 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"speech recognition": models, code, and papers
A Multimodal Dynamical Variational Autoencoder for Audiovisual Speech Representation Learning
May 05, 2023
In this paper, we present a multimodal \textit{and} dynamical VAE (MDVAE) applied to unsupervised audio-visual speech representation learning. The latent space is structured to dissociate the latent dynamical factors that are shared between the modalities from those that are specific to each modality. A static latent variable is also introduced to encode the information that is constant over time within an audiovisual speech sequence. The model is trained in an unsupervised manner on an audiovisual emotional speech dataset, in two stages. In the first stage, a vector quantized VAE (VQ-VAE) is learned independently for each modality, without temporal modeling. The second stage consists in learning the MDVAE model on the intermediate representation of the VQ-VAEs before quantization. The disentanglement between static versus dynamical and modality-specific versus modality-common information occurs during this second training stage. Extensive experiments are conducted to investigate how audiovisual speech latent factors are encoded in the latent space of MDVAE. These experiments include manipulating audiovisual speech, audiovisual facial image denoising, and audiovisual speech emotion recognition. The results show that MDVAE effectively combines the audio and visual information in its latent space. They also show that the learned static representation of audiovisual speech can be used for emotion recognition with few labeled data, and with better accuracy compared with unimodal baselines and a state-of-the-art supervised model based on an audiovisual transformer architecture.
Beyond Universal Transformer: block reusing with adaptor in Transformer for automatic speech recognit
Mar 23, 2023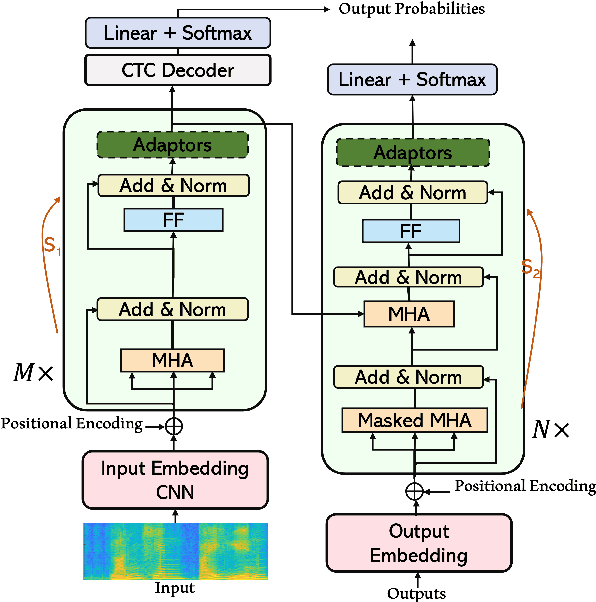
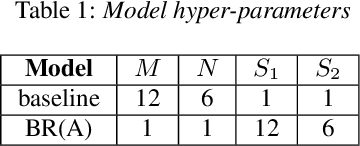
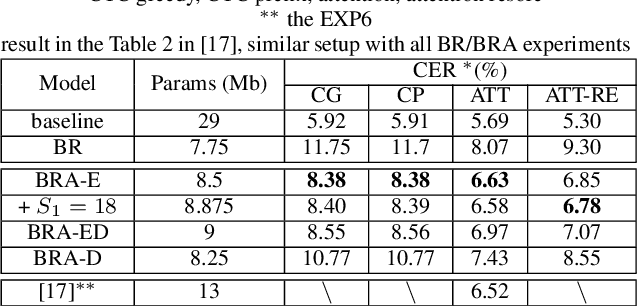
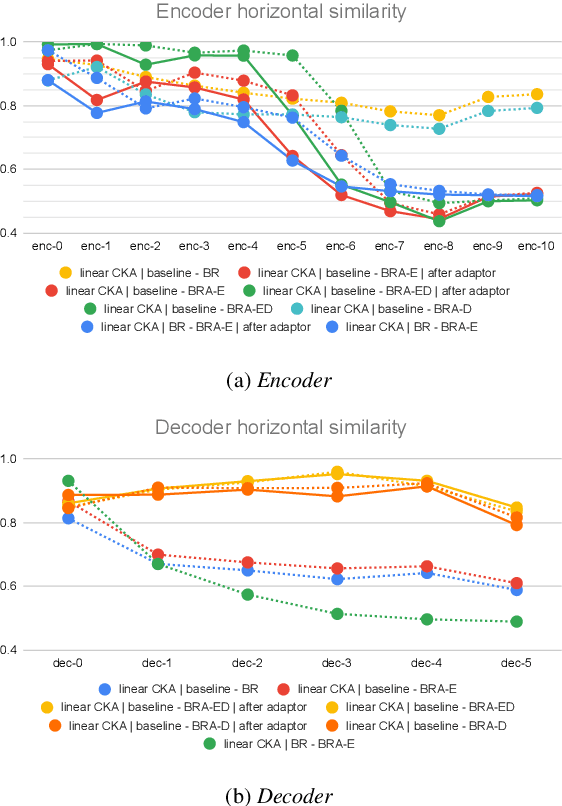
Transformer-based models have recently made significant achievements in the application of end-to-end (E2E) automatic speech recognition (ASR). It is possible to deploy the E2E ASR system on smart devices with the help of Transformer-based models. While these models still have the disadvantage of requiring a large number of model parameters. To overcome the drawback of universal Transformer models for the application of ASR on edge devices, we propose a solution that can reuse the block in Transformer models for the occasion of the small footprint ASR system, which meets the objective of accommodating resource limitations without compromising recognition accuracy. Specifically, we design a novel block-reusing strategy for speech Transformer (BRST) to enhance the effectiveness of parameters and propose an adapter module (ADM) that can produce a compact and adaptable model with only a few additional trainable parameters accompanying each reusing block. We conducted an experiment with the proposed method on the public AISHELL-1 corpus, and the results show that the proposed approach achieves the character error rate (CER) of 9.3%/6.63% with only 7.6M/8.3M parameters without and with the ADM, respectively. In addition, we also make a deeper analysis to show the effect of ADM in the general block-reusing method.
Knowledge-driven Subword Grammar Modeling for Automatic Speech Recognition in Tamil and Kannada
Jul 27, 2022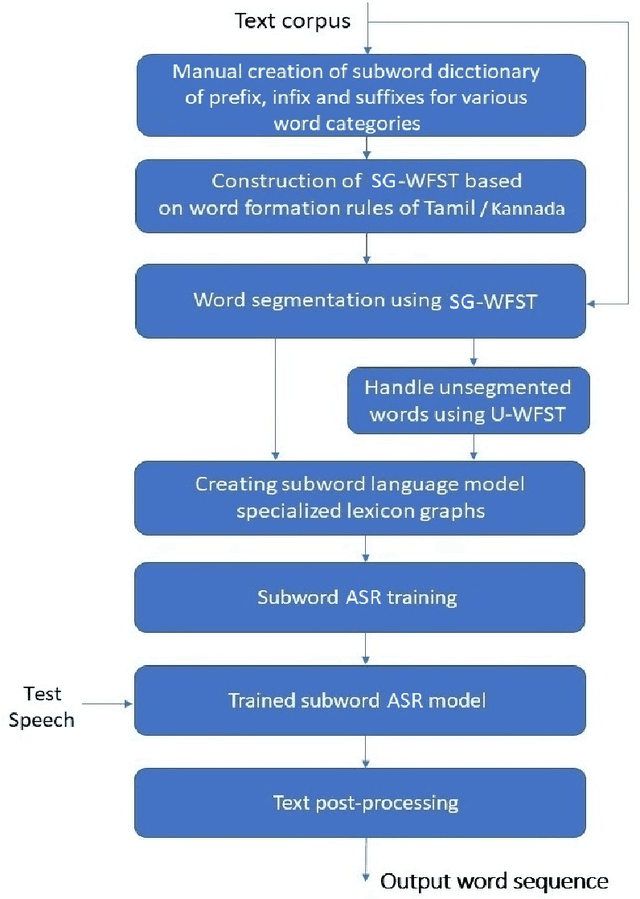
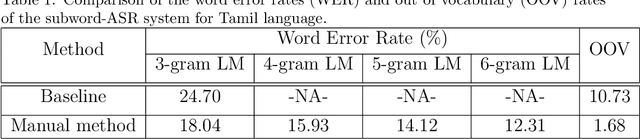
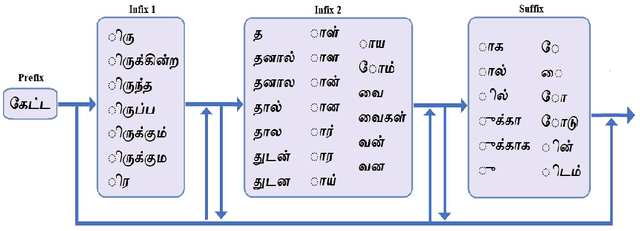
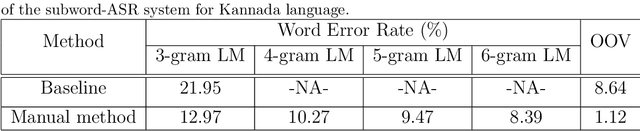
In this paper, we present specially designed automatic speech recognition (ASR) systems for the highly agglutinative and inflective languages of Tamil and Kannada that can recognize unlimited vocabulary of words. We use subwords as the basic lexical units for recognition and construct subword grammar weighted finite state transducer (SG-WFST) graphs for word segmentation that captures most of the complex word formation rules of the languages. We have identified the following category of words (i) verbs, (ii) nouns, (ii) pronouns, and (iv) numbers. The prefix, infix and suffix lists of subwords are created for each of these categories and are used to design the SG-WFST graphs. We also present a heuristic segmentation algorithm that can even segment exceptional words that do not follow the rules encapsulated in the SG-WFST graph. Most of the data-driven subword dictionary creation algorithms are computation driven, and hence do not guarantee morpheme-like units and so we have used the linguistic knowledge of the languages and manually created the subword dictionaries and the graphs. Finally, we train a deep neural network acoustic model and combine it with the pronunciation lexicon of the subword dictionary and the SG-WFST graph to build the subword-ASR systems. Since the subword-ASR produces subword sequences as output for a given test speech, we post-process its output to get the final word sequence, so that the actual number of words that can be recognized is much higher. Upon experimenting the subword-ASR system with the IISc-MILE Tamil and Kannada ASR corpora, we observe an absolute word error rate reduction of 12.39% and 13.56% over the baseline word-based ASR systems for Tamil and Kannada, respectively.
UML: A Universal Monolingual Output Layer for Multilingual ASR
Feb 22, 2023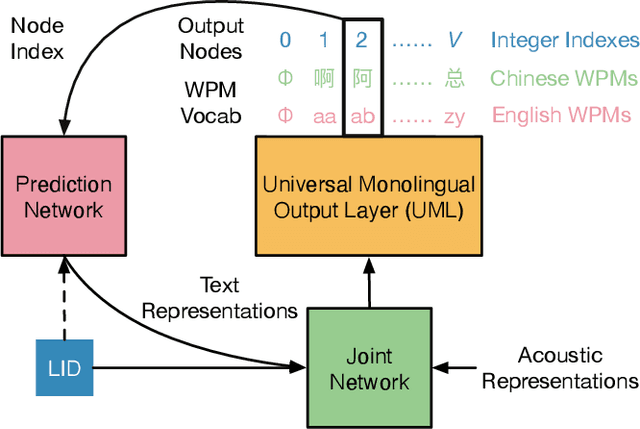
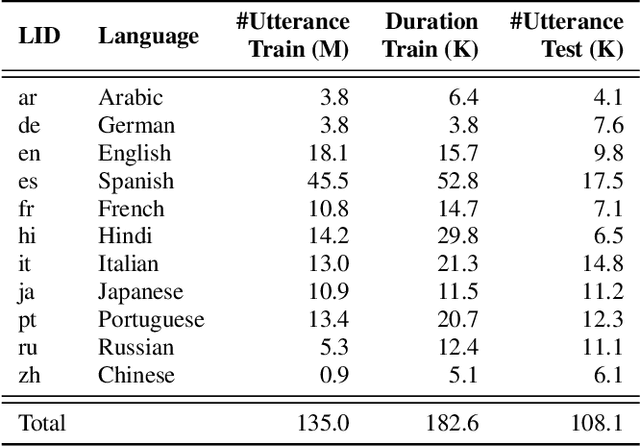
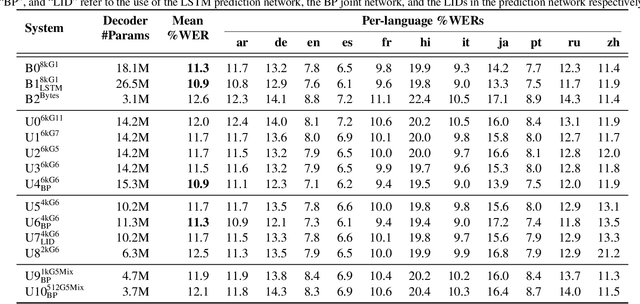
Word-piece models (WPMs) are commonly used subword units in state-of-the-art end-to-end automatic speech recognition (ASR) systems. For multilingual ASR, due to the differences in written scripts across languages, multilingual WPMs bring the challenges of having overly large output layers and scaling to more languages. In this work, we propose a universal monolingual output layer (UML) to address such problems. Instead of one output node for only one WPM, UML re-associates each output node with multiple WPMs, one for each language, and results in a smaller monolingual output layer shared across languages. Consequently, the UML enables to switch in the interpretation of each output node depending on the language of the input speech. Experimental results on an 11-language voice search task demonstrated the feasibility of using UML for high-quality and high-efficiency multilingual streaming ASR.
Multitask Learning for Grapheme-to-Phoneme Conversion of Anglicisms in German Speech Recognition
May 26, 2021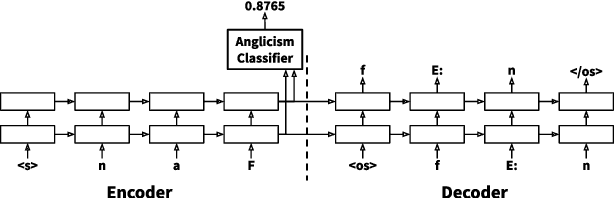

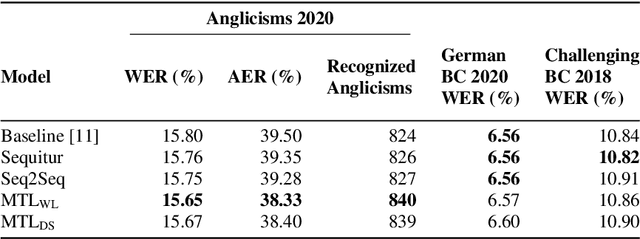

Loanwords, such as Anglicisms, are a challenge in German speech recognition. Due to their irregular pronunciation compared to native German words, automatically generated pronunciation dictionaries often include faulty phoneme sequences for Anglicisms. In this work, we propose a multitask sequence-to-sequence approach for grapheme-to-phoneme conversion to improve the phonetization of Anglicisms. We extended a grapheme-to-phoneme model with a classifier to distinguish Anglicisms from native German words. With this approach, the model learns to generate pronunciations differently depending on the classification result. We used our model to create supplementary Anglicism pronunciation dictionaries that are added to an existing German speech recognition model. Tested on a dedicated Anglicism evaluation set, we improved the recognition of Anglicisms compared to a baseline model, reducing the word error rate by 1 % and the Anglicism error rate by 3 %. We show that multitask learning can help solving the challenge of loanwords in German speech recognition.
Efficient Ensemble Architecture for Multimodal Acoustic and Textual Embeddings in Punctuation Restoration using Time-Delay Neural Networks
Feb 26, 2023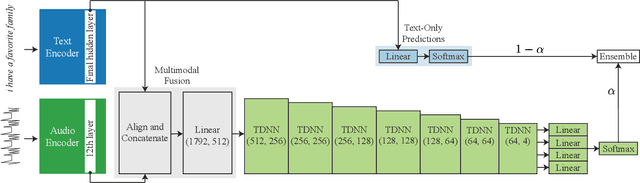

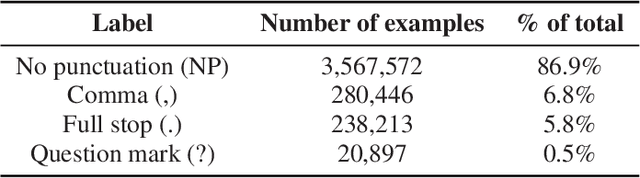
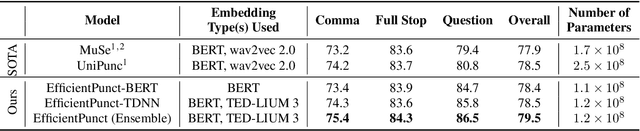
Punctuation restoration plays an essential role in the post-processing procedure of automatic speech recognition, but model efficiency is a key requirement for this task. To that end, we present EfficientPunct, an ensemble method with a multimodal time-delay neural network that outperforms the current best model by 1.0 F1 points, using less than a tenth of its parameters to process embeddings. We streamline a speech recognizer to efficiently output hidden layer latent vectors as audio embeddings for punctuation restoration, as well as BERT to extract meaningful text embeddings. By using forced alignment and temporal convolutions, we eliminate the need for multi-head attention-based fusion, greatly increasing computational efficiency but also raising performance. EfficientPunct sets a new state of the art, in terms of both performance and efficiency, with an ensemble that weights BERT's purely language-based predictions slightly more than the multimodal network's predictions.
Streaming end-to-end speech recognition with jointly trained neural feature enhancement
May 04, 2021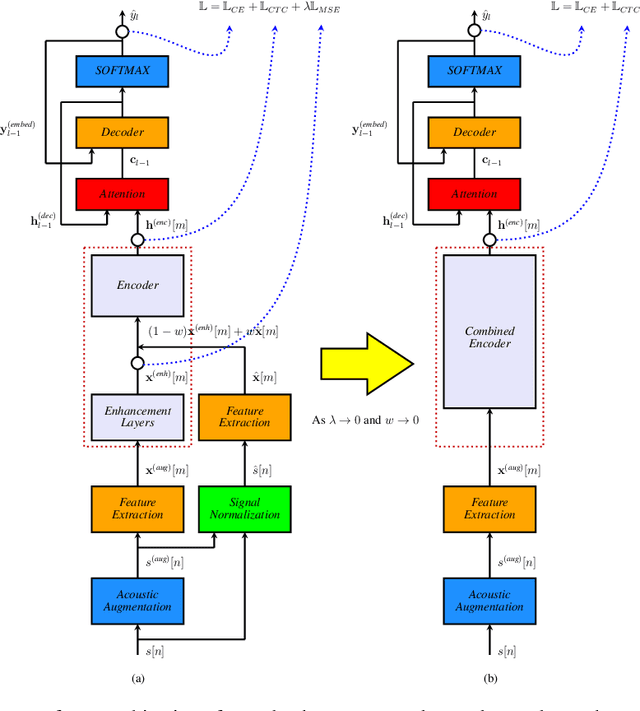
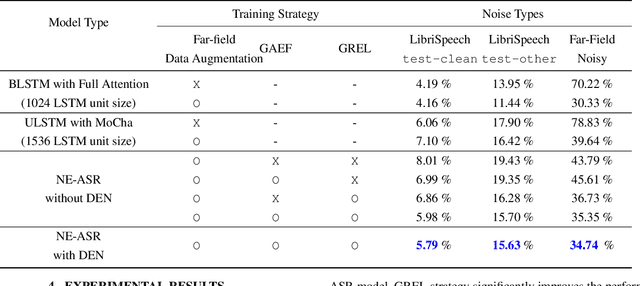
In this paper, we present a streaming end-to-end speech recognition model based on Monotonic Chunkwise Attention (MoCha) jointly trained with enhancement layers. Even though the MoCha attention enables streaming speech recognition with recognition accuracy comparable to a full attention-based approach, training this model is sensitive to various factors such as the difficulty of training examples, hyper-parameters, and so on. Because of these issues, speech recognition accuracy of a MoCha-based model for clean speech drops significantly when a multi-style training approach is applied. Inspired by Curriculum Learning [1], we introduce two training strategies: Gradual Application of Enhanced Features (GAEF) and Gradual Reduction of Enhanced Loss (GREL). With GAEF, the model is initially trained using clean features. Subsequently, the portion of outputs from the enhancement layers gradually increases. With GREL, the portion of the Mean Squared Error (MSE) loss for the enhanced output gradually reduces as training proceeds. In experimental results on the LibriSpeech corpus and noisy far-field test sets, the proposed model with GAEF-GREL training strategies shows significantly better results than the conventional multi-style training approach.
Speech Recognition with Augmented Synthesized Speech
Sep 25, 2019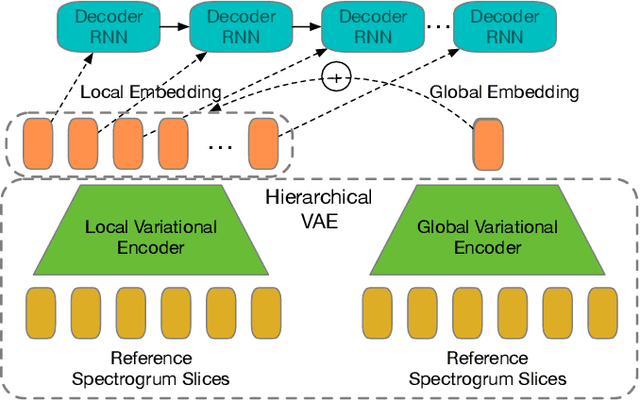
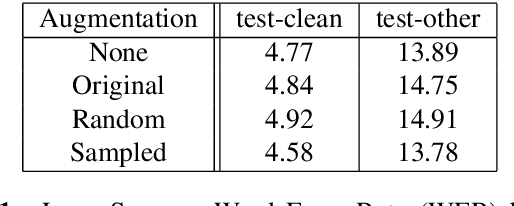
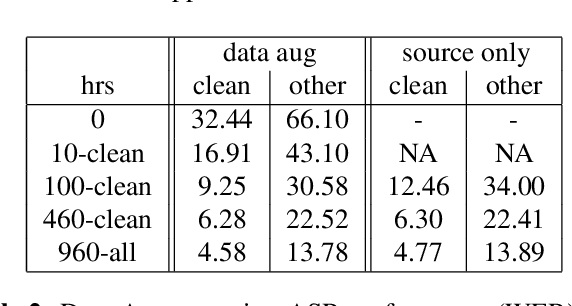
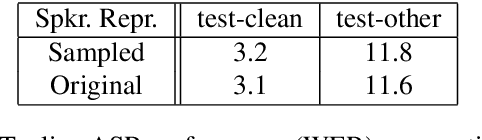
Recent success of the Tacotron speech synthesis architecture and its variants in producing natural sounding multi-speaker synthesized speech has raised the exciting possibility of replacing expensive, manually transcribed, domain-specific, human speech that is used to train speech recognizers. The multi-speaker speech synthesis architecture can learn latent embedding spaces of prosody, speaker and style variations derived from input acoustic representations thereby allowing for manipulation of the synthesized speech. In this paper, we evaluate the feasibility of enhancing speech recognition performance using speech synthesis using two corpora from different domains. We explore algorithms to provide the necessary acoustic and lexical diversity needed for robust speech recognition. Finally, we demonstrate the feasibility of this approach as a data augmentation strategy for domain-transfer. We find that improvements to speech recognition performance is achievable by augmenting training data with synthesized material. However, there remains a substantial gap in performance between recognizers trained on human speech those trained on synthesized speech.
The NTNU System for Formosa Speech Recognition Challenge 2020
Apr 20, 2021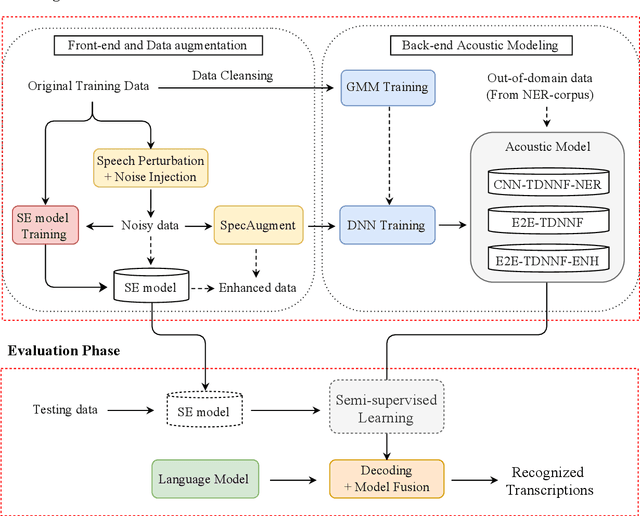
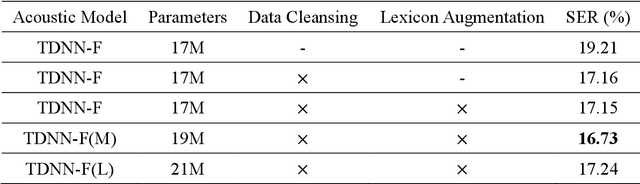
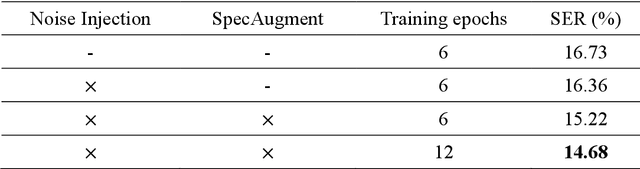
This paper describes the NTNU ASR system participating in the Formosa Speech Recognition Challenge 2020 (FSR-2020) supported by the Formosa Speech in the Wild project (FSW). FSR-2020 aims at fostering the development of Taiwanese speech recognition. Apart from the issues on tonal and dialectical variations of the Taiwanese language, speech artificially contaminated with different types of real-world noise also has to be dealt with in the final test stage; all of these make FSR-2020 much more challenging than before. To work around the under-resourced issue, the main technical aspects of our ASR system include various deep learning techniques, such as transfer learning, semi-supervised learning, front-end speech enhancement and model ensemble, as well as data cleansing and data augmentation conducted on the training data. With the best configuration, our system takes the first place among all participating systems in Track 3.
A comparison of streaming models and data augmentation methods for robust speech recognition
Nov 19, 2021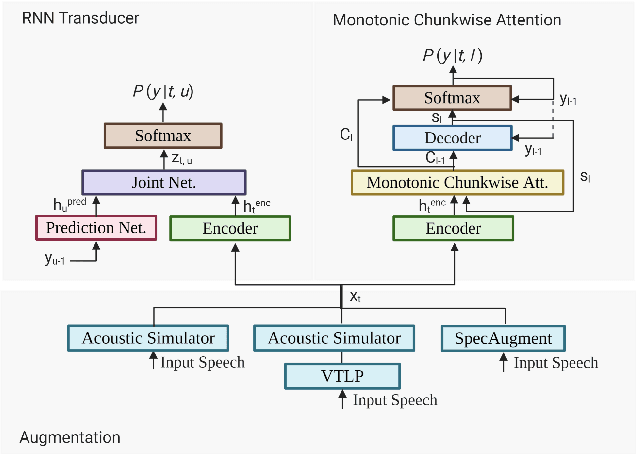


In this paper, we present a comparative study on the robustness of two different online streaming speech recognition models: Monotonic Chunkwise Attention (MoChA) and Recurrent Neural Network-Transducer (RNN-T). We explore three recently proposed data augmentation techniques, namely, multi-conditioned training using an acoustic simulator, Vocal Tract Length Perturbation (VTLP) for speaker variability, and SpecAugment. Experimental results show that unidirectional models are in general more sensitive to noisy examples in the training set. It is observed that the final performance of the model depends on the proportion of training examples processed by data augmentation techniques. MoChA models generally perform better than RNN-T models. However, we observe that training of MoChA models seems to be more sensitive to various factors such as the characteristics of training sets and the incorporation of additional augmentations techniques. On the other hand, RNN-T models perform better than MoChA models in terms of latency, inference time, and the stability of training. Additionally, RNN-T models are generally more robust against noise and reverberation. All these advantages make RNN-T models a better choice for streaming on-device speech recognition compared to MoChA models.