 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"photo": models, code, and papers
Few-shot Semantic Image Synthesis with Class Affinity Transfer
Apr 05, 2023

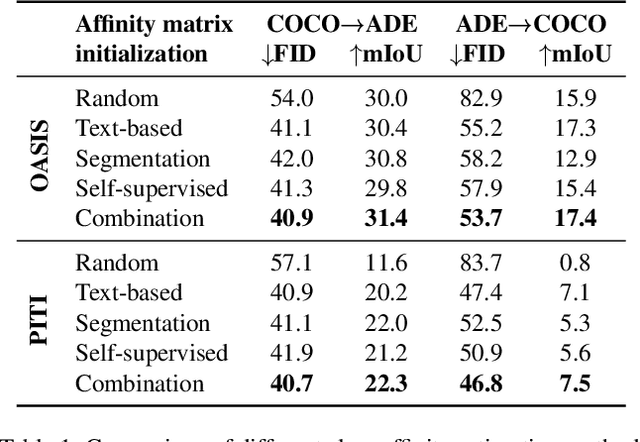
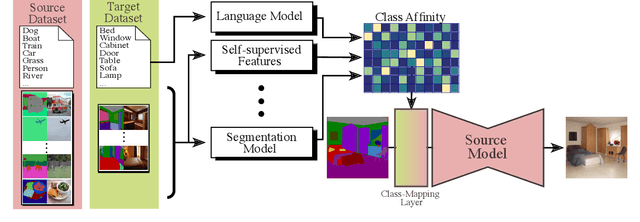
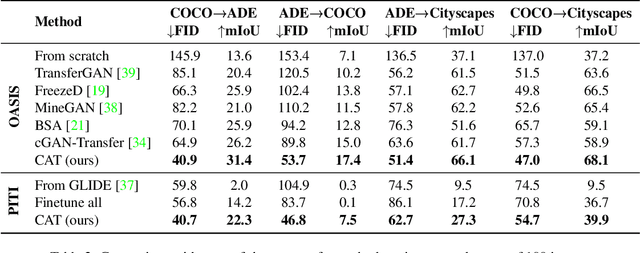
Semantic image synthesis aims to generate photo realistic images given a semantic segmentation map. Despite much recent progress, training them still requires large datasets of images annotated with per-pixel label maps that are extremely tedious to obtain. To alleviate the high annotation cost, we propose a transfer method that leverages a model trained on a large source dataset to improve the learning ability on small target datasets via estimated pairwise relations between source and target classes. The class affinity matrix is introduced as a first layer to the source model to make it compatible with the target label maps, and the source model is then further finetuned for the target domain. To estimate the class affinities we consider different approaches to leverage prior knowledge: semantic segmentation on the source domain, textual label embeddings, and self-supervised vision features. We apply our approach to GAN-based and diffusion-based architectures for semantic synthesis. Our experiments show that the different ways to estimate class affinity can be effectively combined, and that our approach significantly improves over existing state-of-the-art transfer approaches for generative image models.
If At First You Don't Succeed: Test Time Re-ranking for Zero-shot, Cross-domain Retrieval
Mar 30, 2023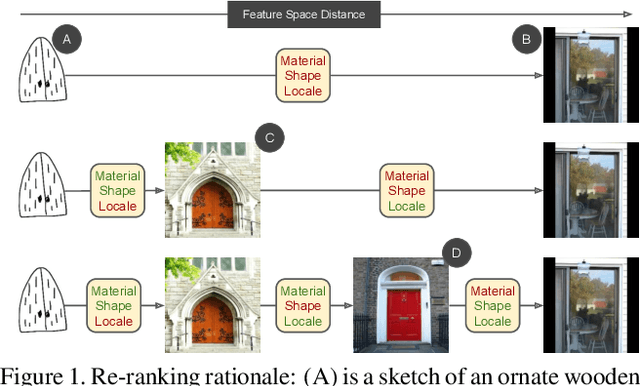
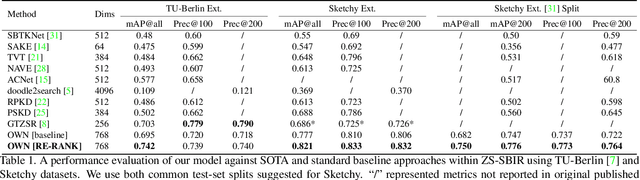
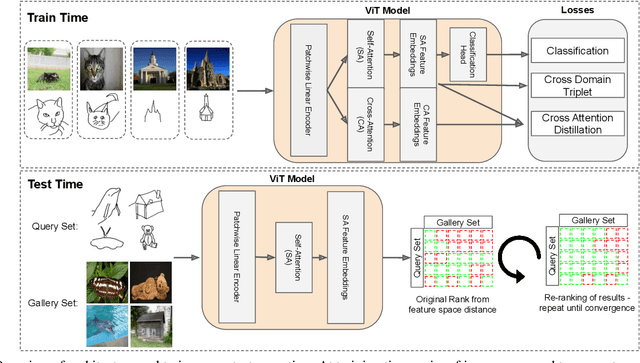
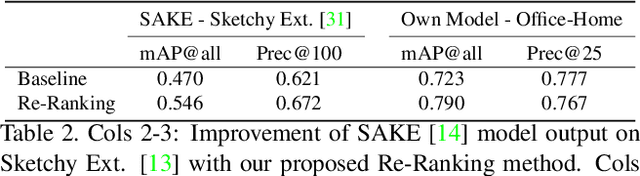
In this paper we propose a novel method for zero-shot, cross-domain image retrieval in which we make two key contributions. The first is a test-time re-ranking procedure that enables query-gallery pairs, without meaningful shared visual features, to be matched by incorporating gallery-gallery ranks into an iterative re-ranking process. The second is the use of cross-attention at training time and knowledge distillation to encourage cross-attention-like features to be extracted at test time from a single image. When combined with the Vision Transformer architecture and zero-shot retrieval losses, our approach yields state-of-the-art results on the Sketchy and TU-Berlin sketch-based image retrieval benchmarks. However, unlike many previous methods, none of the components in our approach are engineered specifically towards the sketch-based image retrieval task - it can be generally applied to any cross-domain, zero-shot retrieval task. We therefore also show results on zero-shot cartoon-to-photo retrieval using the Office-Home dataset.
Learning Pixel-Adaptive Weights for Portrait Photo Retouching
Dec 07, 2021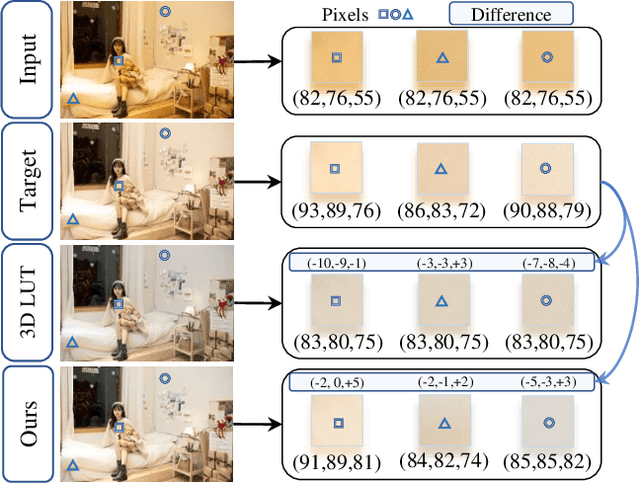
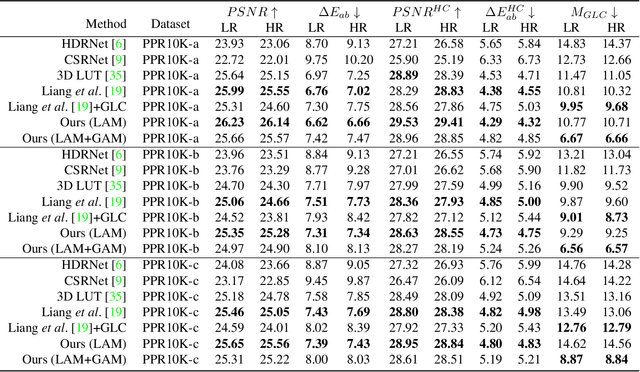
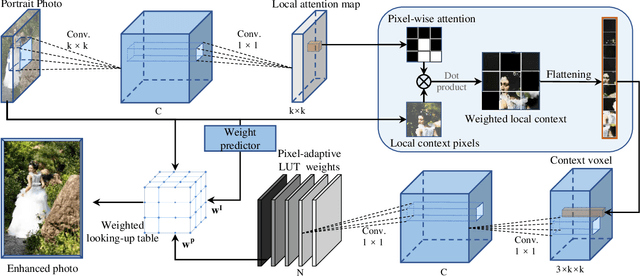
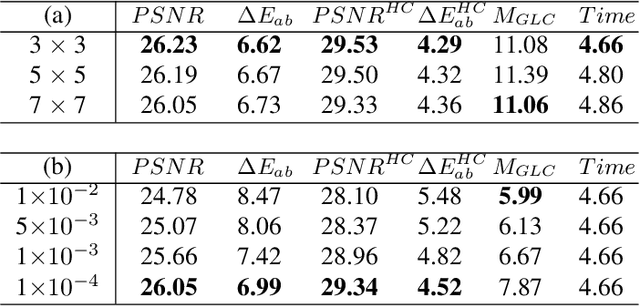
Portrait photo retouching is a photo retouching task that emphasizes human-region priority and group-level consistency. The lookup table-based method achieves promising retouching performance by learning image-adaptive weights to combine 3-dimensional lookup tables (3D LUTs) and conducting pixel-to-pixel color transformation. However, this paradigm ignores the local context cues and applies the same transformation to portrait pixels and background pixels when they exhibit the same raw RGB values. In contrast, an expert usually conducts different operations to adjust the color temperatures and tones of portrait regions and background regions. This inspires us to model local context cues to improve the retouching quality explicitly. Firstly, we consider an image patch and predict pixel-adaptive lookup table weights to precisely retouch the center pixel. Secondly, as neighboring pixels exhibit different affinities to the center pixel, we estimate a local attention mask to modulate the influence of neighboring pixels. Thirdly, the quality of the local attention mask can be further improved by applying supervision, which is based on the affinity map calculated by the groundtruth portrait mask. As for group-level consistency, we propose to directly constrain the variance of mean color components in the Lab space. Extensive experiments on PPR10K dataset verify the effectiveness of our method, e.g. on high-resolution photos, the PSNR metric receives over 0.5 gains while the group-level consistency metric obtains at least 2.1 decreases.
DINAR: Diffusion Inpainting of Neural Textures for One-Shot Human Avatars
Mar 17, 2023
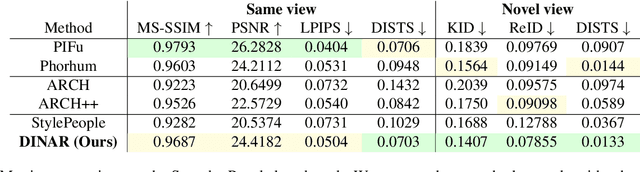
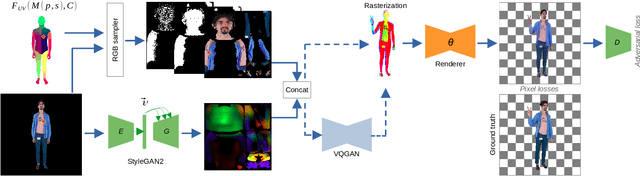
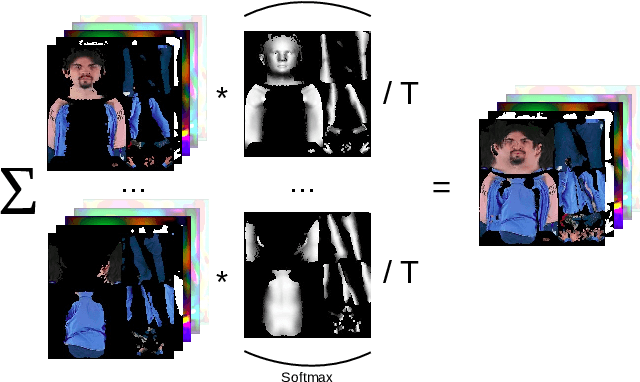
We present DINAR, an approach for creating realistic rigged fullbody avatars from single RGB images. Similarly to previous works, our method uses neural textures combined with the SMPL-X body model to achieve photo-realistic quality of avatars while keeping them easy to animate and fast to infer. To restore the texture, we use a latent diffusion model and show how such model can be trained in the neural texture space. The use of the diffusion model allows us to realistically reconstruct large unseen regions such as the back of a person given the frontal view. The models in our pipeline are trained using 2D images and videos only. In the experiments, our approach achieves state-of-the-art rendering quality and good generalization to new poses and viewpoints. In particular, the approach improves state-of-the-art on the SnapshotPeople public benchmark.
Identity-Aware CycleGAN for Face Photo-Sketch Synthesis and Recognition
Mar 30, 2021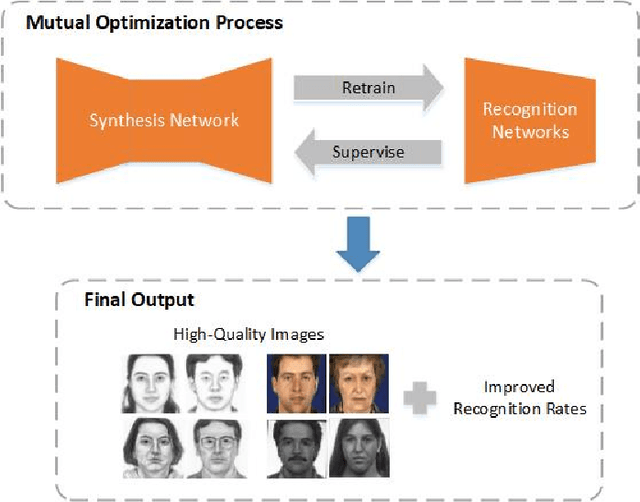
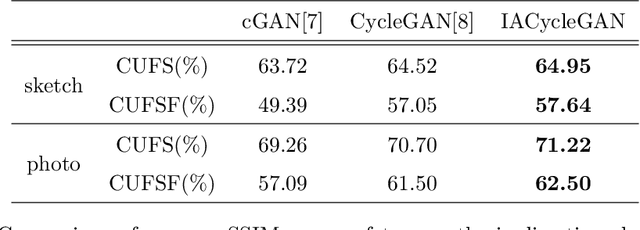
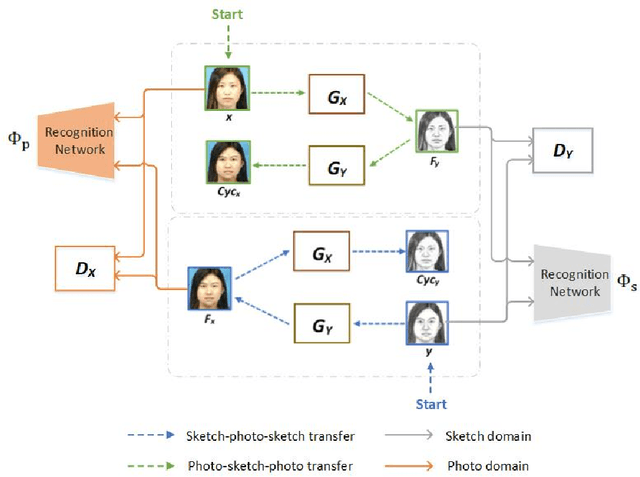
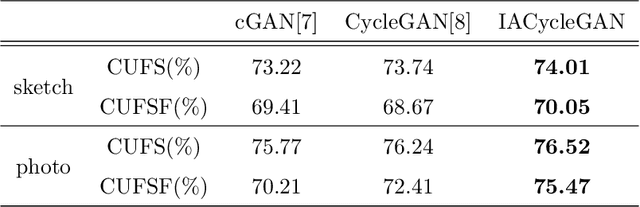
Face photo-sketch synthesis and recognition has many applications in digital entertainment and law enforcement. Recently, generative adversarial networks (GANs) based methods have significantly improved the quality of image synthesis, but they have not explicitly considered the purpose of recognition. In this paper, we first propose an Identity-Aware CycleGAN (IACycleGAN) model that applies a new perceptual loss to supervise the image generation network. It improves CycleGAN on photo-sketch synthesis by paying more attention to the synthesis of key facial regions, such as eyes and nose, which are important for identity recognition. Furthermore, we develop a mutual optimization procedure between the synthesis model and the recognition model, which iteratively synthesizes better images by IACycleGAN and enhances the recognition model by the triplet loss of the generated and real samples. Extensive experiments are performed on both photo-tosketch and sketch-to-photo tasks using the widely used CUFS and CUFSF databases. The results show that the proposed method performs better than several state-of-the-art methods in terms of both synthetic image quality and photo-sketch recognition accuracy.
* 36 pages, 11 figures
TriVol: Point Cloud Rendering via Triple Volumes
Mar 29, 2023
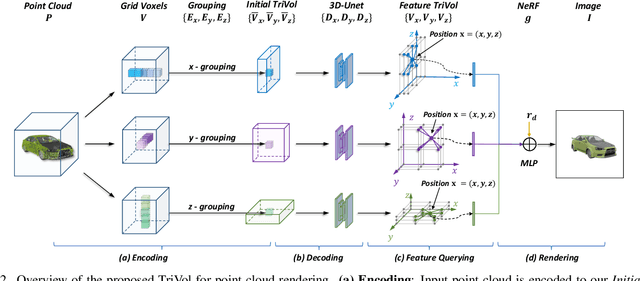
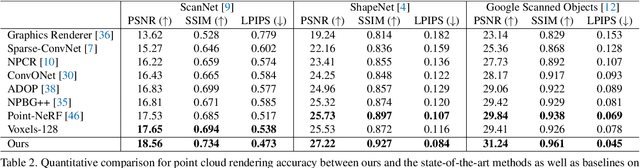
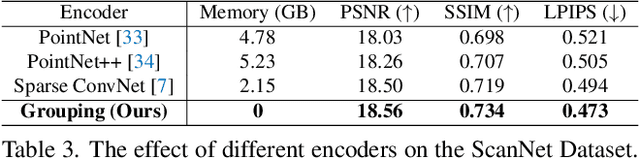
Existing learning-based methods for point cloud rendering adopt various 3D representations and feature querying mechanisms to alleviate the sparsity problem of point clouds. However, artifacts still appear in rendered images, due to the challenges in extracting continuous and discriminative 3D features from point clouds. In this paper, we present a dense while lightweight 3D representation, named TriVol, that can be combined with NeRF to render photo-realistic images from point clouds. Our TriVol consists of triple slim volumes, each of which is encoded from the point cloud. TriVol has two advantages. First, it fuses respective fields at different scales and thus extracts local and non-local features for discriminative representation. Second, since the volume size is greatly reduced, our 3D decoder can be efficiently inferred, allowing us to increase the resolution of the 3D space to render more point details. Extensive experiments on different benchmarks with varying kinds of scenes/objects demonstrate our framework's effectiveness compared with current approaches. Moreover, our framework has excellent generalization ability to render a category of scenes/objects without fine-tuning.
EvAC3D: From Event-based Apparent Contours to 3D Models via Continuous Visual Hulls
Apr 11, 20233D reconstruction from multiple views is a successful computer vision field with multiple deployments in applications. State of the art is based on traditional RGB frames that enable optimization of photo-consistency cross views. In this paper, we study the problem of 3D reconstruction from event-cameras, motivated by the advantages of event-based cameras in terms of low power and latency as well as by the biological evidence that eyes in nature capture the same data and still perceive well 3D shape. The foundation of our hypothesis that 3D reconstruction is feasible using events lies in the information contained in the occluding contours and in the continuous scene acquisition with events. We propose Apparent Contour Events (ACE), a novel event-based representation that defines the geometry of the apparent contour of an object. We represent ACE by a spatially and temporally continuous implicit function defined in the event x-y-t space. Furthermore, we design a novel continuous Voxel Carving algorithm enabled by the high temporal resolution of the Apparent Contour Events. To evaluate the performance of the method, we collect MOEC-3D, a 3D event dataset of a set of common real-world objects. We demonstrate the ability of EvAC3D to reconstruct high-fidelity mesh surfaces from real event sequences while allowing the refinement of the 3D reconstruction for each individual event.
Light Sampling Field and BRDF Representation for Physically-based Neural Rendering
Apr 11, 2023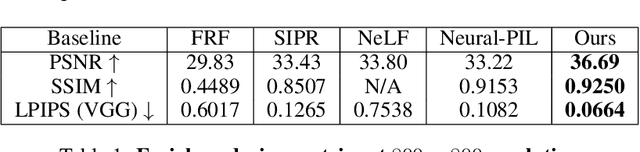

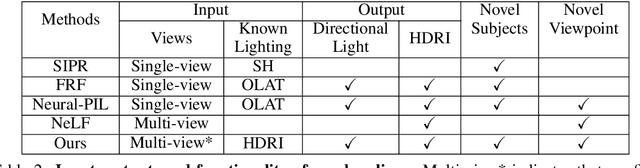
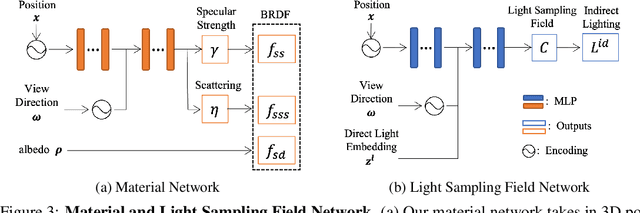
Physically-based rendering (PBR) is key for immersive rendering effects used widely in the industry to showcase detailed realistic scenes from computer graphics assets. A well-known caveat is that producing the same is computationally heavy and relies on complex capture devices. Inspired by the success in quality and efficiency of recent volumetric neural rendering, we want to develop a physically-based neural shader to eliminate device dependency and significantly boost performance. However, no existing lighting and material models in the current neural rendering approaches can accurately represent the comprehensive lighting models and BRDFs properties required by the PBR process. Thus, this paper proposes a novel lighting representation that models direct and indirect light locally through a light sampling strategy in a learned light sampling field. We also propose BRDF models to separately represent surface/subsurface scattering details to enable complex objects such as translucent material (i.e., skin, jade). We then implement our proposed representations with an end-to-end physically-based neural face skin shader, which takes a standard face asset (i.e., geometry, albedo map, and normal map) and an HDRI for illumination as inputs and generates a photo-realistic rendering as output. Extensive experiments showcase the quality and efficiency of our PBR face skin shader, indicating the effectiveness of our proposed lighting and material representations.
Linking Representations with Multimodal Contrastive Learning
Apr 11, 2023
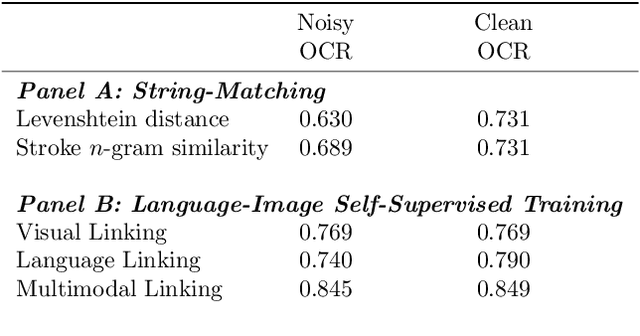
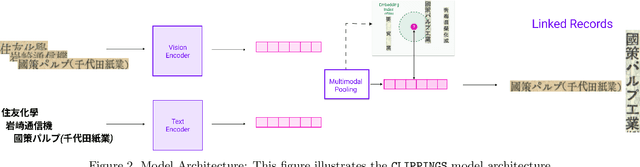
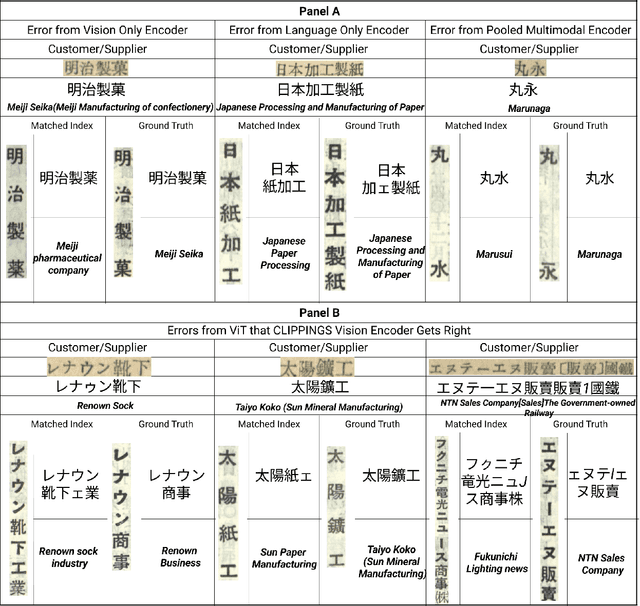
Many applications require grouping instances contained in diverse document datasets into classes. Most widely used methods do not employ deep learning and do not exploit the inherently multimodal nature of documents. Notably, record linkage is typically conceptualized as a string-matching problem. This study develops CLIPPINGS, (Contrastively Linking Pooled Pre-trained Embeddings), a multimodal framework for record linkage. CLIPPINGS employs end-to-end training of symmetric vision and language bi-encoders, aligned through contrastive language-image pre-training, to learn a metric space where the pooled image-text representation for a given instance is close to representations in the same class and distant from representations in different classes. At inference time, instances can be linked by retrieving their nearest neighbor from an offline exemplar embedding index or by clustering their representations. The study examines two challenging applications: constructing comprehensive supply chains for mid-20th century Japan through linking firm level financial records - with each firm name represented by its crop in the document image and the corresponding OCR - and detecting which image-caption pairs in a massive corpus of historical U.S. newspapers came from the same underlying photo wire source. CLIPPINGS outperforms widely used string matching methods by a wide margin and also outperforms unimodal methods. Moreover, a purely self-supervised model trained on only image-OCR pairs also outperforms popular string-matching methods without requiring any labels.
Eagle: End-to-end Deep Reinforcement Learning based Autonomous Control of PTZ Cameras
Apr 10, 2023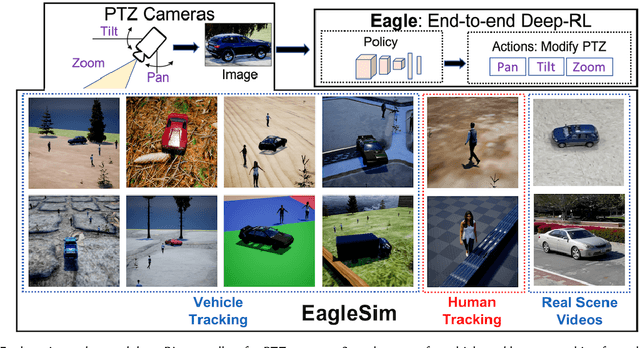

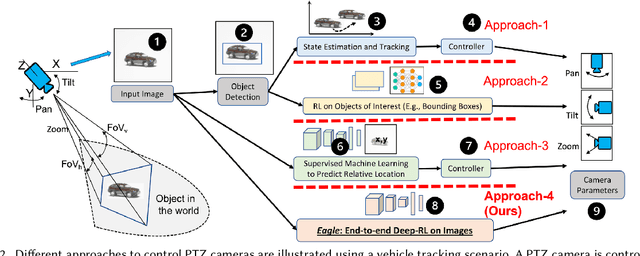
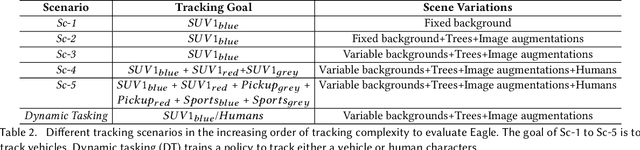
Existing approaches for autonomous control of pan-tilt-zoom (PTZ) cameras use multiple stages where object detection and localization are performed separately from the control of the PTZ mechanisms. These approaches require manual labels and suffer from performance bottlenecks due to error propagation across the multi-stage flow of information. The large size of object detection neural networks also makes prior solutions infeasible for real-time deployment in resource-constrained devices. We present an end-to-end deep reinforcement learning (RL) solution called Eagle to train a neural network policy that directly takes images as input to control the PTZ camera. Training reinforcement learning is cumbersome in the real world due to labeling effort, runtime environment stochasticity, and fragile experimental setups. We introduce a photo-realistic simulation framework for training and evaluation of PTZ camera control policies. Eagle achieves superior camera control performance by maintaining the object of interest close to the center of captured images at high resolution and has up to 17% more tracking duration than the state-of-the-art. Eagle policies are lightweight (90x fewer parameters than Yolo5s) and can run on embedded camera platforms such as Raspberry PI (33 FPS) and Jetson Nano (38 FPS), facilitating real-time PTZ tracking for resource-constrained environments. With domain randomization, Eagle policies trained in our simulator can be transferred directly to real-world scenarios.