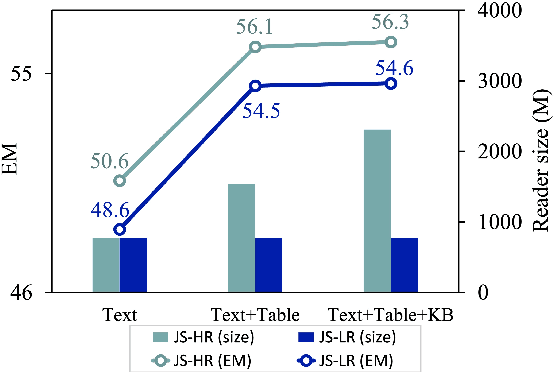
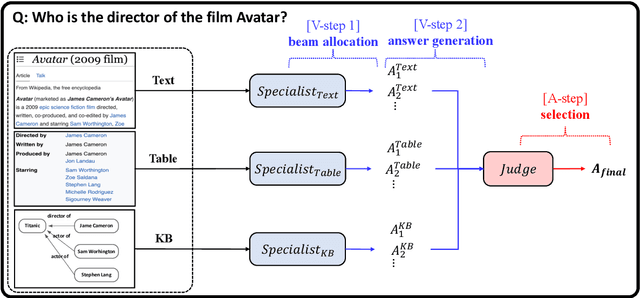
Question answering (QA) is a critical task for speech-based retrieval from knowledge sources, by sifting only the answers without requiring to read supporting documents. Specifically, open-domain QA aims to answer user questions on unrestricted knowledge sources. Ideally, adding a source should not decrease the accuracy, but we find this property (denoted as "monotonicity") does not hold for current state-of-the-art methods. We identify the cause, and based on that we propose Judge-Specialist framework. Our framework consists of (1) specialist retrievers/readers to cover individual sources, and (2) judge, a dedicated language model to select the final answer. Our experiments show that our framework not only ensures monotonicity, but also outperforms state-of-the-art multi-source QA methods on Natural Questions. Additionally, we show that our models robustly preserve the monotonicity against noise from speech recognition. We publicly release our code and setting.
Code-Switched Urdu ASR for Noisy Telephonic Environment using Data Centric Approach with Hybrid HMM and CNN-TDNN
Jul 24, 2023Call Centers have huge amount of audio data which can be used for achieving valuable business insights and transcription of phone calls is manually tedious task. An effective Automated Speech Recognition system can accurately transcribe these calls for easy search through call history for specific context and content allowing automatic call monitoring, improving QoS through keyword search and sentiment analysis. ASR for Call Center requires more robustness as telephonic environment are generally noisy. Moreover, there are many low-resourced languages that are on verge of extinction which can be preserved with help of Automatic Speech Recognition Technology. Urdu is the $10^{th}$ most widely spoken language in the world, with 231,295,440 worldwide still remains a resource constrained language in ASR. Regional call-center conversations operate in local language, with a mix of English numbers and technical terms generally causing a "code-switching" problem. Hence, this paper describes an implementation framework of a resource efficient Automatic Speech Recognition/ Speech to Text System in a noisy call-center environment using Chain Hybrid HMM and CNN-TDNN for Code-Switched Urdu Language. Using Hybrid HMM-DNN approach allowed us to utilize the advantages of Neural Network with less labelled data. Adding CNN with TDNN has shown to work better in noisy environment due to CNN's additional frequency dimension which captures extra information from noisy speech, thus improving accuracy. We collected data from various open sources and labelled some of the unlabelled data after analysing its general context and content from Urdu language as well as from commonly used words from other languages, primarily English and were able to achieve WER of 5.2% with noisy as well as clean environment in isolated words or numbers as well as in continuous spontaneous speech.
VAST: Vivify Your Talking Avatar via Zero-Shot Expressive Facial Style Transfer
Aug 09, 2023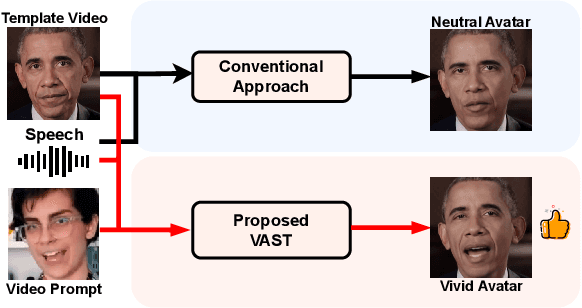

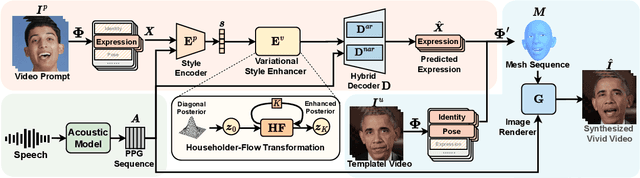
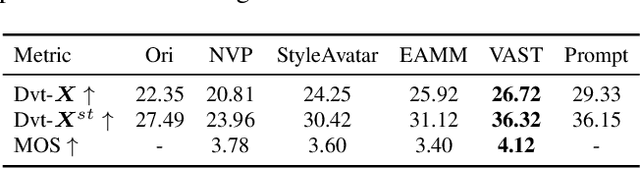
Current talking face generation methods mainly focus on speech-lip synchronization. However, insufficient investigation on the facial talking style leads to a lifeless and monotonous avatar. Most previous works fail to imitate expressive styles from arbitrary video prompts and ensure the authenticity of the generated video. This paper proposes an unsupervised variational style transfer model (VAST) to vivify the neutral photo-realistic avatars. Our model consists of three key components: a style encoder that extracts facial style representations from the given video prompts; a hybrid facial expression decoder to model accurate speech-related movements; a variational style enhancer that enhances the style space to be highly expressive and meaningful. With our essential designs on facial style learning, our model is able to flexibly capture the expressive facial style from arbitrary video prompts and transfer it onto a personalized image renderer in a zero-shot manner. Experimental results demonstrate the proposed approach contributes to a more vivid talking avatar with higher authenticity and richer expressiveness.