 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"speech recognition": models, code, and papers
Towards ASR Robust Spoken Language Understanding Through In-Context Learning With Word Confusion Networks
Jan 05, 2024
In the realm of spoken language understanding (SLU), numerous natural language understanding (NLU) methodologies have been adapted by supplying large language models (LLMs) with transcribed speech instead of conventional written text. In real-world scenarios, prior to input into an LLM, an automated speech recognition (ASR) system generates an output transcript hypothesis, where inherent errors can degrade subsequent SLU tasks. Here we introduce a method that utilizes the ASR system's lattice output instead of relying solely on the top hypothesis, aiming to encapsulate speech ambiguities and enhance SLU outcomes. Our in-context learning experiments, covering spoken question answering and intent classification, underline the LLM's resilience to noisy speech transcripts with the help of word confusion networks from lattices, bridging the SLU performance gap between using the top ASR hypothesis and an oracle upper bound. Additionally, we delve into the LLM's robustness to varying ASR performance conditions and scrutinize the aspects of in-context learning which prove the most influential.
The Art of Deception: Robust Backdoor Attack using Dynamic Stacking of Triggers
Jan 03, 2024The area of Machine Learning as a Service (MLaaS) is experiencing increased implementation due to recent advancements in the AI (Artificial Intelligence) industry. However, this spike has prompted concerns regarding AI defense mechanisms, specifically regarding potential covert attacks from third-party providers that cannot be entirely trusted. Recent research has uncovered that auditory backdoors may use certain modifications as their initiating mechanism. DynamicTrigger is introduced as a methodology for carrying out dynamic backdoor attacks that use cleverly designed tweaks to ensure that corrupted samples are indistinguishable from clean. By utilizing fluctuating signal sampling rates and masking speaker identities through dynamic sound triggers (such as the clapping of hands), it is possible to deceive speech recognition systems (ASR). Our empirical testing demonstrates that DynamicTrigger is both potent and stealthy, achieving impressive success rates during covert attacks while maintaining exceptional accuracy with non-poisoned datasets.
ED-TTS: Multi-Scale Emotion Modeling using Cross-Domain Emotion Diarization for Emotional Speech Synthesis
Jan 16, 2024Existing emotional speech synthesis methods often utilize an utterance-level style embedding extracted from reference audio, neglecting the inherent multi-scale property of speech prosody. We introduce ED-TTS, a multi-scale emotional speech synthesis model that leverages Speech Emotion Diarization (SED) and Speech Emotion Recognition (SER) to model emotions at different levels. Specifically, our proposed approach integrates the utterance-level emotion embedding extracted by SER with fine-grained frame-level emotion embedding obtained from SED. These embeddings are used to condition the reverse process of the denoising diffusion probabilistic model (DDPM). Additionally, we employ cross-domain SED to accurately predict soft labels, addressing the challenge of a scarcity of fine-grained emotion-annotated datasets for supervising emotional TTS training.
End-to-End Speech Recognition Contextualization with Large Language Models
Sep 19, 2023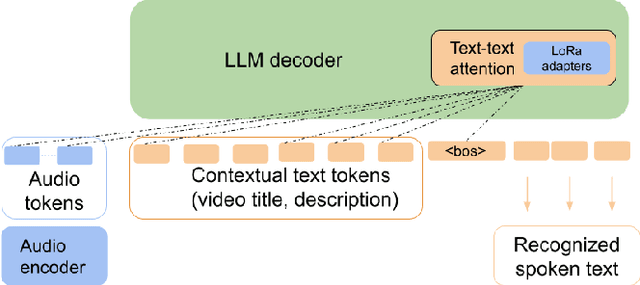

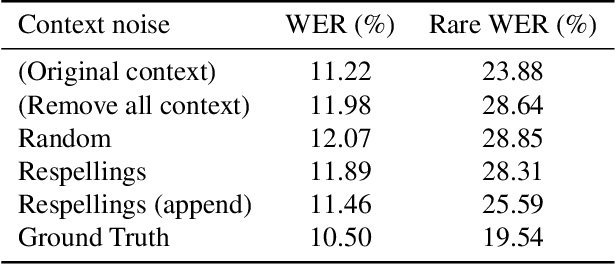

In recent years, Large Language Models (LLMs) have garnered significant attention from the research community due to their exceptional performance and generalization capabilities. In this paper, we introduce a novel method for contextualizing speech recognition models incorporating LLMs. Our approach casts speech recognition as a mixed-modal language modeling task based on a pretrained LLM. We provide audio features, along with optional text tokens for context, to train the system to complete transcriptions in a decoder-only fashion. As a result, the system is implicitly incentivized to learn how to leverage unstructured contextual information during training. Our empirical results demonstrate a significant improvement in performance, with a 6% WER reduction when additional textual context is provided. Moreover, we find that our method performs competitively and improve by 7.5% WER overall and 17% WER on rare words against a baseline contextualized RNN-T system that has been trained on more than twenty five times larger speech dataset. Overall, we demonstrate that by only adding a handful number of trainable parameters via adapters, we can unlock contextualized speech recognition capability for the pretrained LLM while keeping the same text-only input functionality.
Gaussian Adaptive Attention is All You Need: Robust Contextual Representations Across Multiple Modalities
Jan 31, 2024We propose the Multi-Head Gaussian Adaptive Attention Mechanism (GAAM), a novel probabilistic attention framework, and the Gaussian Adaptive Transformer (GAT), designed to enhance information aggregation across multiple modalities, including Speech, Text and Vision. GAAM integrates learnable mean and variance into its attention mechanism, implemented in a Multi-Headed framework enabling it to collectively model any Probability Distribution for dynamic recalibration of feature significance. This method demonstrates significant improvements, especially with highly non-stationary data, surpassing the state-of-the-art attention techniques in model performance (up to approximately +20% in accuracy) by identifying key elements within the feature space. GAAM's compatibility with dot-product-based attention models and relatively low number of parameters showcases its adaptability and potential to boost existing attention frameworks. Empirically, GAAM exhibits superior adaptability and efficacy across a diverse range of tasks, including emotion recognition in speech, image classification, and text classification, thereby establishing its robustness and versatility in handling multi-modal data. Furthermore, we introduce the Importance Factor (IF), a new learning-based metric that enhances the explainability of models trained with GAAM-based methods. Overall, GAAM represents an advancement towards development of better performing and more explainable attention models across multiple modalities.
High-precision Voice Search Query Correction via Retrievable Speech-text Embedings
Jan 08, 2024Automatic speech recognition (ASR) systems can suffer from poor recall for various reasons, such as noisy audio, lack of sufficient training data, etc. Previous work has shown that recall can be improved by retrieving rewrite candidates from a large database of likely, contextually-relevant alternatives to the hypothesis text using nearest-neighbors search over embeddings of the ASR hypothesis text to correct and candidate corrections. However, ASR-hypothesis-based retrieval can yield poor precision if the textual hypotheses are too phonetically dissimilar to the transcript truth. In this paper, we eliminate the hypothesis-audio mismatch problem by querying the correction database directly using embeddings derived from the utterance audio; the embeddings of the utterance audio and candidate corrections are produced by multimodal speech-text embedding networks trained to place the embedding of the audio of an utterance and the embedding of its corresponding textual transcript close together. After locating an appropriate correction candidate using nearest-neighbor search, we score the candidate with its speech-text embedding distance before adding the candidate to the original n-best list. We show a relative word error rate (WER) reduction of 6% on utterances whose transcripts appear in the candidate set, without increasing WER on general utterances.
Towards Online Sign Language Recognition and Translation
Jan 10, 2024The objective of sign language recognition is to bridge the communication gap between the deaf and the hearing. Numerous previous works train their models using the well-established connectionist temporal classification (CTC) loss. During the inference stage, the CTC-based models typically take the entire sign video as input to make predictions. This type of inference scheme is referred to as offline recognition. In contrast, while mature speech recognition systems can efficiently recognize spoken words on the fly, sign language recognition still falls short due to the lack of practical online solutions. In this work, we take the first step towards filling this gap. Our approach comprises three phases: 1) developing a sign language dictionary encompassing all glosses present in a target sign language dataset; 2) training an isolated sign language recognition model on augmented signs using both conventional classification loss and our novel saliency loss; 3) employing a sliding window approach on the input sign sequence and feeding each sign clip to the well-optimized model for online recognition. Furthermore, our online recognition model can be extended to boost the performance of any offline model, and to support online translation by appending a gloss-to-text network onto the recognition model. By integrating our online framework with the previously best-performing offline model, TwoStream-SLR, we achieve new state-of-the-art performance on three benchmarks: Phoenix-2014, Phoenix-2014T, and CSL-Daily. Code and models will be available at https://github.com/FangyunWei/SLRT
Multimodal Speech Emotion Recognition Using Modality-specific Self-Supervised Frameworks
Dec 04, 2023Emotion recognition is a topic of significant interest in assistive robotics due to the need to equip robots with the ability to comprehend human behavior, facilitating their effective interaction in our society. Consequently, efficient and dependable emotion recognition systems supporting optimal human-machine communication are required. Multi-modality (including speech, audio, text, images, and videos) is typically exploited in emotion recognition tasks. Much relevant research is based on merging multiple data modalities and training deep learning models utilizing low-level data representations. However, most existing emotion databases are not large (or complex) enough to allow machine learning approaches to learn detailed representations. This paper explores modalityspecific pre-trained transformer frameworks for self-supervised learning of speech and text representations for data-efficient emotion recognition while achieving state-of-the-art performance in recognizing emotions. This model applies feature-level fusion using nonverbal cue data points from motion capture to provide multimodal speech emotion recognition. The model was trained using the publicly available IEMOCAP dataset, achieving an overall accuracy of 77.58% for four emotions, outperforming state-of-the-art approaches
Keyword spotting -- Detecting commands in speech using deep learning
Dec 09, 2023
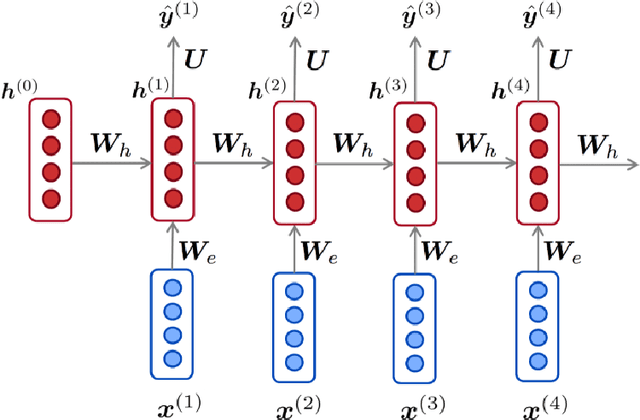
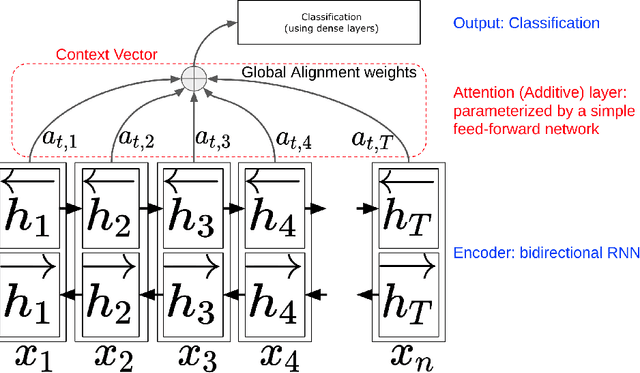
Speech recognition has become an important task in the development of machine learning and artificial intelligence. In this study, we explore the important task of keyword spotting using speech recognition machine learning and deep learning techniques. We implement feature engineering by converting raw waveforms to Mel Frequency Cepstral Coefficients (MFCCs), which we use as inputs to our models. We experiment with several different algorithms such as Hidden Markov Model with Gaussian Mixture, Convolutional Neural Networks and variants of Recurrent Neural Networks including Long Short-Term Memory and the Attention mechanism. In our experiments, RNN with BiLSTM and Attention achieves the best performance with an accuracy of 93.9 %
SpokesBiz -- an Open Corpus of Conversational Polish
Dec 19, 2023This paper announces the early release of SpokesBiz, a freely available corpus of conversational Polish developed within the CLARIN-BIZ project and comprising over 650 hours of recordings. The transcribed recordings have been diarized and manually annotated for punctuation and casing. We outline the general structure and content of the corpus, showcasing selected applications in linguistic research, evaluation and improvement of automatic speech recognition (ASR) systems