 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"speech recognition": models, code, and papers
Towards End-to-End Training of Automatic Speech Recognition for Nigerian Pidgin
Oct 21, 2020
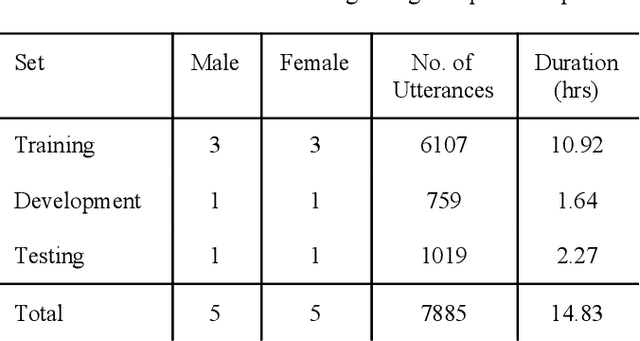
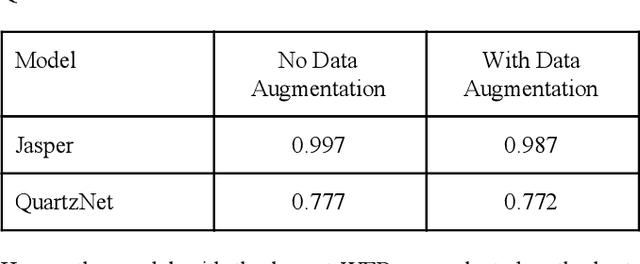
Nigerian Pidgin remains one of the most popular languages in West Africa. With at least 75 million speakers along the West African coast, the language has spread to diasporic communities through Nigerian immigrants in England, Canada, and America, amongst others. In contrast, the language remains an under-resourced one in the field of natural language processing, particularly on speech recognition and translation tasks. In this work, we present the first parallel (speech-to-text) data on Nigerian pidgin. We also trained the first end-to-end speech recognition system (QuartzNet and Jasper model) on this language which were both optimized using Connectionist Temporal Classification (CTC) loss. With baseline results, we were able to achieve a low word error rate (WER) of 0.77% using a greedy decoder on our dataset. Finally, we open-source the data and code along with this publication in order to encourage future research in this direction.
Training Autoregressive Speech Recognition Models with Limited in-domain Supervision
Oct 27, 2022
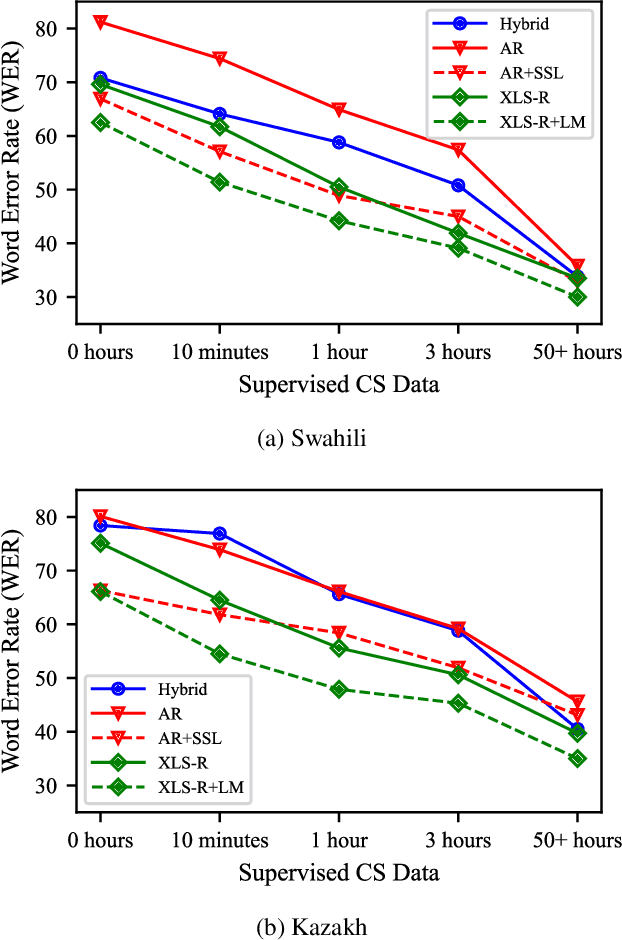

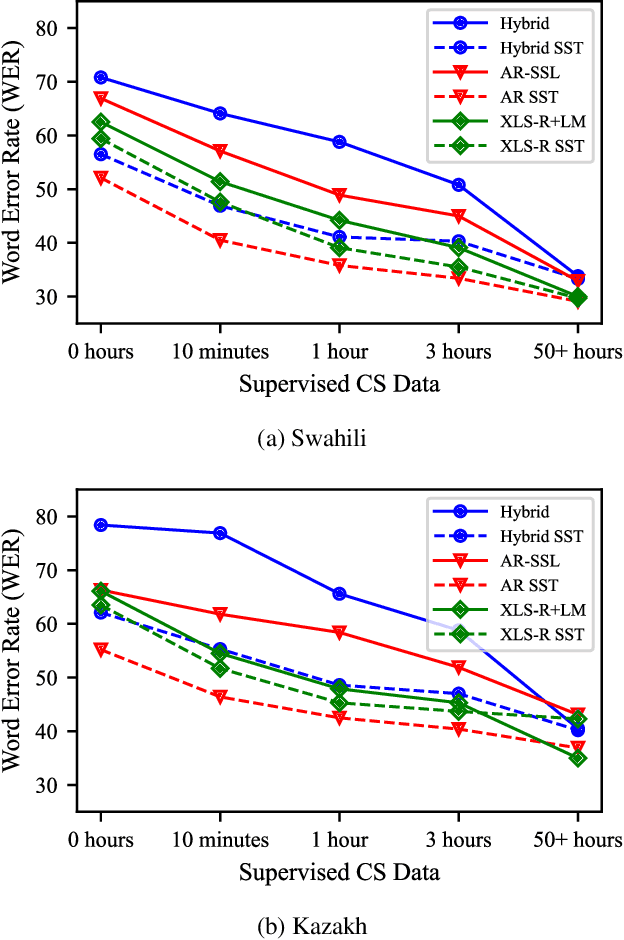
Advances in self-supervised learning have significantly reduced the amount of transcribed audio required for training. However, the majority of work in this area is focused on read speech. We explore limited supervision in the domain of conversational speech. While we assume the amount of in-domain data is limited, we augment the model with open source read speech data. The XLS-R model has been shown to perform well with limited adaptation data and serves as a strong baseline. We use untranscribed data for self-supervised learning and semi-supervised training in an autoregressive encoder-decoder model. We demonstrate that by using the XLS-R model for pseudotranscription, a much smaller autoregressive model can outperform a finetuned XLS-R model when transcribed in-domain data is limited, reducing WER by as much as 8% absolute.
Effectiveness of Text, Acoustic, and Lattice-based representations in Spoken Language Understanding tasks
Dec 16, 2022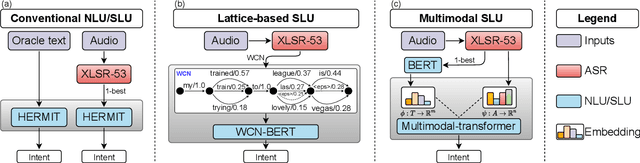
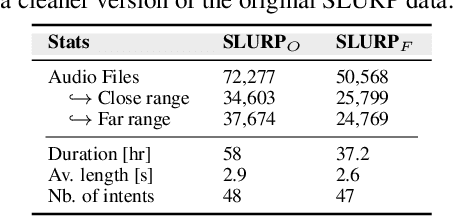
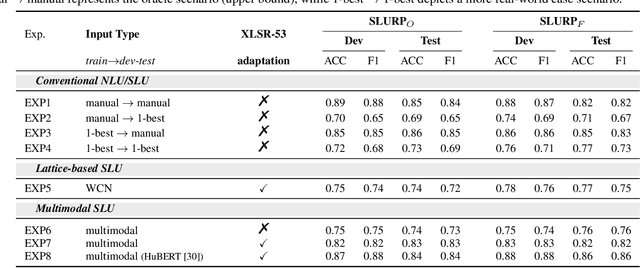

In this paper, we perform an exhaustive evaluation of different representations to address the intent classification problem in a Spoken Language Understanding (SLU) setup. We benchmark three types of systems to perform the SLU intent detection task: 1) text-based, 2) lattice-based, and a novel 3) multimodal approach. Our work provides a comprehensive analysis of what could be the achievable performance of different state-of-the-art SLU systems under different circumstances, e.g., automatically- vs. manually-generated transcripts. We evaluate the systems on the publicly available SLURP spoken language resource corpus. Our results indicate that using richer forms of Automatic Speech Recognition (ASR) outputs allows SLU systems to improve in comparison to the 1-best setup (4% relative improvement). However, crossmodal approaches, i.e., learning from acoustic and text embeddings, obtains performance similar to the oracle setup, and a relative improvement of 18% over the 1-best configuration. Thus, crossmodal architectures represent a good alternative to overcome the limitations of working purely automatically generated textual data.
On the Usefulness of Self-Attention for Automatic Speech Recognition with Transformers
Nov 08, 2020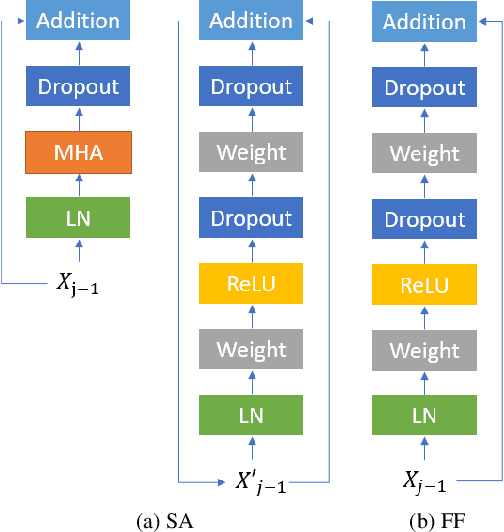
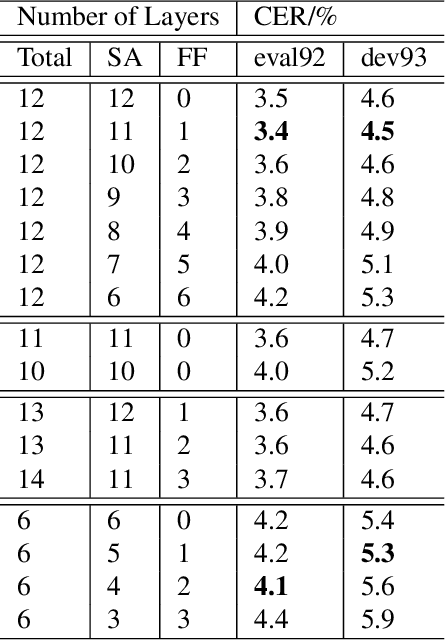
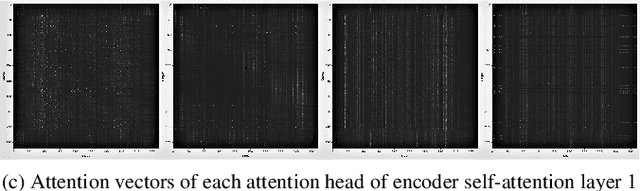
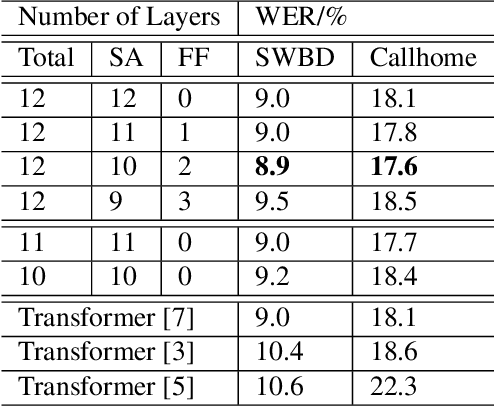
Self-attention models such as Transformers, which can capture temporal relationships without being limited by the distance between events, have given competitive speech recognition results. However, we note the range of the learned context increases from the lower to upper self-attention layers, whilst acoustic events often happen within short time spans in a left-to-right order. This leads to a question: for speech recognition, is a global view of the entire sequence useful for the upper self-attention encoder layers in Transformers? To investigate this, we train models with lower self-attention/upper feed-forward layers encoders on Wall Street Journal and Switchboard. Compared to baseline Transformers, no performance drop but minor gains are observed. We further developed a novel metric of the diagonality of attention matrices and found the learned diagonality indeed increases from the lower to upper encoder self-attention layers. We conclude the global view is unnecessary in training upper encoder layers.
Improving non-autoregressive end-to-end speech recognition with pre-trained acoustic and language models
Jan 26, 2022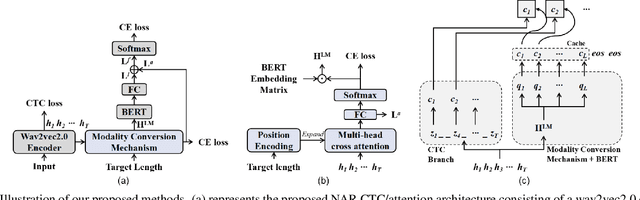
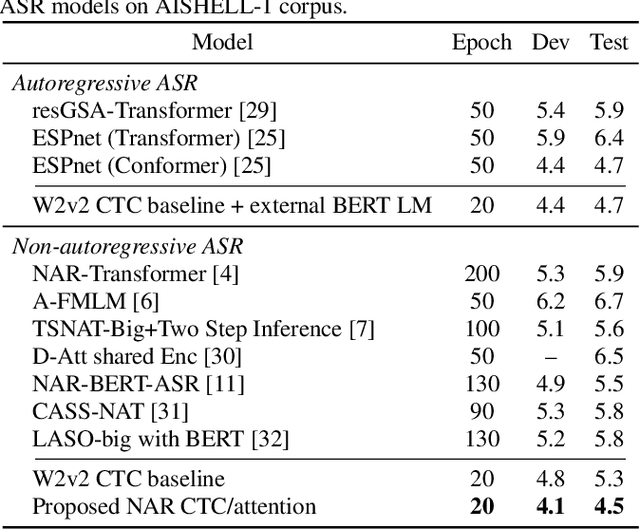
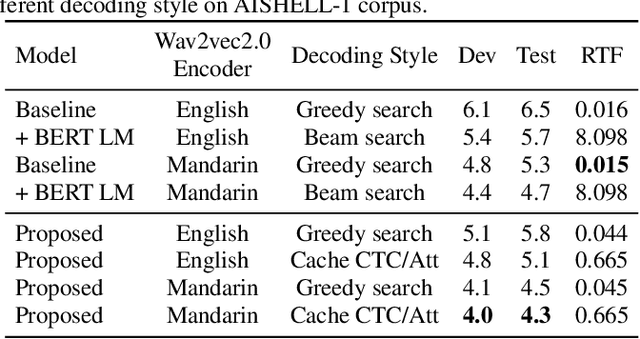
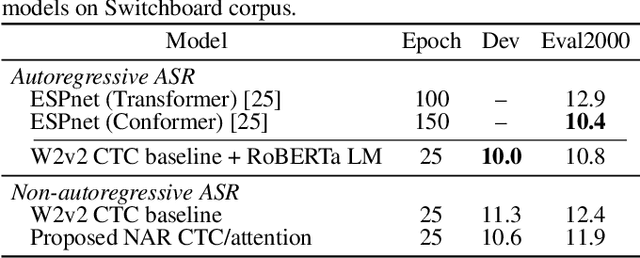
While Transformers have achieved promising results in end-to-end (E2E) automatic speech recognition (ASR), their autoregressive (AR) structure becomes a bottleneck for speeding up the decoding process. For real-world deployment, ASR systems are desired to be highly accurate while achieving fast inference. Non-autoregressive (NAR) models have become a popular alternative due to their fast inference speed, but they still fall behind AR systems in recognition accuracy. To fulfill the two demands, in this paper, we propose a NAR CTC/attention model utilizing both pre-trained acoustic and language models: wav2vec2.0 and BERT. To bridge the modality gap between speech and text representations obtained from the pre-trained models, we design a novel modality conversion mechanism, which is more suitable for logographic languages. During inference, we employ a CTC branch to generate a target length, which enables the BERT to predict tokens in parallel. We also design a cache-based CTC/attention joint decoding method to improve the recognition accuracy while keeping the decoding speed fast. Experimental results show that the proposed NAR model greatly outperforms our strong wav2vec2.0 CTC baseline (15.1% relative CER reduction on AISHELL-1). The proposed NAR model significantly surpasses previous NAR systems on the AISHELL-1 benchmark and shows a potential for English tasks.
Exploring Wav2vec 2.0 fine-tuning for improved speech emotion recognition
Oct 28, 2021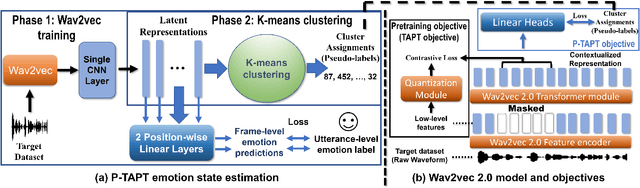
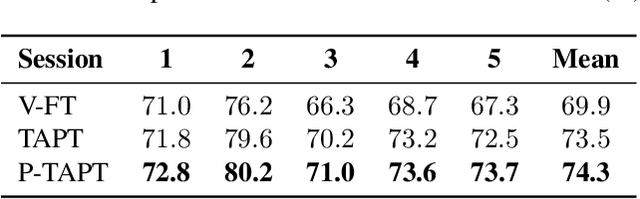
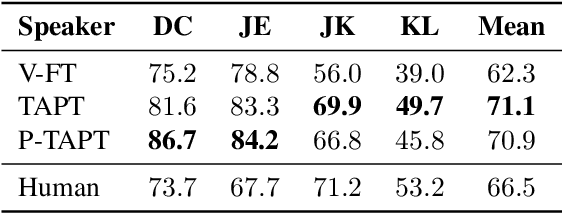

While wav2vec 2.0 has been proposed for speech recognition (ASR), it can also be used for speech emotion recognition (SER); its performance can be significantly improved using different fine-tuning strategies. Two baseline methods, vanilla fine-tuning (V-FT) and task adaptive pretraining (TAPT) are first presented. We show that V-FT is able to outperform state-of-the-art models on the IEMOCAP dataset. TAPT, an existing NLP fine-tuning strategy, further improves the performance on SER. We also introduce a novel fine-tuning method termed P-TAPT, which modifies the TAPT objective to learn contextualized emotion representations. Experiments show that P-TAPT performs better than TAPT especially under low-resource settings. Compared to prior works in this literature, our top-line system achieved a 7.4% absolute improvement on unweighted accuracy (UA) over the state-of-the-art performance on IEMOCAP. Our code is publicly available.
Multimodal Speech Recognition with Unstructured Audio Masking
Oct 16, 2020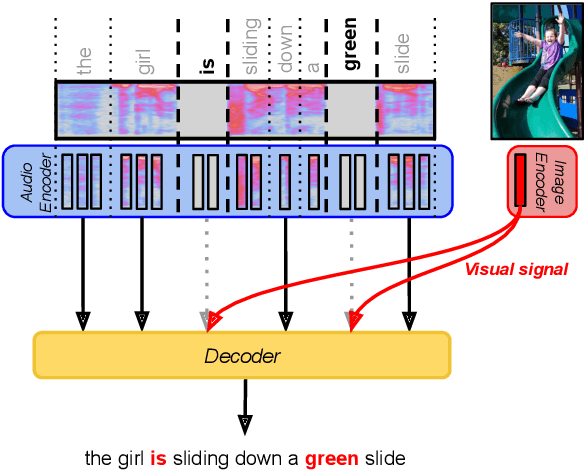
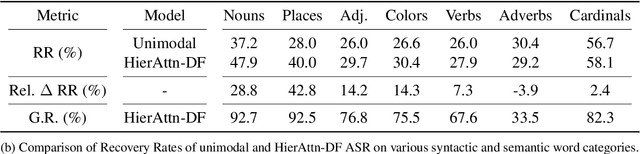
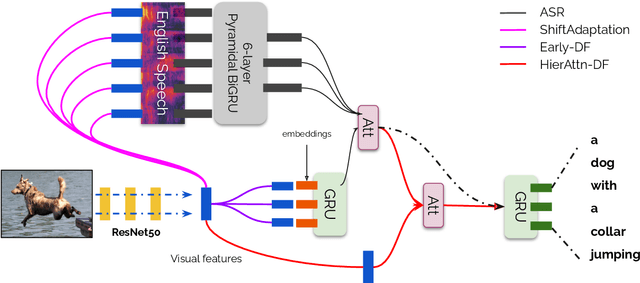
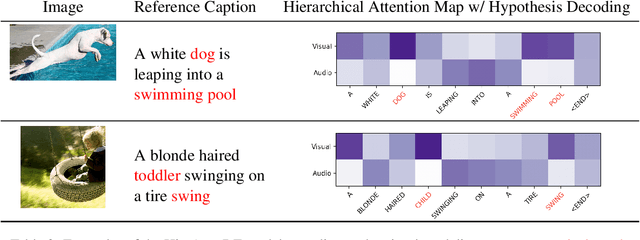
Visual context has been shown to be useful for automatic speech recognition (ASR) systems when the speech signal is noisy or corrupted. Previous work, however, has only demonstrated the utility of visual context in an unrealistic setting, where a fixed set of words are systematically masked in the audio. In this paper, we simulate a more realistic masking scenario during model training, called RandWordMask, where the masking can occur for any word segment. Our experiments on the Flickr 8K Audio Captions Corpus show that multimodal ASR can generalize to recover different types of masked words in this unstructured masking setting. Moreover, our analysis shows that our models are capable of attending to the visual signal when the audio signal is corrupted. These results show that multimodal ASR systems can leverage the visual signal in more generalized noisy scenarios.
Improving Transformer-based Speech Recognition Using Unsupervised Pre-training
Oct 31, 2019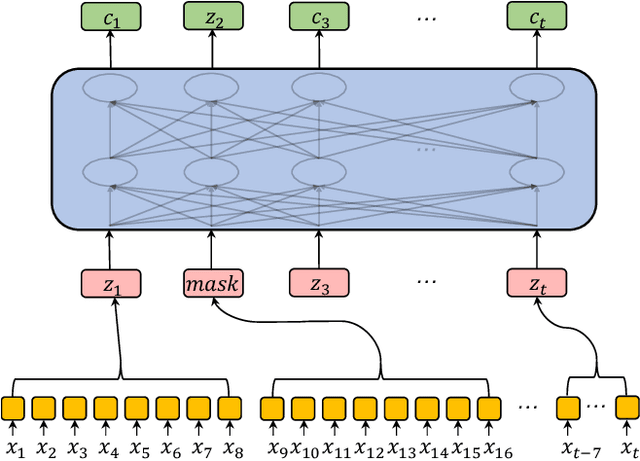
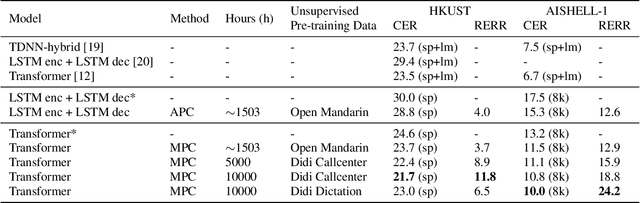
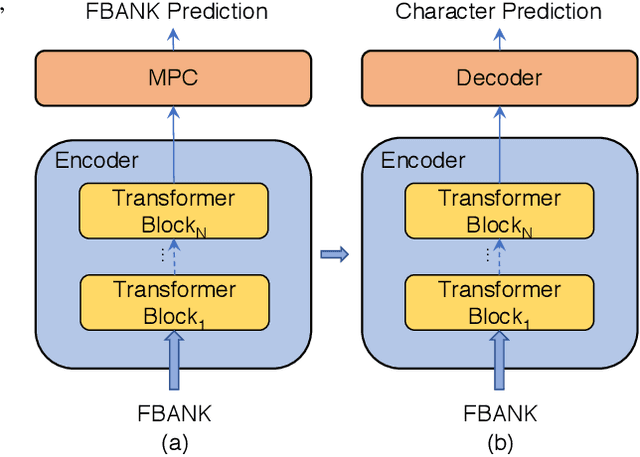
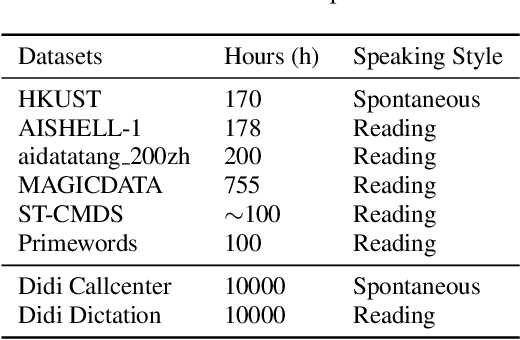
Speech recognition technologies are gaining enormous popularity in various industrial applications. However, building a good speech recognition system usually requires large amounts of transcribed data, which is expensive to collect. To tackle this problem, an unsupervised pre-training method called Masked Predictive Coding is proposed, which can be applied for unsupervised pre-training with Transformer based model. Experiments on HKUST show that using the same training data, we can achieve CER 23.3%, exceeding the best end-to-end model by over 0.2% absolute CER. With more pre-training data, we can further reduce the CER to 21.0%, or a 11.8% relative CER reduction over baseline.
English Broadcast News Speech Recognition by Humans and Machines
Apr 30, 2019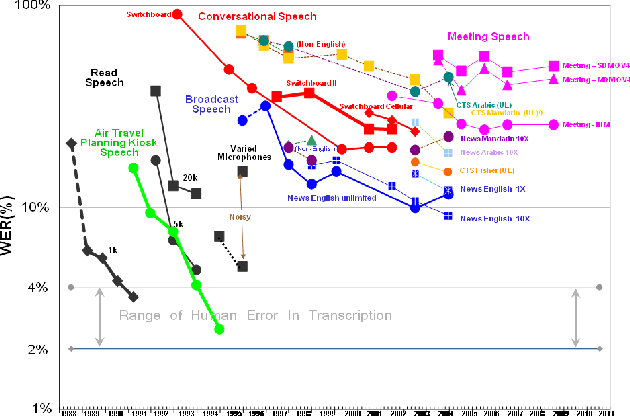
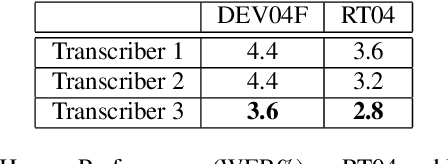


With recent advances in deep learning, considerable attention has been given to achieving automatic speech recognition performance close to human performance on tasks like conversational telephone speech (CTS) recognition. In this paper we evaluate the usefulness of these proposed techniques on broadcast news (BN), a similar challenging task. We also perform a set of recognition measurements to understand how close the achieved automatic speech recognition results are to human performance on this task. On two publicly available BN test sets, DEV04F and RT04, our speech recognition system using LSTM and residual network based acoustic models with a combination of n-gram and neural network language models performs at 6.5% and 5.9% word error rate. By achieving new performance milestones on these test sets, our experiments show that techniques developed on other related tasks, like CTS, can be transferred to achieve similar performance. In contrast, the best measured human recognition performance on these test sets is much lower, at 3.6% and 2.8% respectively, indicating that there is still room for new techniques and improvements in this space, to reach human performance levels.