 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeRobust Multimodal Safety via Conditional Decoding
Mar 31, 2026Multimodal large-language models (MLLMs) often experience degraded safety alignment when harmful queries exploit cross-modal interactions. Models aligned on text alone show a higher rate of successful attacks when extended to two or more modalities. In this work, we propose a simple conditional decoding strategy, CASA (Classification Augmented with Safety Attention) that utilizes internal representations of MLLMs to predict a binary safety token before response generation. We introduce a novel safety attention module designed to enhance the model's ability to detect malicious queries. Our design ensures robust safety alignment without relying on any external classifier or auxiliary head, and without the need for modality-specific safety fine-tuning. On diverse benchmarks such as MM-SafetyBench, JailbreakV-28k, and adversarial audio tests, CASA lowers the average attack success rate by more than 97% across modalities and across attack types. Our empirical evaluations also show that CASA maintains strong utility in benign inputs, a result validated through both automated and human evaluations (via 13 trained annotators). Together, these results highlight CASA as a simple and generalizable framework to improve multimodal LLM safety.
SpeechGuard: Exploring the Adversarial Robustness of Multimodal Large Language Models
May 14, 2024



Integrated Speech and Large Language Models (SLMs) that can follow speech instructions and generate relevant text responses have gained popularity lately. However, the safety and robustness of these models remains largely unclear. In this work, we investigate the potential vulnerabilities of such instruction-following speech-language models to adversarial attacks and jailbreaking. Specifically, we design algorithms that can generate adversarial examples to jailbreak SLMs in both white-box and black-box attack settings without human involvement. Additionally, we propose countermeasures to thwart such jailbreaking attacks. Our models, trained on dialog data with speech instructions, achieve state-of-the-art performance on spoken question-answering task, scoring over 80% on both safety and helpfulness metrics. Despite safety guardrails, experiments on jailbreaking demonstrate the vulnerability of SLMs to adversarial perturbations and transfer attacks, with average attack success rates of 90% and 10% respectively when evaluated on a dataset of carefully designed harmful questions spanning 12 different toxic categories. However, we demonstrate that our proposed countermeasures reduce the attack success significantly.
VoxWatch: An open-set speaker recognition benchmark on VoxCeleb
Jun 30, 2023



Despite its broad practical applications such as in fraud prevention, open-set speaker identification (OSI) has received less attention in the speaker recognition community compared to speaker verification (SV). OSI deals with determining if a test speech sample belongs to a speaker from a set of pre-enrolled individuals (in-set) or if it is from an out-of-set speaker. In addition to the typical challenges associated with speech variability, OSI is prone to the "false-alarm problem"; as the size of the in-set speaker population (a.k.a watchlist) grows, the out-of-set scores become larger, leading to increased false alarm rates. This is in particular challenging for applications in financial institutions and border security where the watchlist size is typically of the order of several thousand speakers. Therefore, it is important to systematically quantify the false-alarm problem, and develop techniques that alleviate the impact of watchlist size on detection performance. Prior studies on this problem are sparse, and lack a common benchmark for systematic evaluations. In this paper, we present the first public benchmark for OSI, developed using the VoxCeleb dataset. We quantify the effect of the watchlist size and speech duration on the watchlist-based speaker detection task using three strong neural network based systems. In contrast to the findings from prior research, we show that the commonly adopted adaptive score normalization is not guaranteed to improve the performance for this task. On the other hand, we show that score calibration and score fusion, two other commonly used techniques in SV, result in significant improvements in OSI performance.
User-Level Differential Privacy against Attribute Inference Attack of Speech Emotion Recognition in Federated Learning
Apr 05, 2022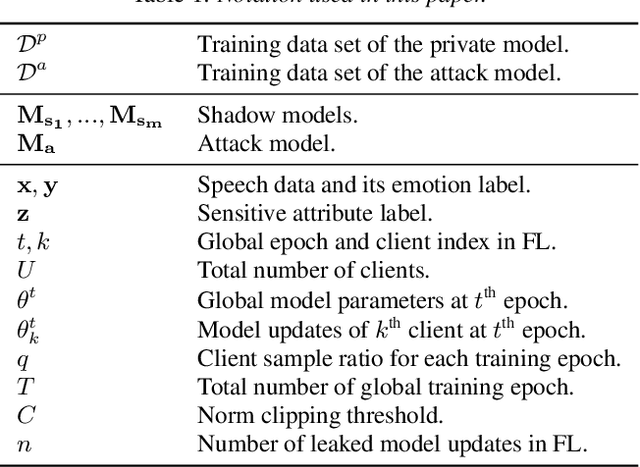
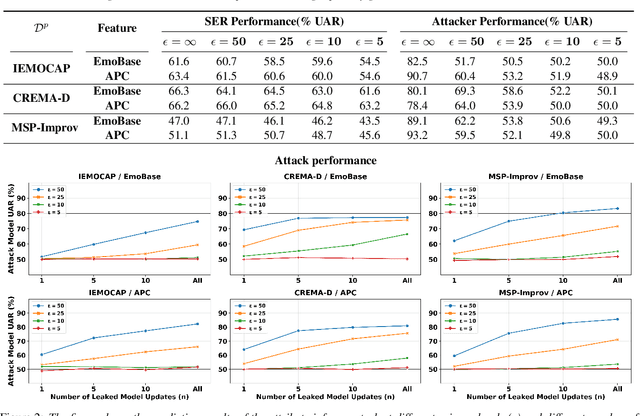
Many existing privacy-enhanced speech emotion recognition (SER) frameworks focus on perturbing the original speech data through adversarial training within a centralized machine learning setup. However, this privacy protection scheme can fail since the adversary can still access the perturbed data. In recent years, distributed learning algorithms, especially federated learning (FL), have gained popularity to protect privacy in machine learning applications. While FL provides good intuition to safeguard privacy by keeping the data on local devices, prior work has shown that privacy attacks, such as attribute inference attacks, are achievable for SER systems trained using FL. In this work, we propose to evaluate the user-level differential privacy (UDP) in mitigating the privacy leaks of the SER system in FL. UDP provides theoretical privacy guarantees with privacy parameters $\epsilon$ and $\delta$. Our results show that the UDP can effectively decrease attribute information leakage while keeping the utility of the SER system with the adversary accessing one model update. However, the efficacy of the UDP suffers when the FL system leaks more model updates to the adversary. We make the code publicly available to reproduce the results in https://github.com/usc-sail/fed-ser-leakage.
Mel Frequency Spectral Domain Defenses against Adversarial Attacks on Speech Recognition Systems
Mar 29, 2022
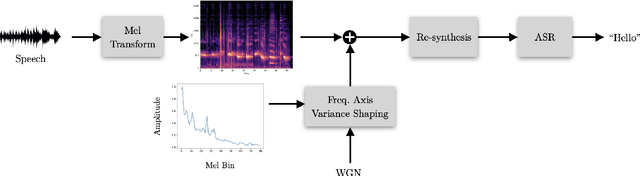

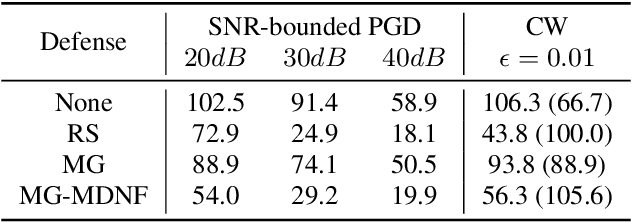
A variety of recent works have looked into defenses for deep neural networks against adversarial attacks particularly within the image processing domain. Speech processing applications such as automatic speech recognition (ASR) are increasingly relying on deep learning models, and so are also prone to adversarial attacks. However, many of the defenses explored for ASR simply adapt the image-domain defenses, which may not provide optimal robustness. This paper explores speech specific defenses using the mel spectral domain, and introduces a novel defense method called 'mel domain noise flooding' (MDNF). MDNF applies additive noise to the mel spectrogram of a speech utterance prior to re-synthesising the audio signal. We test the defenses against strong white-box adversarial attacks such as projected gradient descent (PGD) and Carlini-Wagner (CW) attacks, and show better robustness compared to a randomized smoothing baseline across strong threat models.
To train or not to train adversarially: A study of bias mitigation strategies for speaker recognition
Mar 17, 2022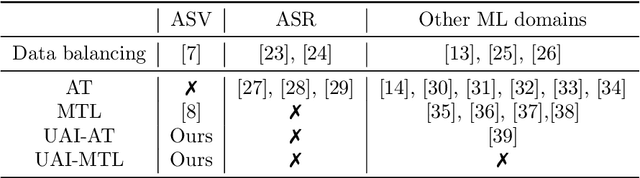
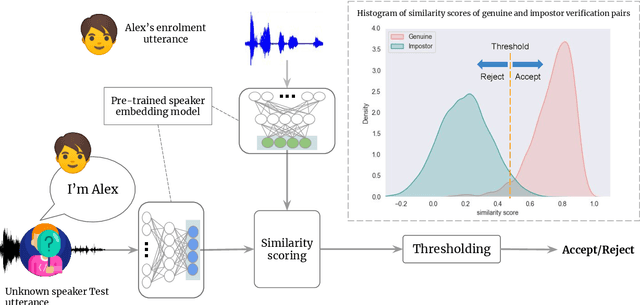
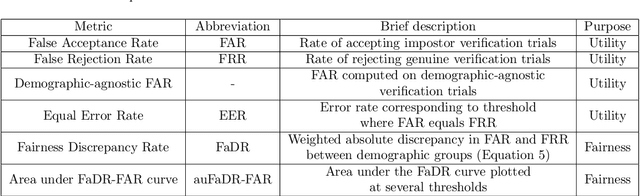
Speaker recognition is increasingly used in several everyday applications including smart speakers, customer care centers and other speech-driven analytics. It is crucial to accurately evaluate and mitigate biases present in machine learning (ML) based speech technologies, such as speaker recognition, to ensure their inclusive adoption. ML fairness studies with respect to various demographic factors in modern speaker recognition systems are lagging compared to other human-centered applications such as face recognition. Existing studies on fairness in speaker recognition systems are largely limited to evaluating biases at specific operating points of the systems, which can lead to false expectations of fairness. Moreover, there are only a handful of bias mitigation strategies developed for speaker recognition systems. In this paper, we systematically evaluate the biases present in speaker recognition systems with respect to gender across a range of system operating points. We also propose adversarial and multi-task learning techniques to improve the fairness of these systems. We show through quantitative and qualitative evaluations that the proposed methods improve the fairness of ASV systems over baseline methods trained using data balancing techniques. We also present a fairness-utility trade-off analysis to jointly examine fairness and the overall system performance. We show that although systems trained using adversarial techniques improve fairness, they are prone to reduced utility. On the other hand, multi-task methods can improve the fairness while retaining the utility. These findings can inform the choice of bias mitigation strategies in the field of speaker recognition.
Perceptual-based deep-learning denoiser as a defense against adversarial attacks on ASR systems
Jul 12, 2021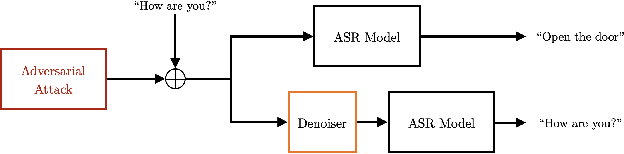
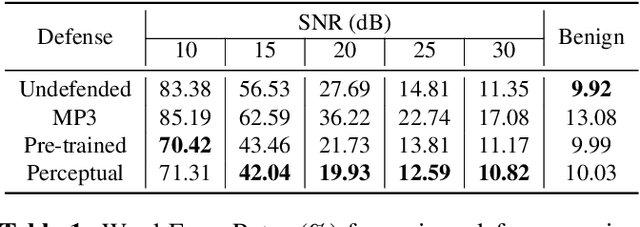
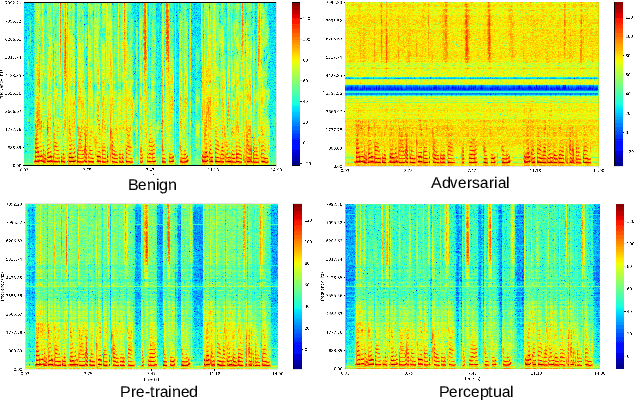
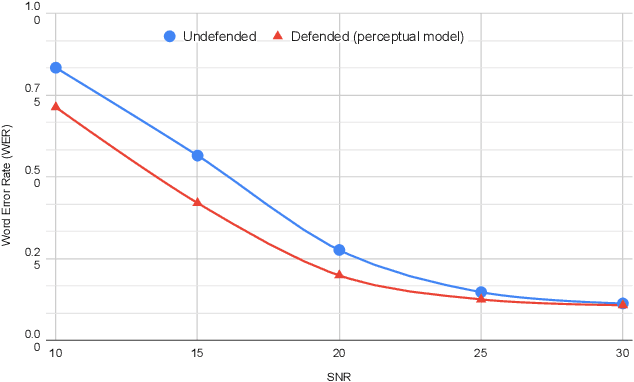
In this paper we investigate speech denoising as a defense against adversarial attacks on automatic speech recognition (ASR) systems. Adversarial attacks attempt to force misclassification by adding small perturbations to the original speech signal. We propose to counteract this by employing a neural-network based denoiser as a pre-processor in the ASR pipeline. The denoiser is independent of the downstream ASR model, and thus can be rapidly deployed in existing systems. We found that training the denoisier using a perceptually motivated loss function resulted in increased adversarial robustness without compromising ASR performance on benign samples. Our defense was evaluated (as a part of the DARPA GARD program) on the 'Kenansville' attack strategy across a range of attack strengths and speech samples. An average improvement in Word Error Rate (WER) of about 7.7% was observed over the undefended model at 20 dB signal-to-noise-ratio (SNR) attack strength.
"Am I A Good Therapist?" Automated Evaluation Of Psychotherapy Skills Using Speech And Language Technologies
Feb 22, 2021
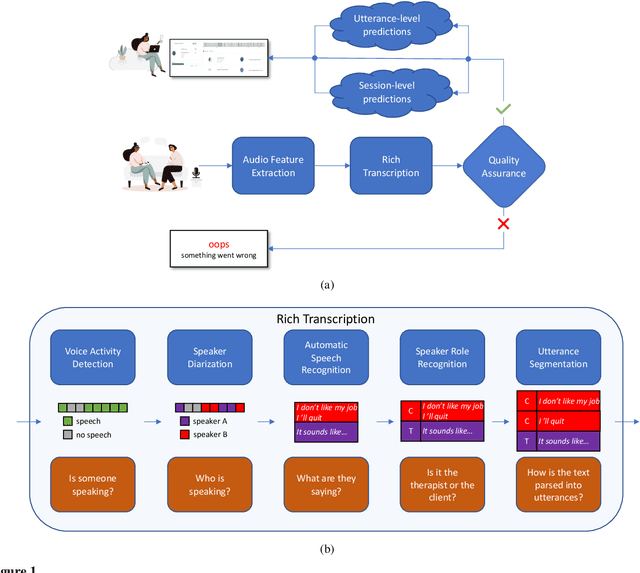
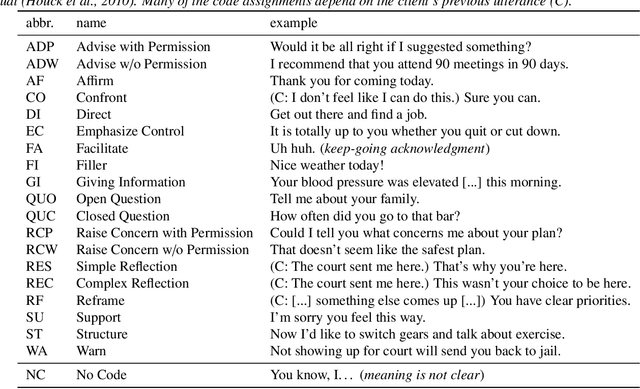
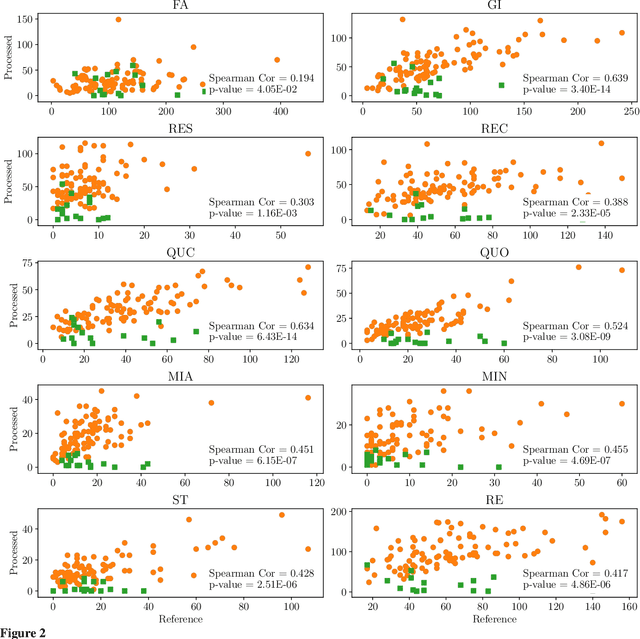
With the growing prevalence of psychological interventions, it is vital to have measures which rate the effectiveness of psychological care, in order to assist in training, supervision, and quality assurance of services. Traditionally, quality assessment is addressed by human raters who evaluate recorded sessions along specific dimensions, often codified through constructs relevant to the approach and domain. This is however a cost-prohibitive and time-consuming method which leads to poor feasibility and limited use in real-world settings. To facilitate this process, we have developed an automated competency rating tool able to process the raw recorded audio of a session, analyzing who spoke when, what they said, and how the health professional used language to provide therapy. Focusing on a use case of a specific type of psychotherapy called Motivational Interviewing, our system gives comprehensive feedback to the therapist, including information about the dynamics of the session (e.g., therapist's vs. client's talking time), low-level psychological language descriptors (e.g., type of questions asked), as well as other high-level behavioral constructs (e.g., the extent to which the therapist understands the clients' perspective). We describe our platform and its performance, using a dataset of more than 5,000 recordings drawn from its deployment in a real-world clinical setting used to assist training of new therapists. We are confident that a widespread use of automated psychotherapy rating tools in the near future will augment experts' capabilities by providing an avenue for more effective training and skill improvement and will eventually lead to more positive clinical outcomes.
Disentanglement for audio-visual emotion recognition using multitask setup
Feb 11, 2021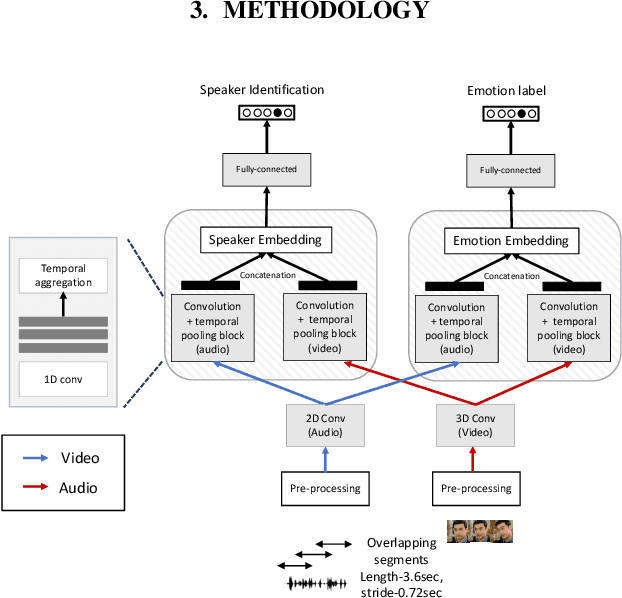
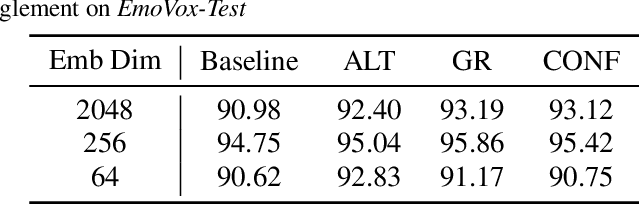
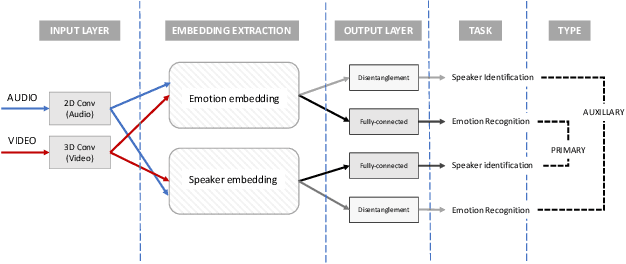
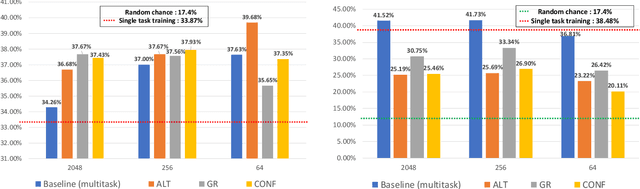
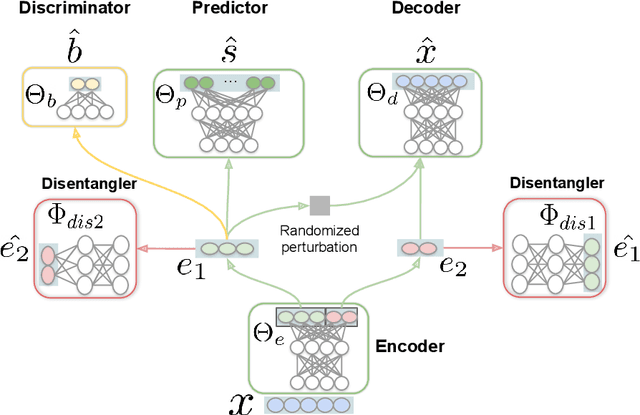
Deep learning models trained on audio-visual data have been successfully used to achieve state-of-the-art performance for emotion recognition. In particular, models trained with multitask learning have shown additional performance improvements. However, such multitask models entangle information between the tasks, encoding the mutual dependencies present in label distributions in the real world data used for training. This work explores the disentanglement of multimodal signal representations for the primary task of emotion recognition and a secondary person identification task. In particular, we developed a multitask framework to extract low-dimensional embeddings that aim to capture emotion specific information, while containing minimal information related to person identity. We evaluate three different techniques for disentanglement and report results of up to 13% disentanglement while maintaining emotion recognition performance.
Adversarial Attack and Defense Strategies for Deep Speaker Recognition Systems
Aug 18, 2020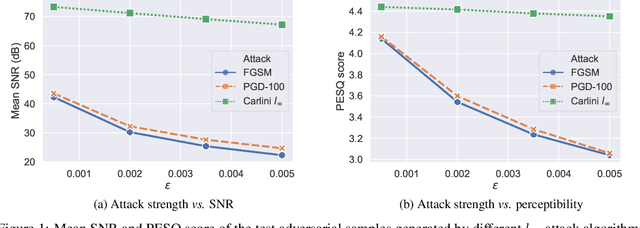
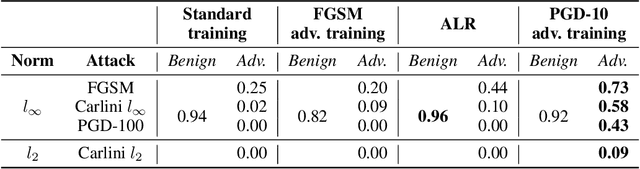
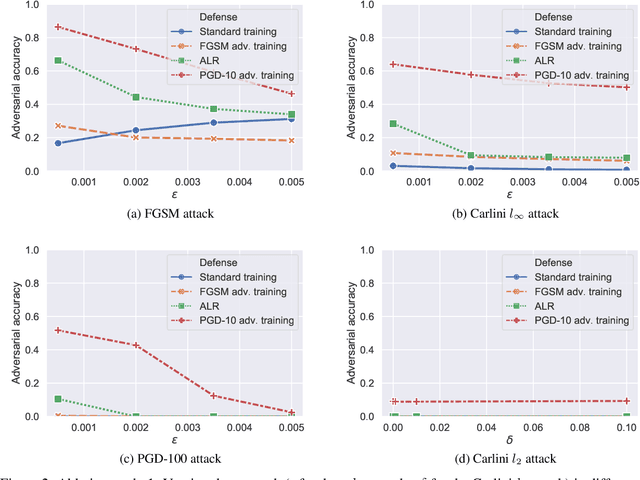

Robust speaker recognition, including in the presence of malicious attacks, is becoming increasingly important and essential, especially due to the proliferation of several smart speakers and personal agents that interact with an individual's voice commands to perform diverse, and even sensitive tasks. Adversarial attack is a recently revived domain which is shown to be effective in breaking deep neural network-based classifiers, specifically, by forcing them to change their posterior distribution by only perturbing the input samples by a very small amount. Although, significant progress in this realm has been made in the computer vision domain, advances within speaker recognition is still limited. The present expository paper considers several state-of-the-art adversarial attacks to a deep speaker recognition system, employing strong defense methods as countermeasures, and reporting on several ablation studies to obtain a comprehensive understanding of the problem. The experiments show that the speaker recognition systems are vulnerable to adversarial attacks, and the strongest attacks can reduce the accuracy of the system from 94% to even 0%. The study also compares the performances of the employed defense methods in detail, and finds adversarial training based on Projected Gradient Descent (PGD) to be the best defense method in our setting. We hope that the experiments presented in this paper provide baselines that can be useful for the research community interested in further studying adversarial robustness of speaker recognition systems.