 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCustomVideoX: 3D Reference Attention Driven Dynamic Adaptation for Zero-Shot Customized Video Diffusion Transformers
Feb 10, 2025Customized generation has achieved significant progress in image synthesis, yet personalized video generation remains challenging due to temporal inconsistencies and quality degradation. In this paper, we introduce CustomVideoX, an innovative framework leveraging the video diffusion transformer for personalized video generation from a reference image. CustomVideoX capitalizes on pre-trained video networks by exclusively training the LoRA parameters to extract reference features, ensuring both efficiency and adaptability. To facilitate seamless interaction between the reference image and video content, we propose 3D Reference Attention, which enables direct and simultaneous engagement of reference image features with all video frames across spatial and temporal dimensions. To mitigate the excessive influence of reference image features and textual guidance on generated video content during inference, we implement the Time-Aware Reference Attention Bias (TAB) strategy, dynamically modulating reference bias over different time steps. Additionally, we introduce the Entity Region-Aware Enhancement (ERAE) module, aligning highly activated regions of key entity tokens with reference feature injection by adjusting attention bias. To thoroughly evaluate personalized video generation, we establish a new benchmark, VideoBench, comprising over 50 objects and 100 prompts for extensive assessment. Experimental results show that CustomVideoX significantly outperforms existing methods in terms of video consistency and quality.
ED-TTS: Multi-Scale Emotion Modeling using Cross-Domain Emotion Diarization for Emotional Speech Synthesis
Jan 16, 2024



Existing emotional speech synthesis methods often utilize an utterance-level style embedding extracted from reference audio, neglecting the inherent multi-scale property of speech prosody. We introduce ED-TTS, a multi-scale emotional speech synthesis model that leverages Speech Emotion Diarization (SED) and Speech Emotion Recognition (SER) to model emotions at different levels. Specifically, our proposed approach integrates the utterance-level emotion embedding extracted by SER with fine-grained frame-level emotion embedding obtained from SED. These embeddings are used to condition the reverse process of the denoising diffusion probabilistic model (DDPM). Additionally, we employ cross-domain SED to accurately predict soft labels, addressing the challenge of a scarcity of fine-grained emotion-annotated datasets for supervising emotional TTS training.
EmoMix: Emotion Mixing via Diffusion Models for Emotional Speech Synthesis
Jun 01, 2023



There has been significant progress in emotional Text-To-Speech (TTS) synthesis technology in recent years. However, existing methods primarily focus on the synthesis of a limited number of emotion types and have achieved unsatisfactory performance in intensity control. To address these limitations, we propose EmoMix, which can generate emotional speech with specified intensity or a mixture of emotions. Specifically, EmoMix is a controllable emotional TTS model based on a diffusion probabilistic model and a pre-trained speech emotion recognition (SER) model used to extract emotion embedding. Mixed emotion synthesis is achieved by combining the noises predicted by diffusion model conditioned on different emotions during only one sampling process at the run-time. We further apply the Neutral and specific primary emotion mixed in varying degrees to control intensity. Experimental results validate the effectiveness of EmoMix for synthesizing mixed emotion and intensity control.
SAR: Self-Supervised Anti-Distortion Representation for End-To-End Speech Model
Apr 23, 2023



In recent Text-to-Speech (TTS) systems, a neural vocoder often generates speech samples by solely conditioning on acoustic features predicted from an acoustic model. However, there are always distortions existing in the predicted acoustic features, compared to those of the groundtruth, especially in the common case of poor acoustic modeling due to low-quality training data. To overcome such limits, we propose a Self-supervised learning framework to learn an Anti-distortion acoustic Representation (SAR) to replace human-crafted acoustic features by introducing distortion prior to an auto-encoder pre-training process. The learned acoustic representation from the proposed framework is proved anti-distortion compared to the most commonly used mel-spectrogram through both objective and subjective evaluation.
QI-TTS: Questioning Intonation Control for Emotional Speech Synthesis
Mar 14, 2023



Recent expressive text to speech (TTS) models focus on synthesizing emotional speech, but some fine-grained styles such as intonation are neglected. In this paper, we propose QI-TTS which aims to better transfer and control intonation to further deliver the speaker's questioning intention while transferring emotion from reference speech. We propose a multi-style extractor to extract style embedding from two different levels. While the sentence level represents emotion, the final syllable level represents intonation. For fine-grained intonation control, we use relative attributes to represent intonation intensity at the syllable level.Experiments have validated the effectiveness of QI-TTS for improving intonation expressiveness in emotional speech synthesis.
Dynamic Alignment Mask CTC: Improved Mask-CTC with Aligned Cross Entropy
Mar 14, 2023



Because of predicting all the target tokens in parallel, the non-autoregressive models greatly improve the decoding efficiency of speech recognition compared with traditional autoregressive models. In this work, we present dynamic alignment Mask CTC, introducing two methods: (1) Aligned Cross Entropy (AXE), finding the monotonic alignment that minimizes the cross-entropy loss through dynamic programming, (2) Dynamic Rectification, creating new training samples by replacing some masks with model predicted tokens. The AXE ignores the absolute position alignment between prediction and ground truth sentence and focuses on tokens matching in relative order. The dynamic rectification method makes the model capable of simulating the non-mask but possible wrong tokens, even if they have high confidence. Our experiments on WSJ dataset demonstrated that not only AXE loss but also the rectification method could improve the WER performance of Mask CTC.
Speech Augmentation Based Unsupervised Learning for Keyword Spotting
May 28, 2022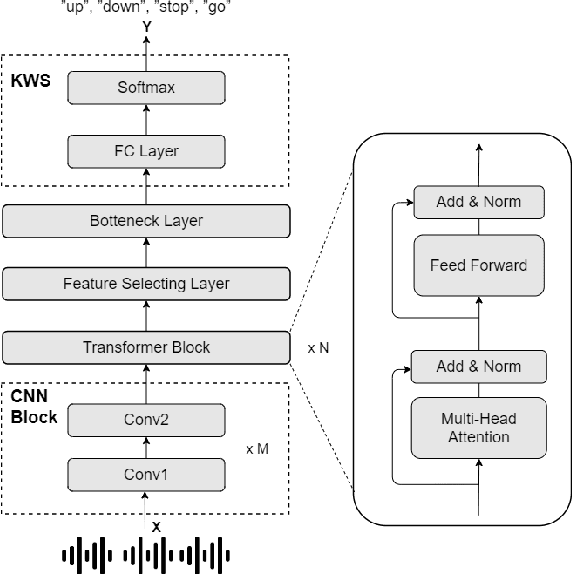
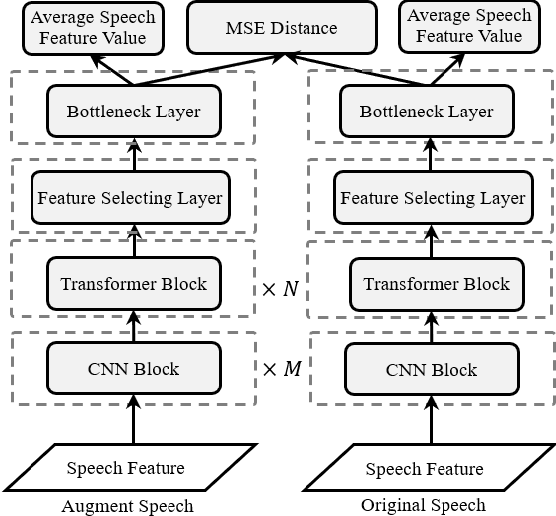

In this paper, we investigated a speech augmentation based unsupervised learning approach for keyword spotting (KWS) task. KWS is a useful speech application, yet also heavily depends on the labeled data. We designed a CNN-Attention architecture to conduct the KWS task. CNN layers focus on the local acoustic features, and attention layers model the long-time dependency. To improve the robustness of KWS model, we also proposed an unsupervised learning method. The unsupervised loss is based on the similarity between the original and augmented speech features, as well as the audio reconstructing information. Two speech augmentation methods are explored in the unsupervised learning: speed and intensity. The experiments on Google Speech Commands V2 Dataset demonstrated that our CNN-Attention model has competitive results. Moreover, the augmentation based unsupervised learning could further improve the classification accuracy of KWS task. In our experiments, with augmentation based unsupervised learning, our KWS model achieves better performance than other unsupervised methods, such as CPC, APC, and MPC.