 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDCARL: A Divide-and-Conquer Framework for Autoregressive Long-Trajectory Video Generation
Mar 25, 2026Long-trajectory video generation is a crucial yet challenging task for world modeling primarily due to the limited scalability of existing video diffusion models (VDMs). Autoregressive models, while offering infinite rollout, suffer from visual drift and poor controllability. To address these issues, we propose DCARL, a novel divide-and-conquer, autoregressive framework that effectively combines the structural stability of the divide-and-conquer scheme with the high-fidelity generation of VDMs. Our approach first employs a dedicated Keyframe Generator trained without temporal compression to establish long-range, globally consistent structural anchors. Subsequently, an Interpolation Generator synthesizes the dense frames in an autoregressive manner with overlapping segments, utilizing the keyframes for global context and a single clean preceding frame for local coherence. Trained on a large-scale internet long trajectory video dataset, our method achieves superior performance in both visual quality (lower FID and FVD) and camera adherence (lower ATE and ARE) compared to state-of-the-art autoregressive and divide-and-conquer baselines, demonstrating stable and high-fidelity generation for long trajectory videos up to 32 seconds in length.
FVGen: Accelerating Novel-View Synthesis with Adversarial Video Diffusion Distillation
Aug 08, 2025



Recent progress in 3D reconstruction has enabled realistic 3D models from dense image captures, yet challenges persist with sparse views, often leading to artifacts in unseen areas. Recent works leverage Video Diffusion Models (VDMs) to generate dense observations, filling the gaps when only sparse views are available for 3D reconstruction tasks. A significant limitation of these methods is their slow sampling speed when using VDMs. In this paper, we present FVGen, a novel framework that addresses this challenge by enabling fast novel view synthesis using VDMs in as few as four sampling steps. We propose a novel video diffusion model distillation method that distills a multi-step denoising teacher model into a few-step denoising student model using Generative Adversarial Networks (GANs) and softened reverse KL-divergence minimization. Extensive experiments on real-world datasets show that, compared to previous works, our framework generates the same number of novel views with similar (or even better) visual quality while reducing sampling time by more than 90%. FVGen significantly improves time efficiency for downstream reconstruction tasks, particularly when working with sparse input views (more than 2) where pre-trained VDMs need to be run multiple times to achieve better spatial coverage.
RDD: Robust Feature Detector and Descriptor using Deformable Transformer
May 12, 2025



As a core step in structure-from-motion and SLAM, robust feature detection and description under challenging scenarios such as significant viewpoint changes remain unresolved despite their ubiquity. While recent works have identified the importance of local features in modeling geometric transformations, these methods fail to learn the visual cues present in long-range relationships. We present Robust Deformable Detector (RDD), a novel and robust keypoint detector/descriptor leveraging the deformable transformer, which captures global context and geometric invariance through deformable self-attention mechanisms. Specifically, we observed that deformable attention focuses on key locations, effectively reducing the search space complexity and modeling the geometric invariance. Furthermore, we collected an Air-to-Ground dataset for training in addition to the standard MegaDepth dataset. Our proposed method outperforms all state-of-the-art keypoint detection/description methods in sparse matching tasks and is also capable of semi-dense matching. To ensure comprehensive evaluation, we introduce two challenging benchmarks: one emphasizing large viewpoint and scale variations, and the other being an Air-to-Ground benchmark -- an evaluation setting that has recently gaining popularity for 3D reconstruction across different altitudes.
Skyeyes: Ground Roaming using Aerial View Images
Sep 25, 2024



Integrating aerial imagery-based scene generation into applications like autonomous driving and gaming enhances realism in 3D environments, but challenges remain in creating detailed content for occluded areas and ensuring real-time, consistent rendering. In this paper, we introduce Skyeyes, a novel framework that can generate photorealistic sequences of ground view images using only aerial view inputs, thereby creating a ground roaming experience. More specifically, we combine a 3D representation with a view consistent generation model, which ensures coherence between generated images. This method allows for the creation of geometrically consistent ground view images, even with large view gaps. The images maintain improved spatial-temporal coherence and realism, enhancing scene comprehension and visualization from aerial perspectives. To the best of our knowledge, there are no publicly available datasets that contain pairwise geo-aligned aerial and ground view imagery. Therefore, we build a large, synthetic, and geo-aligned dataset using Unreal Engine. Both qualitative and quantitative analyses on this synthetic dataset display superior results compared to other leading synthesis approaches. See the project page for more results: https://chaoren2357.github.io/website-skyeyes/.
Geometry-aware Feature Matching for Large-Scale Structure from Motion
Sep 03, 2024



Establishing consistent and dense correspondences across multiple images is crucial for Structure from Motion (SfM) systems. Significant view changes, such as air-to-ground with very sparse view overlap, pose an even greater challenge to the correspondence solvers. We present a novel optimization-based approach that significantly enhances existing feature matching methods by introducing geometry cues in addition to color cues. This helps fill gaps when there is less overlap in large-scale scenarios. Our method formulates geometric verification as an optimization problem, guiding feature matching within detector-free methods and using sparse correspondences from detector-based methods as anchor points. By enforcing geometric constraints via the Sampson Distance, our approach ensures that the denser correspondences from detector-free methods are geometrically consistent and more accurate. This hybrid strategy significantly improves correspondence density and accuracy, mitigates multi-view inconsistencies, and leads to notable advancements in camera pose accuracy and point cloud density. It outperforms state-of-the-art feature matching methods on benchmark datasets and enables feature matching in challenging extreme large-scale settings.
Light Sampling Field and BRDF Representation for Physically-based Neural Rendering
Apr 11, 2023



Physically-based rendering (PBR) is key for immersive rendering effects used widely in the industry to showcase detailed realistic scenes from computer graphics assets. A well-known caveat is that producing the same is computationally heavy and relies on complex capture devices. Inspired by the success in quality and efficiency of recent volumetric neural rendering, we want to develop a physically-based neural shader to eliminate device dependency and significantly boost performance. However, no existing lighting and material models in the current neural rendering approaches can accurately represent the comprehensive lighting models and BRDFs properties required by the PBR process. Thus, this paper proposes a novel lighting representation that models direct and indirect light locally through a light sampling strategy in a learned light sampling field. We also propose BRDF models to separately represent surface/subsurface scattering details to enable complex objects such as translucent material (i.e., skin, jade). We then implement our proposed representations with an end-to-end physically-based neural face skin shader, which takes a standard face asset (i.e., geometry, albedo map, and normal map) and an HDRI for illumination as inputs and generates a photo-realistic rendering as output. Extensive experiments showcase the quality and efficiency of our PBR face skin shader, indicating the effectiveness of our proposed lighting and material representations.
Unimodal Face Classification with Multimodal Training
Dec 08, 2021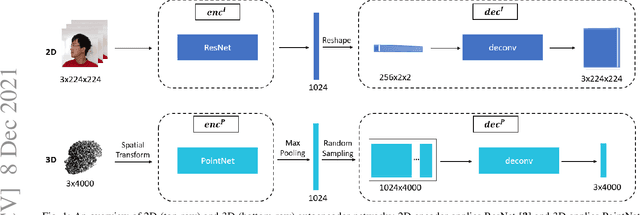
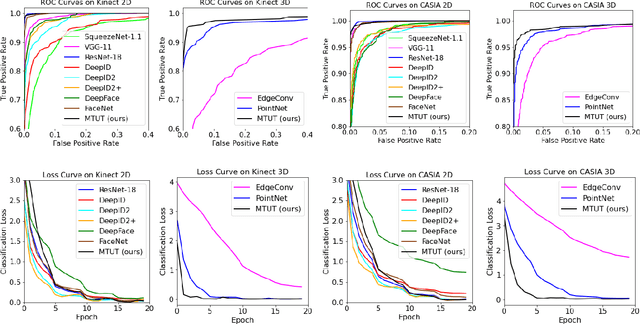
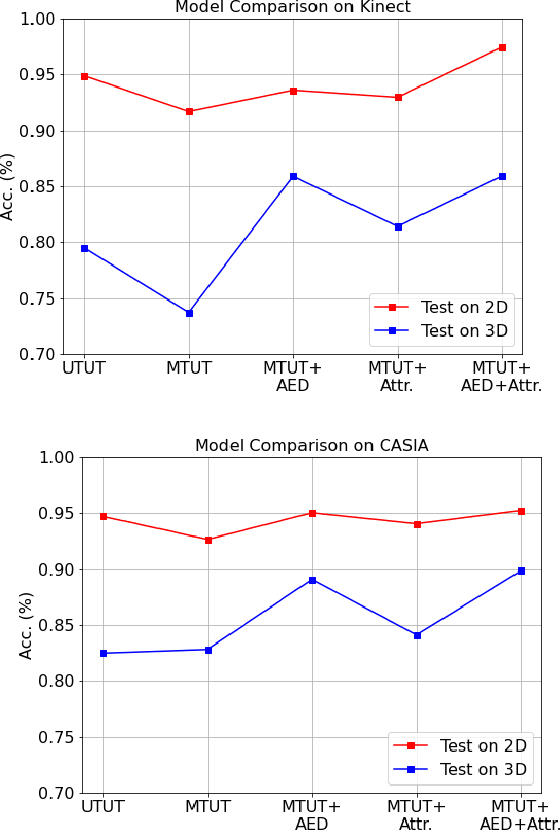
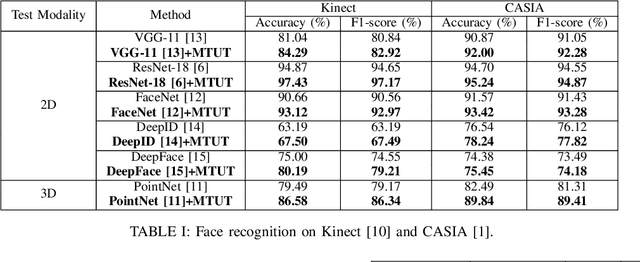
Face recognition is a crucial task in various multimedia applications such as security check, credential access and motion sensing games. However, the task is challenging when an input face is noisy (e.g. poor-condition RGB image) or lacks certain information (e.g. 3D face without color). In this work, we propose a Multimodal Training Unimodal Test (MTUT) framework for robust face classification, which exploits the cross-modality relationship during training and applies it as a complementary of the imperfect single modality input during testing. Technically, during training, the framework (1) builds both intra-modality and cross-modality autoencoders with the aid of facial attributes to learn latent embeddings as multimodal descriptors, (2) proposes a novel multimodal embedding divergence loss to align the heterogeneous features from different modalities, which also adaptively avoids the useless modality (if any) from confusing the model. This way, the learned autoencoders can generate robust embeddings in single-modality face classification on test stage. We evaluate our framework in two face classification datasets and two kinds of testing input: (1) poor-condition image and (2) point cloud or 3D face mesh, when both 2D and 3D modalities are available for training. We experimentally show that our MTUT framework consistently outperforms ten baselines on 2D and 3D settings of both datasets.