 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"photo": models, code, and papers
Convolutional Neural Opacity Radiance Fields
Apr 05, 2021

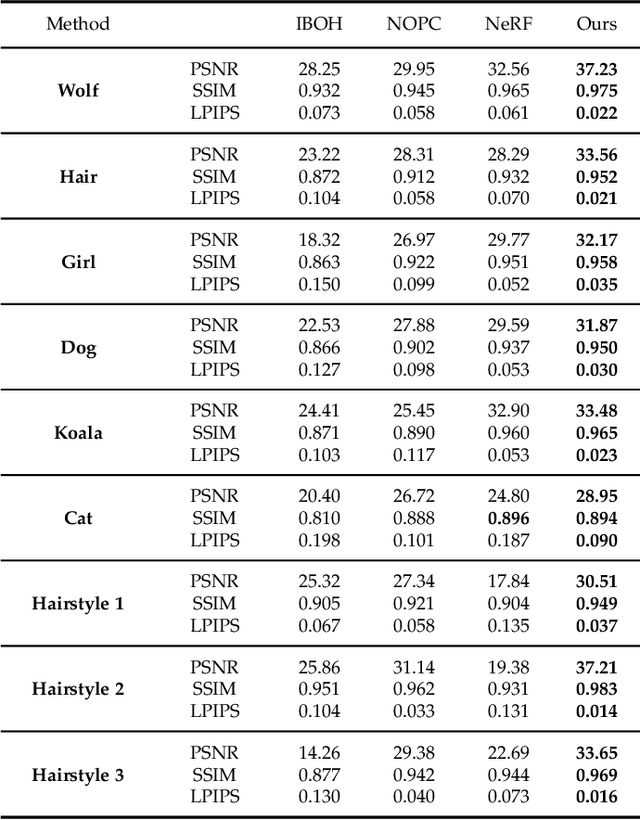
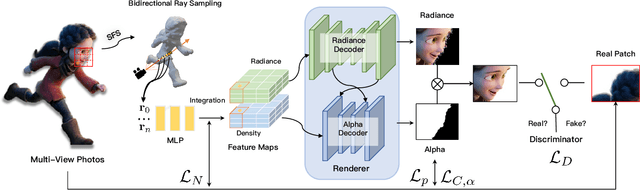
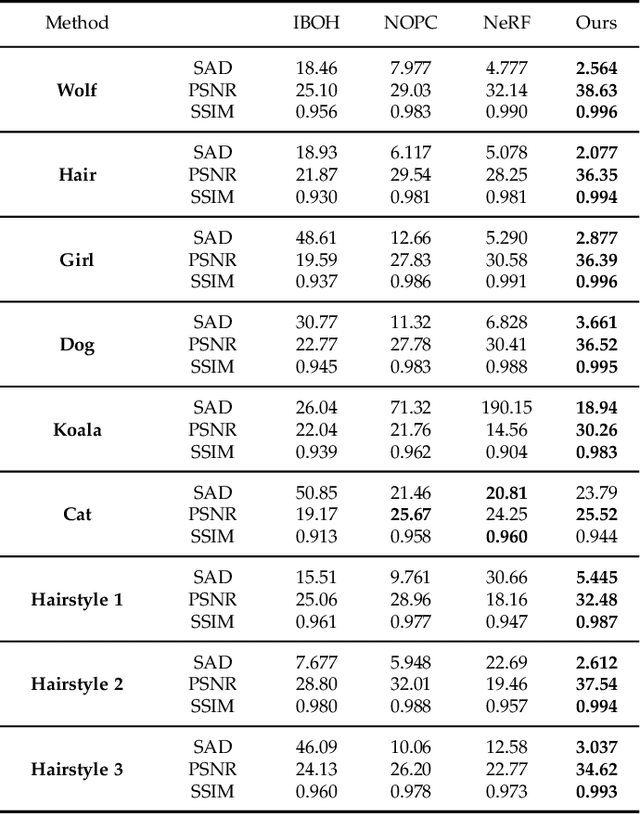
Photo-realistic modeling and rendering of fuzzy objects with complex opacity are critical for numerous immersive VR/AR applications, but it suffers from strong view-dependent brightness, color. In this paper, we propose a novel scheme to generate opacity radiance fields with a convolutional neural renderer for fuzzy objects, which is the first to combine both explicit opacity supervision and convolutional mechanism into the neural radiance field framework so as to enable high-quality appearance and global consistent alpha mattes generation in arbitrary novel views. More specifically, we propose an efficient sampling strategy along with both the camera rays and image plane, which enables efficient radiance field sampling and learning in a patch-wise manner, as well as a novel volumetric feature integration scheme that generates per-patch hybrid feature embeddings to reconstruct the view-consistent fine-detailed appearance and opacity output. We further adopt a patch-wise adversarial training scheme to preserve both high-frequency appearance and opacity details in a self-supervised framework. We also introduce an effective multi-view image capture system to capture high-quality color and alpha maps for challenging fuzzy objects. Extensive experiments on existing and our new challenging fuzzy object dataset demonstrate that our method achieves photo-realistic, globally consistent, and fined detailed appearance and opacity free-viewpoint rendering for various fuzzy objects.
Towers of Babel: Combining Images, Language, and 3D Geometry for Learning Multimodal Vision
Aug 12, 2021



The abundance and richness of Internet photos of landmarks and cities has led to significant progress in 3D vision over the past two decades, including automated 3D reconstructions of the world's landmarks from tourist photos. However, a major source of information available for these 3D-augmented collections---namely language, e.g., from image captions---has been virtually untapped. In this work, we present WikiScenes, a new, large-scale dataset of landmark photo collections that contains descriptive text in the form of captions and hierarchical category names. WikiScenes forms a new testbed for multimodal reasoning involving images, text, and 3D geometry. We demonstrate the utility of WikiScenes for learning semantic concepts over images and 3D models. Our weakly-supervised framework connects images, 3D structure, and semantics---utilizing the strong constraints provided by 3D geometry---to associate semantic concepts to image pixels and 3D points.
StyleMeUp: Towards Style-Agnostic Sketch-Based Image Retrieval
Mar 31, 2021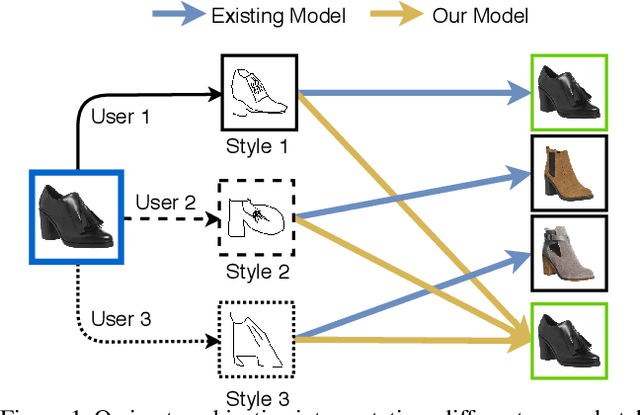
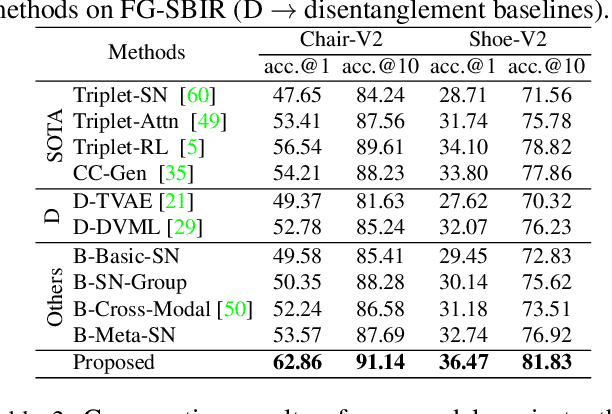
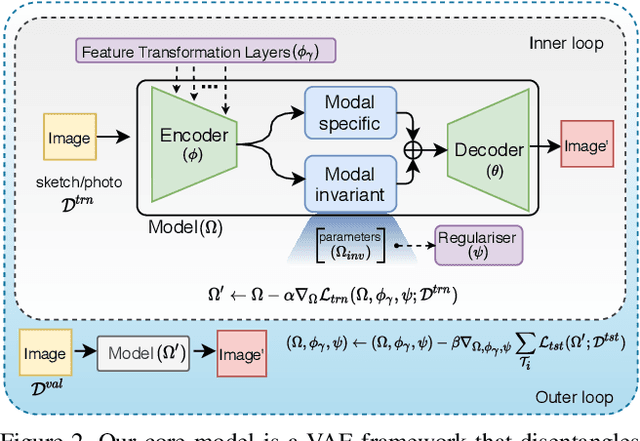
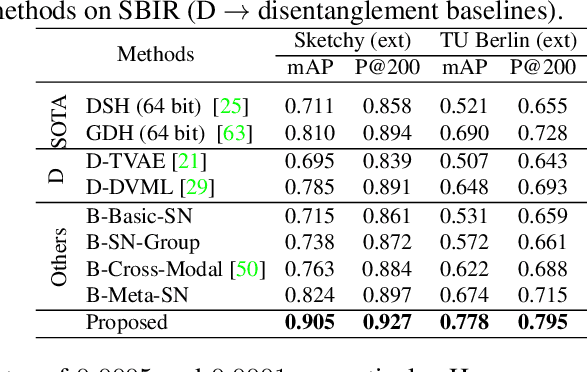
Sketch-based image retrieval (SBIR) is a cross-modal matching problem which is typically solved by learning a joint embedding space where the semantic content shared between photo and sketch modalities are preserved. However, a fundamental challenge in SBIR has been largely ignored so far, that is, sketches are drawn by humans and considerable style variations exist amongst different users. An effective SBIR model needs to explicitly account for this style diversity, crucially, to generalise to unseen user styles. To this end, a novel style-agnostic SBIR model is proposed. Different from existing models, a cross-modal variational autoencoder (VAE) is employed to explicitly disentangle each sketch into a semantic content part shared with the corresponding photo, and a style part unique to the sketcher. Importantly, to make our model dynamically adaptable to any unseen user styles, we propose to meta-train our cross-modal VAE by adding two style-adaptive components: a set of feature transformation layers to its encoder and a regulariser to the disentangled semantic content latent code. With this meta-learning framework, our model can not only disentangle the cross-modal shared semantic content for SBIR, but can adapt the disentanglement to any unseen user style as well, making the SBIR model truly style-agnostic. Extensive experiments show that our style-agnostic model yields state-of-the-art performance for both category-level and instance-level SBIR.
CariMe: Unpaired Caricature Generation with Multiple Exaggerations
Oct 01, 2020



Caricature generation aims to translate real photos into caricatures with artistic styles and shape exaggerations while maintaining the identity of the subject. Different from the generic image-to-image translation, drawing a caricature automatically is a more challenging task due to the existence of various spacial deformations. Previous caricature generation methods are obsessed with predicting definite image warping from a given photo while ignoring the intrinsic representation and distribution for exaggerations in caricatures. This limits their ability on diverse exaggeration generation. In this paper, we generalize the caricature generation problem from instance-level warping prediction to distribution-level deformation modeling. Based on this assumption, we present the first exploration for unpaired CARIcature generation with Multiple Exaggerations (CariMe). Technically, we propose a Multi-exaggeration Warper network to learn the distribution-level mapping from photo to facial exaggerations. This makes it possible to generate diverse and reasonable exaggerations from randomly sampled warp codes given one input photo. To better represent the facial exaggeration and produce fine-grained warping, a deformation-field-based warping method is also proposed, which helps us to capture more detailed exaggerations than other point-based warping methods. Experiments and two perceptual studies prove the superiority of our method comparing with other state-of-the-art methods, showing the improvement of our work on caricature generation.
PoseFace: Pose-Invariant Features and Pose-Adaptive Loss for Face Recognition
Jul 25, 2021
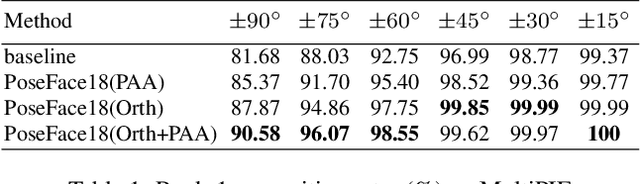
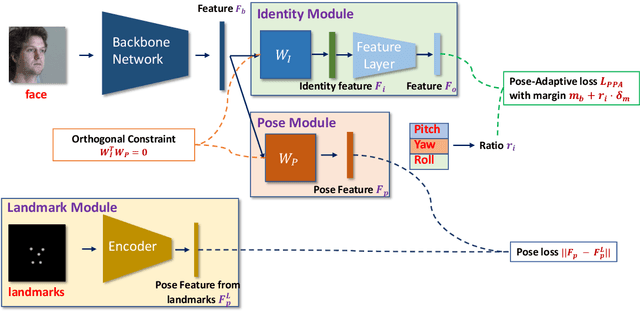
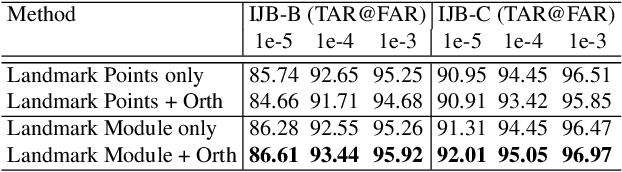
Despite the great success achieved by deep learning methods in face recognition, severe performance drops are observed for large pose variations in unconstrained environments (e.g., in cases of surveillance and photo-tagging). To address it, current methods either deploy pose-specific models or frontalize faces by additional modules. Still, they ignore the fact that identity information should be consistent across poses and are not realizing the data imbalance between frontal and profile face images during training. In this paper, we propose an efficient PoseFace framework which utilizes the facial landmarks to disentangle the pose-invariant features and exploits a pose-adaptive loss to handle the imbalance issue adaptively. Extensive experimental results on the benchmarks of Multi-PIE, CFP, CPLFW and IJB have demonstrated the superiority of our method over the state-of-the-arts.
StyleNeRF: A Style-based 3D-Aware Generator for High-resolution Image Synthesis
Oct 18, 2021


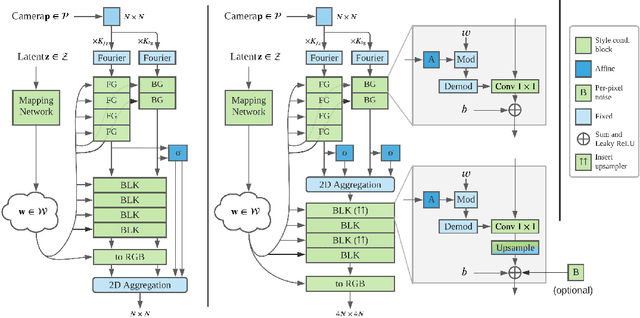
We propose StyleNeRF, a 3D-aware generative model for photo-realistic high-resolution image synthesis with high multi-view consistency, which can be trained on unstructured 2D images. Existing approaches either cannot synthesize high-resolution images with fine details or yield noticeable 3D-inconsistent artifacts. In addition, many of them lack control over style attributes and explicit 3D camera poses. StyleNeRF integrates the neural radiance field (NeRF) into a style-based generator to tackle the aforementioned challenges, i.e., improving rendering efficiency and 3D consistency for high-resolution image generation. We perform volume rendering only to produce a low-resolution feature map and progressively apply upsampling in 2D to address the first issue. To mitigate the inconsistencies caused by 2D upsampling, we propose multiple designs, including a better upsampler and a new regularization loss. With these designs, StyleNeRF can synthesize high-resolution images at interactive rates while preserving 3D consistency at high quality. StyleNeRF also enables control of camera poses and different levels of styles, which can generalize to unseen views. It also supports challenging tasks, including zoom-in and-out, style mixing, inversion, and semantic editing.
Spatial-Temporal Super-Resolution of Satellite Imagery via Conditional Pixel Synthesis
Jun 22, 2021
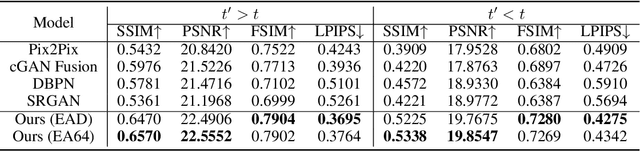
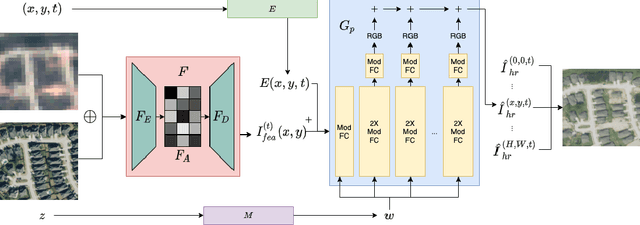

High-resolution satellite imagery has proven useful for a broad range of tasks, including measurement of global human population, local economic livelihoods, and biodiversity, among many others. Unfortunately, high-resolution imagery is both infrequently collected and expensive to purchase, making it hard to efficiently and effectively scale these downstream tasks over both time and space. We propose a new conditional pixel synthesis model that uses abundant, low-cost, low-resolution imagery to generate accurate high-resolution imagery at locations and times in which it is unavailable. We show that our model attains photo-realistic sample quality and outperforms competing baselines on a key downstream task -- object counting -- particularly in geographic locations where conditions on the ground are changing rapidly.
PRNU Based Source Camera Identification for Webcam Videos
Jul 05, 2021
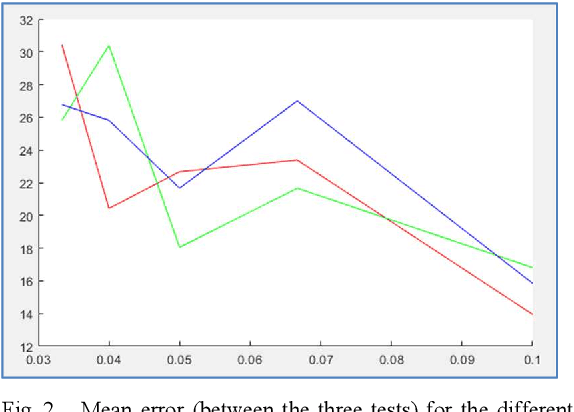
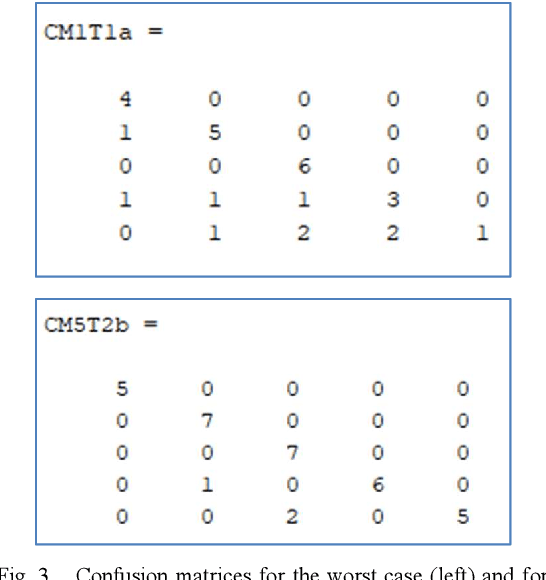
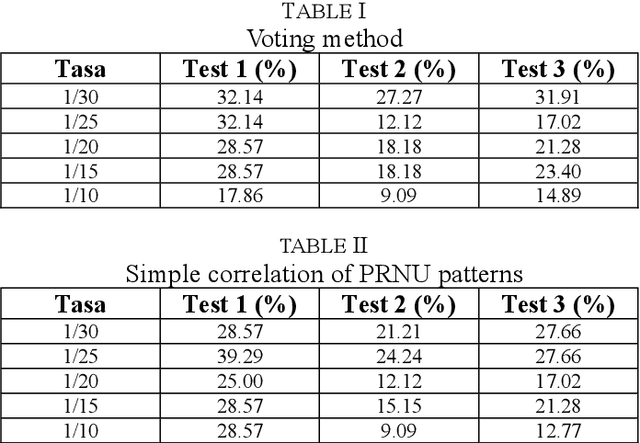
This communication is about an application of image forensics where we use camera sensor fingerprints to identify source camera (SCI: Source Camera Identification) in webcam videos. Sensor or camera fingerprints are based on computing the intrinsic noise that is always present in this kind of sensors due to manufacturing imperfections. This is an unavoidable characteristic that links each sensor with its noise pattern. PRNU (Photo Response Non-Uniformity) has become the default technique to compute a camera fingerprint. There are many applications nowadays dealing with PRNU patterns for camera identification using still images. In this work we focus on video, more specifically on webcam video, because of the great importance of webcam video nowadays. Three possible methods for SCI are implemented and assessed in this work.
More Photos are All You Need: Semi-Supervised Learning for Fine-Grained Sketch Based Image Retrieval
Mar 25, 2021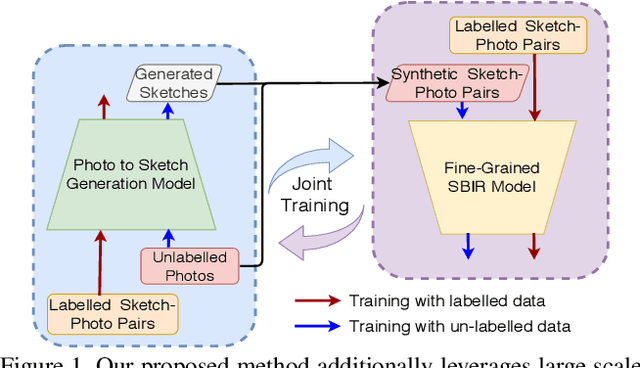
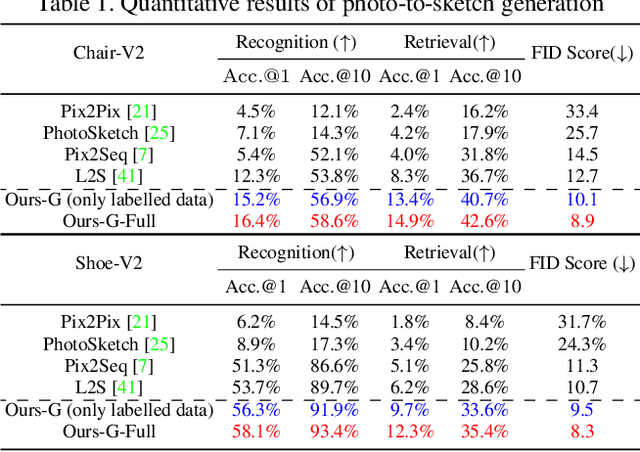
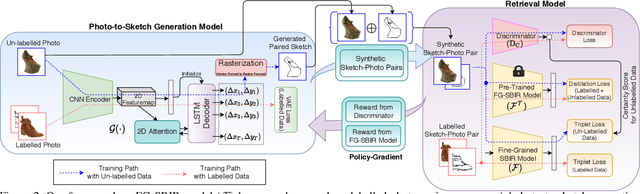
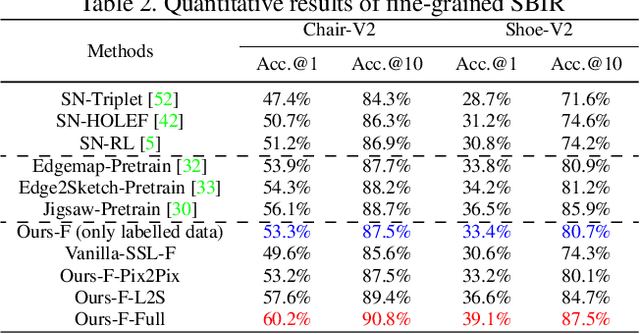
A fundamental challenge faced by existing Fine-Grained Sketch-Based Image Retrieval (FG-SBIR) models is the data scarcity -- model performances are largely bottlenecked by the lack of sketch-photo pairs. Whilst the number of photos can be easily scaled, each corresponding sketch still needs to be individually produced. In this paper, we aim to mitigate such an upper-bound on sketch data, and study whether unlabelled photos alone (of which they are many) can be cultivated for performances gain. In particular, we introduce a novel semi-supervised framework for cross-modal retrieval that can additionally leverage large-scale unlabelled photos to account for data scarcity. At the centre of our semi-supervision design is a sequential photo-to-sketch generation model that aims to generate paired sketches for unlabelled photos. Importantly, we further introduce a discriminator guided mechanism to guide against unfaithful generation, together with a distillation loss based regularizer to provide tolerance against noisy training samples. Last but not least, we treat generation and retrieval as two conjugate problems, where a joint learning procedure is devised for each module to mutually benefit from each other. Extensive experiments show that our semi-supervised model yields significant performance boost over the state-of-the-art supervised alternatives, as well as existing methods that can exploit unlabelled photos for FG-SBIR.
Multi-Density Sketch-to-Image Translation Network
Jun 18, 2020



Sketch-to-image (S2I) translation plays an important role in image synthesis and manipulation tasks, such as photo editing and colorization. Some specific S2I translation including sketch-to-photo and sketch-to-painting can be used as powerful tools in the art design industry. However, previous methods only support S2I translation with a single level of density, which gives less flexibility to users for controlling the input sketches. In this work, we propose the first multi-level density sketch-to-image translation framework, which allows the input sketch to cover a wide range from rough object outlines to micro structures. Moreover, to tackle the problem of noncontinuous representation of multi-level density input sketches, we project the density level into a continuous latent space, which can then be linearly controlled by a parameter. This allows users to conveniently control the densities of input sketches and generation of images. Moreover, our method has been successfully verified on various datasets for different applications including face editing, multi-modal sketch-to-photo translation, and anime colorization, providing coarse-to-fine levels of controls to these applications.