 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"speech recognition": models, code, and papers
StutterNet: Stuttering Detection Using Time Delay Neural Network
May 12, 2021
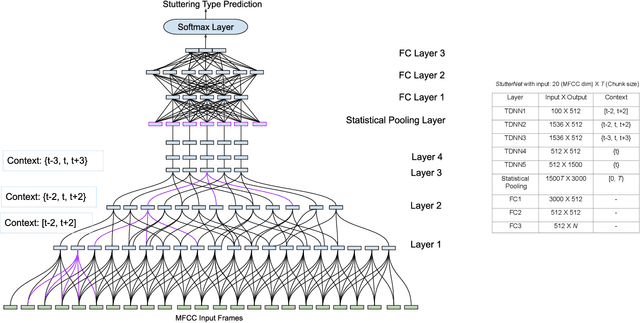
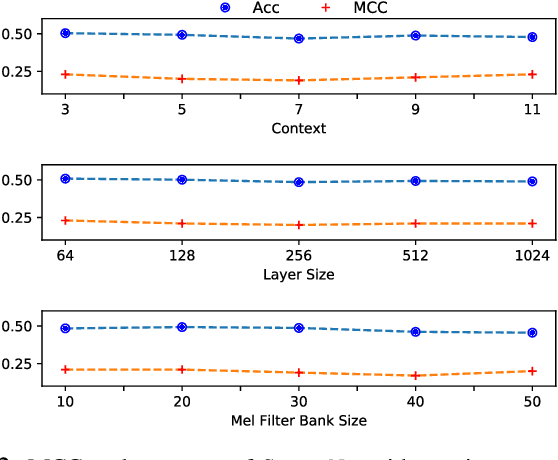
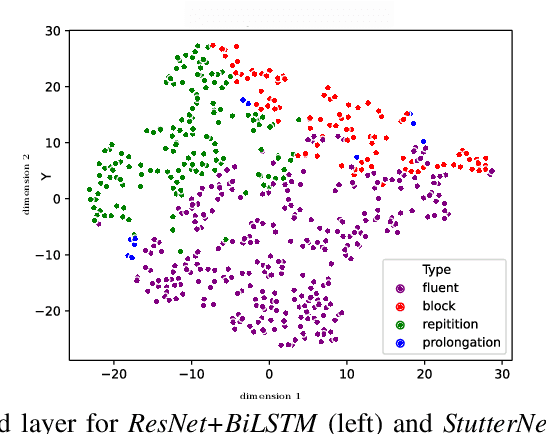

This paper introduce StutterNet, a novel deep learning based stuttering detection capable of detecting and identifying various types of disfluencies. Most of the existing work in this domain uses automatic speech recognition (ASR) combined with language models for stuttering detection. Compared to the existing work, which depends on the ASR module, our method relies solely on the acoustic signal. We use a time-delay neural network (TDNN) suitable for capturing contextual aspects of the disfluent utterances. We evaluate our system on the UCLASS stuttering dataset consisting of more than 100 speakers. Our method achieves promising results and outperforms the state-of-the-art residual neural network based method. The number of trainable parameters of the proposed method is also substantially less due to the parameter sharing scheme of TDNN.
Grammar Based Identification Of Speaker Role For Improving ATCO And Pilot ASR
Aug 27, 2021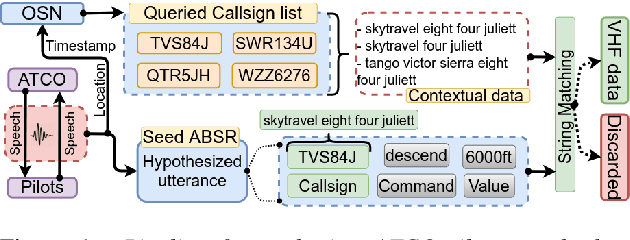



Assistant Based Speech Recognition (ABSR) for air traffic control is generally trained by pooling both Air Traffic Controller (ATCO) and pilot data. In practice, this is motivated by the fact that the proportion of pilot data is lesser compared to ATCO while their standard language of communication is similar. However, due to data imbalance of ATCO and pilot and their varying acoustic conditions, the ASR performance is usually significantly better for ATCOs than pilots. In this paper, we propose to (1) split the ATCO and pilot data using an automatic approach exploiting ASR transcripts, and (2) consider ATCO and pilot ASR as two separate tasks for Acoustic Model (AM) training. For speaker role classification of ATCO and pilot data, a hypothesized ASR transcript is generated with a seed model, subsequently used to classify the speaker role based on the knowledge extracted from grammar defined by International Civil Aviation Organization (ICAO). This approach provides an average speaker role identification accuracy of 83% for ATCO and pilot. Finally, we show that training AMs separately for each task, or using a multitask approach is well suited for this data compared to AM trained by pooling all data.
XY Neural Networks
Mar 31, 2021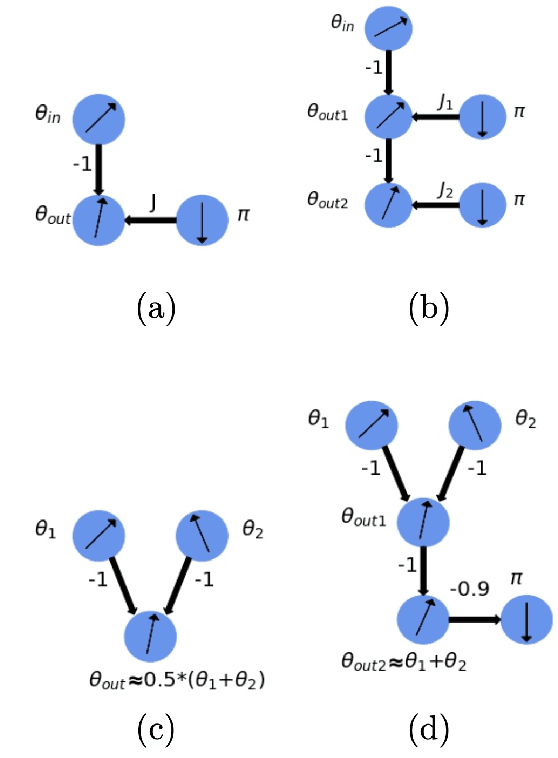
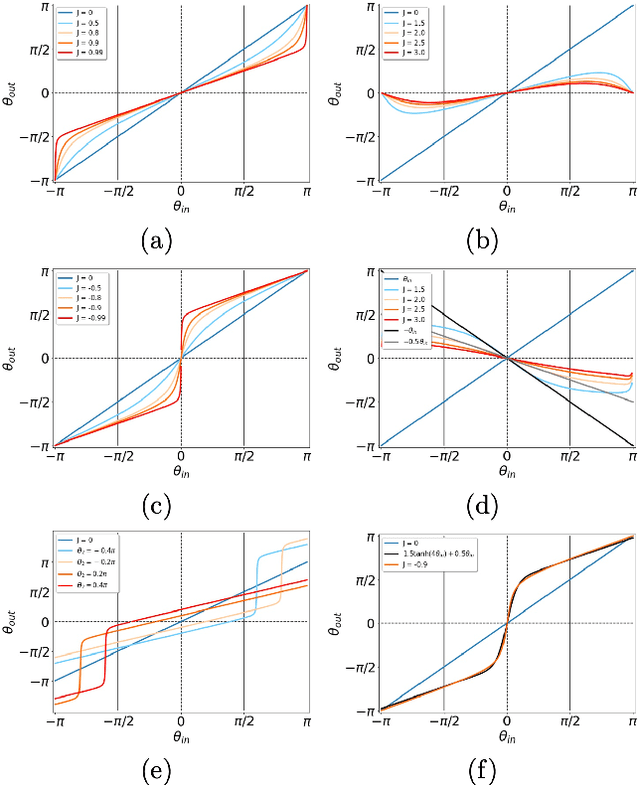
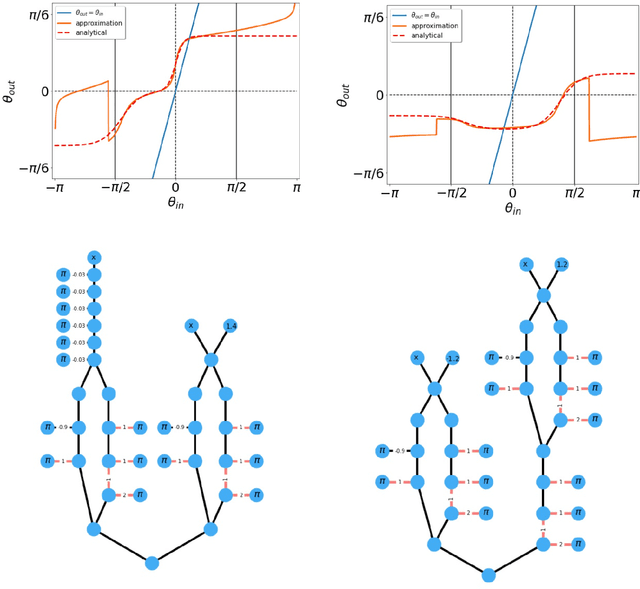
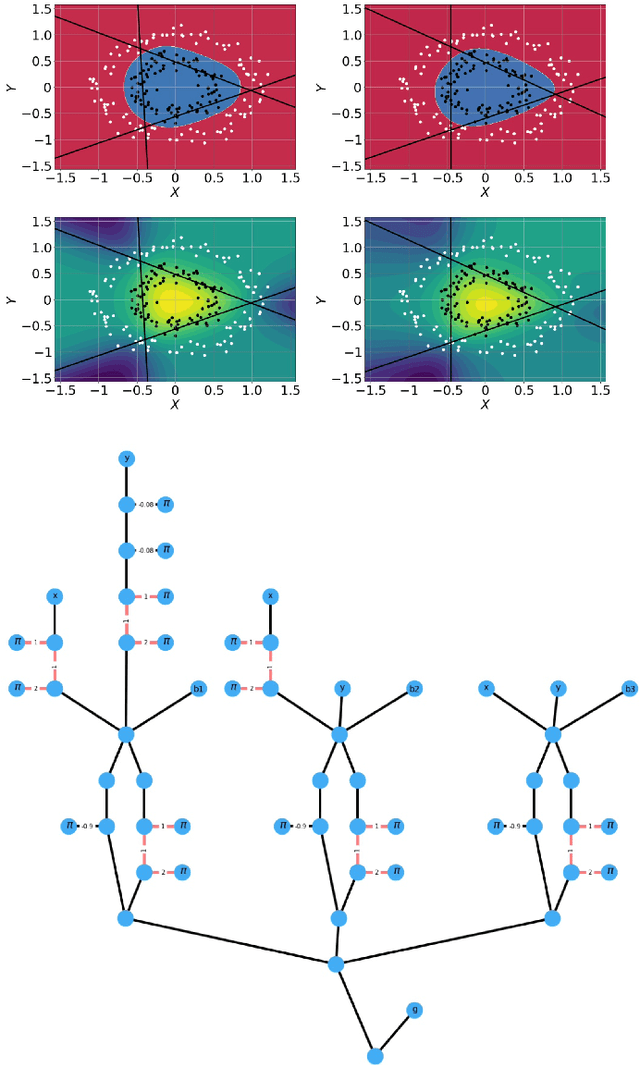
The classical XY model is a lattice model of statistical mechanics notable for its universality in the rich hierarchy of the optical, laser and condensed matter systems. We show how to build complex structures for machine learning based on the XY model's nonlinear blocks. The final target is to reproduce the deep learning architectures, which can perform complicated tasks usually attributed to such architectures: speech recognition, visual processing, or other complex classification types with high quality. We developed the robust and transparent approach for the construction of such models, which has universal applicability (i.e. does not strongly connect to any particular physical system), allows many possible extensions while at the same time preserving the simplicity of the methodology.
Semantic sentence similarity: size does not always matter
Jun 16, 2021
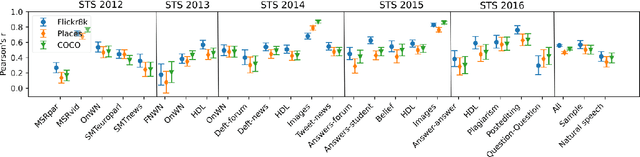
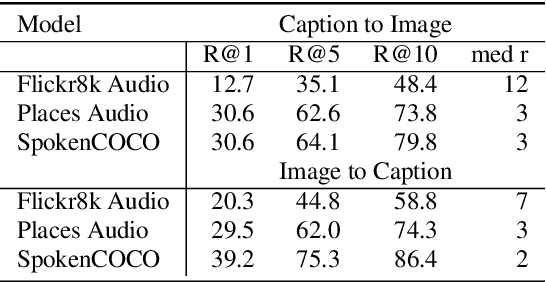
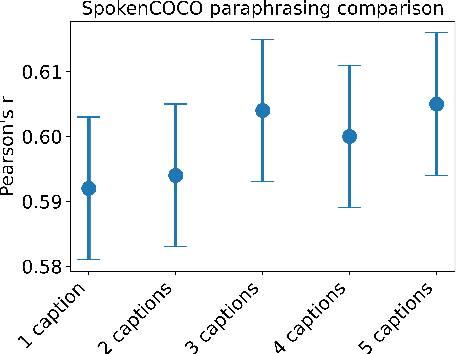
This study addresses the question whether visually grounded speech recognition (VGS) models learn to capture sentence semantics without access to any prior linguistic knowledge. We produce synthetic and natural spoken versions of a well known semantic textual similarity database and show that our VGS model produces embeddings that correlate well with human semantic similarity judgements. Our results show that a model trained on a small image-caption database outperforms two models trained on much larger databases, indicating that database size is not all that matters. We also investigate the importance of having multiple captions per image and find that this is indeed helpful even if the total number of images is lower, suggesting that paraphrasing is a valuable learning signal. While the general trend in the field is to create ever larger datasets to train models on, our findings indicate other characteristics of the database can just as important important.
PDAugment: Data Augmentation by Pitch and Duration Adjustments for Automatic Lyrics Transcription
Sep 17, 2021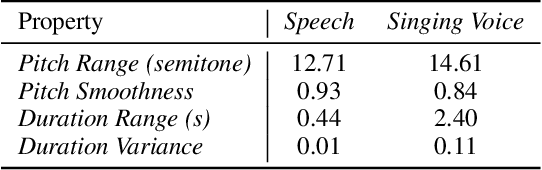
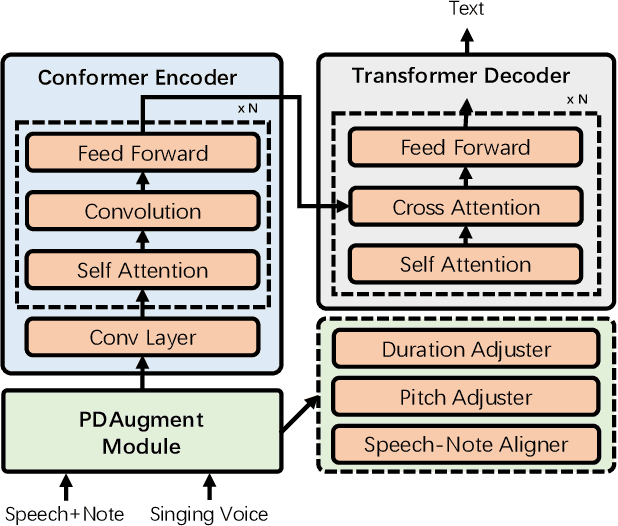
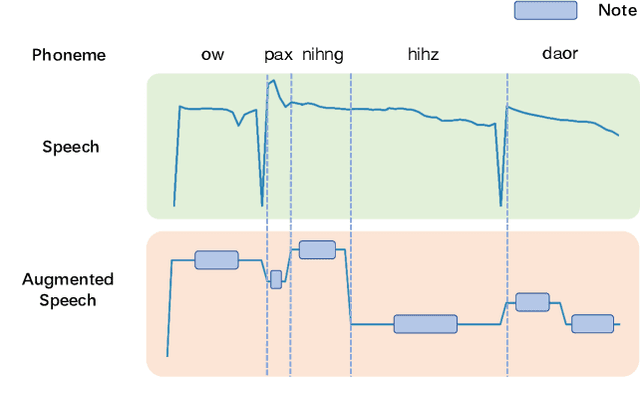

Automatic lyrics transcription (ALT), which can be regarded as automatic speech recognition (ASR) on singing voice, is an interesting and practical topic in academia and industry. ALT has not been well developed mainly due to the dearth of paired singing voice and lyrics datasets for model training. Considering that there is a large amount of ASR training data, a straightforward method is to leverage ASR data to enhance ALT training. However, the improvement is marginal when training the ALT system directly with ASR data, because of the gap between the singing voice and standard speech data which is rooted in music-specific acoustic characteristics in singing voice. In this paper, we propose PDAugment, a data augmentation method that adjusts pitch and duration of speech at syllable level under the guidance of music scores to help ALT training. Specifically, we adjust the pitch and duration of each syllable in natural speech to those of the corresponding note extracted from music scores, so as to narrow the gap between natural speech and singing voice. Experiments on DSing30 and Dali corpus show that the ALT system equipped with our PDAugment outperforms previous state-of-the-art systems by 5.9% and 18.1% WERs respectively, demonstrating the effectiveness of PDAugment for ALT.
Muddling Label Regularization: Deep Learning for Tabular Datasets
Jun 29, 2021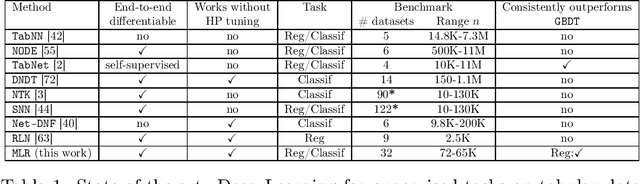


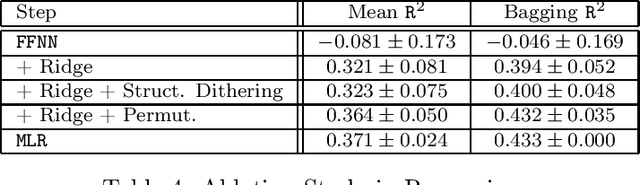
Deep Learning (DL) is considered the state-of-the-art in computer vision, speech recognition and natural language processing. Until recently, it was also widely accepted that DL is irrelevant for learning tasks on tabular data, especially in the small sample regime where ensemble methods are acknowledged as the gold standard. We present a new end-to-end differentiable method to train a standard FFNN. Our method, \textbf{Muddling labels for Regularization} (\texttt{MLR}), penalizes memorization through the generation of uninformative labels and the application of a differentiable close-form regularization scheme on the last hidden layer during training. \texttt{MLR} outperforms classical NN and the gold standard (GBDT, RF) for regression and classification tasks on several datasets from the UCI database and Kaggle covering a large range of sample sizes and feature to sample ratios. Researchers and practitioners can use \texttt{MLR} on its own as an off-the-shelf \DL{} solution or integrate it into the most advanced ML pipelines.
Unsupervised Domain Adaptation Schemes for Building ASR in Low-resource Languages
Sep 16, 2021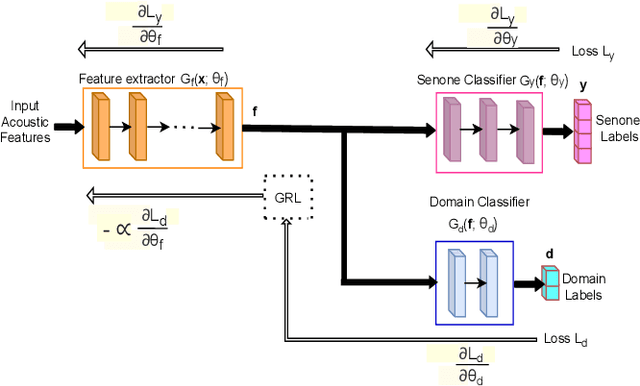
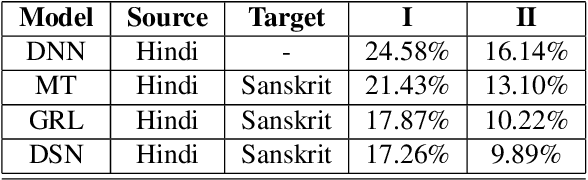
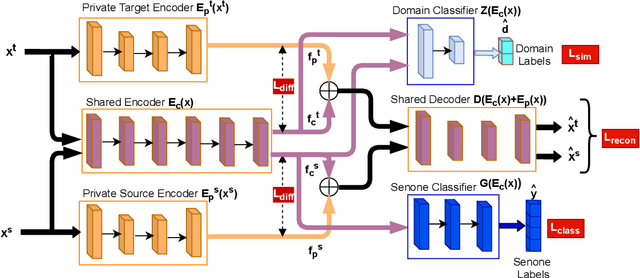
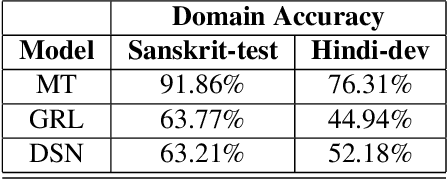
Building an automatic speech recognition (ASR) system from scratch requires a large amount of annotated speech data, which is difficult to collect in many languages. However, there are cases where the low-resource language shares a common acoustic space with a high-resource language having enough annotated data to build an ASR. In such cases, we show that the domain-independent acoustic models learned from the high-resource language through unsupervised domain adaptation (UDA) schemes can enhance the performance of the ASR in the low-resource language. We use the specific example of Hindi in the source domain and Sanskrit in the target domain. We explore two architectures: i) domain adversarial training using gradient reversal layer (GRL) and ii) domain separation networks (DSN). The GRL and DSN architectures give absolute improvements of 6.71% and 7.32%, respectively, in word error rate over the baseline deep neural network model when trained on just 5.5 hours of data in the target domain. We also show that choosing a proper language (Telugu) in the source domain can bring further improvement. The results suggest that UDA schemes can be helpful in the development of ASR systems for low-resource languages, mitigating the hassle of collecting large amounts of annotated speech data.
Kurdish (Sorani) Speech to Text: Presenting an Experimental Dataset
Dec 02, 2019
We present an experimental dataset, Basic Dataset for Sorani Kurdish Automatic Speech Recognition (BD-4SK-ASR), which we used in the first attempt in developing an automatic speech recognition for Sorani Kurdish. The objective of the project was to develop a system that automatically could recognize simple sentences based on the vocabulary which is used in grades one to three of the primary schools in the Kurdistan Region of Iraq. We used CMUSphinx as our experimental environment. We developed a dataset to train the system. The dataset is publicly available for non-commercial use under the CC BY-NC-SA 4.0 license.
The USTC-NEL Speech Translation system at IWSLT 2018
Dec 06, 2018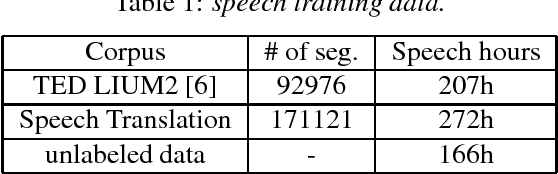
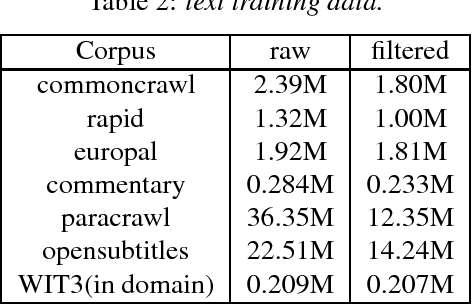
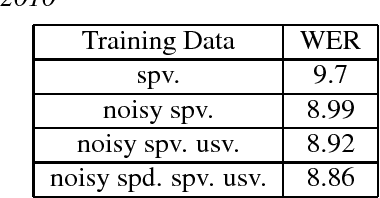

This paper describes the USTC-NEL system to the speech translation task of the IWSLT Evaluation 2018. The system is a conventional pipeline system which contains 3 modules: speech recognition, post-processing and machine translation. We train a group of hybrid-HMM models for our speech recognition, and for machine translation we train transformer based neural machine translation models with speech recognition output style text as input. Experiments conducted on the IWSLT 2018 task indicate that, compared to baseline system from KIT, our system achieved 14.9 BLEU improvement.
On Knowledge Distillation for Direct Speech Translation
Dec 09, 2020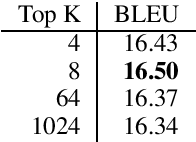

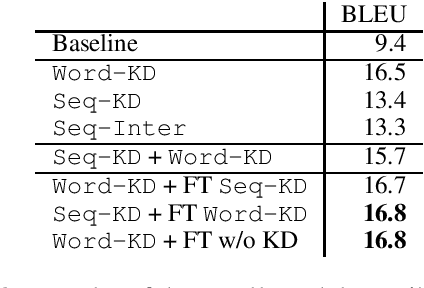

Direct speech translation (ST) has shown to be a complex task requiring knowledge transfer from its sub-tasks: automatic speech recognition (ASR) and machine translation (MT). For MT, one of the most promising techniques to transfer knowledge is knowledge distillation. In this paper, we compare the different solutions to distill knowledge in a sequence-to-sequence task like ST. Moreover, we analyze eventual drawbacks of this approach and how to alleviate them maintaining the benefits in terms of translation quality.