 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAn Event Grouping Based Algorithm for University Course Timetabling Problem
Jul 18, 2016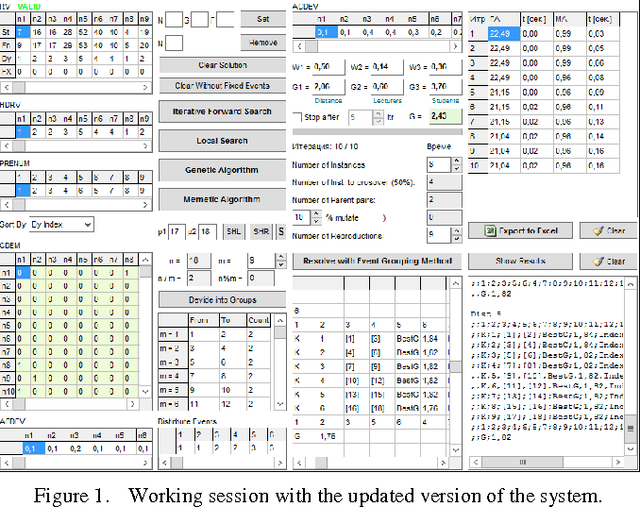
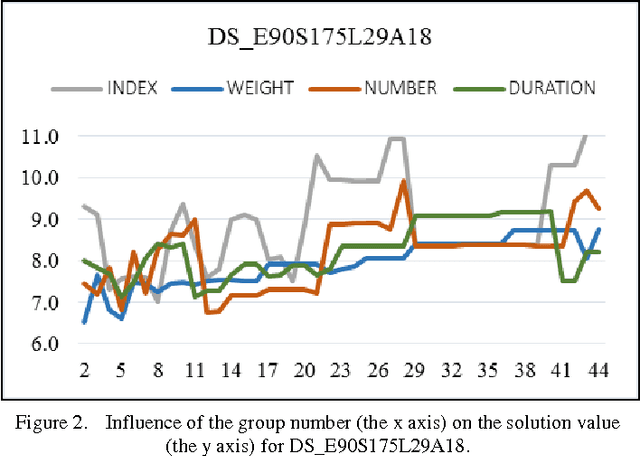
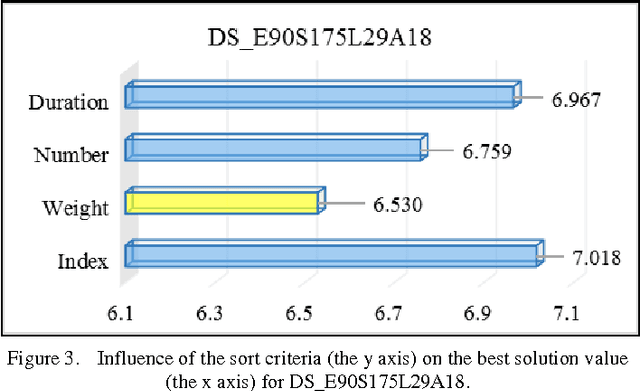
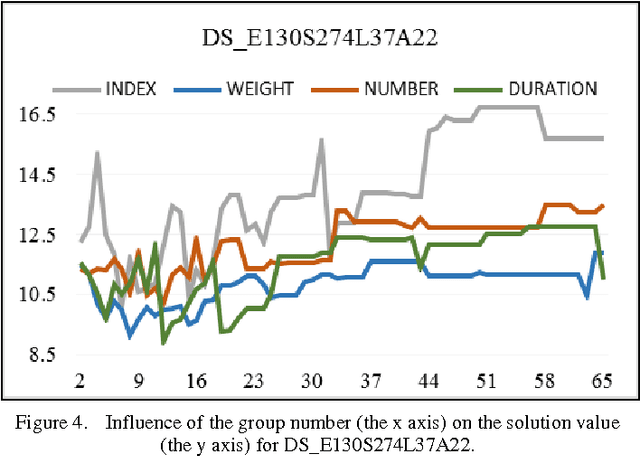
This paper presents the study of an event grouping based algorithm for a university course timetabling problem. Several publications which discuss the problem and some approaches for its solution are analyzed. The grouping of events in groups with an equal number of events in each group is not applicable to all input data sets. For this reason, a universal approach to all possible groupings of events in commensurate in size groups is proposed here. Also, an implementation of an algorithm based on this approach is presented. The methodology, conditions and the objectives of the experiment are described. The experimental results are analyzed and the ensuing conclusions are stated. The future guidelines for further research are formulated.
Design and development a children's speech database
May 25, 2016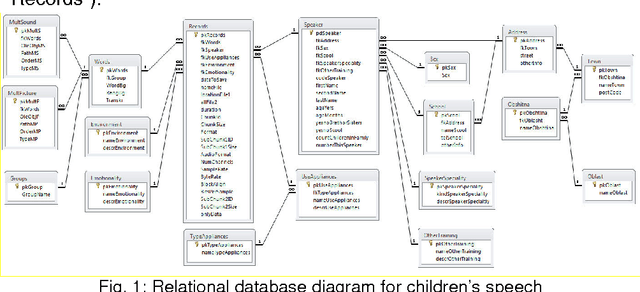

The report presents the process of planning, designing and the development of a database of spoken children's speech whose native language is Bulgarian. The proposed model is designed for children between the age of 4 and 6 without speech disorders, and reflects their specific capabilities. At this age most children cannot read, there is no sustained concentration, they are emotional, etc. The aim is to unite all the media information accompanying the recording and processing of spoken speech, thereby to facilitate the work of researchers in the field of speech recognition. This database will be used for the development of systems for children's speech recognition, children's speech synthesis systems, games which allow voice control, etc. As a result of the proposed model a prototype system for speech recognition is presented.
* 8 pages, 2 figures, 1 table, conference FMNS 2011, Blagoevgrad, Bulgaria
On model architecture for a children's speech recognition interactive dialog system
May 25, 2016
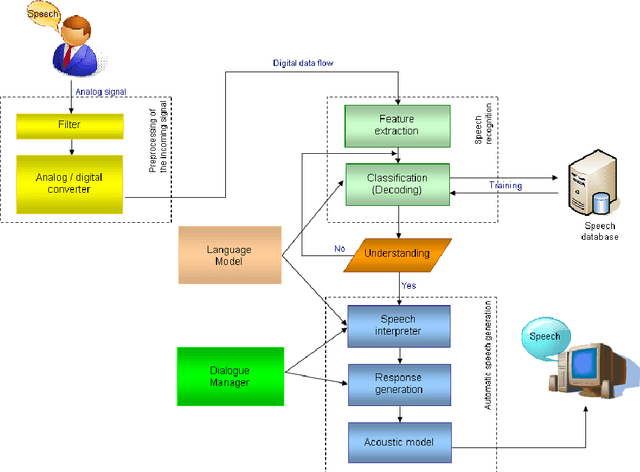
This report presents a general model of the architecture of information systems for the speech recognition of children. It presents a model of the speech data stream and how it works. The result of these studies and presented veins architectural model shows that research needs to be focused on acoustic-phonetic modeling in order to improve the quality of children's speech recognition and the sustainability of the systems to noise and changes in transmission environment. Another important aspect is the development of more accurate algorithms for modeling of spontaneous child speech.
* 6 pages, 2 figures, in proc. of conference FMNS 2009, Blagoevgrad, Bulgaria