 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"speech recognition": models, code, and papers
Plant Species Classification Using Transfer Learning by Pretrained Classifier VGG-19
Sep 07, 2022
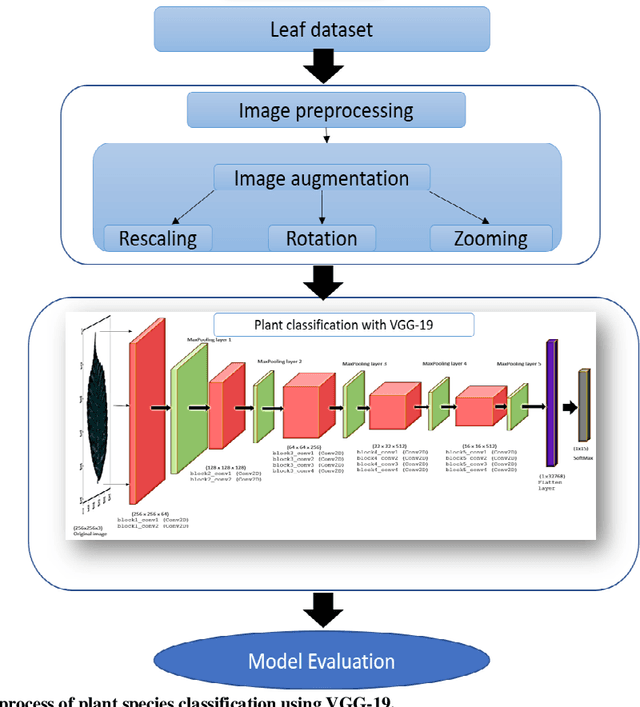


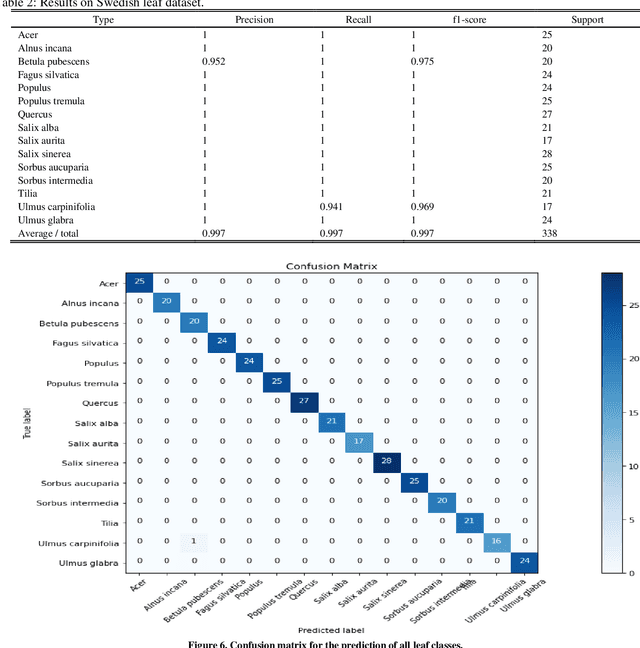
Deep learning is currently the most important branch of machine learning, with applications in speech recognition, computer vision, image classification, and medical imaging analysis. Plant recognition is one of the areas where image classification can be used to identify plant species through their leaves. Botanists devote a significant amount of time to recognizing plant species by personally inspecting. This paper describes a method for dissecting color images of Swedish leaves and identifying plant species. To achieve higher accuracy, the task is completed using transfer learning with the help of pre-trained classifier VGG-19. The four primary processes of classification are image preprocessing, image augmentation, feature extraction, and recognition, which are performed as part of the overall model evaluation. The VGG-19 classifier grasps the characteristics of leaves by employing pre-defined hidden layers such as convolutional layers, max pooling layers, and fully connected layers, and finally uses the soft-max layer to generate a feature representation for all plant classes. The model obtains knowledge connected to aspects of the Swedish leaf dataset, which contains fifteen tree classes, and aids in predicting the proper class of an unknown plant with an accuracy of 99.70% which is higher than previous research works reported.
SoK: A Modularized Approach to Study the Security of Automatic Speech Recognition Systems
Mar 19, 2021
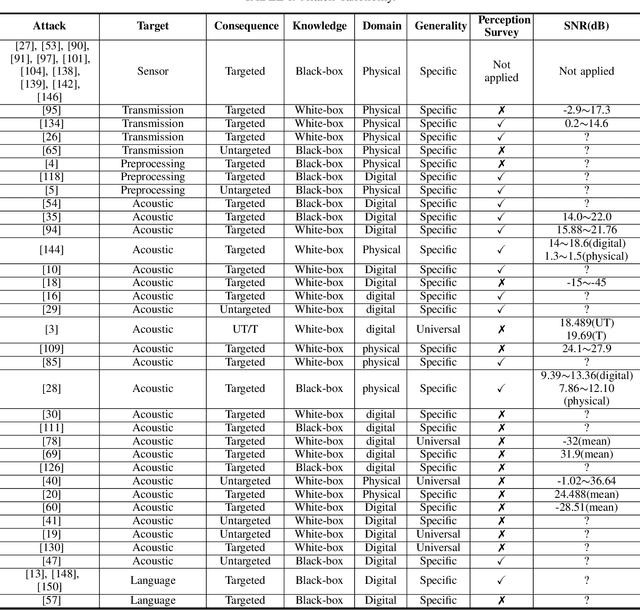

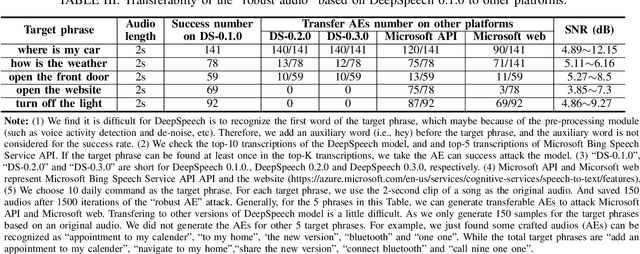
With the wide use of Automatic Speech Recognition (ASR) in applications such as human machine interaction, simultaneous interpretation, audio transcription, etc., its security protection becomes increasingly important. Although recent studies have brought to light the weaknesses of popular ASR systems that enable out-of-band signal attack, adversarial attack, etc., and further proposed various remedies (signal smoothing, adversarial training, etc.), a systematic understanding of ASR security (both attacks and defenses) is still missing, especially on how realistic such threats are and how general existing protection could be. In this paper, we present our systematization of knowledge for ASR security and provide a comprehensive taxonomy for existing work based on a modularized workflow. More importantly, we align the research in this domain with that on security in Image Recognition System (IRS), which has been extensively studied, using the domain knowledge in the latter to help understand where we stand in the former. Generally, both IRS and ASR are perceptual systems. Their similarities allow us to systematically study existing literature in ASR security based on the spectrum of attacks and defense solutions proposed for IRS, and pinpoint the directions of more advanced attacks and the directions potentially leading to more effective protection in ASR. In contrast, their differences, especially the complexity of ASR compared with IRS, help us learn unique challenges and opportunities in ASR security. Particularly, our experimental study shows that transfer learning across ASR models is feasible, even in the absence of knowledge about models (even their types) and training data.
Analysis of Self-Supervised Learning and Dimensionality Reduction Methods in Clustering-Based Active Learning for Speech Emotion Recognition
Jun 21, 2022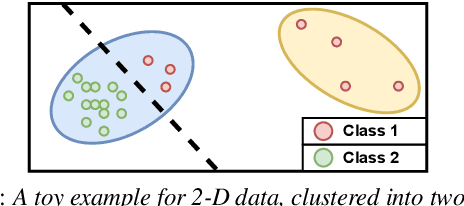

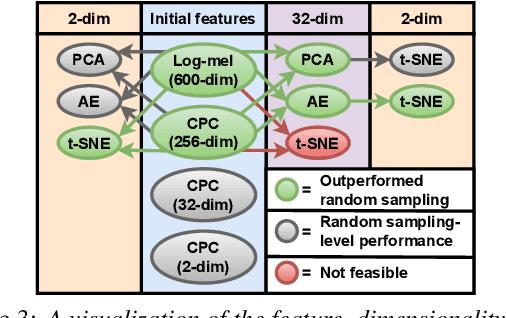
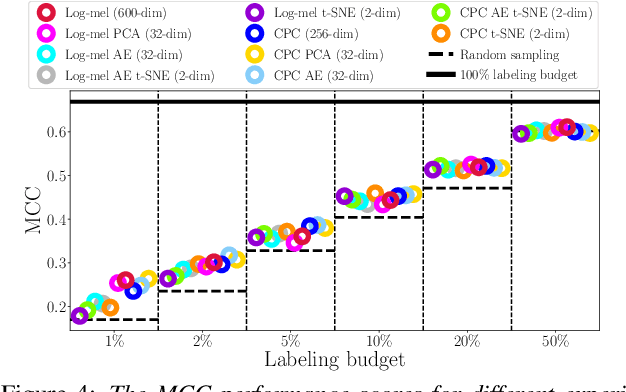
When domain experts are needed to perform data annotation for complex machine-learning tasks, reducing annotation effort is crucial in order to cut down time and expenses. For cases when there are no annotations available, one approach is to utilize the structure of the feature space for clustering-based active learning (AL) methods. However, these methods are heavily dependent on how the samples are organized in the feature space and what distance metric is used. Unsupervised methods such as contrastive predictive coding (CPC) can potentially be used to learn organized feature spaces, but these methods typically create high-dimensional features which might be challenging for estimating data density. In this paper, we combine CPC and multiple dimensionality reduction methods in search of functioning practices for clustering-based AL. Our experiments for simulating speech emotion recognition system deployment show that both the local and global topology of the feature space can be successfully used for AL, and that CPC can be used to improve clustering-based AL performance over traditional signal features. Additionally, we observe that compressing data dimensionality does not harm AL performance substantially, and that 2-D feature representations achieved similar AL performance as higher-dimensional representations when the number of annotations is not very low.
Investigating data partitioning strategies for crosslinguistic low-resource ASR evaluation
Aug 26, 2022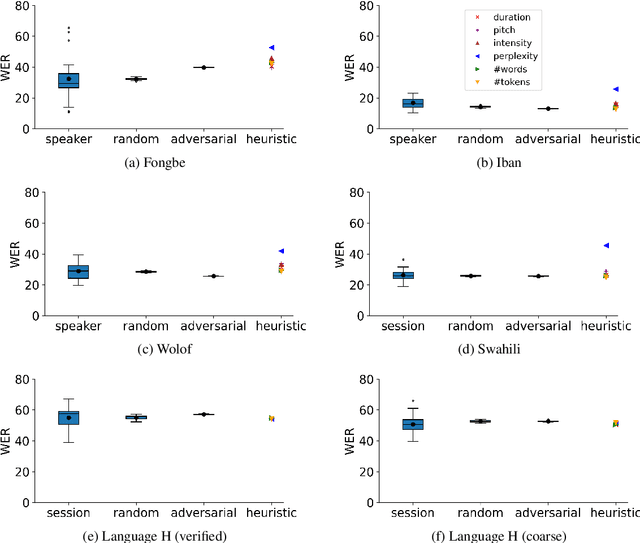
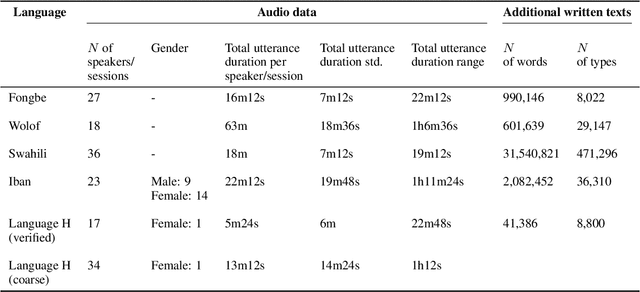
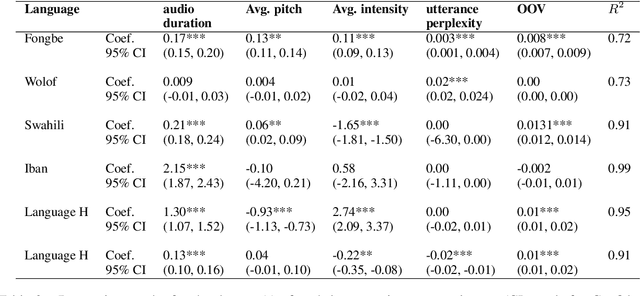
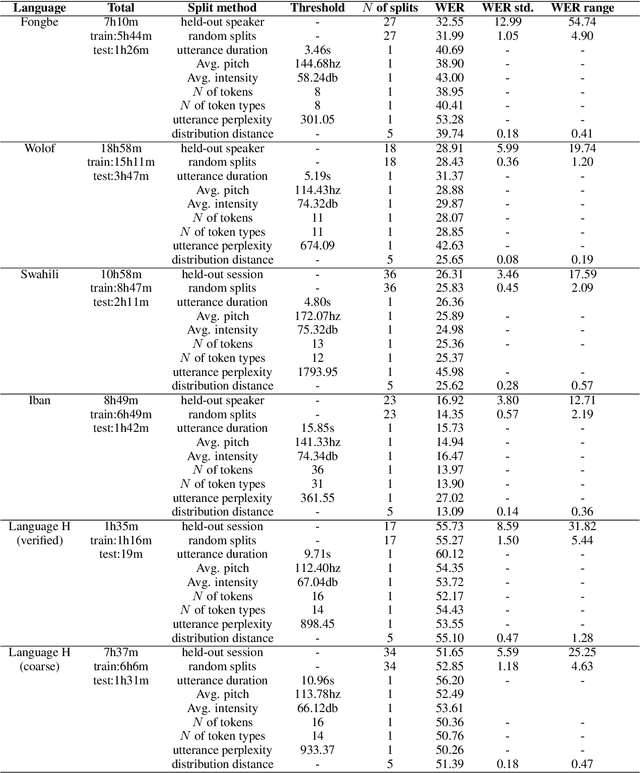
Many automatic speech recognition (ASR) data sets include a single pre-defined test set consisting of one or more speakers whose speech never appears in the training set. This "hold-speaker(s)-out" data partitioning strategy, however, may not be ideal for data sets in which the number of speakers is very small. This study investigates ten different data split methods for five languages with minimal ASR training resources. We find that (1) model performance varies greatly depending on which speaker is selected for testing; (2) the average word error rate (WER) across all held-out speakers is comparable not only to the average WER over multiple random splits but also to any given individual random split; (3) WER is also generally comparable when the data is split heuristically or adversarially; (4) utterance duration and intensity are comparatively more predictive factors of variability regardless of the data split. These results suggest that the widely used hold-speakers-out approach to ASR data partitioning can yield results that do not reflect model performance on unseen data or speakers. Random splits can yield more reliable and generalizable estimates when facing data sparsity.
On model architecture for a children's speech recognition interactive dialog system
May 25, 2016
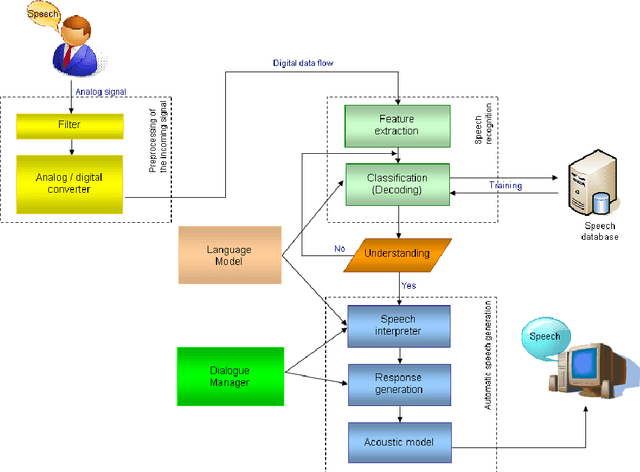
This report presents a general model of the architecture of information systems for the speech recognition of children. It presents a model of the speech data stream and how it works. The result of these studies and presented veins architectural model shows that research needs to be focused on acoustic-phonetic modeling in order to improve the quality of children's speech recognition and the sustainability of the systems to noise and changes in transmission environment. Another important aspect is the development of more accurate algorithms for modeling of spontaneous child speech.
* 6 pages, 2 figures, in proc. of conference FMNS 2009, Blagoevgrad, Bulgaria
User-Level Differential Privacy against Attribute Inference Attack of Speech Emotion Recognition in Federated Learning
Apr 05, 2022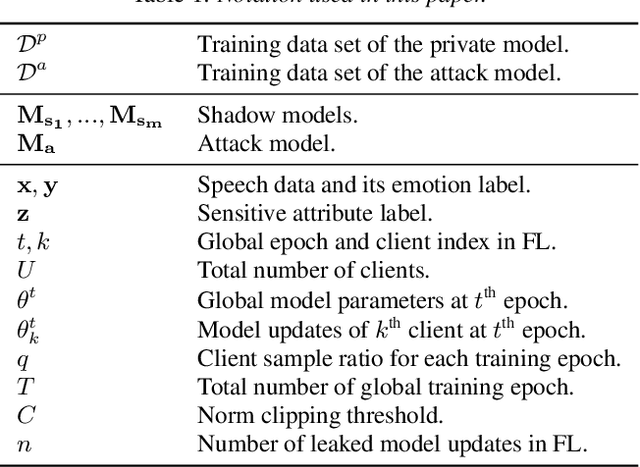
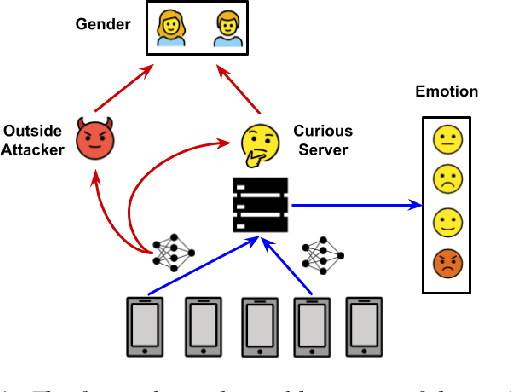
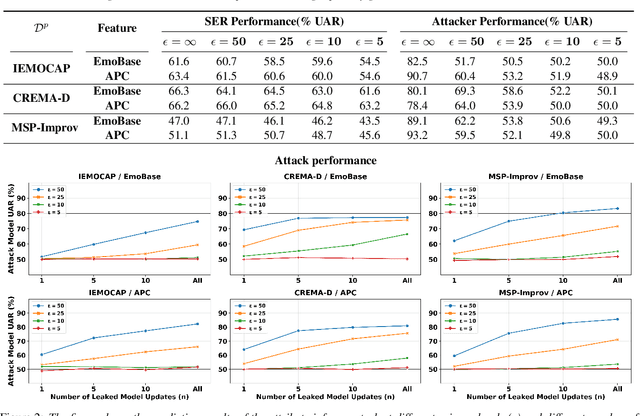
Many existing privacy-enhanced speech emotion recognition (SER) frameworks focus on perturbing the original speech data through adversarial training within a centralized machine learning setup. However, this privacy protection scheme can fail since the adversary can still access the perturbed data. In recent years, distributed learning algorithms, especially federated learning (FL), have gained popularity to protect privacy in machine learning applications. While FL provides good intuition to safeguard privacy by keeping the data on local devices, prior work has shown that privacy attacks, such as attribute inference attacks, are achievable for SER systems trained using FL. In this work, we propose to evaluate the user-level differential privacy (UDP) in mitigating the privacy leaks of the SER system in FL. UDP provides theoretical privacy guarantees with privacy parameters $\epsilon$ and $\delta$. Our results show that the UDP can effectively decrease attribute information leakage while keeping the utility of the SER system with the adversary accessing one model update. However, the efficacy of the UDP suffers when the FL system leaks more model updates to the adversary. We make the code publicly available to reproduce the results in https://github.com/usc-sail/fed-ser-leakage.
Building DNN Acoustic Models for Large Vocabulary Speech Recognition
Jan 20, 2015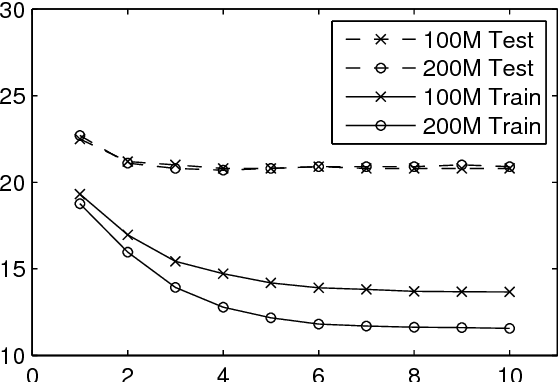

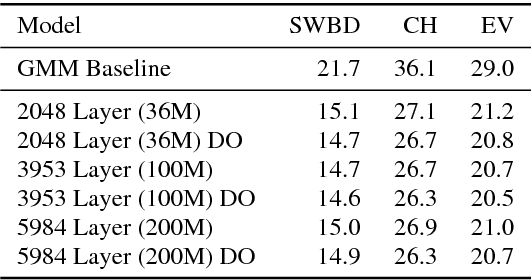

Deep neural networks (DNNs) are now a central component of nearly all state-of-the-art speech recognition systems. Building neural network acoustic models requires several design decisions including network architecture, size, and training loss function. This paper offers an empirical investigation on which aspects of DNN acoustic model design are most important for speech recognition system performance. We report DNN classifier performance and final speech recognizer word error rates, and compare DNNs using several metrics to quantify factors influencing differences in task performance. Our first set of experiments use the standard Switchboard benchmark corpus, which contains approximately 300 hours of conversational telephone speech. We compare standard DNNs to convolutional networks, and present the first experiments using locally-connected, untied neural networks for acoustic modeling. We additionally build systems on a corpus of 2,100 hours of training data by combining the Switchboard and Fisher corpora. This larger corpus allows us to more thoroughly examine performance of large DNN models -- with up to ten times more parameters than those typically used in speech recognition systems. Our results suggest that a relatively simple DNN architecture and optimization technique produces strong results. These findings, along with previous work, help establish a set of best practices for building DNN hybrid speech recognition systems with maximum likelihood training. Our experiments in DNN optimization additionally serve as a case study for training DNNs with discriminative loss functions for speech tasks, as well as DNN classifiers more generally.
ViDeBERTa: A powerful pre-trained language model for Vietnamese
Jan 25, 2023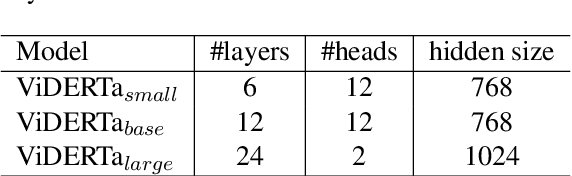
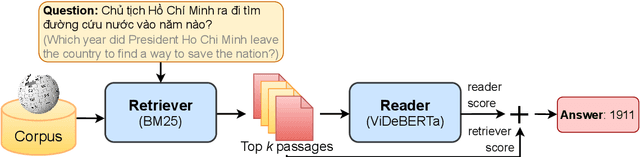
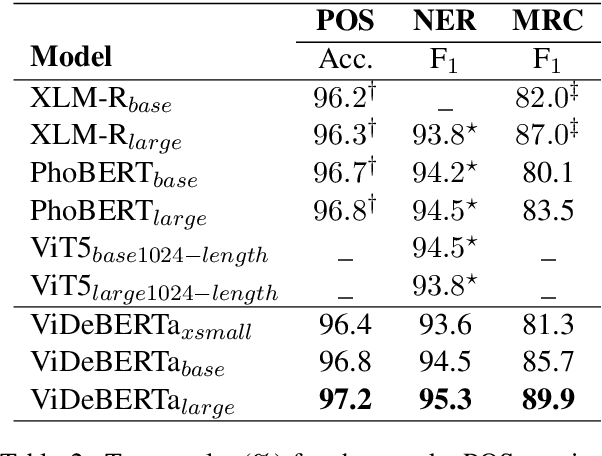
This paper presents ViDeBERTa, a new pre-trained monolingual language model for Vietnamese, with three versions - ViDeBERTa_xsmall, ViDeBERTa_base, and ViDeBERTa_large, which are pre-trained on a large-scale corpus of high-quality and diverse Vietnamese texts using DeBERTa architecture. Although many successful pre-trained language models based on Transformer have been widely proposed for the English language, there are still few pre-trained models for Vietnamese, a low-resource language, that perform good results on downstream tasks, especially Question answering. We fine-tune and evaluate our model on three important natural language downstream tasks, Part-of-speech tagging, Named-entity recognition, and Question answering. The empirical results demonstrate that ViDeBERTa with far fewer parameters surpasses the previous state-of-the-art models on multiple Vietnamese-specific natural language understanding tasks. Notably, ViDeBERTa_base with 86M parameters, which is only about 23% of PhoBERT_large with 370M parameters, still performs the same or better results than the previous state-of-the-art model. Our ViDeBERTa models are available at: https://github.com/HySonLab/ViDeBERTa.
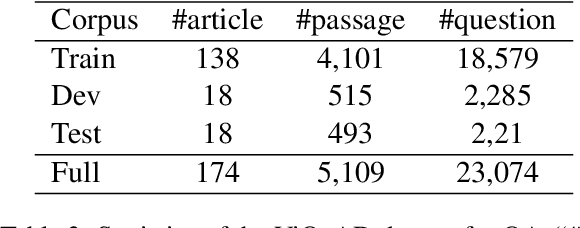
Rank-1 Constrained Multichannel Wiener Filter for Speech Recognition in Noisy Environments
Nov 15, 2017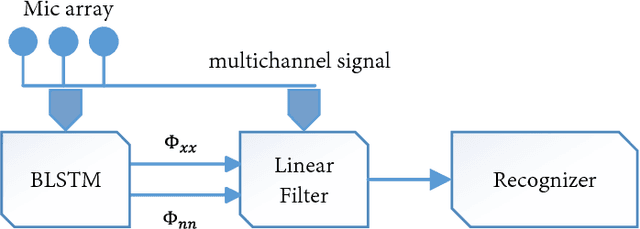

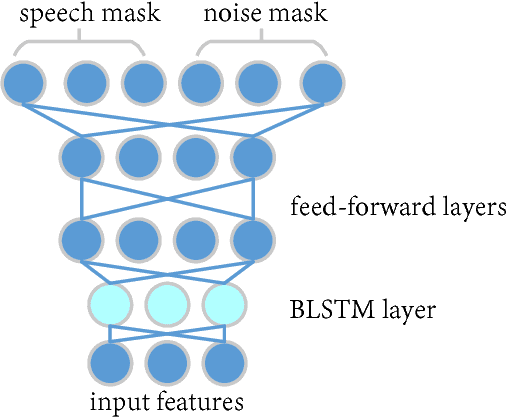
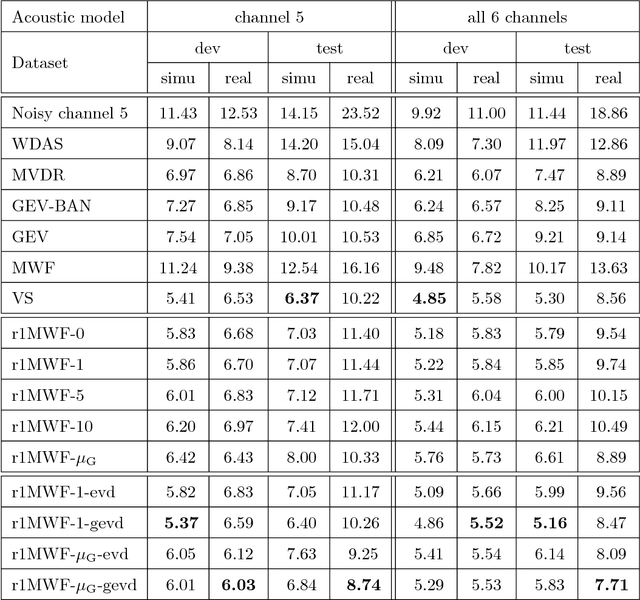
Multichannel linear filters, such as the Multichannel Wiener Filter (MWF) and the Generalized Eigenvalue (GEV) beamformer are popular signal processing techniques which can improve speech recognition performance. In this paper, we present an experimental study on these linear filters in a specific speech recognition task, namely the CHiME-4 challenge, which features real recordings in multiple noisy environments. Specifically, the rank-1 MWF is employed for noise reduction and a new constant residual noise power constraint is derived which enhances the recognition performance. To fulfill the underlying rank-1 assumption, the speech covariance matrix is reconstructed based on eigenvectors or generalized eigenvectors. Then the rank-1 constrained MWF is evaluated with alternative multichannel linear filters under the same framework, which involves a Bidirectional Long Short-Term Memory (BLSTM) network for mask estimation. The proposed filter outperforms alternative ones, leading to a 40% relative Word Error Rate (WER) reduction compared with the baseline Weighted Delay and Sum (WDAS) beamformer on the real test set, and a 15% relative WER reduction compared with the GEV-BAN method. The results also suggest that the speech recognition accuracy correlates more with the Mel-frequency cepstral coefficients (MFCC) feature variance than with the noise reduction or the speech distortion level.
Incremental Learning for End-to-End Automatic Speech Recognition
May 11, 2020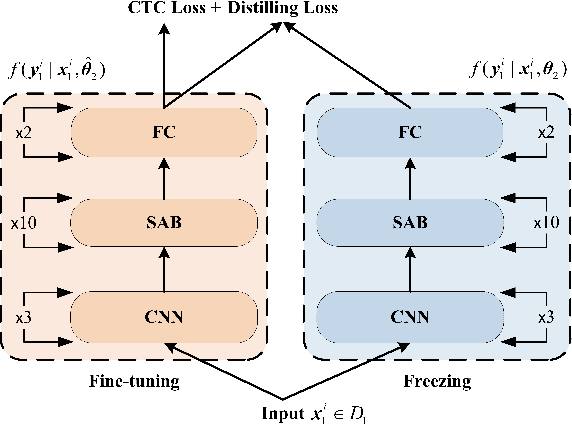
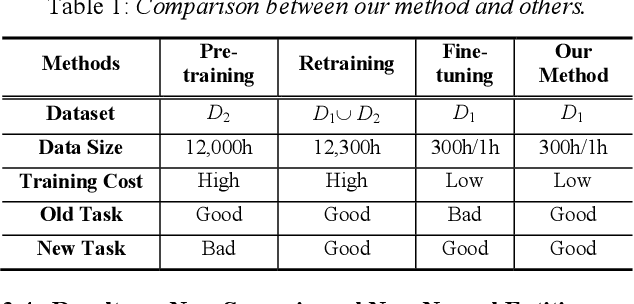
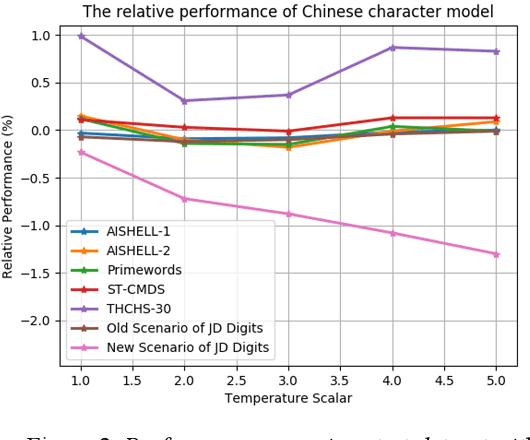
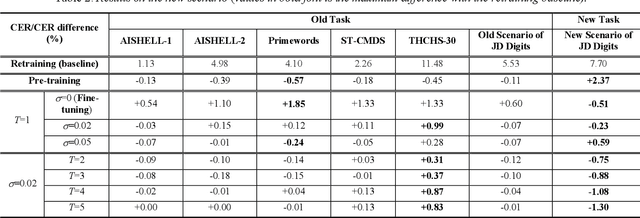
We propose an incremental learning for end-to-end Automatic Speech Recognition (ASR) to extend the model's capacity on a new task while retaining the performance on existing ones. The proposed method is effective without accessing to the old dataset to address the issues of high training cost and old dataset unavailability. To achieve this, knowledge distillation is applied as a guidance to retain the recognition ability from the previous model, which is then combined with the new ASR task for model optimization. With an ASR model pre-trained on 12,000h Mandarin speech, we test our proposed method on 300h new scenario task and 1h new named entities task. Experiments show that our method yields 3.25% and 0.88% absolute Character Error Rate (CER) reduction on the new scenario, when compared with the pre-trained model and the full-data retraining baseline, respectively. It even yields a surprising 0.37% absolute CER reduction on the new scenario than the fine-tuning. For the new named entities task, our method significantly improves the accuracy compared with the pre-trained model, i.e. 16.95% absolute CER reduction. For both of the new task adaptions, the new models still maintain a same accuracy with the baseline on the old tasks.