 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"speech": models, code, and papers
Evaluating the Effectiveness of Natural Language Inference for Hate Speech Detection in Languages with Limited Labeled Data
Jun 10, 2023
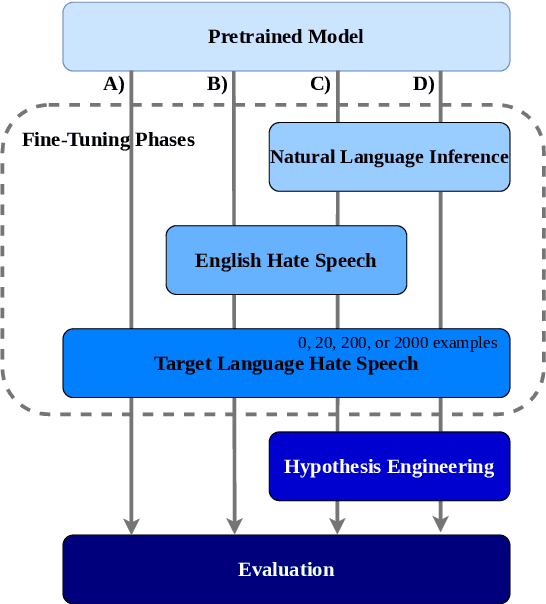
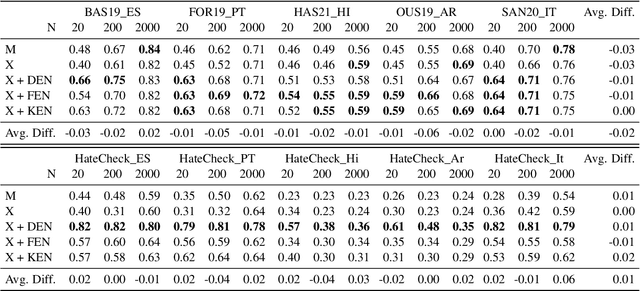
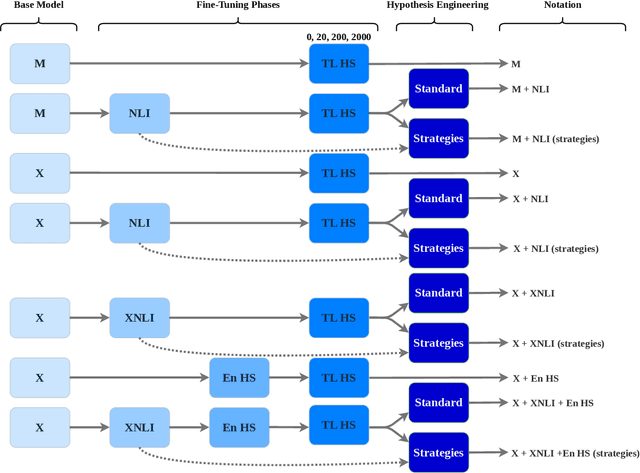

Most research on hate speech detection has focused on English where a sizeable amount of labeled training data is available. However, to expand hate speech detection into more languages, approaches that require minimal training data are needed. In this paper, we test whether natural language inference (NLI) models which perform well in zero- and few-shot settings can benefit hate speech detection performance in scenarios where only a limited amount of labeled data is available in the target language. Our evaluation on five languages demonstrates large performance improvements of NLI fine-tuning over direct fine-tuning in the target language. However, the effectiveness of previous work that proposed intermediate fine-tuning on English data is hard to match. Only in settings where the English training data does not match the test domain, can our customised NLI-formulation outperform intermediate fine-tuning on English. Based on our extensive experiments, we propose a set of recommendations for hate speech detection in languages where minimal labeled training data is available.
On the Efficacy and Noise-Robustness of Jointly Learned Speech Emotion and Automatic Speech Recognition
May 25, 2023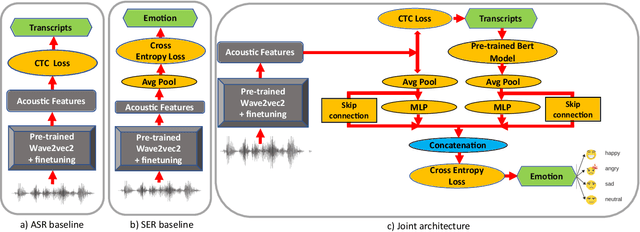
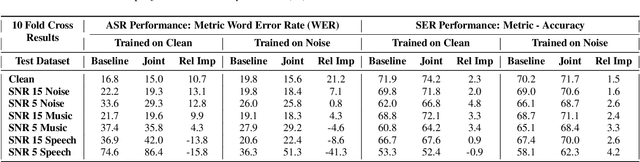
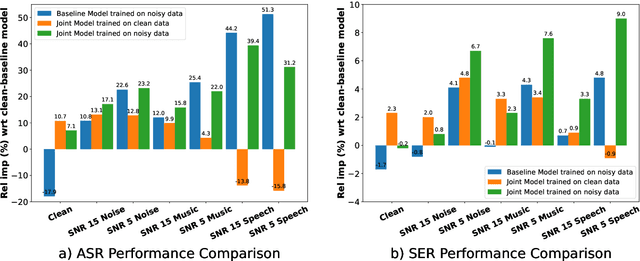
New-age conversational agent systems perform both speech emotion recognition (SER) and automatic speech recognition (ASR) using two separate and often independent approaches for real-world application in noisy environments. In this paper, we investigate a joint ASR-SER multitask learning approach in a low-resource setting and show that improvements are observed not only in SER, but also in ASR. We also investigate the robustness of such jointly trained models to the presence of background noise, babble, and music. Experimental results on the IEMOCAP dataset show that joint learning can improve ASR word error rate (WER) and SER classification accuracy by 10.7% and 2.3% respectively in clean scenarios. In noisy scenarios, results on data augmented with MUSAN show that the joint approach outperforms the independent ASR and SER approaches across many noisy conditions. Overall, the joint ASR-SER approach yielded more noise-resistant models than the independent ASR and SER approaches.
Representation Learning for Audio Privacy Preservation using Source Separation and Robust Adversarial Learning
Aug 09, 2023Privacy preservation has long been a concern in smart acoustic monitoring systems, where speech can be passively recorded along with a target signal in the system's operating environment. In this study, we propose the integration of two commonly used approaches in privacy preservation: source separation and adversarial representation learning. The proposed system learns the latent representation of audio recordings such that it prevents differentiating between speech and non-speech recordings. Initially, the source separation network filters out some of the privacy-sensitive data, and during the adversarial learning process, the system will learn privacy-preserving representation on the filtered signal. We demonstrate the effectiveness of our proposed method by comparing our method against systems without source separation, without adversarial learning, and without both. Overall, our results suggest that the proposed system can significantly improve speech privacy preservation compared to that of using source separation or adversarial learning solely while maintaining good performance in the acoustic monitoring task.
Understanding Spoken Language Development of Children with ASD Using Pre-trained Speech Embeddings
May 23, 2023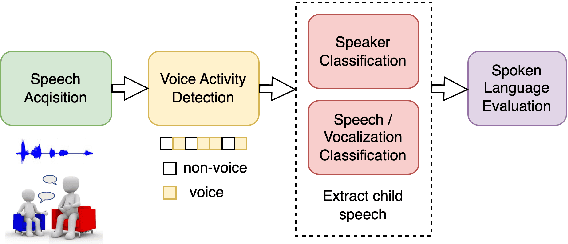

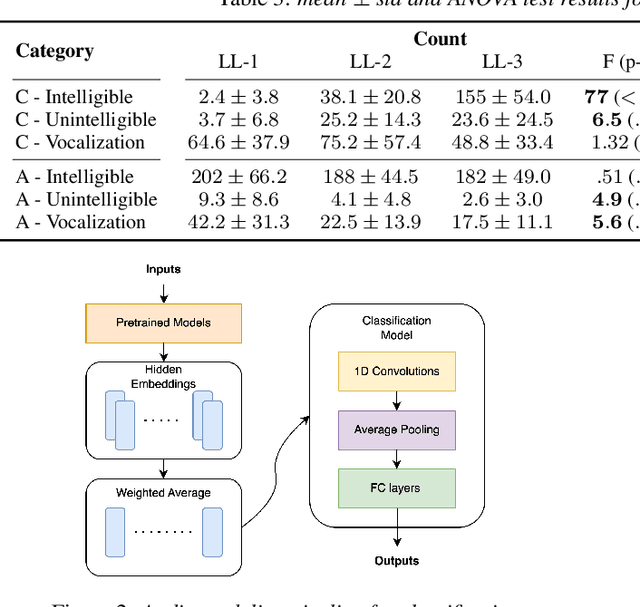
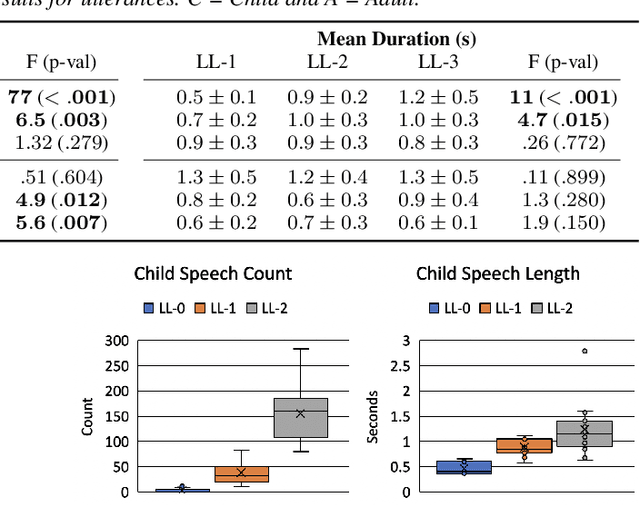
Speech processing techniques are useful for analyzing speech and language development in children with Autism Spectrum Disorder (ASD), who are often varied and delayed in acquiring these skills. Early identification and intervention are crucial, but traditional assessment methodologies such as caregiver reports are not adequate for the requisite behavioral phenotyping. Natural Language Sample (NLS) analysis has gained attention as a promising complement. Researchers have developed benchmarks for spoken language capabilities in children with ASD, obtainable through the analysis of NLS. This paper proposes applications of speech processing technologies in support of automated assessment of children's spoken language development by classification between child and adult speech and between speech and nonverbal vocalization in NLS, with respective F1 macro scores of 82.6% and 67.8%, underscoring the potential for accurate and scalable tools for ASD research and clinical use.
DPHuBERT: Joint Distillation and Pruning of Self-Supervised Speech Models
May 28, 2023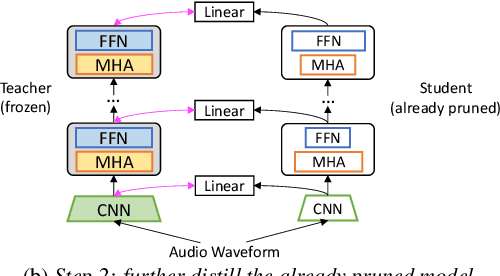
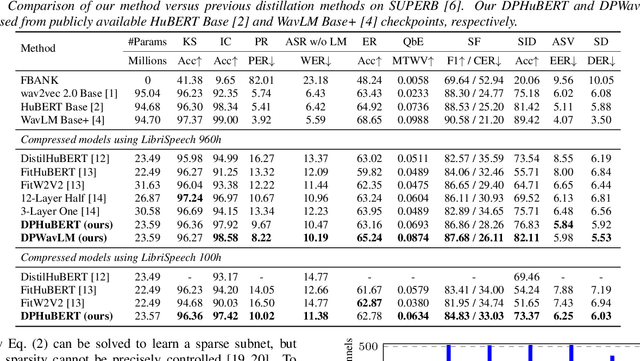
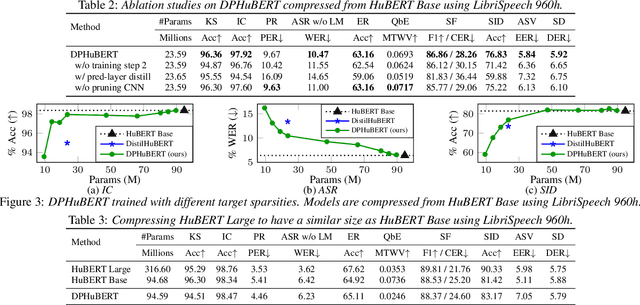
Self-supervised learning (SSL) has achieved notable success in many speech processing tasks, but the large model size and heavy computational cost hinder the deployment. Knowledge distillation trains a small student model to mimic the behavior of a large teacher model. However, the student architecture usually needs to be manually designed and will remain fixed during training, which requires prior knowledge and can lead to suboptimal performance. Inspired by recent success of task-specific structured pruning, we propose DPHuBERT, a novel task-agnostic compression method for speech SSL based on joint distillation and pruning. Experiments on SUPERB show that DPHuBERT outperforms pure distillation methods in almost all tasks. Moreover, DPHuBERT requires little training time and performs well with limited training data, making it suitable for resource-constrained applications. Our method can also be applied to various speech SSL models. Our code and models will be publicly available.
Revisiting Hate Speech Benchmarks: From Data Curation to System Deployment
Jun 01, 2023
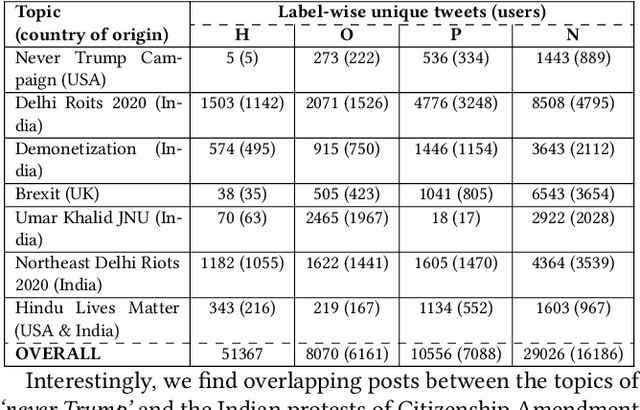
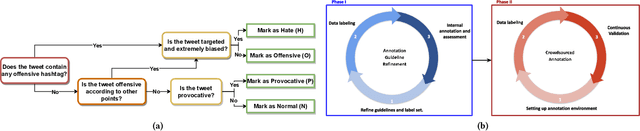
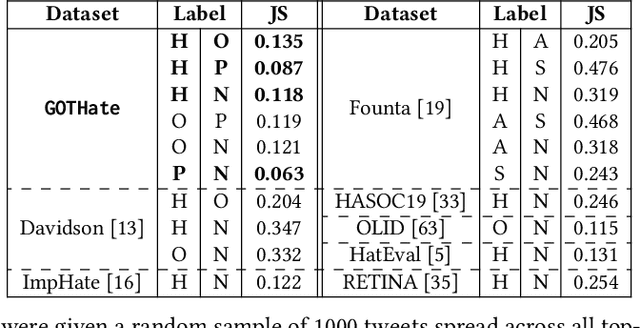
Social media is awash with hateful content, much of which is often veiled with linguistic and topical diversity. The benchmark datasets used for hate speech detection do not account for such divagation as they are predominantly compiled using hate lexicons. However, capturing hate signals becomes challenging in neutrally-seeded malicious content. Thus, designing models and datasets that mimic the real-world variability of hate warrants further investigation. To this end, we present GOTHate, a large-scale code-mixed crowdsourced dataset of around 51k posts for hate speech detection from Twitter. GOTHate is neutrally seeded, encompassing different languages and topics. We conduct detailed comparisons of GOTHate with the existing hate speech datasets, highlighting its novelty. We benchmark it with 10 recent baselines. Our extensive empirical and benchmarking experiments suggest that GOTHate is hard to classify in a text-only setup. Thus, we investigate how adding endogenous signals enhances the hate speech detection task. We augment GOTHate with the user's timeline information and ego network, bringing the overall data source closer to the real-world setup for understanding hateful content. Our proposed solution HEN-mBERT is a modular, multilingual, mixture-of-experts model that enriches the linguistic subspace with latent endogenous signals from history, topology, and exemplars. HEN-mBERT transcends the best baseline by 2.5% and 5% in overall macro-F1 and hate class F1, respectively. Inspired by our experiments, in partnership with Wipro AI, we are developing a semi-automated pipeline to detect hateful content as a part of their mission to tackle online harm.
Detecting Throat Cancer from Speech Signals Using Machine Learning: A Reproducible Literature Review
Jul 18, 2023In this work we perform a scoping review of the current literature on the detection of throat cancer from speech recordings using machine learning and artificial intelligence. We find 22 papers within this area and discuss their methods and results. We split these papers into two groups - nine performing binary classification, and 13 performing multi-class classification. The papers present a range of methods with neural networks being most commonly implemented. Many features are also extracted from the audio before classification, with the most common bring mel-frequency cepstral coefficients. None of the papers found in this search have associated code repositories and as such are not reproducible. Therefore, we create a publicly available code repository of our own classifiers. We use transfer learning on a multi-class problem, classifying three pathologies and healthy controls. Using this technique we achieve an unweighted average recall of 53.54%, sensitivity of 83.14%, and specificity of 64.00%. We compare our classifiers with the results obtained on the same dataset and find similar results.
RedPenNet for Grammatical Error Correction: Outputs to Tokens, Attentions to Spans
Sep 19, 2023The text editing tasks, including sentence fusion, sentence splitting and rephrasing, text simplification, and Grammatical Error Correction (GEC), share a common trait of dealing with highly similar input and output sequences. This area of research lies at the intersection of two well-established fields: (i) fully autoregressive sequence-to-sequence approaches commonly used in tasks like Neural Machine Translation (NMT) and (ii) sequence tagging techniques commonly used to address tasks such as Part-of-speech tagging, Named-entity recognition (NER), and similar. In the pursuit of a balanced architecture, researchers have come up with numerous imaginative and unconventional solutions, which we're discussing in the Related Works section. Our approach to addressing text editing tasks is called RedPenNet and is aimed at reducing architectural and parametric redundancies presented in specific Sequence-To-Edits models, preserving their semi-autoregressive advantages. Our models achieve $F_{0.5}$ scores of 77.60 on the BEA-2019 (test), which can be considered as state-of-the-art the only exception for system combination and 67.71 on the UAGEC+Fluency (test) benchmarks. This research is being conducted in the context of the UNLP 2023 workshop, where it was presented as a paper as a paper for the Shared Task in Grammatical Error Correction (GEC) for Ukrainian. This study aims to apply the RedPenNet approach to address the GEC problem in the Ukrainian language.
Parameter-efficient Dysarthric Speech Recognition Using Adapter Fusion and Householder Transformation
Jun 12, 2023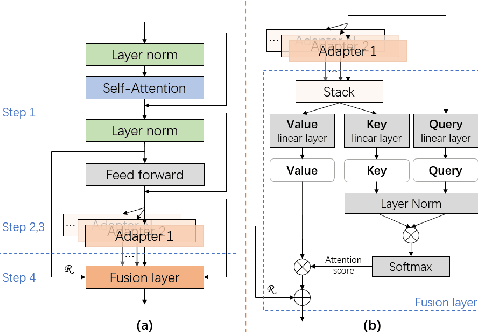
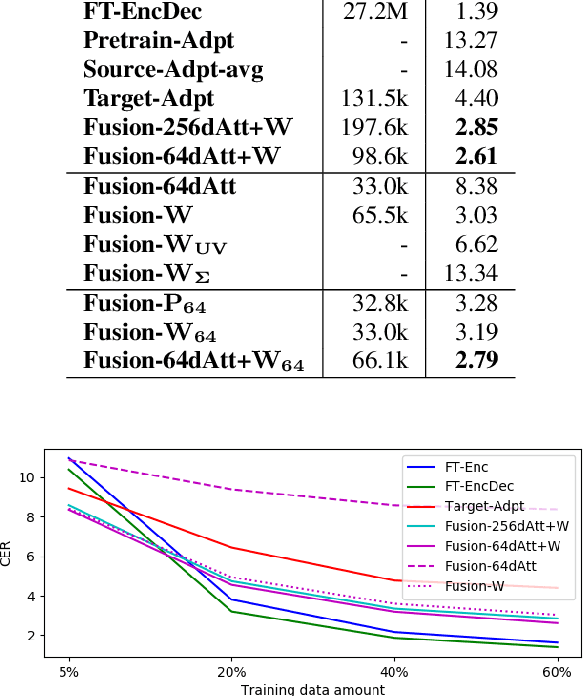

In dysarthric speech recognition, data scarcity and the vast diversity between dysarthric speakers pose significant challenges. While finetuning has been a popular solution, it can lead to overfitting and low parameter efficiency. Adapter modules offer a better solution, with their small size and easy applicability. Additionally, Adapter Fusion can facilitate knowledge transfer from multiple learned adapters, but may employ more parameters. In this work, we apply Adapter Fusion for target speaker adaptation and speech recognition, achieving acceptable accuracy with significantly fewer speaker-specific trainable parameters than classical finetuning methods. We further improve the parameter efficiency of the fusion layer by reducing the size of query and key layers and using Householder transformation to reparameterize the value linear layer. Our proposed fusion layer achieves comparable recognition results to the original method with only one third of the parameters.
Towards Speech Dialogue Translation Mediating Speakers of Different Languages
May 22, 2023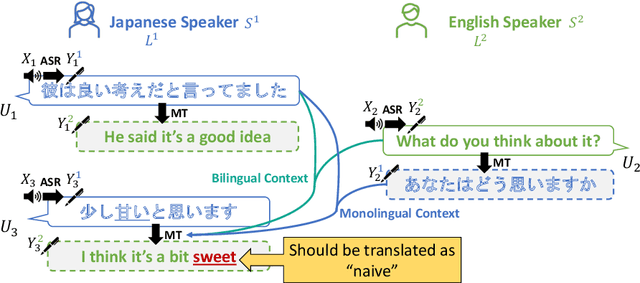
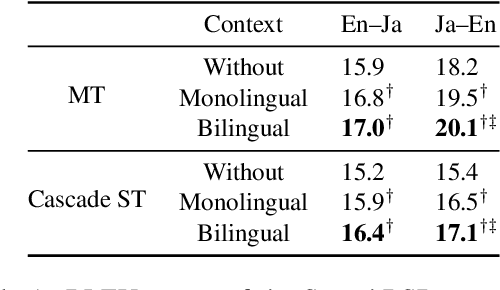
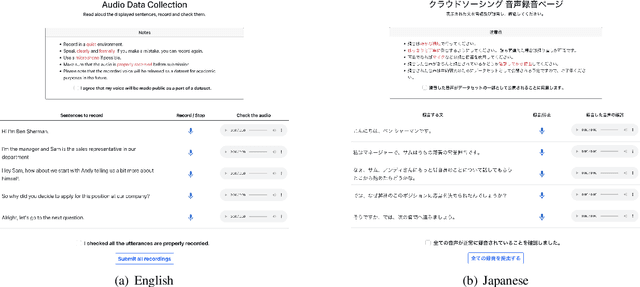
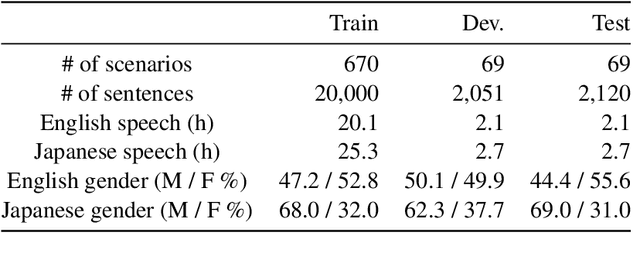
We present a new task, speech dialogue translation mediating speakers of different languages. We construct the SpeechBSD dataset for the task and conduct baseline experiments. Furthermore, we consider context to be an important aspect that needs to be addressed in this task and propose two ways of utilizing context, namely monolingual context and bilingual context. We conduct cascaded speech translation experiments using Whisper and mBART, and show that bilingual context performs better in our settings.