 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMaking Multi-Axis Models Robust to Multiplicative Noise: How, and Why?
Mar 27, 2026In this paper we develop a graph-learning algorithm, MED-MAGMA, to fit multi-axis (Kronecker-sum-structured) models corrupted by multiplicative noise. This type of noise is natural in many application domains, such as that of single-cell RNA sequencing, in which it naturally captures technical biases of RNA sequencing platforms. Our work is evaluated against prior work on each and every public dataset in the Single Cell Expression Atlas under a certain size, demonstrating that our methodology learns networks with better local and global structure. MED-MAGMA is made available as a Python package (MED-MAGMA).
A Classification Benchmark for Artificial Intelligence Detection of Laryngeal Cancer from Patient Speech
Dec 20, 2024



Cases of laryngeal cancer are predicted to rise significantly in the coming years. Current diagnostic pathways cause many patients to be incorrectly referred to urgent suspected cancer pathways, putting undue stress on both patients and the medical system. Artificial intelligence offers a promising solution by enabling non-invasive detection of laryngeal cancer from patient speech, which could help prioritise referrals more effectively and reduce inappropriate referrals of non-cancer patients. To realise this potential, open science is crucial. A major barrier in this field is the lack of open-source datasets and reproducible benchmarks, forcing researchers to start from scratch. Our work addresses this challenge by introducing a benchmark suite comprising 36 models trained and evaluated on open-source datasets. These models are accessible in a public repository, providing a foundation for future research. They evaluate three different algorithms and three audio feature sets, offering a comprehensive benchmarking framework. We propose standardised metrics and evaluation methodologies to ensure consistent and comparable results across future studies. The presented models include both audio-only inputs and multimodal inputs that incorporate demographic and symptom data, enabling their application to datasets with diverse patient information. By providing these benchmarks, future researchers can evaluate their datasets, refine the models, and use them as a foundation for more advanced approaches. This work aims to provide a baseline for establishing reproducible benchmarks, enabling researchers to compare new methods against these standards and ultimately advancing the development of AI tools for detecting laryngeal cancer.
Graphical Modelling without Independence Assumptions for Uncentered Data
Aug 05, 2024The independence assumption is a useful tool to increase the tractability of one's modelling framework. However, this assumption does not match reality; failing to take dependencies into account can cause models to fail dramatically. The field of multi-axis graphical modelling (also called multi-way modelling, Kronecker-separable modelling) has seen growth over the past decade, but these models require that the data have zero mean. In the multi-axis case, inference is typically done in the single sample scenario, making mean inference impossible. In this paper, we demonstrate how the zero-mean assumption can cause egregious modelling errors, as well as propose a relaxation to the zero-mean assumption that allows the avoidance of such errors. Specifically, we propose the "Kronecker-sum-structured mean" assumption, which leads to models with nonconvex-but-unimodal log-likelihoods that can be solved efficiently with coordinate descent.
Making Multi-Axis Gaussian Graphical Models Scalable to Millions of Samples and Features
Jul 29, 2024



Gaussian graphical models can be used to extract conditional dependencies between the features of the dataset. This is often done by making an independence assumption about the samples, but this assumption is rarely satisfied in reality. However, state-of-the-art approaches that avoid this assumption are not scalable, with $O(n^3)$ runtime and $O(n^2)$ space complexity. In this paper, we introduce a method that has $O(n^2)$ runtime and $O(n)$ space complexity, without assuming independence. We validate our model on both synthetic and real-world datasets, showing that our method's accuracy is comparable to that of prior work We demonstrate that our approach can be used on unprecedentedly large datasets, such as a real-world 1,000,000-cell scRNA-seq dataset; this was impossible with previous approaches. Our method maintains the flexibility of prior work, such as the ability to handle multi-modal tensor-variate datasets and the ability to work with data of arbitrary marginal distributions. An additional advantage of our method is that, unlike prior work, our hyperparameters are easily interpretable.
Detecting Throat Cancer from Speech Signals Using Machine Learning: A Reproducible Literature Review
Jul 18, 2023



In this work we perform a scoping review of the current literature on the detection of throat cancer from speech recordings using machine learning and artificial intelligence. We find 22 papers within this area and discuss their methods and results. We split these papers into two groups - nine performing binary classification, and 13 performing multi-class classification. The papers present a range of methods with neural networks being most commonly implemented. Many features are also extracted from the audio before classification, with the most common bring mel-frequency cepstral coefficients. None of the papers found in this search have associated code repositories and as such are not reproducible. Therefore, we create a publicly available code repository of our own classifiers. We use transfer learning on a multi-class problem, classifying three pathologies and healthy controls. Using this technique we achieve an unweighted average recall of 53.54%, sensitivity of 83.14%, and specificity of 64.00%. We compare our classifiers with the results obtained on the same dataset and find similar results.
antGLasso: An Efficient Tensor Graphical Lasso Algorithm
Nov 05, 2022The class of bigraphical lasso algorithms (and, more broadly, 'tensor'-graphical lasso algorithms) has been used to estimate dependency structures within matrix and tensor data. However, all current methods to do so take prohibitively long on modestly sized datasets. We present a novel tensor-graphical lasso algorithm that analytically estimates the dependency structure, unlike its iterative predecessors. This provides a speedup of multiple orders of magnitude, allowing this class of algorithms to be used on large, real-world datasets.
Scalable Bigraphical Lasso: Two-way Sparse Network Inference for Count Data
Mar 15, 2022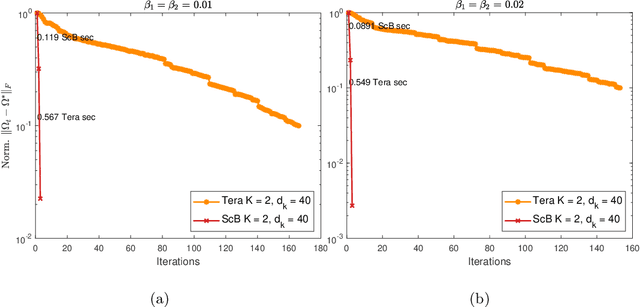
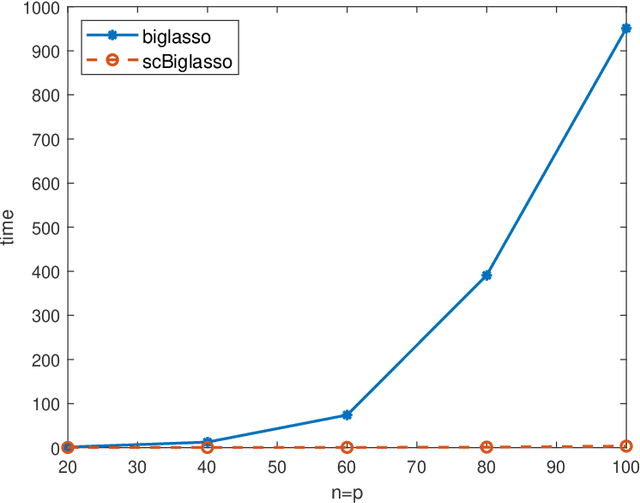
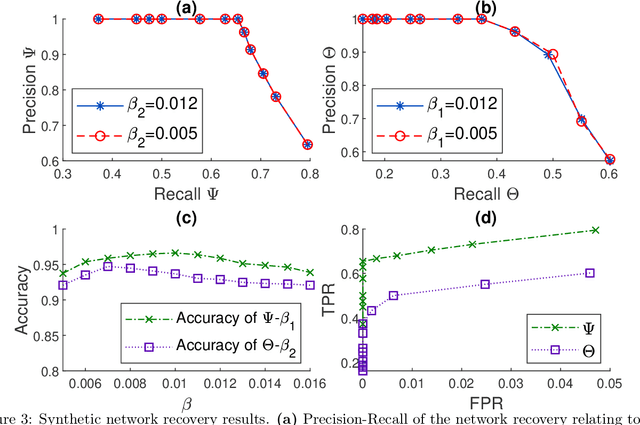
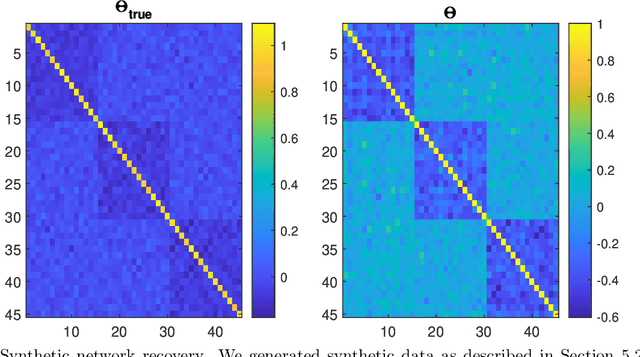
Classically, statistical datasets have a larger number of data points than features ($n > p$). The standard model of classical statistics caters for the case where data points are considered conditionally independent given the parameters. However, for $n\approx p$ or $p > n$ such models are poorly determined. Kalaitzis et al. (2013) introduced the Bigraphical Lasso, an estimator for sparse precision matrices based on the Cartesian product of graphs. Unfortunately, the original Bigraphical Lasso algorithm is not applicable in case of large p and n due to memory requirements. We exploit eigenvalue decomposition of the Cartesian product graph to present a more efficient version of the algorithm which reduces memory requirements from $O(n^2p^2)$ to $O(n^2 + p^2)$. Many datasets in different application fields, such as biology, medicine and social science, come with count data, for which Gaussian based models are not applicable. Our multi-way network inference approach can be used for discrete data. Our methodology accounts for the dependencies across both instances and features, reduces the computational complexity for high dimensional data and enables to deal with both discrete and continuous data. Numerical studies on both synthetic and real datasets are presented to showcase the performance of our method.
Network Clustering by Embedding of Attribute-augmented Graphs
Sep 29, 2021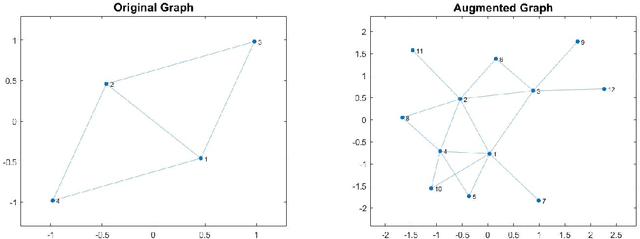
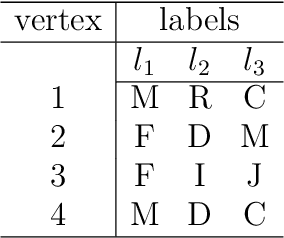
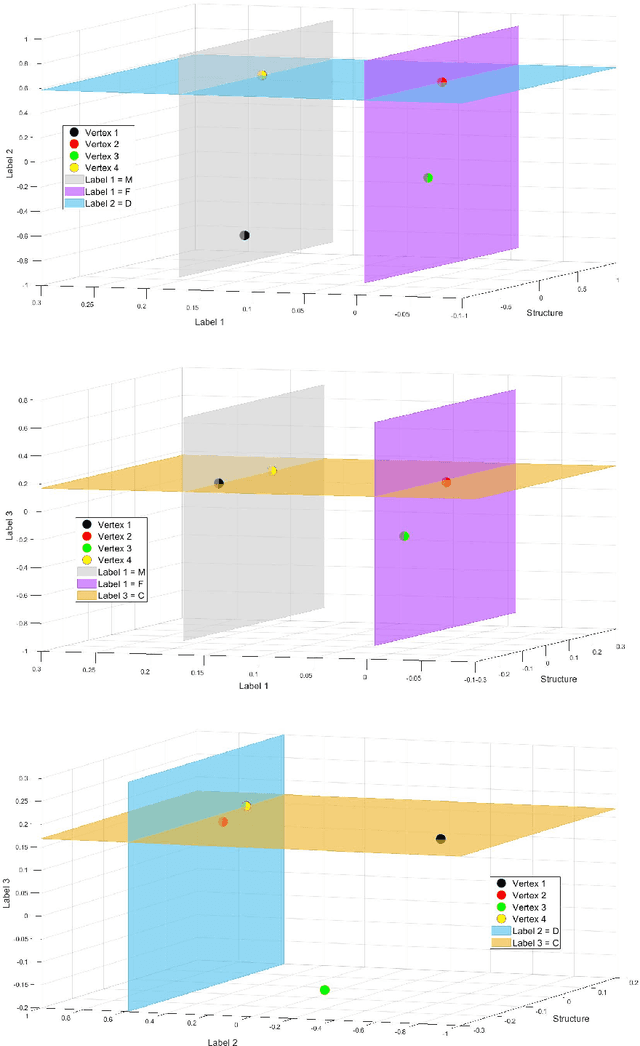
In this paper we propose a new approach to detect clusters in undirected graphs with attributed vertices. The aim is to group vertices which are similar not only in terms of structural connectivity but also in terms of attribute values. We incorporate structural and attribute similarities between the vertices in an augmented graph by creating additional vertices and edges as proposed in [5, 27]. The augmented graph is embedded in a Euclidean space associated to its Laplacian and apply a modified K-means algorithm to identify clusters. The modified K-means uses a vector distance measure where to each original vertex is assigned a vector-valued set of coordinates depending on both structural connectivity and attribute similarities. To define the coordinate vectors we employ an adaptive AMG (Algebraic MultiGrid) method to identify the coordinate directions in the embedding Euclidean space extending our previous result for graphs without attributes. We demonstrate the effectiveness of our proposed clustering method on both synthetic and real-world attributed graphs.