 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTest-Time Compute Scaling for ASR with Depth-Conditioned Looped Transformers
Jun 03, 2026End-to-end ASR systems typically use fixed-depth acoustic encoders at inference, making it difficult to trade additional test-time computation for improved recognition without training a larger model. A natural approach is to reuse a shared Transformer block recurrently, but we find that naive looping does not fully exploit additional recurrent compute. We introduce LARM, a depth-conditioned looped Transformer that turns recurrent encoder depth into a controllable test-time compute axis. LARM combines sparse CTC checkpoints, supervision-clock embeddings, FiLM depth conditioning, and delayed soft-posterior feedback. These components structure the loop into recognition checkpoints separated by latent refinement phases and allow shared weights to specialize across recurrent steps. On LibriSpeech, LARM improves WER as the number of inference loops increases and achieves performance competitive with deeper unshared-parameter baselines. Our results show that test-time compute scaling can extend beyond autoregressive language-model reasoning to continuous non-autoregressive speech recognition.
Deep Learning for Pathological Speech: A Survey
Jan 07, 2025


Advancements in spoken language technologies for neurodegenerative speech disorders are crucial for meeting both clinical and technological needs. This overview paper is vital for advancing the field, as it presents a comprehensive review of state-of-the-art methods in pathological speech detection, automatic speech recognition, pathological speech intelligibility enhancement, intelligibility and severity assessment, and data augmentation approaches for pathological speech. It also high-lights key challenges, such as ensuring robustness, privacy, and interpretability. The paper concludes by exploring promising future directions, including the adoption of multimodal approaches and the integration of graph neural networks and large language models to further advance speech technology for neurodegenerative speech disorders
Graph Neural Networks for Parkinsons Disease Detection
Sep 12, 2024



Despite the promising performance of state of the art approaches for Parkinsons Disease (PD) detection, these approaches often analyze individual speech segments in isolation, which can lead to suboptimal results. Dysarthric cues that characterize speech impairments from PD patients are expected to be related across segments from different speakers. Isolated segment analysis fails to exploit these inter segment relationships. Additionally, not all speech segments from PD patients exhibit clear dysarthric symptoms, introducing label noise that can negatively affect the performance and generalizability of current approaches. To address these challenges, we propose a novel PD detection framework utilizing Graph Convolutional Networks (GCNs). By representing speech segments as nodes and capturing the similarity between segments through edges, our GCN model facilitates the aggregation of dysarthric cues across the graph, effectively exploiting segment relationships and mitigating the impact of label noise. Experimental results demonstrate theadvantages of the proposed GCN model for PD detection and provide insights into its underlying mechanisms
Impact of Speech Mode in Automatic Pathological Speech Detection
Jun 14, 2024
Automatic pathological speech detection approaches yield promising results in identifying various pathologies. These approaches are typically designed and evaluated for phonetically-controlled speech scenarios, where speakers are prompted to articulate identical phonetic content. While gathering controlled speech recordings can be laborious, spontaneous speech can be conveniently acquired as potential patients navigate their daily routines. Further, spontaneous speech can be valuable in detecting subtle and abstract cues of pathological speech. Nonetheless, the efficacy of automatic pathological speech detection for spontaneous speech remains unexplored. This paper analyzes the influence of speech mode on pathological speech detection approaches, examining two distinct categories of approaches, i.e., classical machine learning and deep learning. Results indicate that classical approaches may struggle to capture pathology-discriminant cues in spontaneous speech. In contrast, deep learning approaches demonstrate superior performance, managing to extract additional cues that were previously inaccessible in non-spontaneous speech
Stuttering Detection Using Speaker Representations and Self-supervised Contextual Embeddings
Jun 01, 2023The adoption of advanced deep learning architectures in stuttering detection (SD) tasks is challenging due to the limited size of the available datasets. To this end, this work introduces the application of speech embeddings extracted from pre-trained deep learning models trained on large audio datasets for different tasks. In particular, we explore audio representations obtained using emphasized channel attention, propagation, and aggregation time delay neural network (ECAPA-TDNN) and Wav2Vec2.0 models trained on VoxCeleb and LibriSpeech datasets respectively. After extracting the embeddings, we benchmark with several traditional classifiers, such as the K-nearest neighbour (KNN), Gaussian naive Bayes, and neural network, for the SD tasks. In comparison to the standard SD systems trained only on the limited SEP-28k dataset, we obtain a relative improvement of 12.08%, 28.71%, 37.9% in terms of unweighted average recall (UAR) over the baselines. Finally, we have shown that combining two embeddings and concatenating multiple layers of Wav2Vec2.0 can further improve the UAR by up to 2.60% and 6.32% respectively.
Advancing Stuttering Detection via Data Augmentation, Class-Balanced Loss and Multi-Contextual Deep Learning
Feb 21, 2023



Stuttering is a neuro-developmental speech impairment characterized by uncontrolled utterances (interjections) and core behaviors (blocks, repetitions, and prolongations), and is caused by the failure of speech sensorimotors. Due to its complex nature, stuttering detection (SD) is a difficult task. If detected at an early stage, it could facilitate speech therapists to observe and rectify the speech patterns of persons who stutter (PWS). The stuttered speech of PWS is usually available in limited amounts and is highly imbalanced. To this end, we address the class imbalance problem in the SD domain via a multibranching (MB) scheme and by weighting the contribution of classes in the overall loss function, resulting in a huge improvement in stuttering classes on the SEP-28k dataset over the baseline (StutterNet). To tackle data scarcity, we investigate the effectiveness of data augmentation on top of a multi-branched training scheme. The augmented training outperforms the MB StutterNet (clean) by a relative margin of 4.18% in macro F1-score (F1). In addition, we propose a multi-contextual (MC) StutterNet, which exploits different contexts of the stuttered speech, resulting in an overall improvement of 4.48% in F 1 over the single context based MB StutterNet. Finally, we have shown that applying data augmentation in the cross-corpora scenario can improve the overall SD performance by a relative margin of 13.23% in F1 over the clean training.
StutterNet: Stuttering Detection Using Time Delay Neural Network
Jun 08, 2021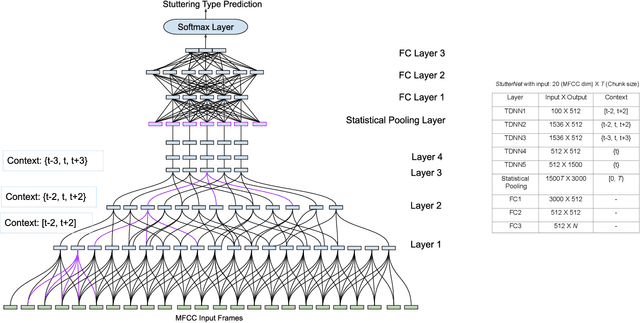
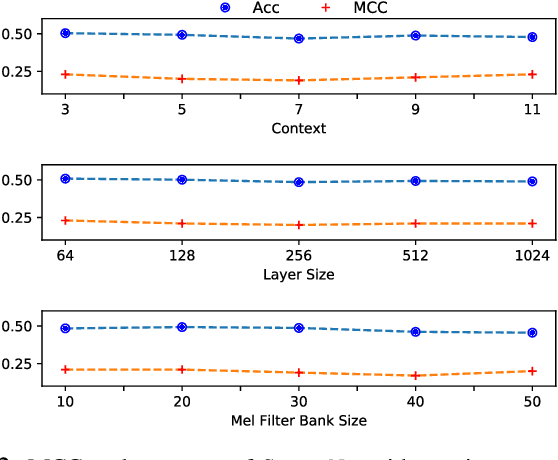
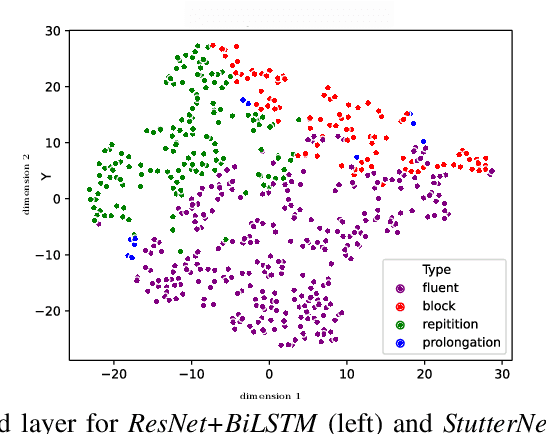

This paper introduces StutterNet, a novel deep learning based stuttering detection capable of detecting and identifying various types of disfluencies. Most of the existing work in this domain uses automatic speech recognition (ASR) combined with language models for stuttering detection. Compared to the existing work, which depends on the ASR module, our method relies solely on the acoustic signal. We use a time-delay neural network (TDNN) suitable for capturing contextual aspects of the disfluent utterances. We evaluate our system on the UCLASS stuttering dataset consisting of more than 100 speakers. Our method achieves promising results and outperforms the state-of-the-art residual neural network based method. The number of trainable parameters of the proposed method is also substantially less due to the parameter sharing scheme of TDNN.